[Перевод] Внедрение Postgres из Docker в Kubernetes

Создание контейнера для базы данных отнюдь не является излишеством. На самом деле, это позволит вам привнести все преимущества контейнеров в вашу БД.
Мы рассмотрим, как создавать контейнеры Postgres с помощью Docker и перезапускать их без потери данных, а в конце статьи с помощью нестандартного метода (использующего ConfigMaps и StatefulSets) мы развернём внутри подов Kubernetes — Postgres.
Зачем использовать контейнерные базы данных?
Создание контейнера для базы данных может показаться излишней морокой по сравнению с простой установкой на сервер. Однако это позволяет пользователям задействовать все преимущества контейнеров для своих баз данных.
Разделение данных и базы данных
Контейнеризация предоставляем пользователям возможность отделить приложение базы данных от самих данных. В результате это повышает отказоустойчивость, давая пользователям запускать новый контейнер в случае сбоя приложения, не затрагивая основные данные. Кроме того, контейнеризация позволяет юзерам с относительной лёгкостью масштабировать и повышать доступность базы данных.
Портирование
Портируемость контейнеров помогает пользователям развёртывать и переносить базы данных в любую поддерживаемую контейнерную среду без каких-либо изменений инфраструктуры или конфигурации. Они также дают возможность вносить изменения в конфигурацию приложения базы данных с минимальным или нулевым воздействием на основные данные в производственных средах. Кроме того, контейнеры позволяют лучше использовать ресурсы и снижать общие затраты, поскольку они по своей сути являются легковесными, по сравнению с другими решениями, такими как виртуальные машины.
Создание контейнеризированной базы данных
Для начала нам нужен образ, который будет служить основой для нашего контейнера. Хотя мы и можем создать образ с нуля, но в большинстве случаев это будет излишним, поскольку такое привычное ПО, как Postgres, уже содержит официальные образы контейнеров с возможностью их настройки. Поэтому для создания контейнера базы данных мы будем использовать официальный образ Postgres в хабе Docker.
Что дальше? Пора создавать конфигурацию контейнера. Это можно легко сделать с помощью файла docker-compose.
version: '3.1'
services:
postgres-db:
container_name: postgres-db
image: postgres:latest
restart: always
environment:
POSTGRES_USER: testadmin
POSTGRES_PASSWORD: test123
POSTGRES_DB: testdb
PGDATA: /var/lib/postgresql/data/pgdata
volumes:
- postgres-db-data:/var/lib/postgresql/data
ports:
- 5432:5432
volumes:
postgres-db-data:
name: postgres-db-data
Мы создаём том docker для хранения данных Postgres в приведённой выше конфигурации. Поскольку этот том является многоразовым, вы сможете восстановить базовые данные, даже если контейнер будет удалён. Для контейнера Postgres мы используем последний образ Postgres с переменными окружения, задающими пользователя, пароль, базу данных и расположение данных внутри контейнера. В разделе тома мы сопоставим внутреннее расположение данных контейнера с нашим томом и откроем порт 5432.
После создания файла мы можем выполнить команду docker-compose up для запуска контейнера.
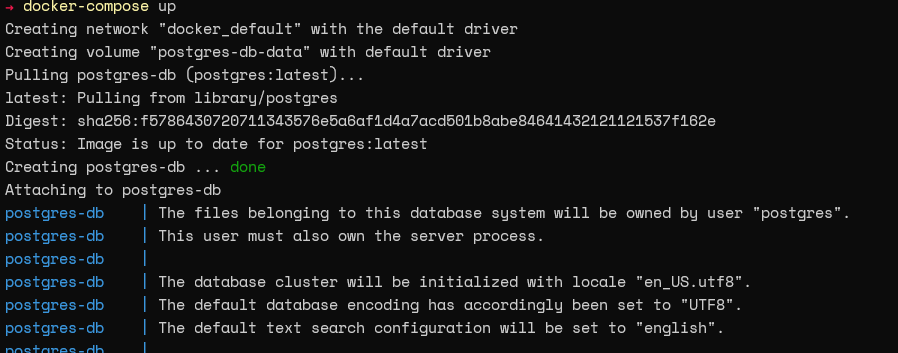
Далее мы можем выполнить команду docker ps, чтобы проверить, успешно ли запущен контейнер.

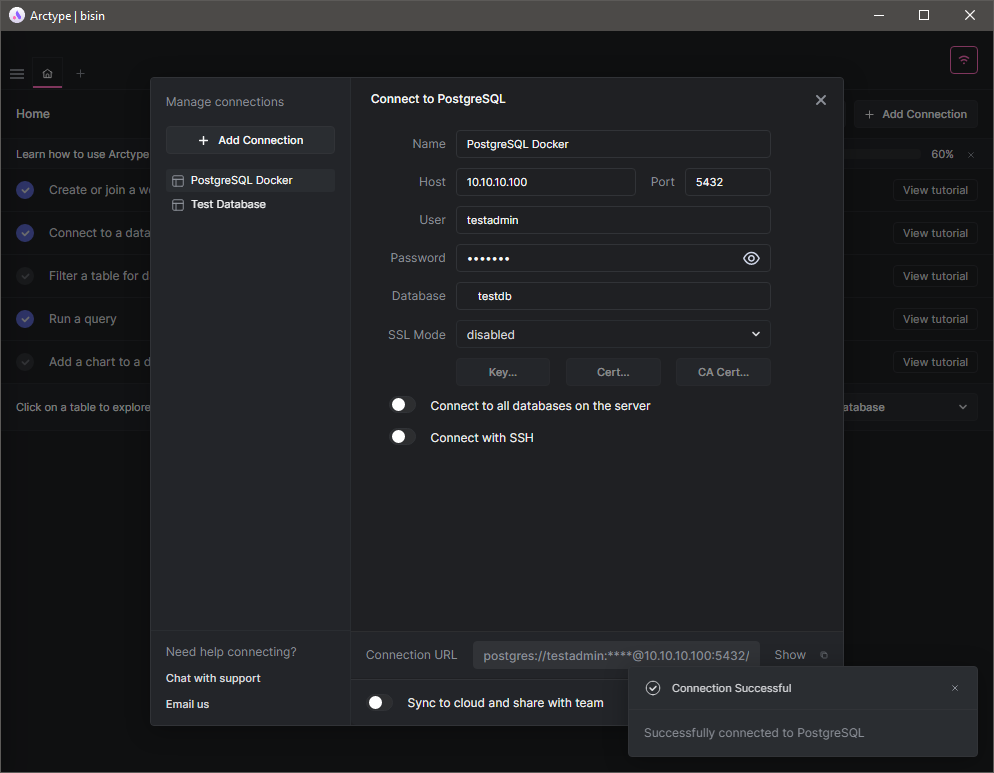
Вот и всё. Мы успешно создали контейнерную базу данных Postgres. Работает ли она? Мы можем проверить это, попытавшись подключиться к базе данных через SQL-клиент. Поэтому давайте воспользуемся SQL-клиентом Arctype для инициализации тестового соединения. Сначала укажите данные подключения к базе данных. В данном случае мы будем использовать IP-адрес хоста Docker, порт и учётные данные, которые мы указали при создании контейнера. Затем, как видно на следующем изображении, мы можем успешно инициализировать соединение с базой данных.
Создание воспроизводимой конфигурации
Как упоминалось ранее, контейнеры позволяют пользователям отделить данные базы данных от приложения и обеспечить воспроизводимость конфигураций. Например, предположим, что вы столкнулись с ошибкой в программном обеспечении базы данных. При традиционной установке это может привести к катастрофическим последствиям, поскольку и данные, и приложение связаны друг с другом. Даже откат невозможен, поскольку он приведёт к потере данных. Однако контейнеризация позволяет удалить сбойный контейнер, запустить новый экземпляр и немедленно получить доступ к данным.
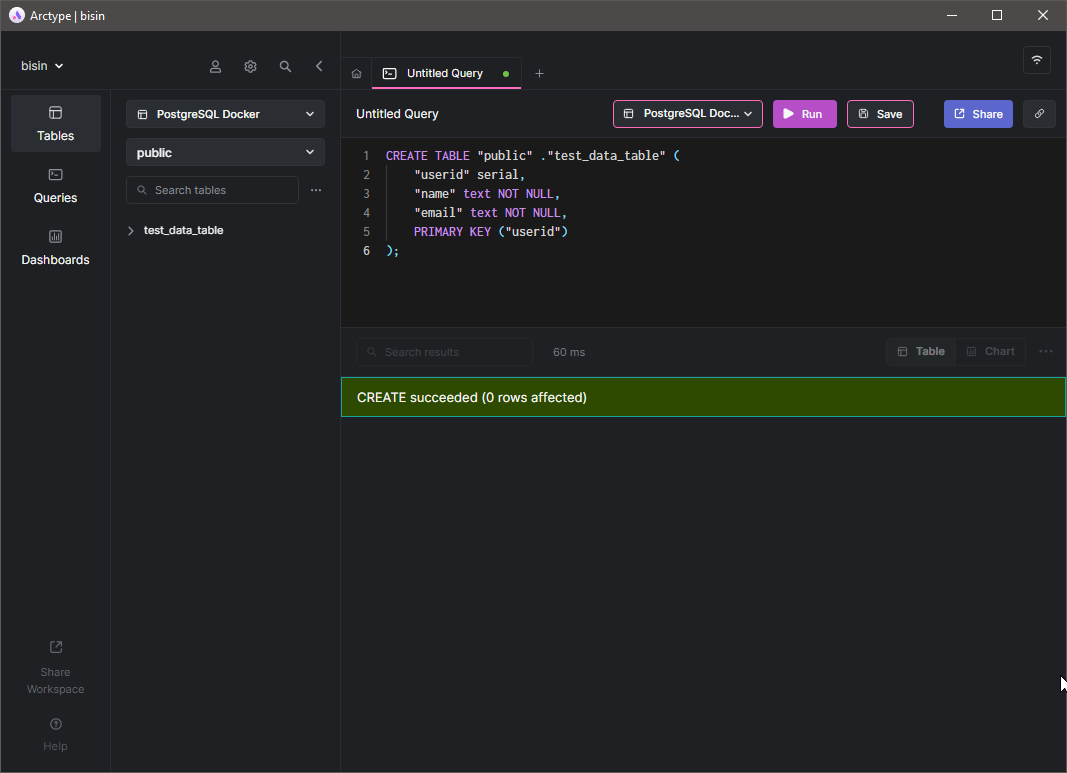
Давайте рассмотрим этот сценарий на практике. Сначала создадим таблицу test_data_table и вставим в неё несколько записей с помощью клиента Arctype.
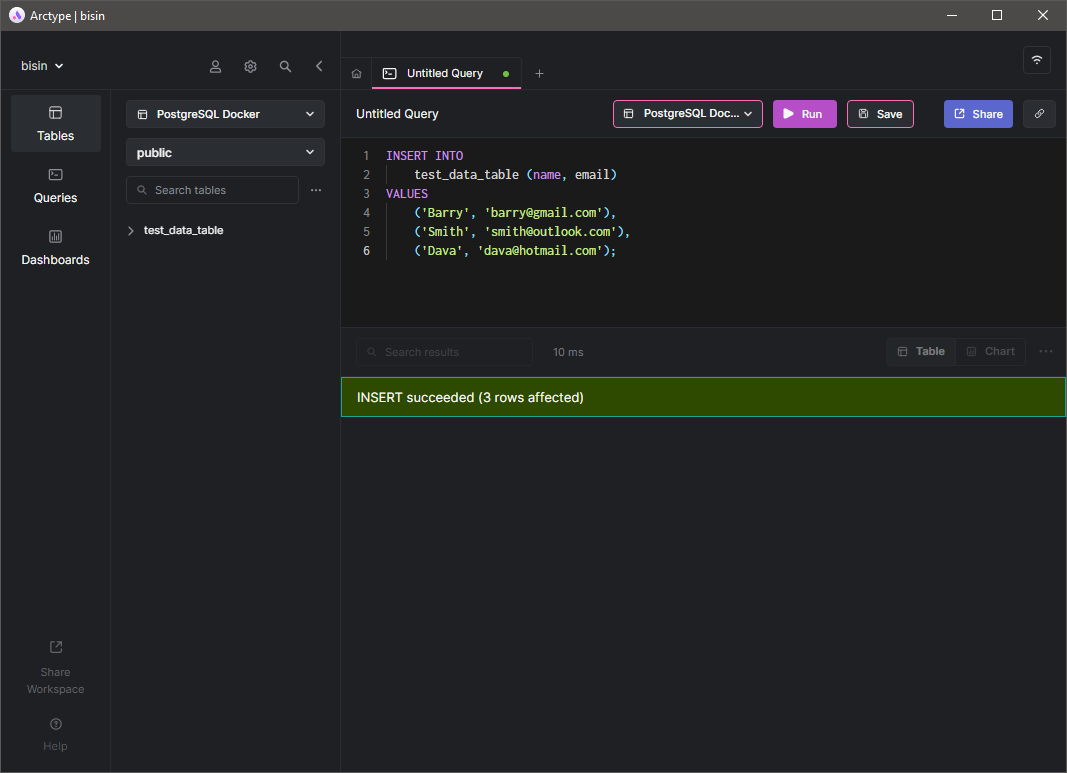
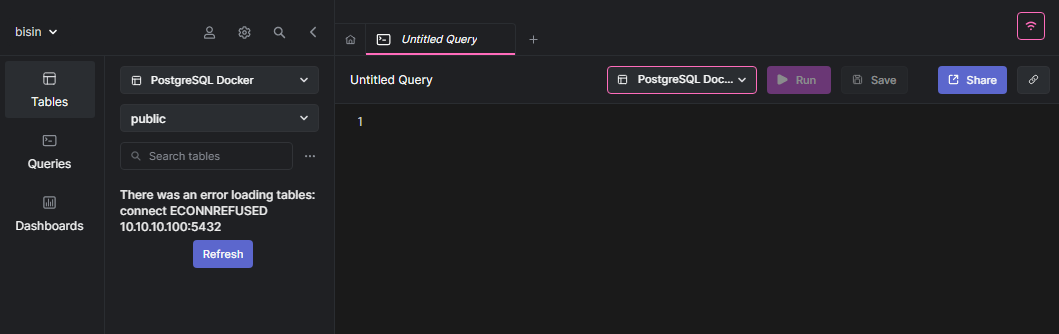
Теперь у нас есть некоторые данные в базе данных. Давайте удалим контейнер из среды docker с помощью команды docker-compose down.

Примечание: Когда контейнер будет удалён, SQL-клиент выдаст ошибку с сообщением об отказе в подключении.
Далее внесём небольшое изменение в файл compose, чтобы изменить имя контейнера.
version: '3.1'
services:
postgres-db:
# New Container
container_name: postgres-db-new
image: postgres:latest
restart: always
environment:
POSTGRES_USER: testadmin
POSTGRES_PASSWORD: test123
POSTGRES_DB: testdb
PGDATA: /var/lib/postgresql/data/pgdata
volumes:
- postgres-db-data:/var/lib/postgresql/data
ports:
- 5432:5432
volumes:
postgres-db-data:
name: postgres-db-data
Затем снова запустите контейнер и проверьте его работоспособность с помощью команды docker ps.

Обновите таблицы в клиенте Arctype, чтобы восстановить соединение. Затем выполните простую команду SELECT для запроса данных в test_data_table, как показано ниже.
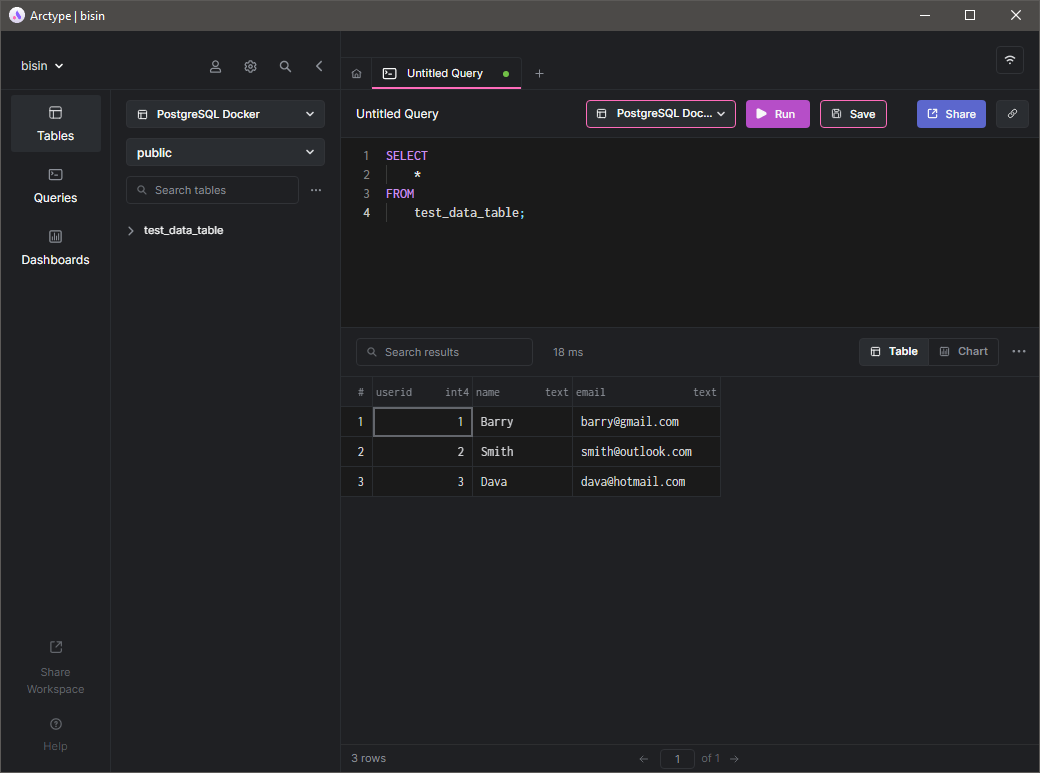
Как видите, мы можем воспроизвести контейнер и получить доступ к данным, даже если контейнер был удалён.
Управление контейнерами с помощью Kubernetes
Docker — отличный выбор для локальных сред разработки или даже для запуска нескольких контейнеров в производственной среде. Однако, поскольку большинство производственных сред состоит из множества контейнеров, то управлять ими быстро становится практически невыполнимой задачей. Именно здесь в игру вступают платформы автоматической конфигурации (оркестровки), такие как Kubernetes, которые предлагают полную многофункциональную платформу для управления контейнерами в больших масштабах.
Лучший способ развёртывания контейнера Postgres в Kubernetes — это использование StatefulSet. Он позволяет пользователям предоставлять stateful-приложения и настраивать постоянное хранилище, уникальные сетевые идентификаторы, автоматические обновления, упорядоченное развёртывание и масштабирование. Все эти функции необходимы для обеспечения работы stateful-приложений, таких как база данных. В этом разделе мы рассмотрим, как развернуть контейнеры Postgres в кластере K8s.
Создание и развёртывание пода Postgres
Для этого развёртывания мы создадим configmap для хранения переменных окружения, сервис для демонстрации базы данных за пределами кластера и StatefulSet для пода Postgres.
# PostgreSQL StatefulSet ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: postgres-db-config
labels:
app: postgresql-db
data:
POSTGRES_PASSWORD: test123
PGDATA: /data/pgdata
---
# PostgreSQL StatefulSet Service
apiVersion: v1
kind: Service
metadata:
name: postgres-db-lb
spec:
selector:
app: postgresql-db
type: LoadBalancer
ports:
- port: 5432
targetPort: 5432
---
# PostgreSQL StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgresql-db
spec:
serviceName: postgresql-db-service
selector:
matchLabels:
app: postgresql-db
replicas: 2
template:
metadata:
labels:
app: postgresql-db
spec:
# Official Postgres Container
containers:
- name: postgresql-db
image: postgres:10.4
imagePullPolicy: IfNotPresent
ports:
- containerPort: 5432
# Resource Limits
resources:
requests:
memory: "265Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
# Data Volume
volumeMounts:
- name: postgresql-db-disk
mountPath: /data
# Point to ConfigMap
env:
- configMapRef:
name: postgres-db-config
# Volume Claim
volumeClaimTemplates:
- metadata:
name: postgresql-db-disk
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 25Gi
Приведённую выше конфигурацию можно свести к следующим пунктам:
- ConfigMap — postgres-db-config: ConfigMap определяет все переменные окружения, необходимые контейнеру Postgres.
- Service — postgres-db-lb: Служба типа балансировщика нагрузки определена для того, чтобы вывести поды за пределы контейнера, используя порт 5432.
- StatefulSet — postgresql-db: StatefulSet настроен с использованием двух дубликатов, использующих образ контейнера Postgres с данными, смонтированными на постоянный том. Дополнительные ограничения ресурсов настроены как для контейнера, так и для тома.
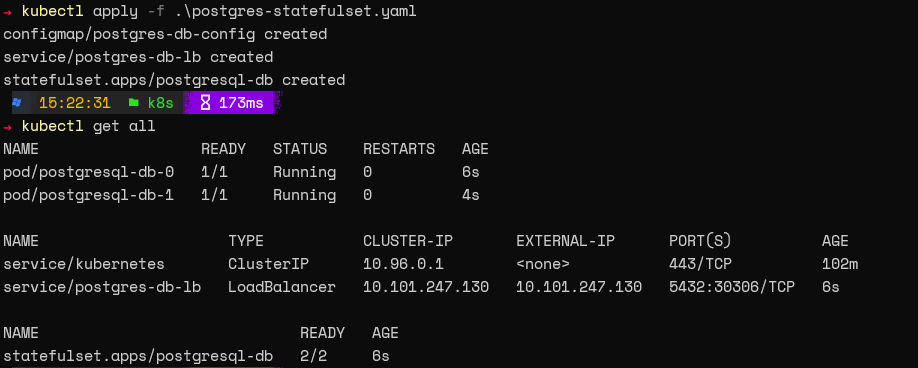
После создания этой конфигурации мы можем применить её и проверить StatefulSet с помощью следующих команд.
kubectl apply -f .\postgres-statefulset.yaml
kubectl get all
kubectl get pvc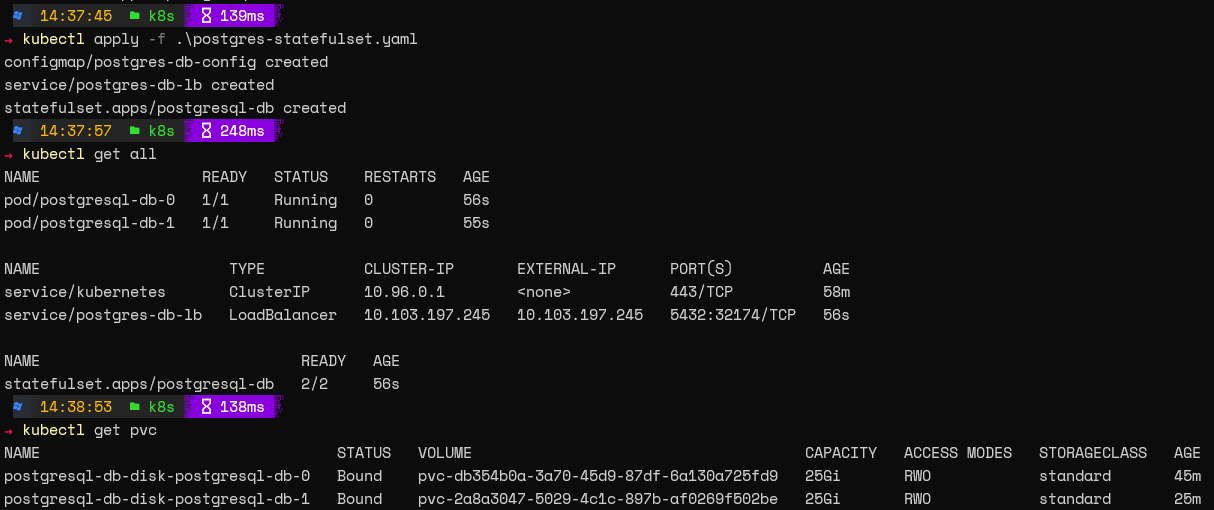
Вот и всё! Вы успешно настроили базу данных Postgres на Kubernetes.
Получение доступа к базе данных
Поскольку теперь у нас есть запущенные поды, давайте обратимся к базе данных. Поскольку мы уже настроили службу, мы можем получить доступ к базе данных, используя внешний IP этой службы. Используя клиент Arctype, укажите данные сервера — пользователя по умолчанию и базу данных (Postgres), после чего протестируйте соединение.
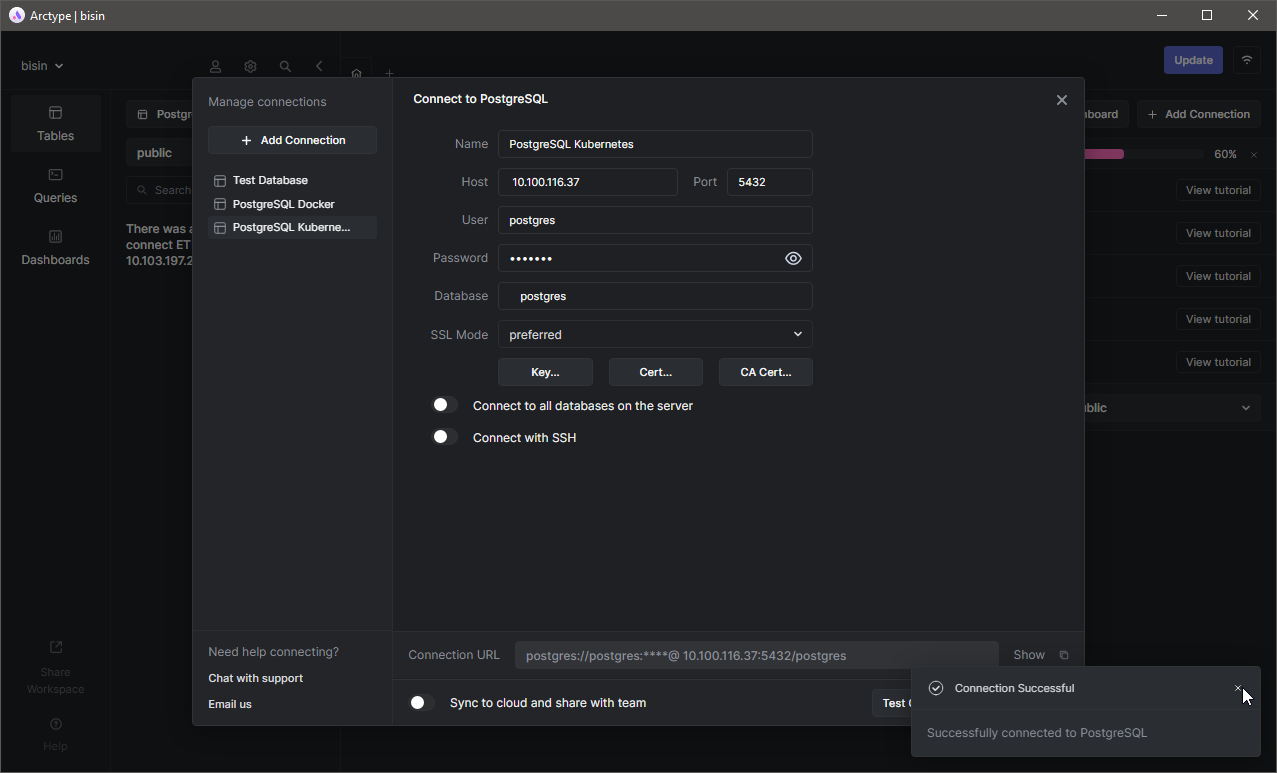
Как и в примере с docker, давайте создадим таблицу test_data_table и добавим в неё несколько записей. Здесь мы удалим весь StatefulSet. Если мы все настроили правильно, данные останутся, а поды будут удалены.

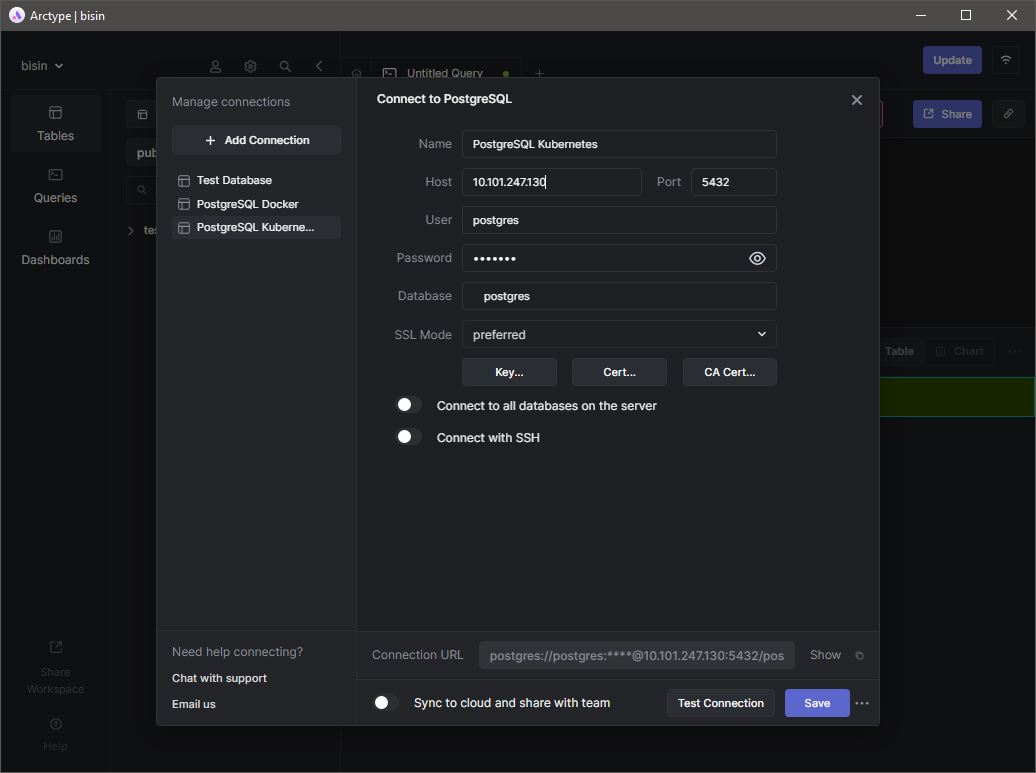
Теперь давайте перезагрузим StatefulSet и попробуем получить доступ к базе данных. Поскольку это новое развёртывание, вы увидите новый связанный со службой внешний IP.
Измените строку конфигурации соединения в клиенте Arctype SQL и попытайтесь подключиться.
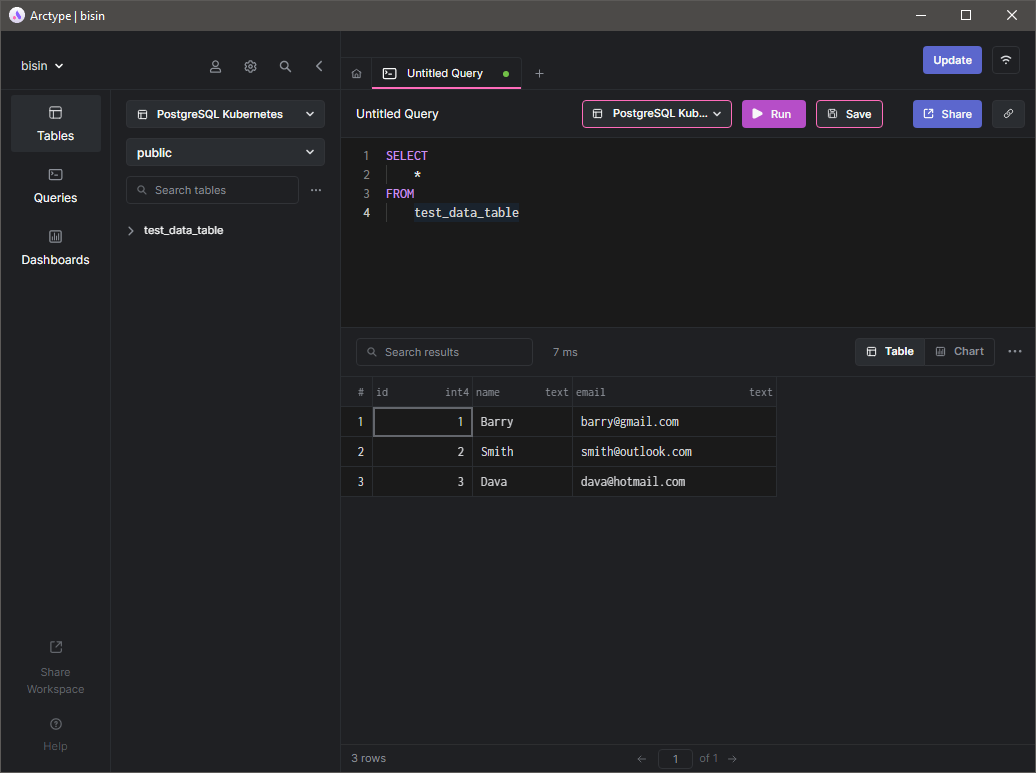
Затем вы увидите таблицу, которую мы создали ранее. Вы сможете открыть все данные в таблице, выполнив команду SELECT, что означает, что данные будут доступны независимо от состояния подов.
Лучшие методы работы с подами баз данных
Существует несколько классных методов, которым стоит следовать при развёртывании баз данных в Kubernetes, чтобы добиться максимальной надёжности и производительности.
- Используйте Kubernetes Secrets для хранения конфиденциальной информации, такой как пароли и т.д. Хотя мы и хранили пароль пользователя в открытом виде в нашей конфигурации для простоты, любая конфиденциальная информация в производственной среде должна храниться в секретах Kubernetes и использоваться только по мере необходимости.
- Внедрите ограничения на использование ресурсов процессора, оперативной памяти и хранилища. Это поможет управлять ресурсами в кластере и гарантирует, что поды не будут перерасходовать ресурсы.
- Всегда настраивайте резервное копирование томов. Даже если поды можно воссоздать, вся база данных станет непригодной для использования, если основные тома данных будут повреждены.
- Внедряйте сетевые политики и RBAC для контроля входа и пользователей, которые могут изменять эти ресурсы, для достижения наилучшей производительности и безопасности.
- Используйте отдельные пространства имён, чтобы изолировать базы данных от обычных приложений и управлять подключением через службы.
Заключение
Создание контейнерных баз данных даёт пользователям возможность задействовать все преимущества контейнеризации и применять их к базам данных. Такая контейнеризация подходит для любой базы данных, от лидеров рынка, таких как MySQL и Postgres, до более новых претендентов, разработанных с нуля специально для облачных приложений. Например, Yugabytedb — это новая база данных, которая может быть запущена в любой среде Kubernetes, например, Amazon EKS. Управление контейнерными базами данных позволяет пользователям создавать отказоустойчивые, высокодоступные и масштабируемые архитектуры баз данных, используя лишь малую часть ресурсов, необходимых для развёртывания традиционных баз данных.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
