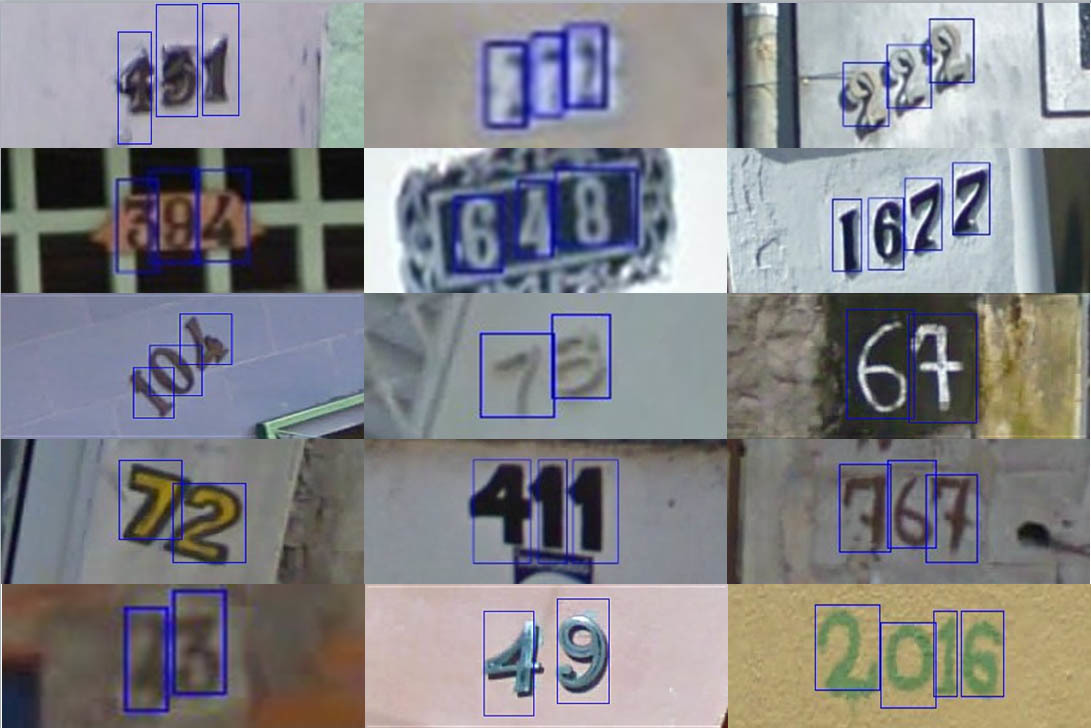Есть одна тема в современном Computer Vision, которая часто остаётся за кадром. В ней нет сложной математики и глубокой логики. Но то что её никак не освещают — вгоняет в ступор многих новичков. А тема не проста: имеет множество граблей, про которые не узнаешь, пока не наступишь.
Тема — называется так: подготовка базы изображений для дальнейшего обучения.
В статье:
Как можно отличить хорошую базу
Примеры хороших баз
Примеры программ, которыми удобно размечать базы
Для начала покажу простой и наиболее любимый свой пример: распознавание автомобильных номеров. Предположим мы делаем систему с нуля. Что мы должны обозначить на этом изображении:
Идеальный вариант, на мой взгляд, такой:
Тут отмечено:
Рамка для каждого номера, которую видно. Ключевой момент: нужно подчеркнуть угол наклона номера + его положение.
Значение каждого номера, который виден. Система не будет распознавать лучше, чем человек, который смотрит на фотографию, так что номера, которые практически нельзя разглядеть можно не обозначать.
Положение каждого символа номера.
Ещё раз: это идеальная разметка. Возможно, она несколько избыточна, но зато на её базе можно настраивать/обучать практически любой алгоритм. Сам я никогда не делал настолько подробную разметку ни в одной задаче, которую решал. Обычно находиться идеальный баланс между тем, что хочется и тем на что есть силы.
Теперь рассмотрим откуда это берётся. И почему этого достаточно. Классический алгоритм выделения номера выглядит следующим образом:
При этом за каждую часть обычно отвечает свой алгоритм или их группа.
Первая часть — нам нужно найти номера. Предположим, что выделение номера мы реализуем через каскад Хаара, или через HOG дескрипторы. Тогда на вход алгоритма обучения нам нужно будет подать набор положительных и отрицательных примеров:
Положительные:
Отрицательные:
Если же мы реализуем поиск номера через какую-нибудь нейронную сеть, то целью обучения сети будет такой набор прямоугольников:
Как видно, из данных, которые мы разметили просто получить оба варианта.
После того как номер найден его нужно обработать. Опять же, тут есть много подходов. Но в целом, вторая часть — это «нормировка номера». Можно сделать алгоритм, ищущий границы в ручную, как описано тут:
Этот алгоритм не требует обучения, но по тем данным которые у нас есть мы сможем оценить его качество работы.
А можно обучить несколько нейронных сетей. Например первая ищет угол, вторая ищет кроп.
И опять. Данных, которые мы разметили — полностью хватает.
Можно объединить часть один и часть два и сделать поисковую сеть для номеров, которая сразу выводит и угол и поворот номера. Для неё данных тоже достаточно.
Принципы
Попробуем сформулировать основные принципы разметки:
1. Заранее обдумайте все возможные алгоритмы, которыми может решаться ваша задача. Определите входные данные для каждого из вариантов. Если это не требует большого количества сил при разметке, придумайте такой формат разметки, который бы обеспечил вам любой из существующих вариантов решения задачи входными данными. Если есть возможность, то лучше, чтобы разметка была избыточна. Иначе, если ваш алгоритм не заработает, придётся делать всё заново.
2. Старайтесь, чтобы разметка была в простом, верифицируемом формате. Помните, что любые задачи компьютерного зрения — достаточно сложны в отладке и в поиске багов. Любая часть должна быть просто визуализируема и проста для проверки глазами. Отдавайте предпочтения текстовым форматам данных или графическим. Старайтесь избегать бинарных форматов, или форматов с большим объёмом метаданных. Старайтесь писать всю возможную информацию. Например не забывайте текстовое название изображения. Если вы используете какую-то функцию «получить список названий файлов» помните, что в Windows, Linux, C#, Python порядок этих файлов может различаться.
3. Помните, что разметка — это длительный процесс. Зачастую разметка большой базы может занимать дни или недели. Монотонного труда. Старайтесь предусмотреть в вашей программе всё что понадобиться.
Примеры баз данных
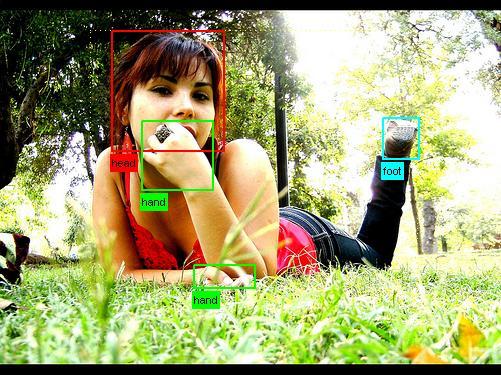
MSRA dataset. MSRA — это целая серия датасетов. Возьмём для примера датасет с детектированием объектов. Для каждой картинки задан ограничивающий прямоугольник объекта на этой картинке:
При этом все параметры лежат в текстовом файле такого вида:
235 - число описанных изображений в файле
0\0_101.jpg - адрес картинки
400 300 - её размер
89 10 371 252; 87 9 379 279; 89 11 376 275; - ограничивающий прямоугольник объекта
0\0_108.jpg
400 300
112 4 241 214; 119 0 241 208; 118 0 238 141;
.....
При этом каждый текстовый файл описывает все объекты одного из классов.
VOC2012 Один из наиболее полных датасетов. Делался в исследовательских целях => старались описать всё хорошо и качественно. До 2012 года датасет обновлялся каждый год (2005–2012). Формат описания: xml.
На каждом изображении отмечаются прямоугольники всех объектов:
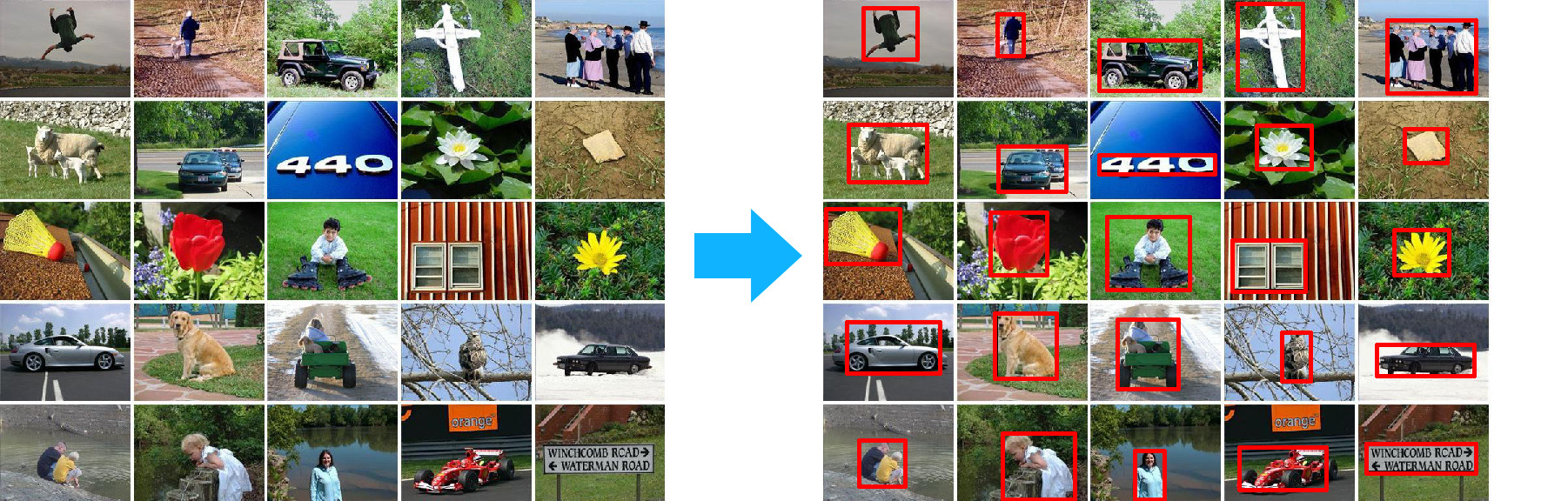
Так же, часть изображений в VOC раскрашены принадлежностью к классу. Задача сегментации (например) требует входных изображений, на которых были бы размечены интересные области. Обычно тип объекта задают цветом:
В данном случае разметка — это по сути раскраска.
CIFAR Исследовательский датасет с небольшими изображениями. Пример неудобного датасета. Все картинки лежат в одном большом файле. Там же и их описания. Для доступа к файлу есть обёртки под Питон и под Матлаб. Описание картинки — номер класса. Больше ничего в датасете нет. Когда-то датасет был популярным. Но был неудачным по формату проектирования. Сейчас его редко кто использует.
The Street View House Numbers (SVHN) Dataset Известный датасет с номерами домов от гугла.
Формат описания — бинарный матлабовский файл для каждого изображения. В файле — прямоугольник ограничивающий цифру и значение цифры.
MS COCO Датасет от Майкрософта. Наверное один из лучших на сегодняшний день. По составу — примерно как VOC, но больше данных, сильно больше информации о разметке.
Информация храниться в сопроводительных json-файлах. Вот пример как аннатируется:
Один из интересных моментов датасета. Области сегментации задаются не картинкой, их заливающей, а замкнутым полилайном, который храниться в том же json-файле. Это значительно уменьшает объем данных. Хотя и ухудшает качество разметки.
Второй момент — для каждой из картинок есть текстовое описание происходящего.
The Citycapes Dataset Набор датасетов для чисто сегментационной задачи: разметить всё происходящее на улицах. Для каждой картинки вторая картинка с разметкой. В отдельном файле описание что значит каждый цвет.
kaggle На каггле много датасетов и они всегда разные под разные задачки. Это пример того, как надо делать датасеты. Все датасеты максимально просты. Есть 10 классов? Вот они лежат по папочкам без лишних текстовиков. Нужно что-то обнаружить? Вот сегментационная разметка.
IMAGENET Огромный, но безблагодатный датасет. Если честно, так и не смог окончательно разобраться в всех доступных для него описаниях. Большинство описаний в mat-файлах. Задача распознавания требует классификации изображённых данных. Так что создатели решили давать полную классификацию каждому изображению:
Набор биометрических датасетов от CASIA. Тут всё замечательно просто. Датасеты для алгоритмов биометрии. Для каждого человека отдельная папочка, внутри которой всё разложено как по нотам: разные спектры, множество подходов.
KITTI Набор самых разных датасетов снятых с автомобиля. Для каждой картинки свой собственный текстовичёк с описанием:
Описание — пример хорошего датасета. Тут задано всё: насколько объект перекрыт, границы объекта. Насколько объект повёрнут к камере, какие реальные координаты объекта по глубине. Но, как я понимаю, большинство исследователей пользуются только координатами рамки объекта.
Кроме изображений с разметкой прямоугольников в датасете есть много интересной информации. Тут есть стереопары для дорожной обстановки.
Есть оптический поток для каждого кадра, который в каждой точке задаёт цвет, кодирующий направление и скорость движения (1), (2):
В этом датасете много интересно и правильно заданной информации.
Существует огромное множество датасетов которые я здесь не упомянул. Главное, что их объединяет: если датасет серьёзный — он хорошо сделан. С ним удобно работать. Когда будете делать датасеты под свои задачи — не забывайте об этом.
Удобство оператора
Даже если базу размечаете не вы — не забывайте об удобстве оператора, который будет размечать. Удобство оператора = скорость работы + качество разметки. Вот несколько советов:
• Старайтесь дублировать все возможные операции на клавиатуре. Оставляйте на мышь только операции выделения объектов на изображении. Это повышает скорость работы в разы.
• Постоянно сохраняйте работу. Не держите её в памяти программы. Так как программы разметки часто пишутся на коленке — вылеты возможны. Обидно потерять 5000 размеченных изображений.
• Сделайте возможность редактирования размеченных данных. Ошибок не избежать.
• Не давайте оператору лишних инструментов. Всё должно быть просто, все углы должны быть срезаны. У вас 3 типа объектов? Не надо давать оператору программу где можно разметить 10 типов. Ваш девиз — «только необходимость и достаточность».
Пара примеров
Я привожу тут несколько примеров, которые я использовал в разных задачах. Написаны на C# + с подключением EmguCV для работы с изображениями (знаю, что избыточно, но так было проще).
В репозитории 2 программы — одна для раскраски изображений под задачи сегментации, вторая для рисования прямоугольников. Ничего сверхъестественного, но может кому-то понадобятся.
Прочее
Мне понравился сервис Яндекса — Толока. Частично он может решить вопросы разметки базы. Но, нужно сказать, что сильно не всё из описанного в нём есть.