Кодирование с изъятием информации. Часть 2-я, математическая
Введение
В предыдущей части рассматривалась принципиальная возможность кодирования при котором, в случае, если можно выделить общую часть у ключа и сообщения, то передавать можно меньше информации чем есть в исходном сообщении.

Позвольте немного расскажу откуда вообще взялась эта тема. Давным-давно от одного хорошего человека- ivlad взял почитать и вот пока никак не отдам (прости пожалуйста) интересную книжку [1], где, написано: «в свою очередь криптография сама может быть разделена на два направления, известные как перестановка и замена».
Соответственно почти сразу появились следующий вопросы:
- т.к. перестановка и замена сохраняют количество информации, то можно ли сделать так, чтобы обойти это ограничение, и передавать информации меньше чем есть в сообщении, — отсюда (из «а не слабо ли») родилась первая часть;
- если задача выглядит решаемой, то есть ли само решение и хотя бы толика математического смысла в нём — этот вопрос и есть тема этой части;
- есть ли во всём этом практический смысл — вопрос пока открыт.
Что общего у ворона и письменного стола?
Загадка Кэрролла в заголовке дана как иллюстрация проблемы, которую необходимо решить. А именно: определить пару функций  — кодирования и
— кодирования и  — декодирования, удовлетворяющих следующим условиям:
— декодирования, удовлетворяющих следующим условиям:
 –объём передаваемой информации по Шеннону меньше объёма информации в исходном сообщении
–объём передаваемой информации по Шеннону меньше объёма информации в исходном сообщении — функция декодирования, применённая к закодированному сообщению, позволит однозначно восстановить исходное сообщение.
— функция декодирования, применённая к закодированному сообщению, позволит однозначно восстановить исходное сообщение.
Здесь  — объём информации по Шеннону [2] (в предположении, что все символы встречаются равновероятно, что в общем случае неверно, но для используется для простоты изложения) в сообщении
— объём информации по Шеннону [2] (в предположении, что все символы встречаются равновероятно, что в общем случае неверно, но для используется для простоты изложения) в сообщении  ,
,  — ключ,
— ключ,  — закодированное сообщение.
— закодированное сообщение.
Для того, чтоб упростить себе дальнейшие рассуждения давайте ограничимся в дальнейшем сообщениями, которые можно привести в числовую форму, что с одной стороны нас не особо ограничивает (т.к. любому символу можно присвоить соответствующий числовой код), а с другой позволит воспользоваться математикой в нужном объёме.
Итак, рассмотрим сначала для примера два числа  и
и  и, воспользовавшись основной теоремой арифметики [4] (любое натуральное можно разложить на произведение простых) найдём следующие параметры:
и, воспользовавшись основной теоремой арифметики [4] (любое натуральное можно разложить на произведение простых) найдём следующие параметры:
- Наименьший общий делитель и —
 , его простые делители
, его простые делители ![$[2,3,11,19]$](https://habrastorage.org/getpro/habr/formulas/1c6/9db/a58/1c69dba58062d563490314fa8c7ee239.svg) ,
, - Частное
 и его простые делители
и его простые делители ![$[5,7,17]$](https://habrastorage.org/getpro/habr/formulas/daa/a54/4d1/daaa544d1233abfac3a57f76fd8a5993.svg) , которое обозначим как
, которое обозначим как  ,
, - Разложение числа на простые множители:
![$[2,3,11,19, 39 979]$](https://habrastorage.org/getpro/habr/formulas/1ca/5ea/c5f/1ca5eac5f298e1fd3a5b96877428e6b1.svg) ,
, - Разложение числа на простые множители:
![$[2,3,5,7,11,17,19]$](https://habrastorage.org/getpro/habr/formulas/687/69a/899/68769a899f73bfa8170253ebd14f6b85.svg) .
.
Запишем всё это в табличном виде, где синим помечена общая часть информации между ключом и сообщением, жёлтым — информация уникальная для ключа, оранжевым — уникальная для сообщения:
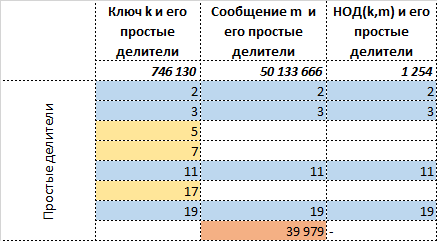
Сразу же становится видно, что  представляет из себя общую часть между ключом и сообщением , которая есть и у отправителя и у получателя. Таким образом, в идеале конечно, а не в реальности, достаточно передать информацию об:
представляет из себя общую часть между ключом и сообщением , которая есть и у отправителя и у получателя. Таким образом, в идеале конечно, а не в реальности, достаточно передать информацию об:
- уникальной для сообщения информации — том, что не относится к т.е.
![$[39 979]$](https://habrastorage.org/getpro/habr/formulas/828/fa6/98a/828fa698a2bc4e648706717d6c6a2e33.svg) , а именно
, а именно  ,
,
- самом , но так, чтобы его нельзя было бы восстановить.
Пометим теперь позиции простых делителей общие с простыми делителями , единицами, а остальные, кроме, может быть ведущей позиции — нулями.
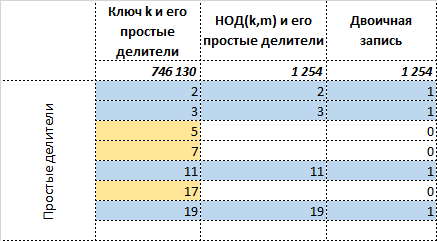
Получившееся число  в достаточной степени характеризует
в достаточной степени характеризует  , позволяя тем самым восстановить исходное сообщение. Т.е. получив на вход два числа
, позволяя тем самым восстановить исходное сообщение. Т.е. получив на вход два числа ![$[39 979, 83]$](https://habrastorage.org/getpro/habr/formulas/edf/1d8/52b/edf1d852bdf7c7bc1e8ab0d1cad463e4.svg) необходимо сделать достаточно простое обратное преобразование:
необходимо сделать достаточно простое обратное преобразование:
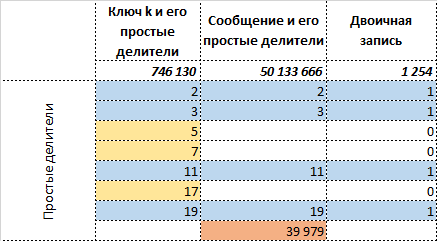
Если теперь оценить длину исходного сообщения в двоичном виде ![$len_2(m) = len_2([1111010000011100100000100])= 26$](https://habrastorage.org/getpro/habr/formulas/0a5/efb/52d/0a5efb52d3f8fd5b79a50a30e5eb519e.svg) и сообщения
и сообщения ![$len_2([c_0,c_1])= len_2([1001110000101011, 1010011]) = 23$](https://habrastorage.org/getpro/habr/formulas/55f/f6f/8dd/55ff6f8dd5a1ff4b389734d87086bebf.svg) , то видно, что можно получить экономию длины сообщения в
, то видно, что можно получить экономию длины сообщения в  бита, то же самое и с количеством информации
бита, то же самое и с количеством информации  бит,
бит, ![$I(c)=I([c_0,c_1])=11.5$](https://habrastorage.org/getpro/habr/formulas/916/bf1/c33/916bf1c338b0de7b75a9f0d2a9aa3b72.svg) бита. Здесь функция
бита. Здесь функция  — длина числа в двоичном виде.
— длина числа в двоичном виде.

Таким образом, выражаясь словами из известного анекдота «в Шотландии есть как минимум одна овца, черная как минимум с одной стороны» [3].
Итак, что на данный момент имеем — данный способ кодирования подходит, но только для пар чисел, имеющих в разложении одинаковые делители. В противном случае, если, например, взять в качестве ключа и в качестве сообщения простые числа, то очевидным образом мы ничего сократить не сможем, а только увеличим и длину сообщения, как и количество передаваемой информации, а это вовсе не то, чего добивались. Эта же ситуация повторяется и в случае когда, например,  или же
или же  т.к. экономия будет либо минимальной либо будет отсутствовать в принципе.
т.к. экономия будет либо минимальной либо будет отсутствовать в принципе.
Что делать…
для того, чтобы повысить вероятность успеха при таком способе кодирования?
В общем-то если внимательно посмотреть на ключ, то видно, что он неплохо делится на простые числа  , что сделано специально для успешности операции нахождения . Так как такая операция негативно может повлиять на количество используемых ключей, то определяя порядок следования простых множителей и сделав его частью ключевой информации, получим, хоть и не радикальное, но увеличение количества вариантов кодирования, что положительным образом отразиться на количестве ключей. Использовав вместо ключа не число
, что сделано специально для успешности операции нахождения . Так как такая операция негативно может повлиять на количество используемых ключей, то определяя порядок следования простых множителей и сделав его частью ключевой информации, получим, хоть и не радикальное, но увеличение количества вариантов кодирования, что положительным образом отразиться на количестве ключей. Использовав вместо ключа не число ![$[746 130]$](https://habrastorage.org/getpro/habr/formulas/86e/89d/9d6/86e89d9d649251c7786e0d0e0ffb0a76.svg) , а пару
, а пару ![$[746 130, 0125763]$](https://habrastorage.org/getpro/habr/formulas/b34/784/2b6/b347842b6d53e32888641b5c9be28101.svg) , где второе число отражает порядок перемножения и определяет значение
, где второе число отражает порядок перемножения и определяет значение  .
.
Следующая проблема, которую предстоит эффективно решить — соотношение частот появления простых чисел и степеней двойки, -легко заметить, что эффективность кодирования степенями двойки довольно быстро падает с ростом длины (см. график соответствующих последовательностей если есть один общий простой делитель) и зависит в основном от количества делителей ключа и их значений.
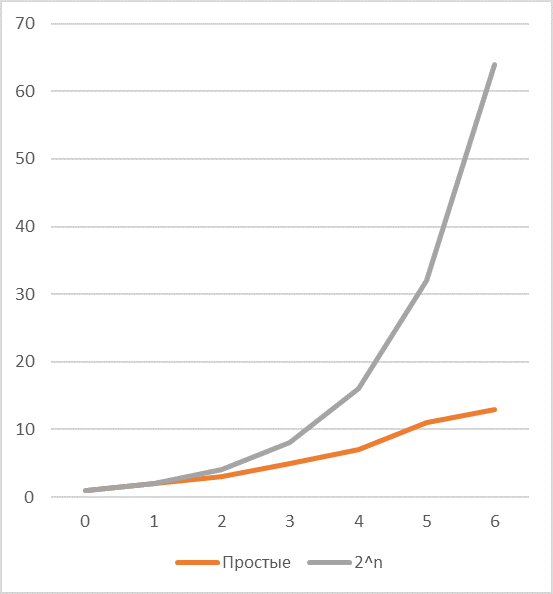
В случае если, общих делителей два и один из них, например, равен , то возможности по экономии возрастают весьма заметно.
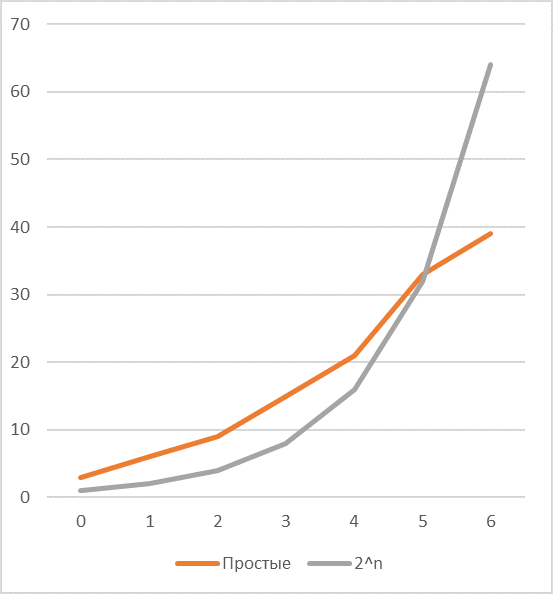
Что означает, что для эффективного кодирования необходимо придумать более эффективный способ кодирования .
То есть тему есть смысл прокапывать дальше.
Пример
Как обычно выложены на github [5] — используется Excel т.к. он есть у многоих и нет необходимости думать о совместимости. В файле две закладки:
- «Тест» — сами вычисления и т.к. в них довольно активно используется функция Excel «СЛУЧМЕЖДУ ()» и числа ключа и сообщения могут оказаться взаимно простые, то придётся несколько раз встать в какую либо ячейку и нажать
enterдля того, чтобы получить искомую экономию (результаты в строчках 31–36); - «Пример 1» — приведены примеры готовых вычислений, т.к. случайность в excel не оставляет им шанса на повторение.
Ссылки
- Сингх Саймон. Книга шифров. Тайная история шифров и их расшифровки. М. Астрель 2007.
- https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D1%8D%D0%BD%D1%82%D1%80%D0%BE%D0%BF%D0%B8%D1%8F
- http://www.gaelic.ru/Biblioteka/Folklore/anekdoty.htm
- https://ru.wikipedia.org/wiki/%D0%9E%D1%81%D0%BD%D0%BE%D0%B2%D0%BD%D0%B0%D1%8F_%D1%82%D0%B5%D0%BE%D1%80%D0%B5%D0%BC%D0%B0_%D0%B0%D1%80%D0%B8%D1%84%D0%BC%D0%B5%D1%82%D0%B8%D0%BA%D0%B8
- https://github.com/rumiantcev/nod_code
