Как программист машину покупал. Часть II
На первом этапе в качестве метода машинного обучения была выбрана множественная линейная регрессия, были рассмотрены правомерность ее использования, а также плюсы и минусы. Простая линейная регрессия была выбрана в качестве ознакомительного алгоритма. Очевидно, что существует еще много методов машинного обучения для решения поставленной задачи регрессии. В этой статье я хотел бы рассказать вам, как именно я выбирал наиболее оптимальный алгоритм машинного обучения для исследуемой модели, который в настоящее время используется в реализованном мною сервисе — robasta.ru.

Выбор алгоритма
Претенденты на звание «чемпиона»:
- Множественная линейная (простая) регрессия
- Лассо-регрессия
- Ридж-регрессия
- Робастная регрессия
- Vowpal Wabbit
- Полиномиальная и нелинейная регрессии
- Random forest
- Xgboost
Прежде чем сделать выбор, были исследованы все вышеизложенные алгоритмы, поэтому хотел подробно рассказать вам о каждом из них. Однако, такой путь перебора «в лоб» не совсем оптимален, разумнее сначала провести дополнительные исследования поставленной задачи.
Помимо Mercedes-Benz E-klasse мне импонировала Audi A5, особенно с дизельным двигателем мощностью 239 л.с., обладающая хорошей динамикой (6 сек. до 100 км/ч) и приемлемым налогом. Взглянув на зависимость цены от мощности двигателя этого творения немецких инженеров (визуализация ниже), многие вопросы отпадают сами собой.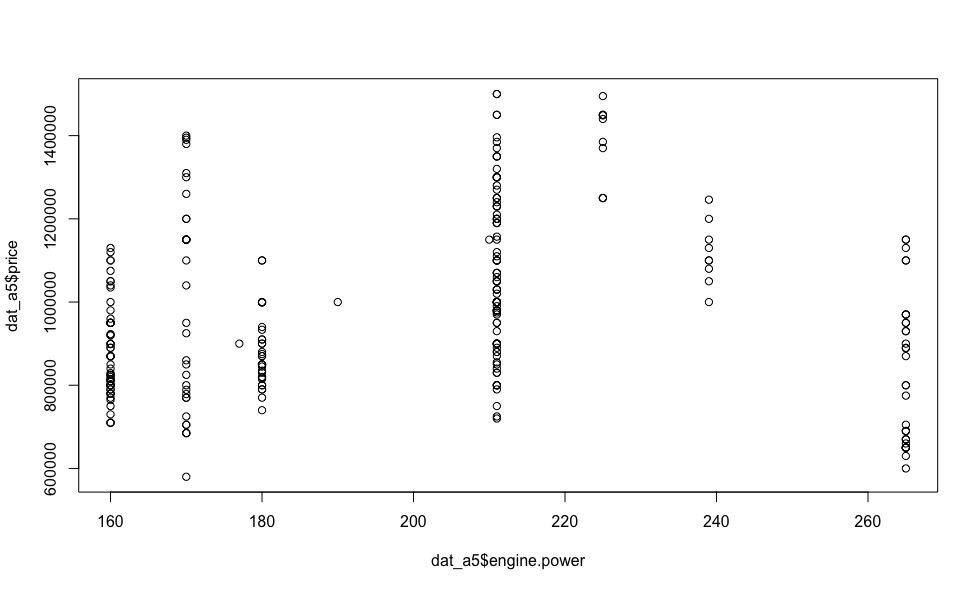
О линейной зависимости тут не может идти и речи, поэтому алгоритмы, в основе которых лежит линейная зависимость объясняемой переменной (стоимости, в нашем случае) от регрессоров, можно смело отбросить. Использование полиномиальных и нелинейных моделей неправомерно по той причине, что заранее неизвестен вид зависимости того или иного регрессора от цены для каждой отдельной взятой модели автомобиля.
Таким образом, приняв вышеизложенные рассуждения во внимание, нам остается рассмотреть только алгоритмы, в основе которых лежат деревья принятия решений — Random forest и Xgboost (с двумя видами бустинга — xgbDart, xgbTree), и выбрать из них оптимальный.
Следует оговориться, что оптимальный алгоритм — это тот, который покажет себя наилучшим образом (min RMSE) при перекрестной проверке (cross-validation) и отложенной выборке.
Прежде чем переходить к «слепому» применению выбранных алгоритмов, в следующей главе я хотел бы более подробно осветить вопрос их настройки.
Cross-validation
Для оценки реальных возможностей модели и настройки ее параметров в задачах машинного обучения зачастую используют перекрестную проверку (Cross-validation, СV). Выделяется некоторое множество разбиений исходной выборки на обучающую и контрольную подвыборки. Для каждого из разбиений алгоритм настраивается по обучающей подвыборке, затем на контрольной оценивается его средняя ошибка.
Оценкой перекрестной проверки называется средняя по всем разбиениям величина ошибки на контрольных подвыборках.
Для несмещенности оценки вероятности ошибки, полученной посредством кросс-валидации, необходимо, чтобы обучающая и контрольная выборки образовывали непересекающееся подмножество, во избежании явления переобучения.
Разновидности перекрестной проверки:
- k-блочная кросс-валидация (k-fold cross-validation). ПодробнееЭтот метод случайным образом разбивает данные на k непересекающихся блоков примерно одинакового размера. Поочередно каждый блок рассматривается как валидационная выборка, а остальные k-1 блоков — как обучающая выборка. Модель обучается на k-1 блоках и прогнозирует валидационный блок. Прогноз модели оценивается с помощью выбранного показателя: правильность (accuracy), среднеквадратическое отклонение (СКО, RMSE) и т.п. Процесс повторяется k раз, и мы получаем k оценок, для которых рассчитывается среднее значение, являющееся итоговой оценкой модели. Обычно k выбирают равным 10, иногда 5. Если k равен количеству элементов в исходном наборе данных, этот метод называется кросс-валидацией по отдельным элементам (в этой статье не рассматривается).
- Многократная k-блочная кросс-валидация (repeated k-fold cross-validation). ПодробнееВ рамках этого метода k-блочная кросс-валидация выполняется несколько раз. Например, 5-кратная 10-блочная кросс-валидация даст 50 оценок, на основе которых затем будет рассчитана средняя оценка. Обратите внимание, это не то же самое, что 50-блочная кросс-валидация.
- Кросс-валидация на основе метода Монте-Карло (МККВ, Monte Carlo cross-validation, leave-group-out cross-validation). ПодробнееДанный метод заданное количество раз случайным образом разбивает исходный набор данных на обучающую и валидационную выборку в заданной пропорции.
Каждый из описанных выше методов кросс-валидации, можно охарактеризовать с помощью смещения (bias) и дисперсии (variance). Смещение характеризует правильность (accuracy) оценки. Дисперсия характеризует точность (precision) оценки.
В общем случае смещение метода кросс-валидации зависит от размера валидационной выборки. Если размер валидационной выборки составляет 50% исходных данных (2-блочная кросс-валидация), итоговая оценка СКО будет более смещенной, чем в случае, когда этот размер составляет 10% исходных данных. С другой стороны, меньший размер валидационной выборки увеличивает дисперсию, поскольку каждая валидационная выборка содержит меньше данных для получения стабильного значения СКО.
Таким образом, когда речь идет о k-блочной кросс-валидации, то для минимизации смещения следует выбирать максимальное k, а для уменьшения дисперсии применять многократный k-блочный метод, который справляется с этой задачей лучше однократного.
Что же касается МККВ, то для этого вида перекрестной проверки размер валидационной выборки имеет немного большее влияние на дисперсию, чем
количество повторений процесса. Следует также отметить, что количество повторений процесса не оказывает существенного влияния на смещение.
Таким образом, для метода МККВ можно порекомендовать использовать валидационную выборку малого размера (например, 10%) и выполнять большое количество повторений, чтобы уменьшить дисперсию.
Однако, при прочих равных, использование многократной 10-блочной КВ обеспечивает меньшую дисперсию, что в первую очередь обусловлено тем, что для этого метода, один и тот же элемент данных не может встречаться в разных выборках, в отличие от МККВ.
В завершении наших рассуждений, хотелось бы сделать оговорку, что при больших объемах данных 10-блочная или даже 5-блочная однократная КВ дает вполне приемлемые результаты, в нашей же задаче, для настройки модели мы будем использовать многократную 10-блочную перекрестную проверку.
Random forest
«Случайный Лес» — алгоритм, который для полученных данных случайным образом создает множество деревьев принятия решений и потом усредняет результаты их предсказаний. Алгоритм построения дерева очень быстр, поэтому не составляет большого труда сделать столько деревьев, сколько будет нужно.
С практической точки зрения у описанного выше метода есть одно огромное преимущество: он почти не требует конфигурации. Если мы возьмем любой другой алгоритм машинного обучения, будь то регрессия или нейронная сеть, они все имеют множество параметров, и их надо уметь подбирать под конкретную задачу. RF, по-сути, имеет лишь один важный параметр требующий настройки — mtry (размер случайного подмножества, выбираемого на каждом шаге построения дерева). Однако, даже используя значение по-умолчанию, можно получить весьма приемлемые результаты.
Как и в предыдущей статье, заменим отсутствующие значения (N/A) на медианные для всех регрессоров, исключим из выборки объем двигателя (ввиду сильной корреляции параметра с мощностью) и посмотрим на возможности этого алгоритма.
dat <- read.csv("dataset.txt") # загружаем выборку в R
dat$mileage[is.na (dat$mileage)] <- median(na.omit(dat$mileage)) # заменяем NA на примере пробега
dat <- dat[-c(1,11)] # исключаем номер строки и объем двигателя из выборки
set.seed (1) # инициализируем генератор случайных чисел (для воспроизводимости)
split <- runif(dim(dat)[1]) > 0.2 # разделяем нашу выборку
train <- dat[split,] # выборка для обучения и настройки (cross-validation) параметров
test <- dat[!split,] # отложенная (hold-out) выборка
Для перекрестной проверки будем использовать пакет caret, который имеет больше возможностей для оценки качества модели, чем rfcv.
library(caret) # подключаем библиотеку caret
fit.control <- trainControl(method = "repeatedcv", number = 10, repeats = 10)
train.rf.model <- train(price~., data=train, method="rf", trControl=fit.control , metric = "RMSE") # применим 10-ти кратную 10-ти блочную кросс-валидацию для настройки модели
train.rf.model # посмотрим на результаты кросс-валидации
292 samples
15 predictor
No pre-processing
Resampling: Cross-Validated (10 fold, repeated 10 times)
Summary of sample sizes: 262, 262, 262, 263, 263, 263, …
Resampling results across tuning parameters:
mtry RMSE Rsquared
2 134565.8 0.4318963
8 117451.8 0.4378768
15 122897.6 0.3956822
RMSE was used to select the optimal model using the smallest value.
The final value used for the model was mtry = 8.
library («randomForest») # подключаем библиотеку random forest
train.rf.model <- randomForest(price ~ ., train,mtry=8) # построим модель на основе полученных с помощью кросс-валидации параметров
Построим график, наглядно иллюстрирующий важность каждого из предикторов модели.
varImpPlot(train.rf.model) # оценим важность предикторов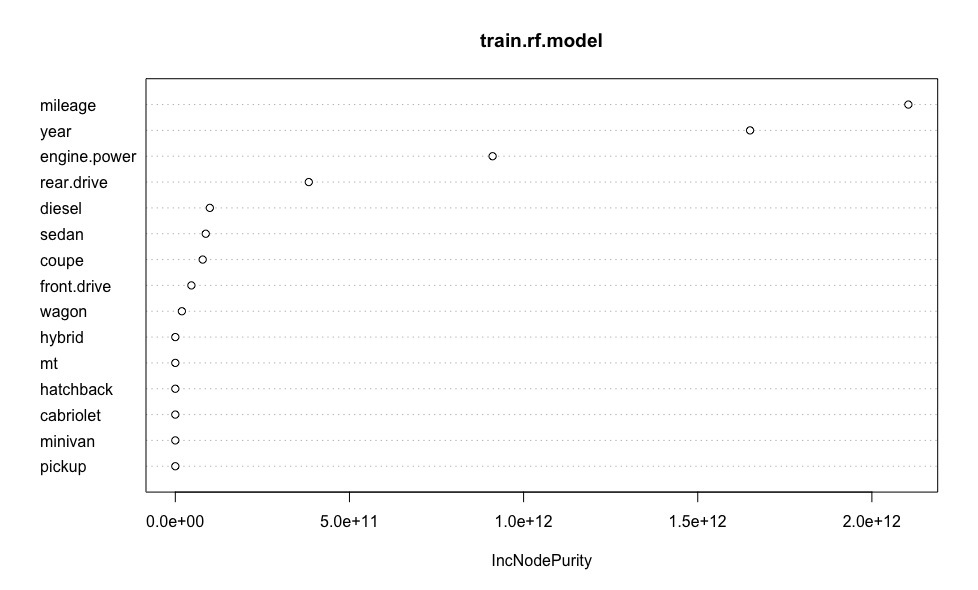
rf.model.predictions <- predict(train.rf.model, test) # проверим точность оценки на отложенной выборке
print (sqrt (sum ((as.vector (rf.model.predictions — test$price))^2)/length (rf.model.predictions))) # средняя ошибка прогноза цены (в рублях)
[1] 121760.5
Полученная средняя ошибка оценки стоимости автомобиля эквивалентна этой же величине полученной для линейной регрессии. Напомню, что при построении линейной модели, в отличие от RF, мы избавлялись от выбросов, что приводило к дополнительным неточностям в оценках стоимости автомобилей. Таким образом, можно утверждать о робастности «случайного леса» к выбросам.
XGboost
Идея градиентного бустинга состоит в построении ансамбля последовательно уточняющих друг друга элементарных моделей. Каждая последующая элементарная модель обучается на «ошибках» ансамбля из предыдущих элементарных моделей, ответы моделей взвешенно суммируются.
«Бустить» можно практически любые модели — общие линейные, обобщенные линейные, деревья решений, K-ближайших соседей и многие другие.
К особенностям реализации алгоритма бустинга в xgboost можно отнести, во-первых, использование помимо первой еще и второй производной от функции потерь, что повышает эффективность алгоритма. Во-вторых, наличие встроенной регуляризации, что помогает бороться с переобучением. И наконец, возможность задавать пользовательские функции потерь и метрики качества.
Благодаря экспериментальному параметру num_parallel_tree можно задать количество одновременно создаваемых деревьев и представить Random Forest, как частный случай бустинговой модели с одной итерацией. А если использовать больше одной итерации, то получится бустинг «случайных лесов», когда каждый «случайный лес» выступает в качестве элементарной модели.
В рамках статьи рассмотрим только один вид бустинга — xgbTree, т.к. xgbDart даёт схожие результаты.
fit.control <- trainControl(method = "repeatedcv", number = 10, repeats = 10)
train.xgb.model <- train(price ~., data = train, method = "xgbTree", trControl = fit.control, metric = "RMSE") # применим 10-ти кратную 10-ти блочную кросс-валидацию
train.xgb.model # посмотрим на результаты кросс-валидации
292 samples
15 predictor
No pre-processing
Resampling: Cross-Validated (10 fold, repeated 10 times)
Summary of sample sizes: 263, 262, 262, 263, 264, 263, …
Resampling results across tuning parameters:
eta max_depth colsample_bytree nrounds RMSE Rsquared
0.3 1 0.6 50 114131.1 0.4705512
0.3 1 0.6 100 113639.6 0.4745488
0.3 1 0.6 150 113821.3 0.4734121
0.3 1 0.8 50 114234.6 0.4694687
0.3 1 0.8 100 113960.5 0.4712563
0.3 1 0.8 150 114337.1 0.4685121
0.3 2 0.6 50 115364.6 0.4604643
0.3 2 0.6 100 117576.4 0.4472452
0.3 2 0.6 150 119443.6 0.4358365
0.3 2 0.8 50 116560.3 0.4494750
0.3 2 0.8 100 119054.2 0.4350078
0.3 2 0.8 150 121035.4 0.4222440
0.3 3 0.6 50 117883.2 0.4422659
0.3 3 0.6 100 121916.7 0.4162103
0.3 3 0.6 150 125206.7 0.3968248
0.3 3 0.8 50 119331.3 0.4296062
0.3 3 0.8 100 124385.7 0.3987044
0.3 3 0.8 150 128396.6 0.3753334
0.4 1 0.6 50 113771.6 0.4727520
0.4 1 0.6 100 113951.6 0.4717968
0.4 1 0.6 150 114135.0 0.4710503
0.4 1 0.8 50 114055.0 0.4700165
0.4 1 0.8 100 114345.5 0.4680938
0.4 1 0.8 150 114715.8 0.4655844
0.4 2 0.6 50 116982.1 0.4499777
0.4 2 0.6 100 119511.9 0.4347406
0.4 2 0.6 150 122337.9 0.4163611
0.4 2 0.8 50 118384.6 0.4379478
0.4 2 0.8 100 121302.6 0.4201654
0.4 2 0.8 150 124283.7 0.4015380
0.4 3 0.6 50 118843.2 0.4356722
0.4 3 0.6 100 124315.3 0.4017282
0.4 3 0.6 150 128263.0 0.3796033
0.4 3 0.8 50 122043.1 0.4135415
0.4 3 0.8 100 128164.0 0.3782641
0.4 3 0.8 150 132538.2 0.3567702
Tuning parameter 'gamma' was held constant at a value of 0
Tuning parameter 'min_child_weight' was held constant at a value of 1
RMSE was used to select the optimal model using the smallest value.
The final values used for the model were nrounds = 100, max_depth = 1, eta = 0.3, gamma = 0, colsample_bytree = 0.6 and min_child_weight = 1.
library («xgboost») # подключаем библиотеку xgboost
xgb_train <- xgb.DMatrix(as.matrix(train[-c(1)] ), label=train$price) # тренировочная выборка
xgb_test <- xgb.DMatrix(as.matrix(test[-c(1)]), label=test$price) # тестовая выборка
xgb.param <- list(booster = "gbtree",
max.depth = 1,
eta = 0.3,
gamma = 0,
colsample_bytree = 0.6,
min_child_weight = 1,
eval_metric = «rmse»)
train.xgb.model <- xgb.train(data = xgb_train, nrounds = 100, params = xgb.param) # построим модель на основе полученных с помощью кросс-валидации параметров
Построим график, демонстрирующий важность каждого из предикторов модели.
importance.frame <- xgb.importance(colnames(train[-c(1)]), model = train.xgb.model) # оценим важность предикторов
library («Ckmeans.1d.dp») # подключим библиотеку для xgb.plot
xgb.plot.importance (importance.frame)
xgb.model.predictions <- predict(train.xgb.model, xgb_test) # проверим точность оценки на отложенной выборке
print (sqrt (sum ((as.vector (xgb.model.predictions — test$price))^2)/length (xgb.model.predictions))) # средняя ошибка прогноза цены (в рублях)
[1] 118742.8
XGboost для данного конкретного случая показал немного более точные оценки стоимости автомобилей. Вызывает опасение большое число гиперпараметров, которые требуют перенастройки в зависимости от выбранной марки и модели авто. В связи с этим, для использования на сервисе robasta.ru предпочтение было отдано алгоритму Random Forest.
Апробация выбранного алгоритма
Теперь, когда с выбором «чемпиона» покончено, самое время посмотреть на него в деле.
library("randomForest”) # подключаем библиотеку random forest
rf.model <- randomForest(price ~ ., dat,mtry=8) # построим модель на основе полученных с помощью кросс-валидации параметров
predicted.price <- predict(rf.model, dat) # предскажем цену для каждого автомобиля
real.price <- dat$price # вектор цен на автомобили полученный из объявлений
profit <- predicted.price - real.price # выгода между предсказанной нами ценой и ценой из объявлений
Как и для линейной регрессии в прошлой статье, построим график зависимости выгоды от цены.
plot(real.price,profit)
abline(0,0)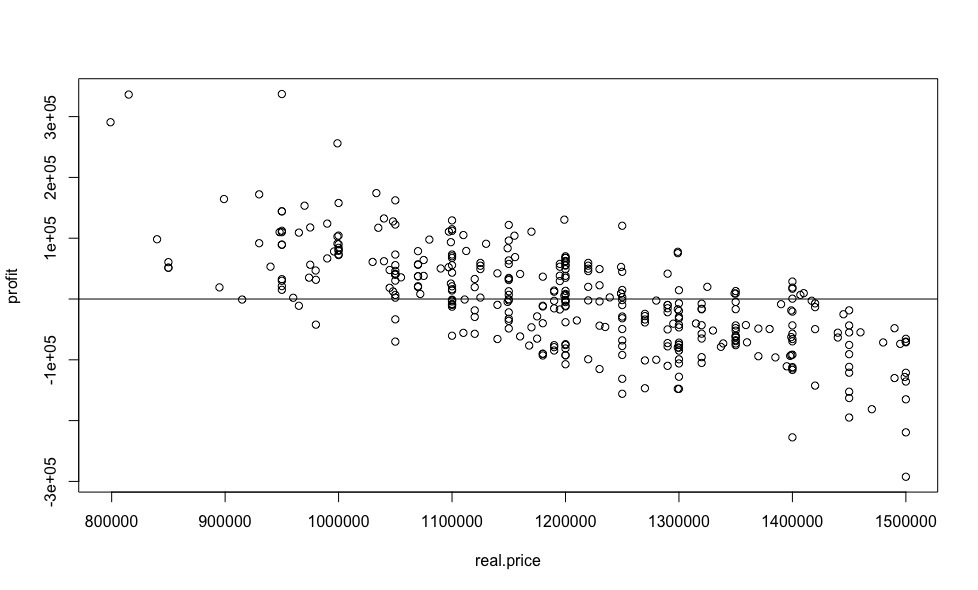
А теперь посчитаем выгоду в процентном соотношении.
sorted <- sort(predicted.price /real.price, decreasing = TRUE)
sorted[1:10]
69 42 122 15 168 248 346 109 231 244
1.412597 1.363876 1.354881 1.256323 1.185104 1.182895 1.168575 1.158208 1.157928 1.154557
Полученные результаты имеют крайне слабое сходство с результатами, полученными с помощью линейной регрессии, и выглядят более правдоподобно, несмотря на практически идентичное СКО для обоих моделей.
Для сравнения результатов в этой статье мы использовали выборку из прошлой публикации, поэтому давайте посмотрим много ли выгодных предложений Mercedes-Benz E-klasse не старше 2010 года выпуска, стоимостью до 1.5 млн рублей в Москве на рынке сейчас.
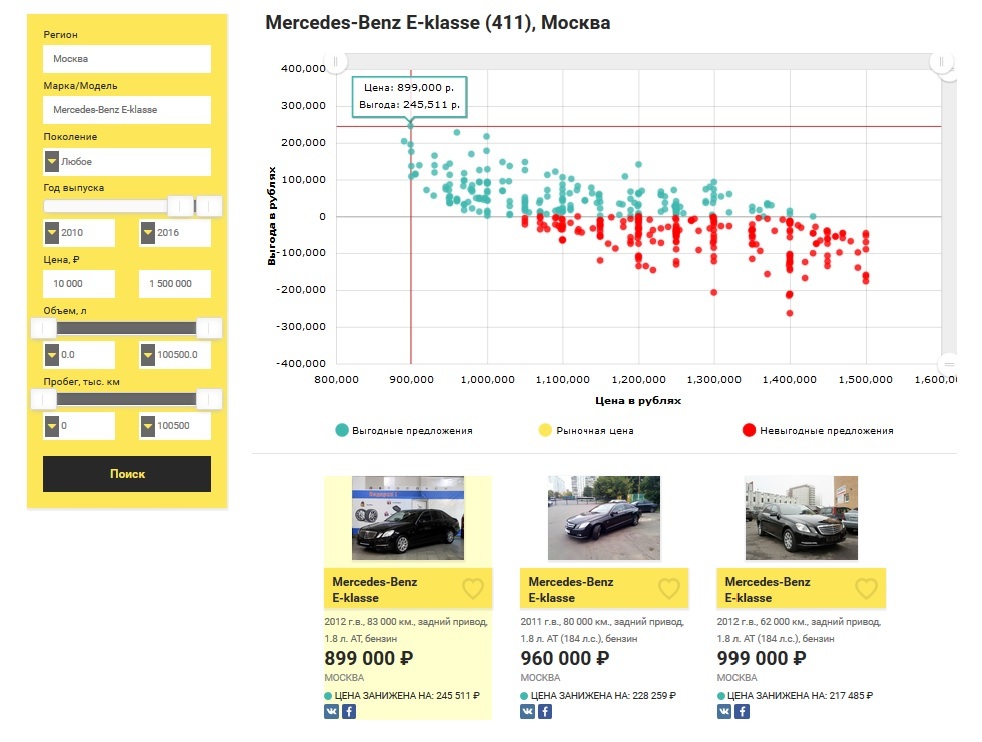
Резюмируя все сказанное выше, могу с уверенностью заявить, что для подбора б/у автомобилей мы получили мощный инструмент, не чувствительный к «фейковым» объявлениям, работающий в режиме реального времени. Вам больше не нужно просиживать часами на нескольких сайтах с объявлениями по продаже машин и ездить смотреть потенциально невыгодные предложения.
Но это еще не все, теперь, используя рассмотренный математический аппарат, Робаста может помочь не только тем, кто хочет купить, но и тем, кто хочет продать свой автомобиль.
Продажа автомобиля
При продаже своей машины вы, разумеется, хотите как минимум не продешевить и продать ее в короткий срок. Для быстрой и выгодной продажи вашего автомобиля нужно понимать вклад различных характеристик в его стоимость.
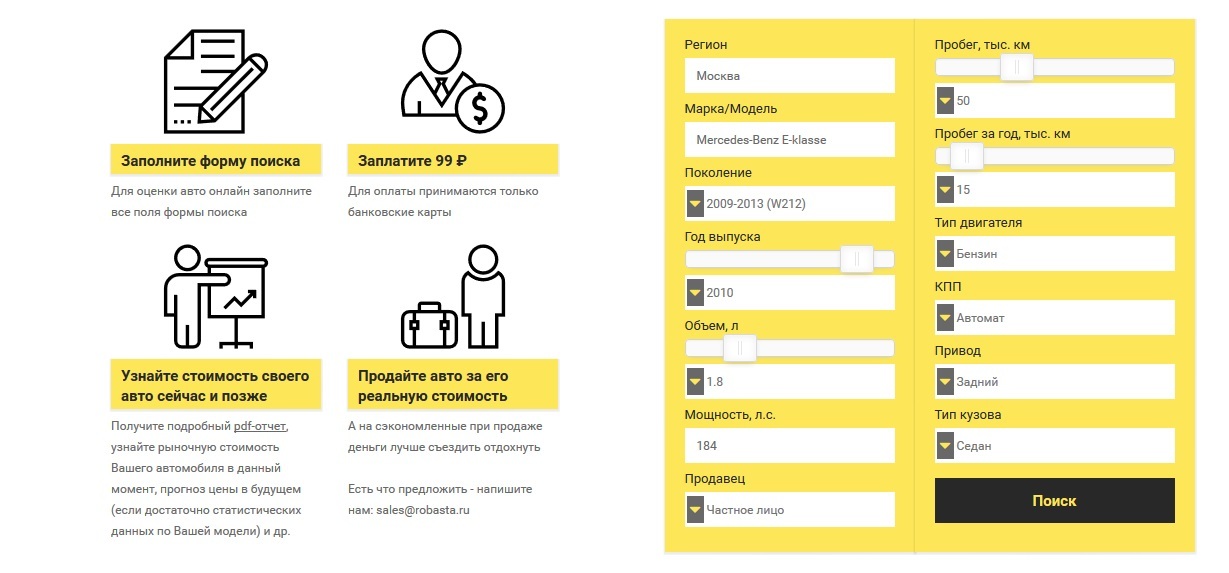
Для решения этой задачи, на основе все того же «случайного леса», был разработан сервис для оценки авто. Вы заполняете все поля формы поиска, в соответствии с параметрами вашего автомобиля, после чего модель обучается на основе рыночных предложений в текущий момент. В случае если нашлось пять и более объявлений на рынке, алгоритм для заполненных вами данных предсказывает цену и выдает несколько интересных особенностях в зависимости от общей картины рынка. Стоит подчеркнуть, что для достижения наибольшей точности, для анализа выбираются только автомобили того же поколения, что и ваш. Результаты оценки вашего автомобиля формируются в виде pdf-отчета, стоимость которого составляет 99 ₽.
Напоследок
В настоящее время прорабатываются различные направления дальнейшего развития, среди которых основными можно назвать следующие:
Относительно новые автомобили (пробег до 100 тыс. км) часто продают перед крупными дорогими ТО, эти данные полезно учитывать в модели. Поэтому сейчас я нахожусь в поиске надежных партнеров среди средних и крупных автодилеров.
Открытие оффлайн-центра по подбору и оценке автомобилей в Москве, который, благодаря реализованному алгоритму, будет гораздо менее затратным чем у конкурентов.
Создание удобного API для предоставления функционала «интеллектуальным перекупщикам».
Вы хотите чем-то помочь в реализации озвученных мной задач или предложить свои идеи? Пишите, я всегда готов рассмотреть любые виды сотрудничества.
Ссылки
- dat (выборка MB E-klasse)
- dat_a5 (выборка Audi A5)
Комментарии (1)
 Pashkevich
Pashkevich
17 октября 2016 в 06:38 (комментарий был изменён)
+2↑
↓
Я помню, меня НЛО наказывало за ссылку в статье, а тут еще и ссылка на платные услуги.
