Конференция для фанатов DevOps-подхода
Речь, конечно, о DevOpsConf. Если не вдаваться в детали, то 30 сентября и 1 октября мы проведем конференцию об объединении процессов разработки, тестирования и эксплуатации, а если вдаваться — прошу под кат.
В рамках DevOps-подхода все части технологического развития проекта переплетены между собой, происходят параллельно и влияют друг на друга. Особую значимость здесь приобретает создание автоматизируемых процессов разработки, которые можно менять, моделировать и тестировать в реальном времени. Это помогает моментально реагировать на изменения в рынке.
На конференции мы хотим показать, как влияет такой подход на развитие продукта. Как обеспечивается надежность и адаптивность системы для клиента. Как DevOps меняет структуру и подход компании к организации рабочего процесса.

Закулисье
Нам важно знать не только, что делают разные компании в рамках DevOps-подхода, но и понимать, зачем вот это вот всё. Поэтому в состав Программного комитета мы позвали не просто экспертов, а специалистов, которые видят DevOps-дискурс с разных позиций:
- senior-инженеров;
- разработчиков;
- тимлидов;
- CTO.
С одной стороны, это создаёт сложности и конфликты при обсуждении заявок на доклады. Если инженеру интересен разбор крупной аварии, то разработчику важнее понять, как создать софт, работающий в облаках и инфраструктурах. Но договариваясь, мы создаём такую программу, которая будет ценна и интересна всем: от инженеров до CTO.

Задача нашей конференции не просто выбрать доклады похайповее, но представить общую картину: как работает DevOps-подход на практике, на какие грабли можно нарваться при переходе к новым процессам. При этом мы выстраиваем контентную часть, спускаясь от бизнес-задачи к конкретным технологиям.
Секции конференции останутся теми же, что и в прошлый раз.
- Инфраструктурная платформа.
- Инфраструктура как код.
- Непрерывная поставка.
- Обратная связь.
- Архитектура в DevOps, DevOps для CTO.
- SRE-практики.
- Обучение и управление знаниями.
- Безопасность, DevSecOps.
- DevOps-трансформация.
Call for Papers: какие доклады мы ищем
Потенциальную аудиторию конференции мы условно разделили на пять групп: инженеры, разработчики, специалисты по безопасности, тимлиды и CTO. У каждой группы своя мотивация прийти на конференцию. И, если посмотреть на DevOps с этих позиций, можно понять, как сфокусировать свою тему и где расставить акценты.
Для инженеров, которые занимаются созданием инфраструктурной платформы, важно разобраться в существующих трендах, понять, какие технологии сейчас самые продвинутые. Им будет интересно ознакомиться с реальным опытом использования этих технологий и обменяться мнениями. Инженер с удовольствием выслушает доклад с разбором какой-нибудь хардкорной аварии, мы в свою очередь такой доклад постараемся подобрать и отшлифовать.
Для разработчиков важно разобраться с таким понятием, как cloud native application. То есть как надо разрабатывать софт, чтобы он работал в облаках и различных инфраструктурах. Разработчику необходимо постоянно получать обратную связь от программного обеспечения. Здесь мы хотим услышать кейсы о том, как компании выстраивают этот процесс, как нужно мониторить работоспособность ПО и как устроен весь процесс поставки.
Специалистам в области кибербезопасности важно понимать, как настроить процесс обеспечения безопасности таким образом, чтобы он не стопорил процессы разработки и изменений внутри компании. Интересны будут и темы о требованиях, которые DevOps предъявляет к таким специалистам.
Тимлиды хотят знать, как устроен процесс continuous delivery в других компаниях. Каким путём компании к этому шли, как выстраивались процессы разработки, обеспечения качества внутри DevOps. Cloud native тимлидам тоже интересен. А ещё — вопросы о взаимодействии внутри команды и между командами разработчиков и инженеров.
Для CTO самое главное — разобраться, как все эти процессы соединить и подстроить под бизнес-нужды. Он заботится о том, чтобы приложение было надёжным и для бизнеса, и для клиента. И здесь нужно понимать, какие технологии под какие бизнес-задачи будут работать, как выстроить процесс целиком и т.д. CTO отвечает и за бюджетирование. Например, он должен понимать, сколько нужно потратить денег на переобучение специалистов, чтобы они могли работать в DevOps.

Если у вас есть, что сказать по этим поводам, не молчите, подавайте доклад. Крайний срок по Call for Papers — 20 августа. Чем раньше заявитесь, тем больше времени будет на доработку доклада и подготовку к выступлению. Так что, не затягивайте.
Ну, а если потребности выступать публично у вас нет, просто покупайте билет и приходите 30 сентября и 1 октября общаться с коллегами. Обещаем, будет интересно и вдохновляюще.
Как мы видим DevOps
Чтобы точно понимать, что мы вкладываем в понятие DevOps, рекомендую прочитать (или перечитать) мой доклад «Что такое DevOps». Гуляя по волнам рынка, я наблюдал, как трансформируется представление о DevOps в разных по величине компаниях: от небольшого стартапа до транснациональных компаний. Доклад построен на серии вопросов, отвечая на них, можно понять, движется ли ваша компания к DevOps или где-то есть проблемы.
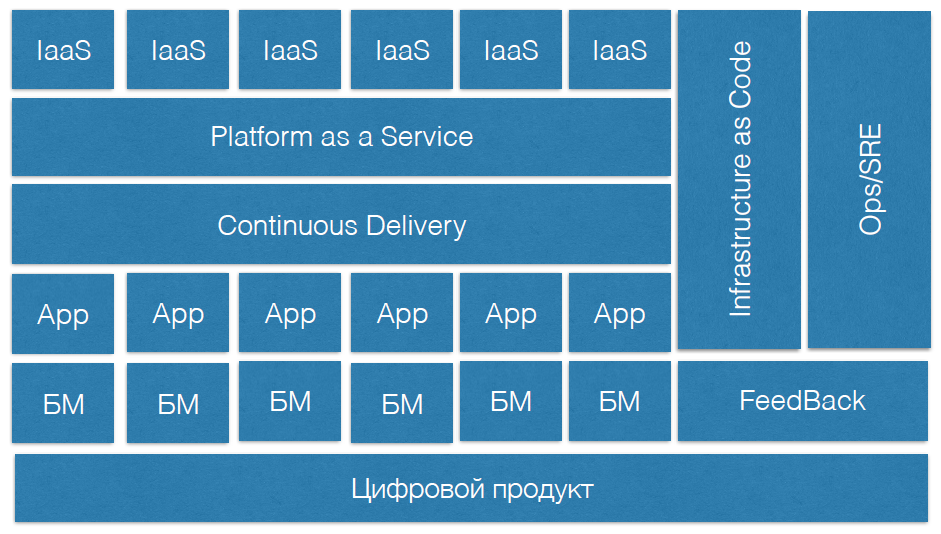
DevOps — это сложная система, в ней должны быть:
- Цифровой продукт.
- Бизнес модули, которые этот цифровой продукт развивают.
- Продуктовые команды, которые пишут код.
- Практики Continuous Delivery.
- Платформы как сервис.
- Инфраструктура как сервис.
- Инфраструктура как код.
- Отдельные практики поддержания надежности, зашитые внутри DevOps.
- Практика обратной связи, которая описывает все это.
В конце доклада есть схема, которая даёт представление о DevOps-системе в компании. Она позволит увидеть, какие процессы в вашей компании уже отлажены, а какие только предстоит выстраивать.
Видео доклада можно посмотреть здесь.
А сейчас будет бонус: нескольких видео с РИТ++ 2019, которые касаются наиболее общих вопросов DevOps-трансформации.
Инфраструктура компании как продукт
Артём Науменко руководит DevOps-командой в Skyeng и заботится о развитии инфраструктуры своей компании. Он рассказал, как инфраструктура влияет на бизнес-процессы в SkyEng: как считать для неё ROI, какие метрики стоит выбрать для подсчёта и как работать над их улучшением.
На пути к микросервисам
Компания Nixys занимается поддержкой нагруженных web-проектов и распределённых систем. Её технический директор Борис Ершов рассказал, как перевести на современные рельсы программные продукты, разработка которых началась лет 5 назад (или даже больше).

Как правило, такие проекты — это особый мир, где есть такие тёмные и древние уголки инфраструктуры, что о них не знают ныне действующие инженеры. А выбранные когда-то подходы к архитектуре и разработке устарели и не могут обеспечить бизнесу прежний темп развития и выпуска новых версий. В результате каждый релиз продукта превращается в невероятное приключение, где постоянно что-то отваливается, причём в самом неожиданном месте.
Руководители таких проектов неизбежно сталкиваются с необходимостью трансформации всех технологических процессов. В своём докладе Борис рассказал:
- как выбрать подходящую для проекта архитектуру и привести в порядок инфраструктуру;
- какие инструменты использовать и какие подводные камни встречаются на пути к трасформации;
- что делать дальше.
Автоматизация релизов или как доставить быстро и без боли
Александ Коротков — ведущий разработчик системы CI/CD в ЦИАН. Он рассказал об инструментах автоматизации, которые позволили повысить качество и сократить время доставки кода в продакшн в 5 раз. Но таких результатов невозможно было бы добиться только одной автоматизацией, поэтому Александр обратил внимание и на изменения в процессах разработки.
Как аварии помогают учиться?
Алексей Кирпичников уже 5 лет занимается внедрением DevOps и инфраструктурой в СКБ Контур. За три года в его компании произошло примерно 1000 факапов разной степени эпичности. Среди них, например, 36% были вызваны выкатыванием некачественного релиза в продакшн, а 14% — работами по обслуживанию железа в дата-центре.
Получать такую точную информацию об авариях позволяет архив отчётов (постмортемы), которые инженеры компании ведут уже несколько лет подряд. Постмортем пишет дежурный инженер, который первым отреагировал на сигнал об аварии и начал всё чинить. Зачем мучать инженеров, которые по ночам сражаются с факапами, написанием отчётов? Эти данные позволяют увидеть картину целиком и двигать инфраструктурную разработку в правильном направлении.
В своём выступлении Алексей поделился, как написать действительно полезный постмортем и как внедрить практику таких отчётов в крупной компании. Если любите истории о том, как кто-то облажался, посмотрите видео выступления.
Мы понимаем, что ваше видение DevOps может не совпадать с нашими представлениями. Будет интересно узнать, как вы видите DevOps-трансформацию. Поделитесь в комментариях своим опытом и видением этой темы.
Какие доклады мы уже приняли в программу?
На этой неделе Программный комитет принял 4 доклада: о безопасности, инфраструктуре и SRE-практиках.
Пожалуй, самая больная тема DevOps-трансформации: как сделать так, чтобы ребята из отдела информационной безопасности не порушили уже выстроенные связи между разработкой, эксплуатацией и администрированием. Некоторые компании обходятся и без отдела ИБ. Как в таком случае обеспечить информационную безопасность? Об этом расскажетМона Архипова из sudo.su. Из её доклада мы узнаем:
- что и от кого нужно защищать;
- каковы рутинные процессы безопасности;
- как пересекаются процессы ИТ и ИБ;
- что такое CIS CSC и как это внедрить;
- как и по каким показателям проводить регулярные проверки ИБ.
Следующий доклад касается развития инфраструктуры как кода. Уменьшить количество ручной рутины и не превратить весь проект в хаос, возможно ли это? На этот вопрос ответитМаксим Кострикин из Ixtens. В его компании используют Terraform для работы с AWS-инфраструктурой. Инструмент удобный, но вопрос в том, как при его использовании избежать появления огромной глыбы кода. Обслуживание такого наследия с каждым годом будет обходиться всё дороже и дороже.
Максим покажет, как работают паттерны размещения кода, нацеленные на упрощение автоматизации и развития.
Ещё один доклад об инфраструктуре услышим от Владимира Рябова из Playkey. Здесь речь пойдёт об инфраструктурной платформе, и мы узнаем:
- как понять, эффективно ли используется объём хранилища;
- как несколько сотен пользователей могут получить по 10 ТБ контента, если используются всего 20ТБ хранилища;
- как сжать данные в 5 раз и предоставлять их пользователям в real-time;
- как налету синхронизировать данные между несколькими дата-центрами;
- как исключить любое влияние пользователей друг на друга при последовательном использовании одной виртуальной машины.
Секрет этой магии — в технологии ZFS для FreeBSD и ее свежем форке ZFS on Linux. Владимир поделится кейсами от Playkey.
Матвей Кукуй из Amixr.IO готов на примерах из жизни рассказать, что такое SRE и как оно помогает строить надёжные системы. Amixr.IO пропускает инциденты клиентов через свой бекенд, десятки дежурных команд по всему миру уже разобрали 150 тысяч случаев. На конференции Матвей поделится статистикой и инсайтами, которые его компания накопила, решая проблемы клиентов и анализируя факапы.
Ещё раз призываю не жадничать и поделиться своим опытом DevOps-самурая. Подавайте заявку на доклад, и у нас с вами будет 2,5 месяца, чтобы подготовить отличное выступление. Если хотите быть слушателем, подпишитесь на рассылку с обновлениями программы и всерьез задумайтесь о заблоговоременном бронировании билетов, потому что ближе к датам конференции они подорожают.
