Консультант+: небольшое улучшение выдачи. Шрифт, стили, выравнивание текста в python
«Консультант+» — справочная система для юристов, бухгалтеров и так далее. Работает стабильно, как часы. В этом посте предлагается немного эти часы настроить под свои нужды в части выдачи текста, а именно: взглянуть как можно переработать с помощью python текстовую информацию, которую выдает система. Попутно поработать с элементами текста, заявленными в заголовке.
Тень на плетень
Мне, как юристу, достаточно долго проработавшему со справочной программой «Консультант+», всегда не хватало обыкновенной функции в этой системе. Данная функция заключалась в следующем. При появлении каких-либо изменений в нормативном акте, сотрудники К+ выкладывают обзор изменений в виде двух столбцов текста:

Столбец слева — то, что было ранее, справа столбец — норма, которая действует теперь. Сейчас (лет эдак n назад) функционал обновили и изменения выделяются жирным шрифтом и их сразу видно. Это все очень удобно. Но есть и неудобные вещи.
Во-первых, некоторые нормы не приводятся, т.к. их объем слишком велик для сотрудников К+ и приходится ходить по ссылкам системы, во-вторых, нельзя просто взять и скопировать эти два столбца, вставив их в обычный excel или word-таблицу.
Возможно, это сделано намеренно, чтобы пользователи активнее работали с системой, в том числе ничего оттуда не переносили.
Что ж придется это исправить.
Задача: разнести текст по двум столбцам, где это возможно, а где нет — просто изъять норму и все это поместить в таблицу Excel. Заодно, посмотрим как можно изменить в тексте при помощи python шрифт, выравнивание и прочую мелочь.
Для примера, который скормим нашей будущей программе, возьмем из К+ изменения в Закон «Об АО». Этот закон часто меняют, поэтому будет с чем поработать.
Сохраним изменения в обычном txt файле (например, редакция.txt). Получится примерно следующее:

Итак, видно, что каждое изменение отделено от другого сплошной чертой, которая после сохранения приняла вид многочисленных »???». Так же имеется заголовок изменения, с которым придется считаться. Все выглядит просто за исключением отдельных моментов.
Так, попадаются изменения, которые имеют следующий вид:

Кроме того, дело усугубляется тем, что отдельные изменения существенно отличаются по длине.
Приступим к К+.
Создадим новый файл consult.py и внесем в него первые строки:
from __future__ import unicode_literals
import codecs
import openpyxl
Модуль openpyxl уже знаком, он позволяет работать с Excel, а вот два других новые. Их функция корректно обработать русские символы, которые зачастую некорректно читаются программами.
Заранее создадим новый пустой файл excel вне программы, назвав его например редакция2.xlsx. Данный файл мы будем открывать нашей программой и записывать туда данные. Это будет наш итоговый файл. В файл редакция.txt поместим
Итак, программа открывает excel файл, заходит в него:
wb = openpyxl.load_workbook('редакция2.xlsx')
sheet=wb.get_active_sheet()
x=1
y=0
test=[]
test2=[]
test3=[]
Также выше мы создаем 3 пустых списка, куда будем собирать данные: test, test2, test3.
Далее в переменную «а» мы поместим все, что может попасться в виде наименования изменения. В y — будет разделительная черта. Она одинакова по длине:
a=('Изменение','Дополнение','Абзац','Пункт','Статья','Наименование','Подпункт')
y='?????????????????????????????????????????????????????????????????????????'
Теперь самое интересное.
with open ('редакция.txt',encoding='cp1251') as f:
lines = (line.strip() for line in f)
for line in lines:
if line.startswith('старая'):
continue
col1=line[:35]
col2=line[39:]
col3=line[35:39]
if line.startswith(a):
sheet.cell(row=x, column=1).value=line #записали строку заголовок изменения,дополнения и т.п.
sheet.cell(row=x, column=1).font=ft2
#sheet.cell(row=x, column=1).style='20 % - Accent3'
x+=1 # или x+=2
elif line==None:
continuewith open ('редакция.txt',encoding='cp1251') as f:
lines = (line.strip() for line in f)
for line in lines:
if line.startswith('старая'):
continue
col1=line[:35]
col2=line[39:]
col3=line[35:39]
if line.startswith(a):
sheet.cell(row=x, column=1).value=line #записали строку заголовок изменения,дополнения и т.п.
x+=1 # или x+=2
elif line==None:
continue
Мы открыли файл редакция.txt в кодировке cp1251. Каждую строку очистили от пробелов с конца и начала методом strip.
Если строка начинается со слова «старая» мы ее пропускаем. Зачем нам сохранять «старая» и «новая», это и так ясно. Далее мы делим строку: с начала и до 35 знака и с 39 знака и до конца. То есть мы исключаем пробел в середине:

Содержимое пробела в середине строки мы заносим в col3, т.к. это может быть и не пробел, если изменение записано в одну строчку всплошную:

Далее, если строка начинается с заголовка изменения (эти заголовки мы записали в переменную а), то мы сразу пишем эту строку в excel без каких-либо дроблений и добавляем строку — x+=1 (или x=x+1).Пустые строки, которые нам попадаются, мы пропускаем.
Рассмотрим следующий фрагмент кода:
if len(col2)==0: # чтобы в 1-й столбец не попадали куски 2-го
if line.startswith(a):
continue
test2.append(col1)
#test3.append(col1)
if col3==' ' and col2!=None:
test.append(line[:35])
test2.append(line[39:])
if col3!=' ' and line!=y and len(line)>60:
#print(test3)
test3.append(line)
if line==y: # пишем в ячейки, что собрали
if test!=None:
sheet.cell(row=x, column=1).value=(' '.join(test).strip('\?'))
sheet.cell(row=x, column=1).font=ft
sheet.cell(row=x, column=1).alignment=al
sheet.cell(row=x, column=2).value=(' '.join(test2).strip('\?'))
sheet.cell(row=x, column=2).font=ft
sheet.cell(row=x, column=2).alignment=al
test=[]
test2=[]
x+=1
if len(test3)>0:
#print(len(test3))
sheet.cell(row=x, column=2).value=(' '.join(test3).strip('\?'))
sheet.cell(row=x, column=2).font=ft
sheet.cell(row=x, column=2).alignment=al
test3=[]
x+=1
else:
continue
Если длина 2 части строки равна 0, то есть ее нет, то в test2 попадает первая часть строки. Если пробел в строке есть, а вторая часть строки отсутствует, то в test и test2 попадают первая и вторая часть строки соответственно.
Если пробел в строке есть, и строка не пустая и ее длина более 60 символов, то она добавляется в test3.
Если строка пустая, то есть мы прошлись по всему изменению, то мы записываем в excel ячейки все, что собрали, попутно проверяя пустоту в test (чтобы он был не пустой) и длину test3.
В конце, сохраняем файл excel:
wb.save('редакция2.xlsx')Стили, font и выравнивание текста в python
Добавим немного красоты в нашу таблицу.
В частности, сделаем так, чтобы при выводе данных заголовки изменений были выделены жирным шрифтом, а сам текст был помельче и отформатирован для удобства восприятия.
Python позволяет это сделать. Для этого нам надо дополнить и изменить код в местах, где мы производим запись результатов в excel файл:
from openpyxl.styles import Font, Color,NamedStyle, Alignmental= Alignment(horizontal="justify", vertical="top")
ft = Font(name='Calibri', size=9)
ft2 = Font(name='Calibri', size=9,bold=True)if line.startswith(a):
sheet.cell(row=x, column=1).value=line #записали строку заголовок изменения,дополнения и т.п.
sheet.cell(row=x, column=1).font=ft2if line==y: # пишем в ячейки, что собрали
if test!=None:
sheet.cell(row=x, column=1).value=(' '.join(test).strip('\?'))
sheet.cell(row=x, column=1).font=ft
sheet.cell(row=x, column=1).alignment=al
sheet.cell(row=x, column=2).value=(' '.join(test2).strip('\?'))
sheet.cell(row=x, column=2).font=ft
sheet.cell(row=x, column=2).alignment=alif len(test3)>0:
#print(len(test3))
sheet.cell(row=x, column=2).value=(' '.join(test3).strip('\?'))
sheet.cell(row=x, column=2).font=ft
sheet.cell(row=x, column=2).alignment=al
То есть, по сути у нас добавились только применимые методы .font и .alignment.
Полностью программа приняла вид:
from __future__ import unicode_literals
import codecs
import openpyxl
from openpyxl.styles import Font, Color,NamedStyle, Alignment
"""
1.из файла Consultant+ с таблицей изменений, сохраненного в обычном .txt
вида
?????????????????????????????????????????????????????????????????????????
Изменение подпункта 15 пункта 1 статьи 48
старая редакция новая редакция
15) принятие решений об 15) принятие решений о
делает excel таблицу с двумя столбцами.
в word сохранить файл как обычный текст - txt
на вход: редакция.txt
на выходе: редакция2.xlsx
"""
#file = open ( 'редакция2.txt', 'w',encoding='cp1251', newline = '\n')
wb = openpyxl.load_workbook('редакция2.xlsx')
sheet=wb.get_active_sheet()
x=1
y=0
test=[]
test2=[]
test3=[]
a=('Изменение','Дополнение','Абзац','Пункт','Статья','Наименование','Подпункт')
y='?????????????????????????????????????????????????????????????????????????'
#стили ячеек
#al= Alignment(horizontal="distributed", vertical="top")
al= Alignment(horizontal="justify", vertical="top")
ft = Font(name='Calibri', size=9)
ft2 = Font(name='Calibri', size=9,bold=True)
with open ('редакция.txt',encoding='cp1251') as f:
lines = (line.strip() for line in f)
for line in lines:
if line.startswith('старая'):
continue
col1=line[:35]
col2=line[39:]
col3=line[35:39]
if line.startswith(a):
sheet.cell(row=x, column=1).value=line #записали строку заголовок изменения,дополнения и т.п.
sheet.cell(row=x, column=1).font=ft2
#sheet.cell(row=x, column=1).style='20 % - Accent3'
x+=1 # или x+=2
elif line==None:
continue
#print (line)
#print (len(col2))
if len(col2)==0: # чтобы в 1-й столбец не попадали куски 2-го
if line.startswith(a):
continue
test2.append(col1)
#test3.append(col1)
if col3==' ' and col2!=None:
test.append(line[:35])
test2.append(line[39:])
if col3!=' ' and line!=y and len(line)>60:
#print(test3)
test3.append(line)
if line==y: # пишем в ячейки, что собрали
if test!=None:
sheet.cell(row=x, column=1).value=(' '.join(test).strip('\?'))
sheet.cell(row=x, column=1).font=ft
sheet.cell(row=x, column=1).alignment=al
sheet.cell(row=x, column=2).value=(' '.join(test2).strip('\?'))
sheet.cell(row=x, column=2).font=ft
sheet.cell(row=x, column=2).alignment=al
test=[]
test2=[]
x+=1
if len(test3)>0:
#print(len(test3))
sheet.cell(row=x, column=2).value=(' '.join(test3).strip('\?'))
sheet.cell(row=x, column=2).font=ft
sheet.cell(row=x, column=2).alignment=al
test3=[]
x+=1
else:
continue
wb.save('редакция2.xlsx')
Итак, в итоге, после обработки файла программой, мы имеем вполне приличную таблицу с изменениями в законе:
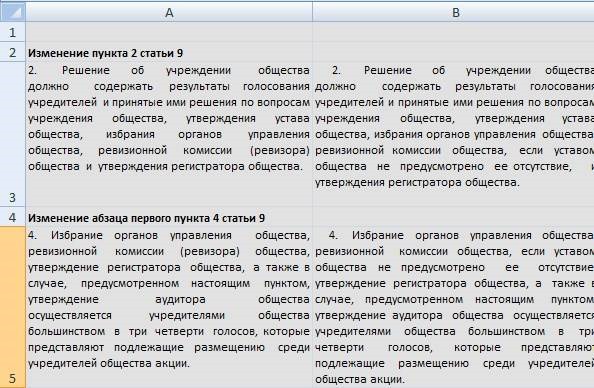
Программу можно скачать по ссылке — здесь.
Пример файла для обработки программой — здесь.
