Когда разница адресов имеет значение

Среди бесчисленных режимов адресации архитектуры х86 существует один такой…
Впрочем, почему «бесчисленных» режимов? Если разобраться, то их немного. Со времен первого процессора 8086 адресация укладывалась в байт, который имел аббревиатуру MODRM, где «MOD» — это собственно режим адресации (т.е. mode), «R» — регистр и «M» — очевидно, память (memory).
Если не рассматривать дальнейшее совершенствование системы адресации с помощью SIB-байта, то, поскольку под MODE в MODRM-байте выделено всего два бита, получается, что возможны всего-навсего четыре режима адресации.
Один из них задает просто пересылку регистра в регистр, без использования адресации как таковой (если задан mode из двух единичных бит), например,
код 8BD3 это mov edx, ebx.
А остальные три подразумевают вычисление адреса, который или просто записан в регистре (включая частный случай не регистра, а прямо константы-адреса в коде команды) или получается прибавлением к содержимому регистра константы, записанной в коде команды. Причем такая константа занимает в коде команды или четыре байта или байт, расширяемый со знаком.
Не будем касаться всяких тонкостей адресации вроде восьмибайтовых адресов-констант для x86–64 или уже упомянутого SIB-байта. Далее речь пойдет только об одном из четырех режимов адресации, у которого mode равен 01 и в кодах команды записан байт расширяемой со знаком адресной константы, прибавляемой к содержимому регистра.
Из-за того, что адрес записан в регистре, а добавка-константа занимает лишь байт, команды с таким режимом адресации короче «обычных», но я не обращал на них особого внимания, поскольку считал, что данный режим применим только при передаче параметров подпрограмме через стек и для части локальных данных в стеке, а также для доступа к отдельным полям агрегатов разнотипных данных.
В самом деле, если перед вызовом подпрограммы необходимые параметры записать в стек, а после вызова переслать регистр стека RSP в RBP и выделить память в стеке для локальных данных, то параметры и локальные данные окажутся «по разные стороны» от текущего значения RBP. И, например, теперь к параметрам можно обращаться как к [RBP]+8, [RBP]+16 и т.д., а к части локальных данных как, например, к [RBP]-8, [RBP]-10, [RBP]-70h и т.п. Т.е. как раз удобно применять режим прибавления байтовой константы со знаком и, тем самым, уменьшать общий размер кода.
Но недавно пришла мысль, что такой же режим адресации можно использовать и в другом случае. Впрочем, обо все по порядку.
Исторически сложилось так, что я использую компилятор, который сам же сопровождаю и по мере сил совершенствую. Оптимизация генерируемого компилятором кода для меня это очень интересная задача и, заодно, нечто вроде хобби. Я не верю заявлениям, что теперь достаточно выдать результат в виде кода LLVM, а далее некий волшебный оптимизатор сгенерирует идеальный код для x86 и заботиться об оптимизации команд на самом низком уровне компиляторам более не надо. Не бывает идеального кода. А кроме того, в глубине души, я считаю настоящим компилятором только тот, который доводит исходный текст программы прямо до исполняемых команд, а не перекладывает с одного языка (со своими «тараканами» и ограничениями) на другой, умножая и число «тараканов» и число ограничений.
Так вот, я с удовольствием занимаюсь оптимизацией генерируемого кода и процесс этот бесконечен. Технология оптимизации самая простая. Получаю листинг программы, включающий исходный текст, сгенерированные коды и эти же коды в виде псевдоассемблера. А затем просто иду по листингу, пытаясь представить, как бы я сам писал этот код на ассемблере, где бы я улучшил этот код и анализируя, почему компилятор так не улучшил. Если догадался, как можно улучшить — вношу очередное дополнение в генератор кода. Замечу, что в основном, это оптимизация на очень низком уровне, когда почти все команды уже сгенерированы, но адреса переходов еще не вычислялись и поэтому команды еще можно менять или выбрасывать.
Очень много оптимизаций кода на этом самом нижнем уровне связаны с отслеживанием состояния и содержимого регистров. Например, самый очевидный случай — в регистр засылается некоторое значение, а выше уже есть точно такая же команда и регистр и значение за это время не изменились, так сказать, не «испортились». В этом случае текущую анализируемую команду можно просто выбросить из программы — она ничего не меняет.
И я обратил внимание, что довольно часто требуется адрес какой-либо переменной, а в текущем состоянии регистров нет такого адреса и поэтому использовать вместо адреса-константы адрес в регистре не получается. Но может быть в регистрах есть адрес СОСЕДНЕЙ переменной? Ведь если она имеет похожий адрес (плюс 127- минус 128 байт) — то бинго! — можно использовать тот самый короткий режим адресации с байтом-константой.
И действительно, оказалось, что в реальных программах такие случаи не редкость. Причем похожий адрес может оказаться даже не у переменной, введенной программистом, а у служебной переменной, выделенной самим компилятором. Хотя на этапе компиляции отдельных модулей окончательные адреса еще неизвестны и будут определены лишь редактором связей, относительные адреса локальных данных уже известны и, следовательно, разница адресов между ними уже не изменится.
Могут возразить, что при таком уменьшении кода возрастает зависимость команд через содержимое регистров, а, следовательно, ухудшается параллельность их выполнения. Да, такое может быть. Но тестирование реальных программ не показало ощутимого или вообще какого-либо замедления. Во-первых, оптимизируемые команды не обязательно оказываются смежными, а, значит их влияние на параллельность выполнения снижается. А во-вторых, на мой взгляд, сейчас недооценивается важность компактности кода для скорости работы. Если в далекие времена процессора 8086 чтение команд из памяти занимало тактов 25, а выполнение команды — тактов 10, то сейчас выполнение команды может занимать 1–2 такта, а чтение кода из памяти — тактов 200 (если не все 400). Поэтому сокращение кода сейчас больше влияет на скорость работы, чем раньше.
Напоследок, приведу пример использования адресации с константой-байтом, взятый из кода реальной программы. Я понимаю, что большинство программистов нового поколения довольно смутно представляет себе какими именно машинными инструкциями обеспечивается результат работы их программ и уж точно никто не будет разбираться в двоичном коде выполняемых команд. И, тем не менее, на пальцах и небольшом фрагменте кода постараюсь пояснить все выше сказанное. При этом в примере двоичный код и код на псевдоассемблере не совпадают. Я сделал такой режим листинга намеренно, чтобы видеть, что нужно было сгенерировать по логике программы и что реально сгенерировал компилятор. Иначе отладка компилятора сильно затрудняется.
Ниже приведена небольшая часть стандартной подпрограммы поиска максимума функции одной переменной на заданном отрезке. Все переменные имеют тип double. На листинге слева направо выведен: номер строки, глубина вложенности (блоков и подпрограмм), двоичный код, исходный текст прописными буквами и текст псевдоассемблера.
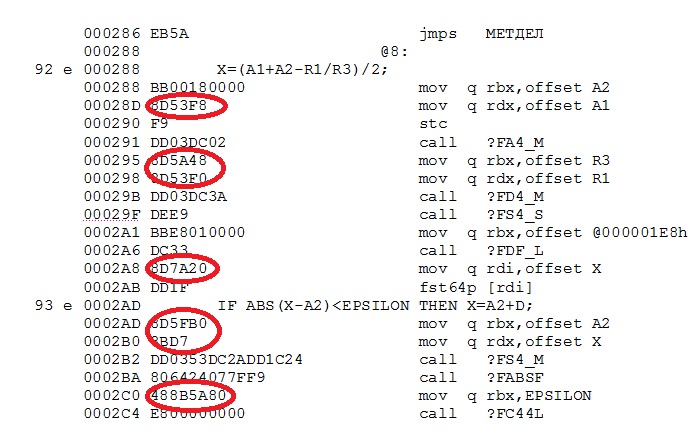
Итак, приведенный фрагмент начинается с безусловного перехода и следующей за ним метки @8, введенной самим компилятором для ветви условного перехода. Для простоты анализа считается, что после любой метки состояние регистров не определено, поскольку управление на метку может попасть из любого места программы.
Первая команда загружает в регистр rbx адрес-константу переменной A2. Реально значение загружается лишь в младшую половину rbx (в регистр ebx), а старшая половина rbx при этом автоматически обнуляется.
Следующая команда должна сделать загрузку адреса переменной A1, но оказывается, что адрес A1 лишь на 8 байт меньше A2, поэтому вместо команды mov rdx, offset A1 генерируется более короткая команда lea edx,[rbx]-8.
Затем идут загрузки адресов переменных R3 и R1 и их, оказывается, опять можно выразить через адрес A1, еще сохранившийся в регистре edx.
А вот в следующей загрузке адреса константы 2 не повезло: память для констант компилятор выделил раньше, чем память для переменных и поэтому адрес этой константы имеет значение 1E8h, что слишком далеко от адресов других переменных и использовать короткий режим адресации в этой команде не удается.
Зато уже в следующей команде загрузки адреса переменной X опять ее адрес можно выразить через адрес переменной R1, так и продолжающийся оставаться в регистре rdx.
Следующая загрузка адреса переменной A2 снова может быть выражена через адрес одной из соседних переменных. А в следующей загрузке адреса переменной X еще больше повезло — нужный адрес так и остался в регистре rdi и команду загрузки можно заменить более короткой двухбайтовой пересылкой из rdi в требуемый rdx.
Наконец любопытна последняя оптимизация в данном фрагменте. Здесь в команде вообще нет загрузки адреса, а есть обычная загрузка значения из переменной EPSILON. Но адрес этой переменной случайно оказался лишь на 128 байт меньше, чем адрес переменной X, еще сохранившийся в регистре rdx. Поэтому вместо команды mov rbx, EPSILON длиной 7 байт, сгенерирована команда mov rbx,[rdx]+0ffffff80h, длиной лишь 4 байта.
Таким образом, в этом небольшом фрагменте, где часто использованы локальные статические переменные, удалось сократить практически «на ровном месте» 7 команд в целом на 2×5+3×2=16 байт по сравнению с обычными загрузками адресов. Причем просто из анализа исходного текста никак не следует, что одни адреса можно выразить через другие и это сократит длину кода.
Как говорил персонаж рассказа Дж. Лондона «Малыш видит сны»: «И все благодаря покривившимуся колесику и зоркому глазу». Правда, в данном случае помогло не кривое колесо рулетки, как в рассказе, а подходящий режим адресации.
