Kubernetes CronJob не запустился? Тогда мы с shared informer идём к вам
Всем привет! Меня зовут Аня, я строю и развиваю инфраструктуру мониторинга в платформе телеметрии Ozon. Моя команда не только помогает настроить мониторинг, но и разрабатывает различные сервисы и инструменты, чтобы упростить жизнь разработчикам компании.
В прошлом году я рассказывала, как мы организовали мониторинг Kubernetes CronJob на основе kube-state-metrics, Thanos Receive и Thanos Ruler. За год мы нашли ответ на вопрос, почему же крон может не запускаться. И в этой статье я хочу рассказать об основных причинах и проблемах, о которых мы узнали.
Спойлер: многие не задумываются о том, как устроен и управляется CronJob.

Основные причины незапуска крона
Прежде чем перейти к вишенке на торте, сначала разрежем его.
CronJob Controller следит за описанием кронов, а именно за расписанием запуском. По необходимости он создаёт джобу, которая в свою очередь создаёт под.
«The CronJob is only responsible for creating Jobs that match its schedule, and the Job in turn is responsible for the management of the Pods it represents» [1] (Список источников ищите в конце статьи).
При этом Kubernetes старается, но не гарантирует запуск крона и выполнение полезной работы им. О чём прямо и говорится в документации:
«A cron job creates a job object about once per execution time of its schedule» [1].
Пример описания крона:
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailureЭто описание проще понять на схеме:
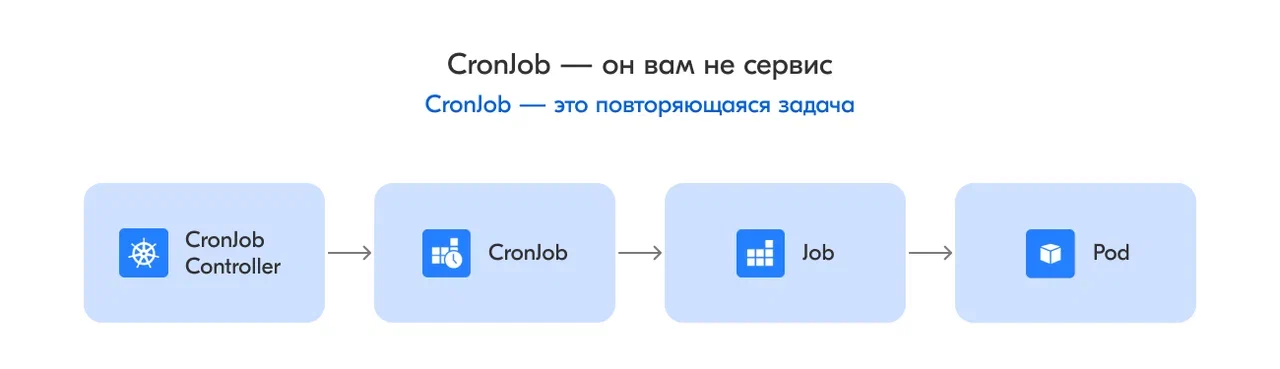
Все причины незапуска можно разделить на две группы:
Человеческий фактор.
Проблемы с CronJob Сontroller.
Человеческий фактор
Описание крона содержит довольно большое количество неявно заданных параметров. Кроме того, многие параметры трудны для понимания, если постоянно не работаешь с Kubernetes. Если по незнанию неправильно выставить параметры запуска, CronJob не запустится. Эти параметры довольно тесно между собой переплетаются, и с ходу не всегда понятно, что будет при их сочетании. Ниже я приведу параметры, которые наиболее часто приводят к незапуску крона.
Сначала рассмотрим параметры самого CronJob.
startingDeadlineSeconds
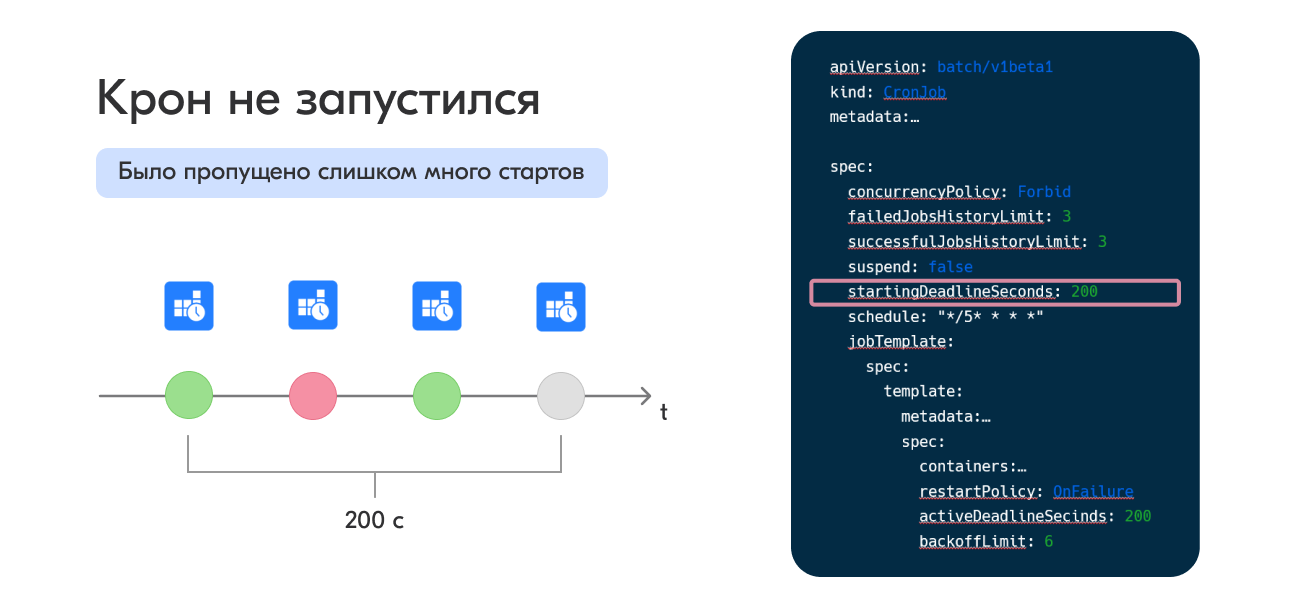
Первый и самый сложный для понимания параметр — это startingDeadlineSeconds, проверка на количество уже пропущенных запусков и период времени, на который крон может опоздать с запуском.
Для каждого крона контроллер проверяет, как много запусков он пропустил до текущего момента. Запуск считается пропущенным, если не получилось создать джобу в указанное время.
Если данный параметр не выставлен, то контроллер считает пропуски с момента прошлого запуска.
Если данный параметр выставлен (например, startingDeadlineSeconds = 200 с), то контроллер будет считать пропуски за последние 200 секунд.
Если значение данного параметра меньше 10 секунд, контроллер не будет успевать запускать крон, потому что он проверяет статусы каждые 10 секунд.
При пропуске более 100 запусков контроллер просто выкидывает крон из расписания и больше не пытается его запускать. При этом сам крон в Kubernetes будет помечен ошибкой:
«Cannot determine if job needs to be started. Too many missed start time (> 100). Set or decrease .spec.startingDeadlineSeconds or check clock skew» [1].
Также, как я упомянула выше, параметр startingDeadlineSeconds указывает период времени, на который крон может отклониться от своего запуска по расписанию.
tooLate := false
if cronJob.Spec.StartingDeadlineSeconds != nil {
tooLate = scheduledTime.Add(time.Second * time.Duration(*cronJob.Spec.StartingDeadlineSeconds)).Before(now)
}
if tooLate {
klog.V(4).InfoS("Missed starting window", "cronjob", klog.KRef(cronJob.GetNamespace(), cronJob.GetName()))
}Если параметр не выставлен, то разрешено любое отклонение.
Если параметр выставлен, то контроллер сравнивает время между ожидаемым запуском и настоящим моментом. Если этот период больше лимита, то запуск будет пропущен.
Например, у нас указан параметр startingDeadlineSeconds = 200 c, крон запускается раз в час (01.00, 02.00 и т. д.).
Мы собираемся запустить крон в t1 = 01.00. Контроллер начал проверку джобы в tnow = 01.00.00, tnow — t1 = 0 < 200 (startingDeadlineSeconds). Крон будет запущен.
Мы собираемся запустить крон в t1 = 01.00. Контроллер начал проверку джобы в tnow = 01.01.00, tnow — t1 = 60 < 200 (startingDeadlineSeconds). Крон будет запущен.
Мы собираемся запустить крон в t1 = 01.00. Контроллер начал проверку джобы в tnow = 01.04.00, tnow — t1 = 240 > 200 (startingDeadlineSeconds). Крон не будет запущен и будет помечен как неудавшийся.
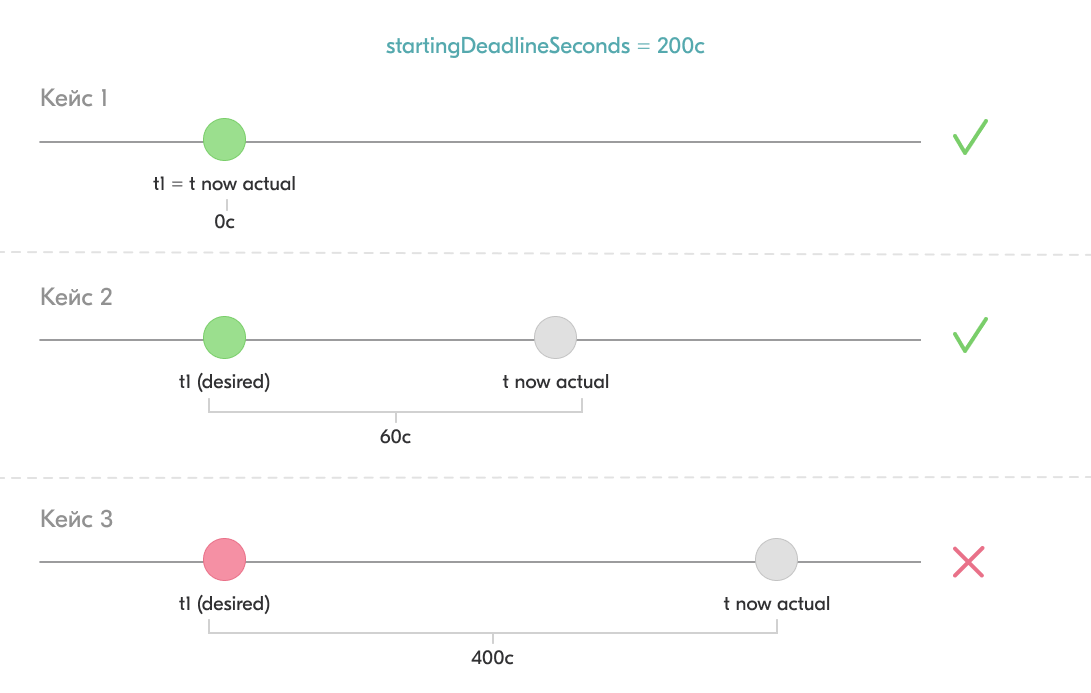
Как мы это встретили: у крона был выставлен очень маленький параметр startingDeadlineSeconds. Каждый раз, когда контроллер проверял статус крона, оказывалось, что разница между требуемым стартом и текущим моментом больше допустимого лимита. В итоге было пропущено более 100 стартов и контроллер перестал пытаться запустить крон.
ConcurrencyPolicy
Параметр ConcurrencyPolicy сообщает контроллеру, как поступать с параллельной работой нескольких джоб.
Если параметр не выставлен, то значение считается Allow. Если джоба уже запущена, то контроллер запустит ещё одну. Таким образом, у нас будут работать параллельно две джобы. Поэтому стоит помнить, что
jobs should be idempotent(действие, многократное повторение которого эквивалентно однократному выполнению).Если значение будет Forbid, то при наличии уже запущенной джобы новая джоба не запустится по расписанию.
Если значение будет Replace, при наступлении времени запуска новой джобы, если предыдущая ещё не запустилась, то контроллер немедленно завершит текущую джобу и запустит новую.
Как мы это встретили: у ребят повис крон в ожидании ответа от сервиса, при этом в коде не было никаких тайм-аутов, новые кроны не запускались.
 ConcurrencyPolicy
ConcurrencyPolicy
Теперь переходим к параметрам, с которыми запускается джоба.
backoffLimit
Параметр backoffLimitустанавливает, сколько раз перезапустить под, прежде чем джоба будет считаться зафейленной. Отмечу, что он говорит о рестарте именно пода, а не джобы, то есть все рестарты происходят в рамках одной джобы. По дефолту данный параметр имеет значение 6. Рестарты осуществляются джоб контроллером с интервалом, увеличивающимся по экспоненте (10 с, 20 с, 40 с) и достигающим 6 минут для последней попытки.
Как было у нас: ребята выставляли очень большое значение backoffLimit и concurrencyPolicy = Forbid, в какой-то момент интервалы между рестартами подов стали исчисляться часами, текущий крон фактически не работал, а все новые кроны не запускались, так как это крон ещё считался рабочим.
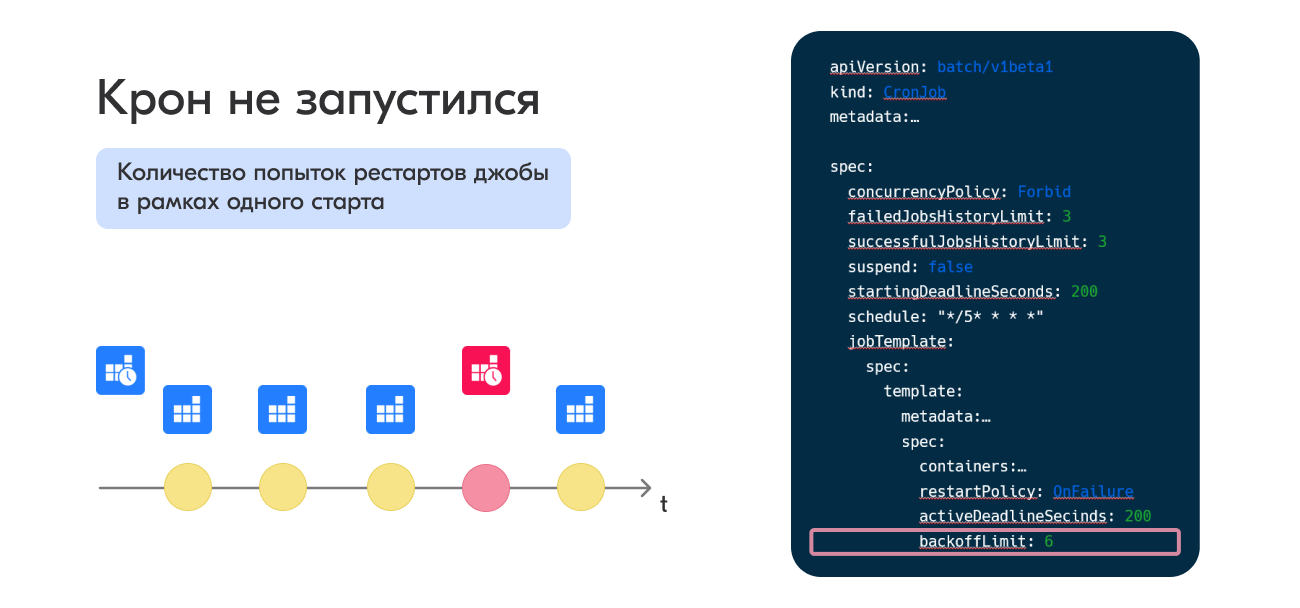 backoffLimit
backoffLimit
activeDeadlineSeconds
Параметр activeDeadlineSeconds определяет лимит длительности работы джобы. Как только он будет достигнут, все запущенные поды будут остановлены, а статус джобы изменится на Failed c причиной DeadlineExceeded.
Стоит отметить, что activeDeadlineSeconds имеет приоритет над backoffLimit. Если мы достигли лимита по времени работы джобы, она будет считаться зафейленной, даже если ещё не все попытки рестарта были использованы.
Как было у нас: разработчики указывали очень большой лимит, крон по какой-то причине вис, при этом параметр ConcurrencyPolicy был установлен в значении Forbid, новые кроны не запускались.
 activeDeadlineSeconds
activeDeadlineSeconds
suspend
Моя самая любимая причина незапуска. Задержите дыхание… Готовы?
Кто-то поставил крон на паузу. У крона есть опциональный параметр suspend. Если suspend = true, новые запуски не будут производиться до тех пор, пока он не станет false. Текущий же рабочий запуск будет завершён в штатном порядке (то есть этот параметр применяется только к новым запускам).
Отмечу, что все запуски, которые должны были быть совершены, помечаются как пропущенные.
Как только значение параметра будет изменено (suspend = false), те кроны, у которых не выставлен параметр startingDeadlineSeconds, будут запущены немедленно. Если параметр выставлен, то будет произведена проверка на количество пропущенных стартов.я
Как было у нас: разработчики ставили крон на паузу, чтобы протестировать новый функционал, забывали и уходили на выходные.
 suspend
suspend
CronJob-контроллеры
Основным открытием и проблемой оказалась версия CronJob Controller. Есть две версии контроллера, которые совершенно по-разному следят за кронами.
CronJob Controller v1
CronJob Controller v1 является единственным контроллером для версий Kubernetes ниже v1.19.
Данный контроллер довольно прост. Он работает в один поток и каждые 10 секунд запрашивает у Kubernetes API описание всех кронов, затем последовательно проходит по этому списку и проверяет статус каждого крона, чтобы понять, надо ли его запустить.
// Run starts the main goroutine responsible for watching and syncing jobs.
func (jm *Controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
klog.Infof("Starting CronJob Manager")
// Check things every 10 second.
go wait.Until(jm.syncAll, 10*time.Second, stopCh)
<-stopCh
klog.Infof("Shutting down CronJob Manager")
}
// syncAll lists all the CronJobs and Jobs and reconciles them.
func (jm *Controller) syncAll() {
// List children (Jobs) before parents (CronJob).
jobListFunc := func(opts metav1.ListOptions) (runtime.Object, error) {
return jm.kubeClient.BatchV1().Jobs(metav1.NamespaceAll).List(context.TODO(), opts)
}
...
cronJobListFunc := func(opts metav1.ListOptions) (runtime.Object, error) {
return jm.kubeClient.BatchV1beta1().CronJobs(metav1.NamespaceAll).List(context.TODO(), opts)
}
...
// затем вызывается функция syncOne для каждого крона.
// syncOne(sj, jobsBySj[sj.UID], time.Now(), jm.jobControl, jm.sjControl, jm.recorder)
}
// syncOne reconciles a CronJob with a list of any Jobs that it created.
func syncOne(sj *batchv1beta1.CronJob, js []batchv1.Job, now time.Time, jc jobControlInterface, sjc sjControlInterface, recorder record.EventRecorder){
}
Код CronJobController v1 [10]
Данный запрос довольно сильно нагружается непосредственно Kubernetes API, и обход списка занимает много времени. В результате при увеличении количества кронов в кластере контроллер начинает пропускать запуски кронов. Например, запросили список в t1, а дошли до последнего крона в списке в t1 + N минут.
С каждой 1000 добавленных в кластер кронов контроллер начинает обходить список дольше на 90—120 секунд. В результате, если в кластере 5120 кронов, контроллер тратит приблизительно 9 минут, чтобы запустить 20 кронов (которые действительно надо запустить). За цикл контроллер пропускает примерно 8 запусков [5].
 CronJobController v1
CronJobController v1
CronJob Controller v2
CronJob Controller v2 появился в версии Kubernetes 1.19, и его можно было включить опционально. Начиная с версии Kubernetes 1.21 данный контроллер — основной по умолчанию.
Новая версия контроллера написана в единой концепции с другими контроллерами: использует shared informers. Это позволило существенно снизить нагрузку на Kubernetes API.

Shared informers. Всё в Kubernetes представляет собой декларативное описание объектов, которое указывает желаемое для объекта состояние. И задача Kubernetes — следить за изменениями системы и поддерживать объекты в нужном состоянии. Текущее состояние объекта — это результат всех предшествующих ивентов.
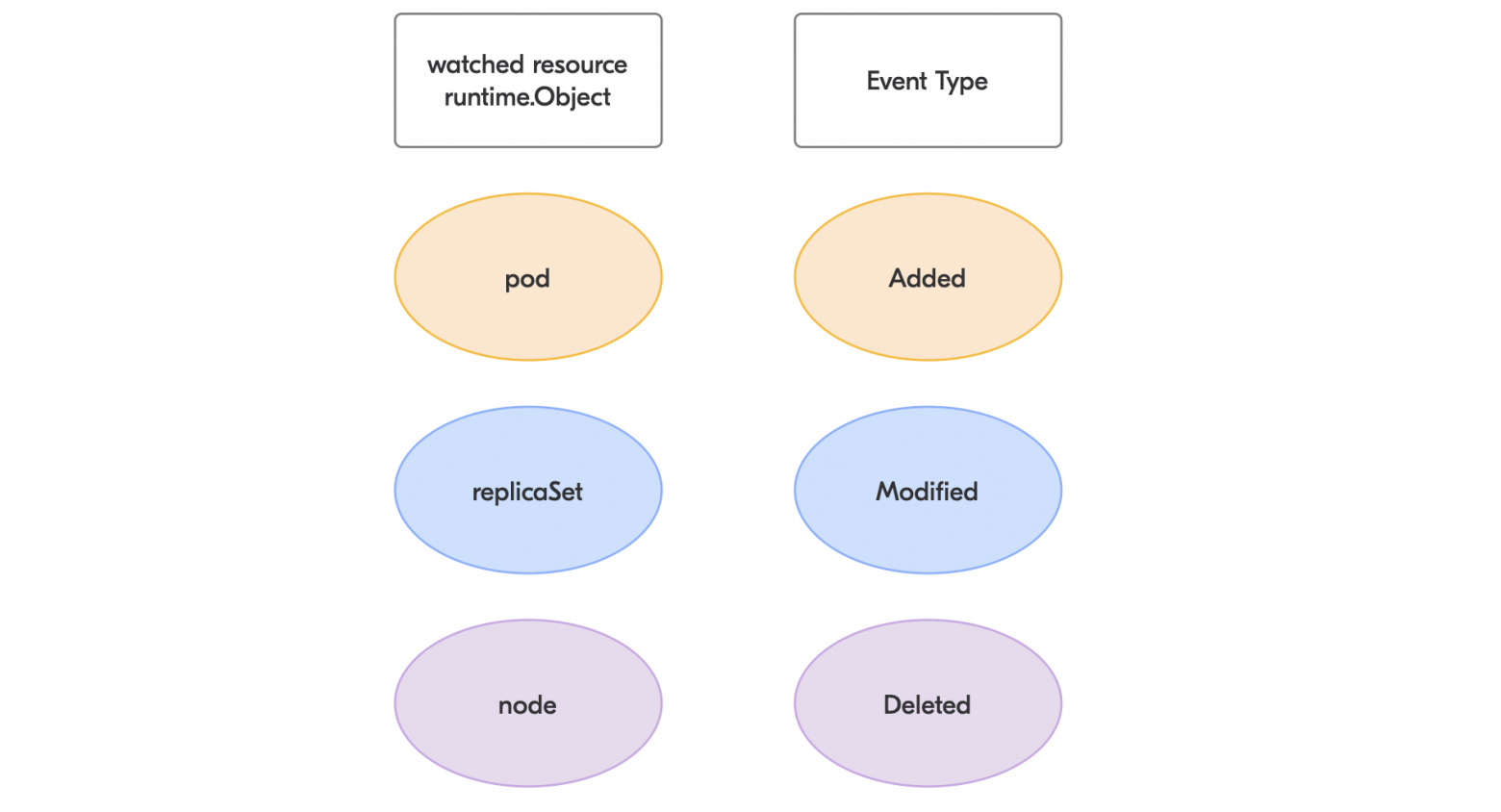 Пример объектов и типов событий
Пример объектов и типов событий
Каждый объект в Kubernetes имеет версию ресурса (resourceVersion), которая изменяется при любом новом ивенте, который случается с объектом.
Давайте рассмотрим жизнь ивента в Kubernetes. Например, вы создали под. Что произойдёт? Сначала объект будет сохранён в etcd, который является хранилищем для Kubernetes. Затем объект из etcd попадёт в API Server, а после этого будет обработан в client-go. И уже client-go доставит объект всем заинтересованным пользователям (контроллерам, операторам, шедулерам).
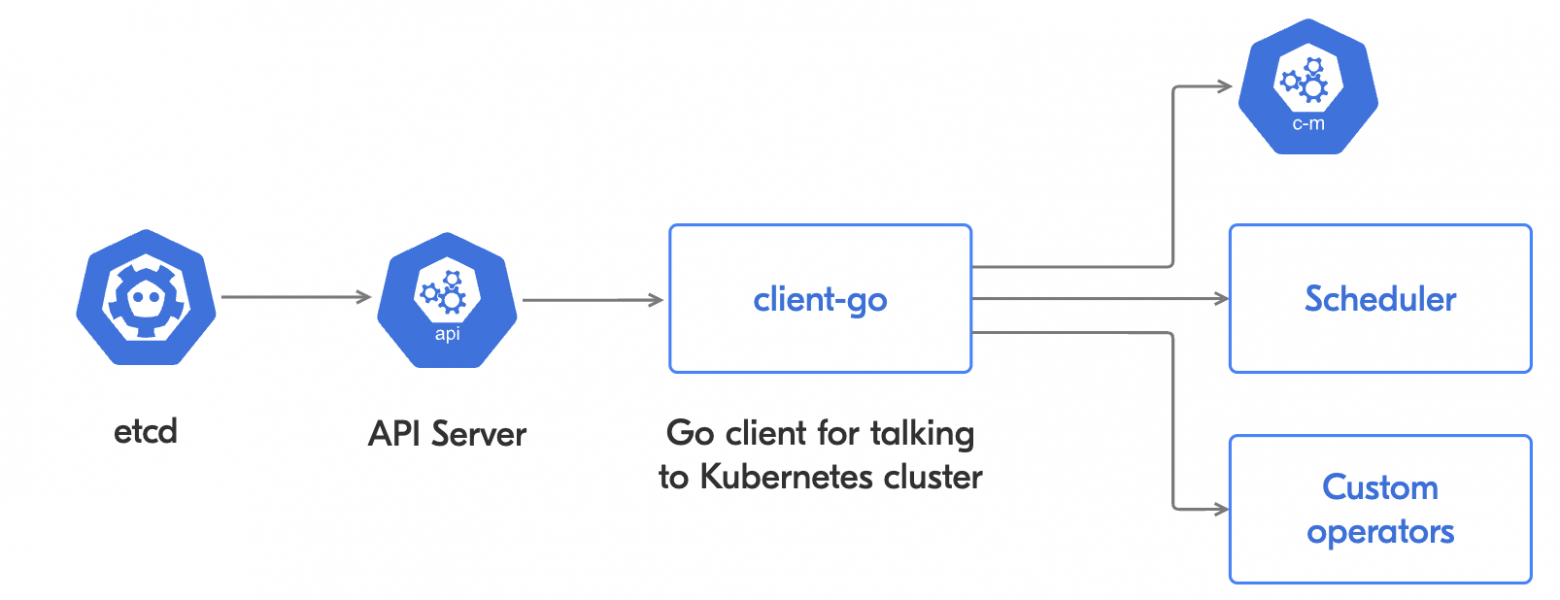 Etcd
Etcd
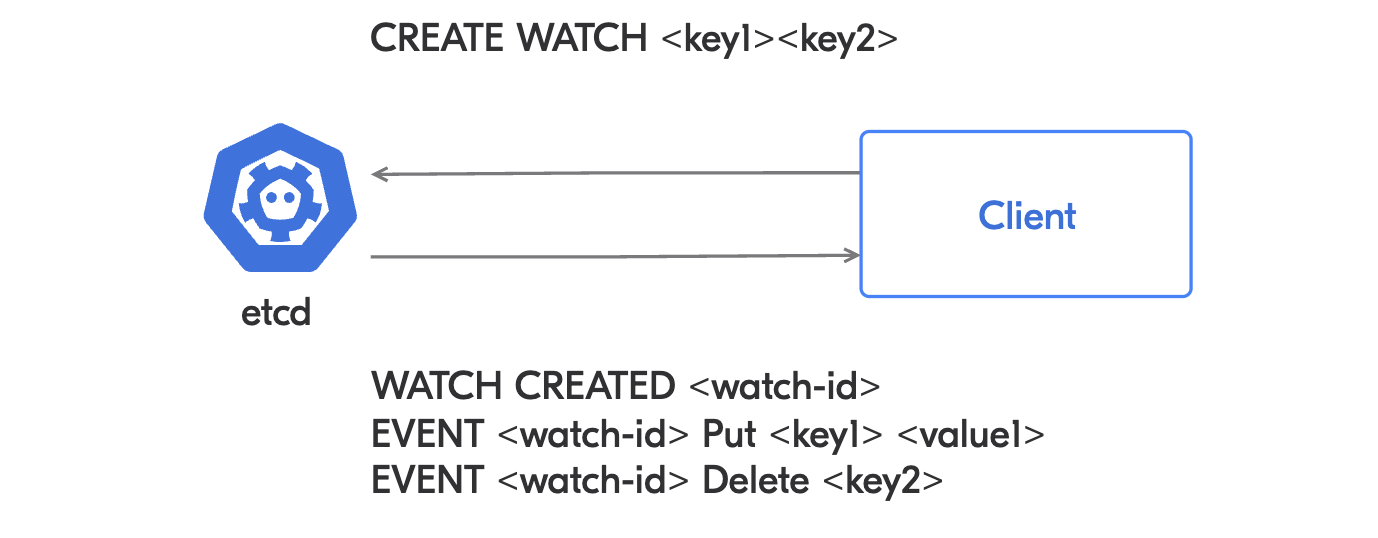
Etcd предоставляет интерфейс, основанный на событиях. Если произойдёт изменение, то наблюдатели будут уведомлены о нём. Понятие ревизий в etcd соответствует версии ресурса в API Server: Revision (etcd)=resourceVersion (API Server).
Между etcd и клиентом поддерживается двунаправленный стрим. Таким образом, клиенты могут установить наблюдение за объектом и получать интересующие ивенты. Клиентом etcd в случае Kubernetes является API Server.
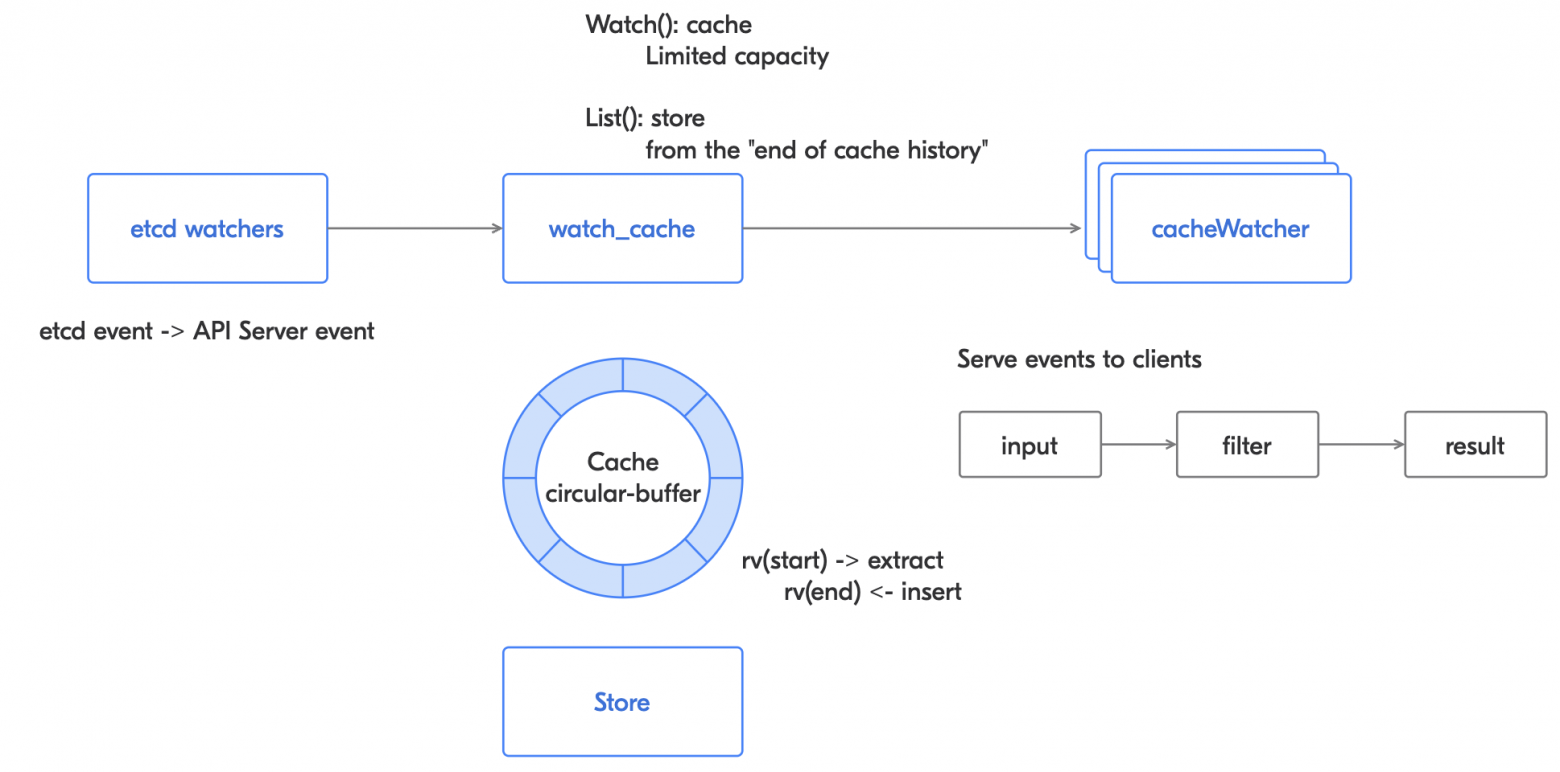
В API Server etcd watchers получают ивент, преобразовывают его из etcd-ивента в ивент API Server, а затем ивент попадает в watch_cache, который отвечает за Watсh- и List-интерфейсы.
Watch_cacheWatch_cache состоит из закольцованного буфера и хранилища. Когда ивент приходит, он записывается в кольцевой кеш. Если кеш полный, то новый ивент будет записан поверх самого старого. Когда вы устанавливаете наблюдение, то оно начинается с какой-то конкретной версии объекта. Если версия объекта слишком старая (её уже нет в кольцевом кеше), то происходит обращение в store, откуда получается нужная версия объекта.
Затем в дело вступают cacheWatchers, которые предоставляют ивенты для каждого клиента.
Далее нам надо понять пункт назначения каждого из ивентов. И тут на сцену выходит client-go — Kubernetes-пакет, который содержит множество клиентских библиотек (Dynamic Client, Clientset, REST Client, Informers и др.) и позволяет обращаться к кластеру Kubernetes.
Нас с вами интересует Informers. Это решение разработано специально для использования контроллерами и пользовательскими операторами и является частью client-go. Informer представляет собой in-memory cache событий в Kubernetes. Между Informers и API Server устанавливается постоянное соединение.

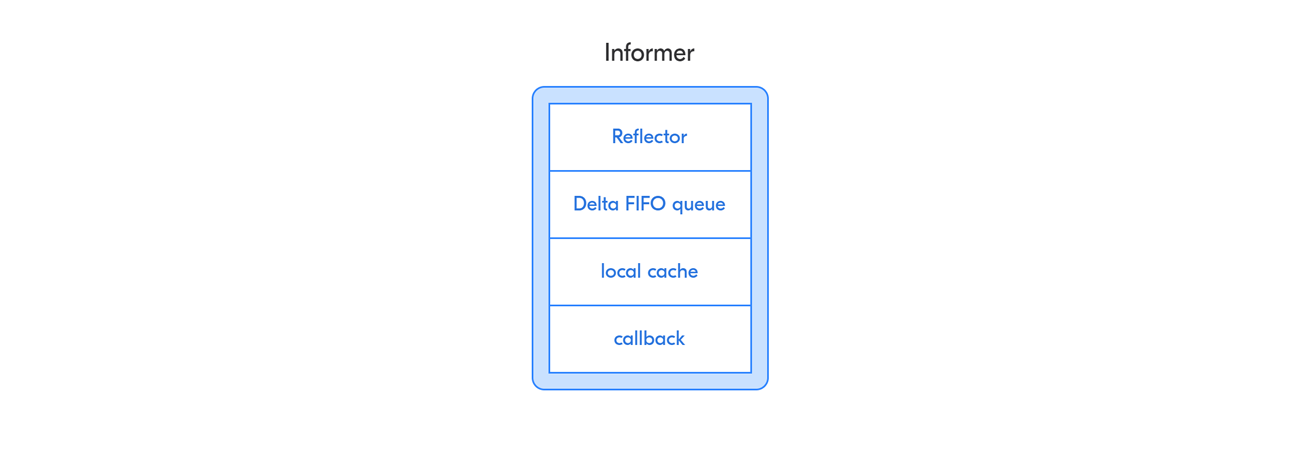
Рефлектор (Reflector) наблюдает за ивентами и запрашивает актуальное состояние интересующих объектов у Kubernetes API, затем складывает их в очередь (Delta FIFO), которая вызывает необходимые колбэк-функции, и далее каждый объект из очереди попадает в локальный кеш. Он хранит информацию о всех интересующих нас объектах в кластере. В информере хранится не сам объект, а его метаинформация.
Одна инсталляция информерa создаёт кеш именно для себя. Но в реальности за одним ресурсом могут наблюдать много контроллеров, и создание отдельных информеров опять приводит к нагрузке на Kubernetes API и к проблемам синхронизации разных контроллеров. Для решения этих проблем был разработан shared informer, который создаёт один кеш, к которому обращаются разные контроллеры.
Мы можем зарегистрировать набор колбэк-функций, которые будут вызываться Informers при соответствующем ивенте (добавление, удаление, обновление ресурса).
job.Informer().AddEventHandler(
ResourceEventHandler {
OnAdd(obj interface{})
OnUpdate(oldObj interface{}, newObj interface{})
OnDelete(obj interface{})
}
)Колбэк-функции должны работать быстро, так как наша очередь конечна. Обычно они складывают элементы в рабочую очередь контроллера, и уже после этого воркеры обрабатывают эту новую очередь.
Для каждой колбэк-функции информер доставляет события последовательно, но не обеспечивает никакой координации и последовательности между самими функциями.
Перед началом работы контроллер убеждается, что кеш в информере готов к работе, и только после этого начинает обработку событий.
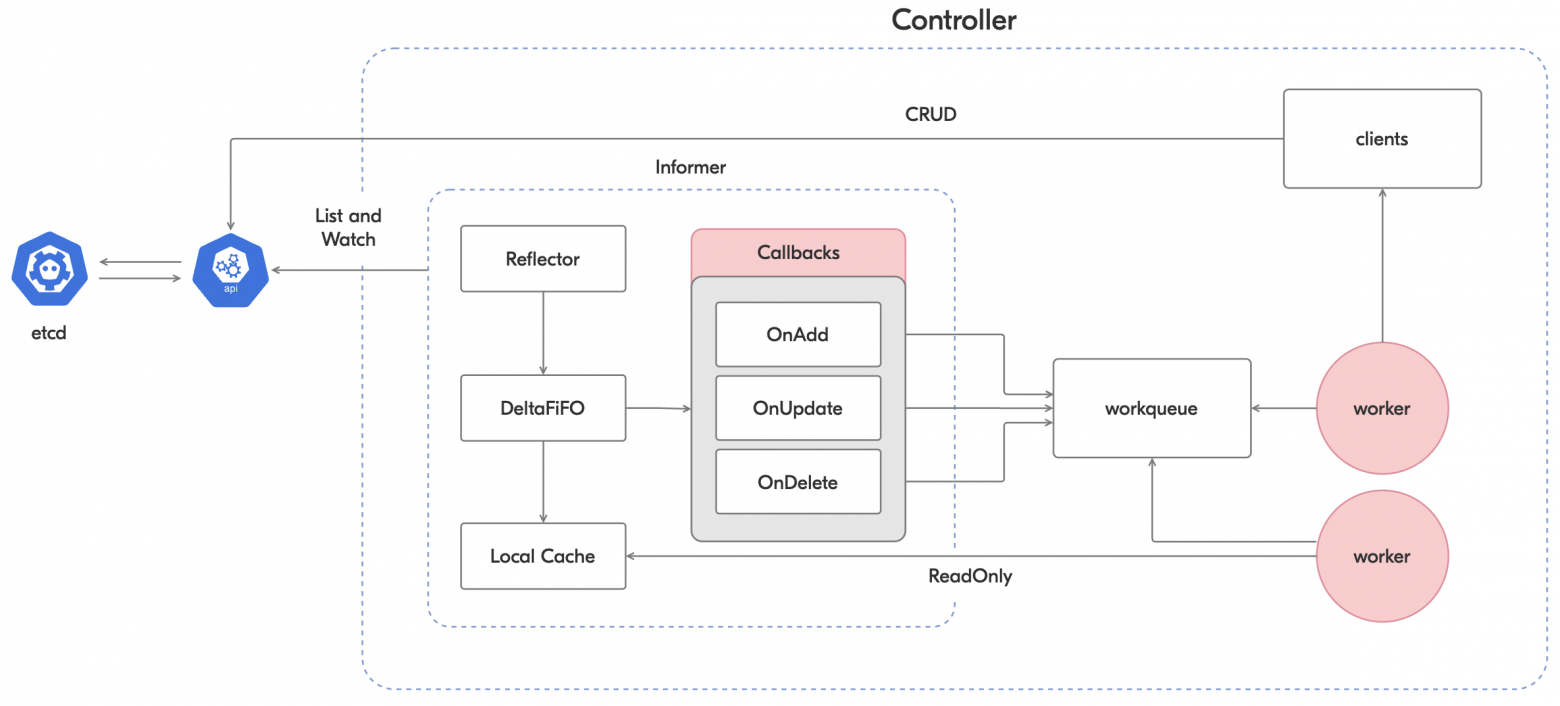 Упрощённая схема контроллера с информером
Упрощённая схема контроллера с информером
Подробную схему взаимодействия контроллера и информера с разбором смотрите в доке.
Что там про CronJob Controller v2?

Как же всё устроено в CronJob Controller? Есть одна очередь для кронов, два информера — для CronJobs и для Jobs — и колбэк-функции для них.
Колбэк-функции для job informer:
jobInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: jm.addJob,
UpdateFunc: jm.updateJob,
DeleteFunc: jm.deleteJob,
})Все эти колбэк-функции сводятся к тому, что в случае появления ивента, связанного с джобой, необходимо найти CronJob, который является родителем для данной Job, и добавить его в очередь.
Затем регистрируются колбэк-функции для cronJob informer:
cronJobsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
jm.enqueueController(obj)
},
UpdateFunc: jm.updateCronJob,
DeleteFunc: func(obj interface{}) {
jm.enqueueController(obj)
},
})Как мы видим, при ивентах создания и удаления у нас идёт сразу добавление элемента в рабочую очередь. Для ивентов обновлений сначала происходит запрос объектов из кеша и их детальное сравнение, после чего принимается решение о добавлении обновлённого объекта в очередь.
Затем воркер берёт каждый крон из очереди, синхронизирует объект (помним, что мы не единственный контроллер во вселенной и кто-то мог раньше нас изменить наш объект в ответ на ивент). Во время синхронизации выполняются проверки нашего описания крона, чтобы понять, надо его запустить или остановить, и т. п.
Функция синхронизации возвращает время, через которое крон должен быть снова добавлен в очередь, и статус ресинхронизации. В случае успешного завершения синхронизации крон будет удалён из текущей очереди и снова добавлен в неё через установленный промежуток времени.
requeueAfter, err := jm.sync(ctx, key.(string))
// AddAfter adds an item to the workqueue after the indicated duration has passed
jm.queue.AddAfter(key, *requeueAfter)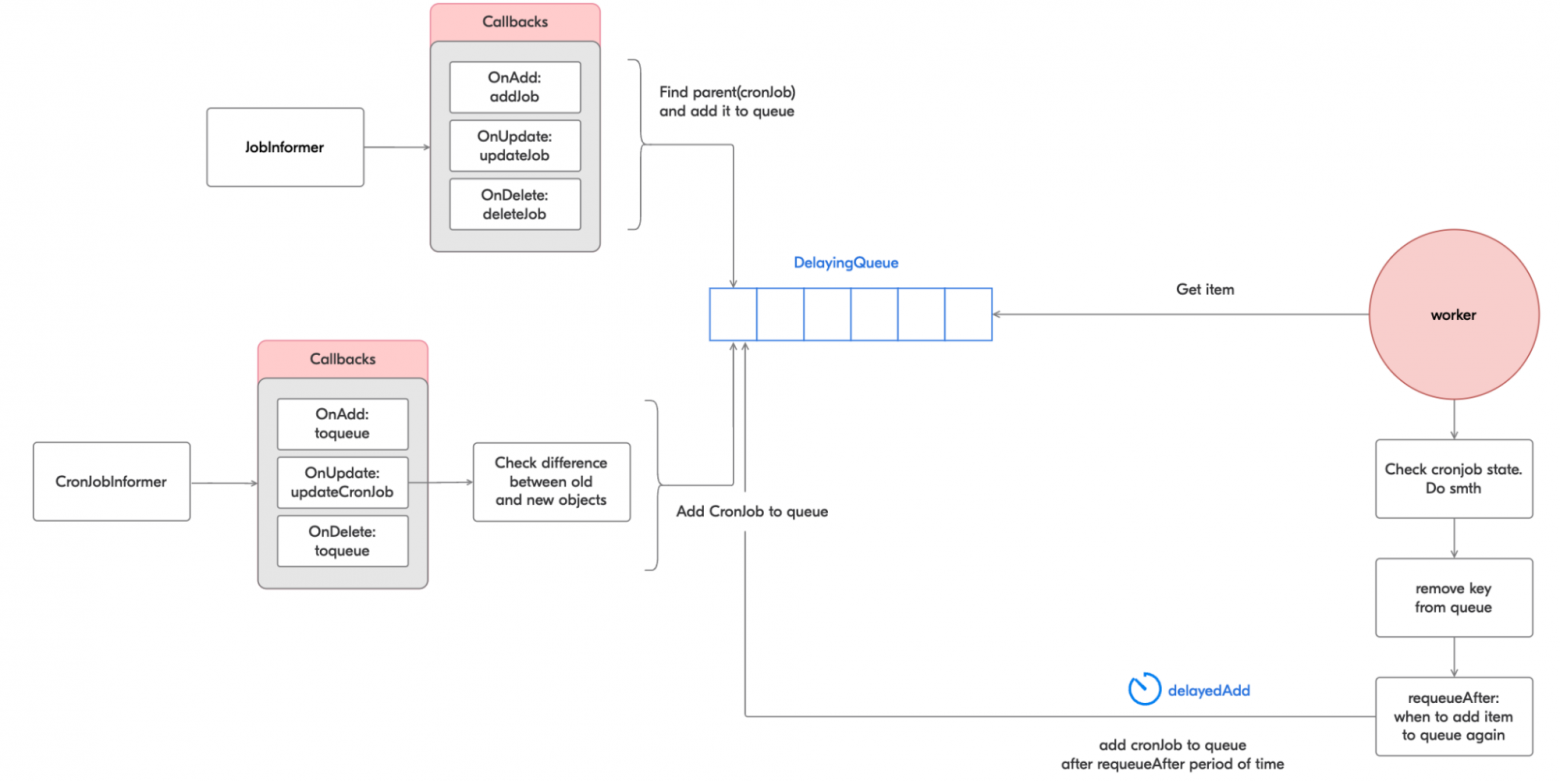 Схема контроллера
Схема контроллера
Кстати, в новом контроллере появилась метрика cronjob_job_creation_skew_duration_seconds, которая показывает промежуток времени между моментами, когда крон должен был быть запущен и когда дочерняя джоба реально была запущена.
Почему же в первой версии контроллера не использовались shared informers, если они такие крутые? Всё просто: когда был написан данный контроллер, их просто ещё не существовало [7].
Вывод, что ли?
Введение мониторинга показало нам, что кроны используются чаще, чем мы думали, и в целях, которые мы даже не могли представить. Разработчики просто хотят, чтобы они работали. При этом они, сами того не понимая, насиловали Kubernetes:
Очень часто создавали кроны, которые работали дольше, чем интервал запуска. Например, крон работал 10 минут, а хотели, чтобы он запускался каждые 3 минуты.
Заставляли кроны работать постоянно.
Разворачивали сервисы, которые требуют очень много ресурсов, но там запускается полезная работа по тикеру каждые 6 часов.
Пишут кроны, которые имеют интервал запуска меньше 5 минут.
Все эти крайности создают нагрузку на Kubernetes: у нас работает CronJob Controller, Job Controller, поды надо куда-то и как-то шедулить, выделять ресурсы (CPU, memory), выделять IP-aдрес поду. Всё это делает актуальным вопрос грамотной утилизации ресурсов.
Источники вдохновения
Что такое крон: официальная дока.
Контроллеры в Kubernetes.
Подробный разбор параметров CronJob.
Параметры джобы.
Про усталость старого CronJob Controller.
Видос про информеры с родины Махатмы Ганди.
Про контроллеры и информеры от первого лица.
Взаимодействие между информером и контроллером под капотом.
Ещё про контроллеры.
Код CronJob Controller v1.
Большая схема с IndexedInformers.
Про ивенты в Kubernetes.
Моё выступление с прошедшей DevOpsConf:
