[Из песочницы] Akumuli — база данных временных рядов
Привет! В этой статье я хочу рассказать о проекте Akumuli, специализированной базе данных для сбора и хранения временных рядов. Я работаю над проектом уже больше четырех лет и достиг высокой стабильности, надежности, и возможно изобрел кое-что новое в этой области.
Временной ряд это упорядоченная во времени последовательность измерений, если говорить максимально просто, это то что можно нарисовать на графике. Временные ряды естественным образом возникают во многих приложениях, начиная с финансов и заканчивая анализом ДНК. Наиболее широкое применение базы данных временных рядов находят в мониторинге инфраструктуры. Там же часто наблюдаются самые серьезные нагрузки.
«Мне не нужна TSDB, у меня уже есть Х»
Х может быть чем угодно, начиная с SQL базы данных и заканчивая плоскими файлами. На самом деле все это действительно можно использовать для хранения временных рядов, с одной оговоркой — у вас мало данных. Если вы делаете 10 000 вставок в свою SQL базу данных — все будет хорошо какое-то время, потом таблица вырастет в размерах настолько, что время выполнения операций вставки увеличится.
Вы начнете их группировать перед вставкой, это поможет, но теперь у вас появилась новая проблема — данные приходится где-то накапливать, а значит можно потерять все что не успело записаться в БД. Следующий шаг — попытаться использовать какую-нибудь хитрую схему, например хранить в одной строке не одно измерение (id + метку времени + значение), а несколько (id + метку времени + значение + значение через 10сек + значение через 20сек + …). Это увеличит пропускную способность на запись, но породит новые проблемы. Место стремительно заканчивается так как сжатие не очень, нужно хранить временные ряды с разным шагом, нужно хранить временные ряды с переменным шагом, нужно считать агрегации (максимальное значение за интервал), нужно сделать из временного ряда с шагом 10 секунд временной ряд с шагом 1 час.
Все эти проблемы преодолимы, нужно просто написать свою TSDB поверх SQL сервера или flat файлов или Cassandra или даже Pandas. На самом деле, многие люди уже прошли этот путь, об этом можно догадаться по количеству уже существующих TSDB, работающих поверх какой-нибудь другой DB. Akumui отличается от них тем, что использует специализированное хранилище на основе оригинальных алгоритмов.
Дизайн
Проблему, которую решает TSDB можно свести к тому что данные записываются в одном порядке, а читаются в другом. Представим что у нас есть миллион временных рядов, раз в секунду в каждый из них нужно записать одно значение с текущей меткой времени. Чтобы их быстро записывать, нужно записывать их в том порядке, в котором они приходят. К сожалению, если мы захотим прочитать один час данных одного временного ряда, мы должны будем прочитать все 3600×1000000 точек, отфильтровать большую часть данных и оставить только 3600. Это называется read amplification и это плохо.
К сожалению, примерно это делают очень многие TSDB. Разница лишь в том, что данные а) сжимаются б) разбиваются на блоки небольшого размера, каждый из которых имеет колумнарный формат (т.н. PAX) который позволяет не разбирать все содержимое, а сразу перейти к нужным данным.
Я решил пойти по другому пути (впрочем сначала я попробовал PAX) и реализовал колумнарное хранилище в каждой колонке которого хранится отдельный временной ряд. Это позволяет читать только те данные, которые нужны запросу. Современные SSD и NVMe не нуждаются в том, чтобы данные, к которым обращается БД, лежали строго последовательно, но их пропускная способность ограничена, поэтому для БД очень важно читать только то что действительно нужно, а не экономить disk seeks. Раньше все было наоборот, мы меняли пропускную способность на disk seeks, многие структуры данных построены вокруг этого компромисса (привет LSM-tree). Akumuli делает наоборот.
Сжатие
Это самый важный аспект для TSDB, т.к. сжатие сильно влияет на компромиссы, баланс которых лежит в основе дизайна любой БД. Для Akumuli я разработал, как мне кажется, довольно неплохой алгоритм. Он сжимает метки времени и значения используя по сути два разных алгоритма. Я не хочу вдаваться в детали слишком сильно, для этого есть whitepaper, но я постараюсь дать хорошую вводную.
Точки (время + значение) объединяются в группы по 16 и сжимаются вместе. Это позволяет записать алгоритм в виде простых циклов обрабатывающих массивы фиксированной длины, которые компилятор может хорошо оптимизировать и векторизовать. В hot path нет ветвлений, которые branch predictor не может предсказать в абсолютном большинстве случаев.
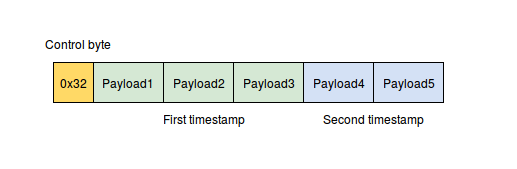
Метки времени сжимаются следующим образом: сначала применяется delta-delta кодировка (сначала считаются дельты, затем из каждой дельты вычитается минимальный элемент), затем это все сжимается с помощью VByte кодировки. VByte кодировка похожа на то что используется в protocol buffers с той лишь разницей, что здесь не требуются побитовые операции, это работает быстрее. Это достигается за счет того, что метки времени объединяются в пары и метаданные каждой пары (control byte) хранятся в одном байте.
Для сжатия значений используется предиктивный алгоритм, который пытается предугадать следующее значение используя differential finite context method (DFCM) predictor.
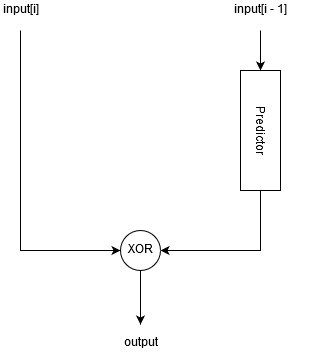
Далее, алгоритм XOR-ит предсказанное и актуальное значения между собой, в результате чего получается строка бит с большим количеством нулей в конце или в начале. Данная строка бит кодируется следующим образом:
Мы считаем количество нулей в начале и в конце строки, если в начале строки нулей больше, устанавливаем специальный флаг.
Считаем сколько байт (N) нужно для того, чтобы записать данную битовую строку (с учетом флага).
Сдвигаем битовую строку влево на 64 — N*8 бит если флаг установлен.
Записываем в выходной буфер первые N байт битовой строки.
В итоге, у нас есть N байт данных, но помимо этого мы должны сохранить метаданные — значение N и флаг, это четыре бита. Для экономии места я объединяю значения в пары и записываю сначала байт с метаданными для обоих значений (control byte), а затем сами значения.
Помимо этого используется еще один трюк. Если мы имеем дело с «удобными» данными, данный алгоритм может предсказать следующее значение со 100% точностью. В мониторинге такое встречается довольно часто, там иногда значения не меняются на протяжении долгого времени, либо растут с постоянной скоростью. В этом случае, после XOR-а мы будем всегда получать нулевые значения. Для того чтобы не кодировать каждое из них целой половиной байта, в алгоритме есть специальный случай — если все 16 значений можно предсказать, он записывает специальный control byte и больше ничего. Получается, что в этом случае мы тратим на значение меньше бита. Подобный shortcut реализован и для меток времени, для случая если измерения имеют фиксированный шаг.
Данный алгоритм не имеет ветвлений и работает on byte boundary. Скорость сжатия, по моим измерениям, составляет порядка 1Гб/сек.
Storage Engine
Каждый временной ряд представлен на диске в виде отдельной структуры данных. Я называю ее Numeric B+tree, т.к. она предназначена для хранения числовых данных, но по сути, это LSM-дерево сегментами которого являются B+деревья. Обычно (но не обязательно) сегменты (SSTables) реализуются как отсортированные массивы.

Роль MemTable в этом LSM-дереве выполняет единственный лист B+дерева. Когда он заполняется данными, он отправляется на второй уровень, где просто присоединяется к другому B+дереву, состоящему из двух уровней. Когда это дерево заполняется, оно отправляется на третий уровень, присоединяясь к В+дереву состоящему из трех уровней и тд. У меня есть whitepaper подробно описывающий данный процесс.
Такая структура данных позволяет:
- Сливать сегменты не читая их с диска целиком (как это делает обычный LSM-tree). Akumuli не читает данные с диска, чтобы выполнить запись. Благодаря этому читатели не могут замедлить процесс записи израсходовав пропускную способность диска на чтение.
- Иметь очень много независимых деревьев в одном файле. Узлы разных деревьев просто перемежаются на диске друг с другом. Благодаря этому, запись на диск по прежнему происходит последовательно. Чтение одной серии выбирает данные с диска в случайном порядке, но для современных SSD это не проблема.
- Оптимизация для SSD и NVMe дисков. Все операции чтения и записи выровнены по границе блока (что уменьшает write amplification). И запись и чтение могут выполняться параллельно (без чего сложно сатурировать современный SSD). БД готова к появлению byte addressable устройств (вроде Intel Optane SSDs), т.к. умеет отображать данные в память и читать/писать с еще большей гранулярностью.
- Выполнять восстановление после сбоев без использования WAL. Это сложная проблема, детали решения которой раскрыты в статье. Если коротко, то Akumuli не использует WAL и для восстановления после сбоев используются дополнительные ссылки между узлами дерева.
- Multiversion concurrency control позволяет искоренить ошибки синхронизации как класс. И запись и чтение могут выполняться параллельно, читатели/писатели не зависят друг от друга и тд и тп.
У этого подхода есть и недостатки:
- Данные должны записываться в порядке увеличения меток времени.
- При падении можно потерять данные, которые были записаны последними, скажем, последние 5 минут данных мониторинга.
Рано или поздно эти проблемы будут решены, но пока они не решены их следует принимать во внимание.
Обработка запросов
Мне хотелось получить что-то похожее по возможностям на Pandas data frames. В первую очередь, иметь возможность прочитать данные в любом порядке и сгруппировать их как угодно — в порядке увеличения меток времени или наоборот, сначала данные одной серии, затем данные следующей (запрос может возвращать много временных рядов), либо сначала данные всех серий с одной меткой времени, затем данные всех серий в том же порядке со следующей меткой времени и тд. Мой опыт показывает, что это обязательно нужно уметь, т.к. размер запрашиваемых данных может превышать объем ОЗУ у клиента и он просто не сможет переупорядочить их локально, но если данные приходят в правильном порядке, он сможет обработать их по частям.
Помимо этого, хотелось иметь возможность сливать несколько рядов в один, просто объединяя точки, либо join-ить несколько временных рядов по меткам времени, агрегировать данные ряда (min, max, avg, etc), агрегировать с шагом (resample), вычислять всякие функции (rate, abs, etc).
Обработчик запросов, в его текущем виде, имеет иерархическую структуру. На нижнем уровне работают операторы, оператор всегда работает с данными одной колонки, соответствующей одному временному ряду и хранящейся в одном дереве. Операторы, это что-то вроде итераторов. Они реализованы на уровне хранилища и умеют использовать его особенности. В отличии от итераторов, операторы БД умеют не только читать данные, они могут агрегировать и фильтровать, причем эти операции могут выполняться на сжатых данных (не всегда).
Операторы могут пропускать (search pruning) части дерева даже не читая их с диска. Например, если запрос читает данные без downsample преобразования, то будет использован оператор scan, который просто возвращает данные как есть, но если запрос выполняет group aggregate с каким-либо шагом, будет использован другой оператор, который умеет делать downsampling не читая все с диска.
Следующий этап — материализация результатов запроса (Akumuli выполняет только раннюю материализацию). Из данных, которые возвращают операторы, формируются кортежи, основные операции плана (например join) выполняются уже на материализованных данных. Здесь же выполняются всевозможные функции (например rate).
Вся обработка выполняется ленивым образом. Сначала обработчик запросов формирует конвейер из операторов, а затем через него прогоняются данные. Скорость чтения и обработки данных зависит от того, с какой скоростью клиент их читает, т.е. если вы прочитали часть результатов запроса и остановились, запрос перестанет выполняться на сервере. На практике это означает, что клиентское приложение может обрабатывать данные в потоковом режиме, причем эти данные вовсе не обязаны помещаться в ОЗУ клиента или даже сервера.
Тесты
Самое интересное в этом проекте, это тестирование. Тестирование происходит в автоматическом режиме на CI сервере (я использую Travis-CI). В проекте применяются следующие виды тестов:
- Первый этап — модульное тестирование. Модульные тесты отрабатывают примерно за минуту-две, они не трогают диск, поэтому работают довольно быстро. Они редко находят регрессии, но зато когда находят, дают больше всего информации о том, где находится проблема.
- Интеграционные тесты. Это приложение, использующее libakumuli — библиотеку, реализующую систему хранения данных. Оно содержит множество простых тестов с небольшим объемом данных. Задача теста состоит в том, чтобы убедиться в том, что контракты не сломались, т.е. в том что поведение функций API библиотеки не изменилось.
- Функциональные тесты. Эти тесты (их больше 20-ти) написаны на питоне и они работают на самом высоком уровне. Каждый тест это отдельный скрипт, который создает новую БД, запускает сервер БД и что-нибудь делает. Например, у меня есть тест, который просто записывает данные и проверяет что все записалось, есть тест, проверяющий все возможные варианты запросов, тест, убивающий сервер БД через kill -9, чтобы проверить crash recovery и т.д. Это самые важные тесты, которые находят больше всего проблем. Обычно сюда я добавляю регрессии — тесты, которые проверяют уже исправленные проблемы.
- Roundtrip тест. Это простой, на первый взгляд, тест, написанный целиком на bash. Он скачивает с S2 несколько сотен МБ тестовых данных в готовом для записи виде, создает БД, запускает сервер БД, записывает в него тестовые данные, затем он формирует join запрос, который должен выдать все записанные данные ровно в том же формате что и тестовые данные. Если все прошло успешно, оба файла идентичны и тест успешно пройден. Это выполняется дважды, для двух входных форматов данных (RESP и OpenTSDB).
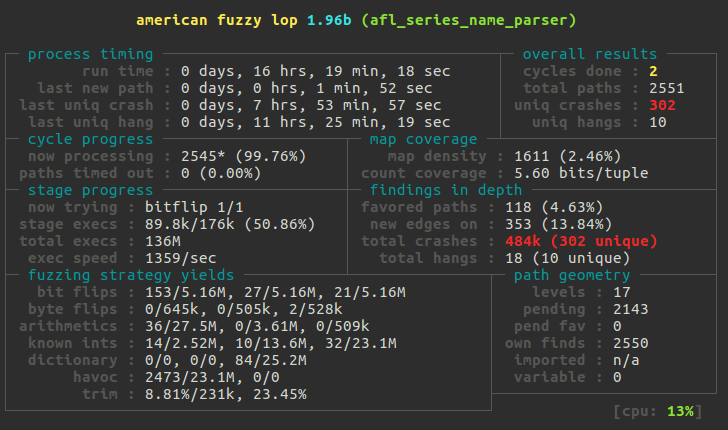
- Fuzz тесты. Эти тесты запускаются вручную. Они проверяют алгоритм сжатия и код, который парсит входные данные, например код разбирающий метки времени и имена временных рядов. Когда pull request затрагивает один из этих участков кода, я запускаю AFL с соответствующим тестом на несколько дней на специально созданном EC2 инстансе в AWS. Eye opening experience!
- Randomized tests. Самая странная разновидность тестов. В некоторых случаях я добавляю специальный код, который делает что-нибудь с очень низкой вероятностью. Например генерирует ошибку при попытке прочитать данные с диска, чтобы не ждать пока она произойдет на самом деле. Из недавнего — я работал над изменением данных в прошлом с использованием shadow pages и для того, чтобы проверить, что запись в прошлое ничего не сломает, я добавил код, который делает то же самое, что делает процедура записи в прошлое ничего при этом не меняя. Этот код вызывался в процессе работы с низкой вероятностью и применялся к случайной точке временного ряда. Собрав БД с этими изменениями я много часов крутил интеграционные тесты на AWS инстансе, пока там что-нибудь не падало, а затем исправлял ошибку и начинал все заново, до тех пор, пока ошибки перестали появляться. Естественно, это не выполняется на CI сервере, мало того, подобный код я всегда удаляю, чтобы он случайно не попал в master.
Benchmarks
Обычно Akumuli может выполнять порядка 0.5 миллионов операций записи в секунду на каждое ядро. Т.е. на двухядерной машине будет порядка 1М, на 4х — 2М и тд. В этой статье я описал процесс тестирования на 32х ядерной машине, там получилось примерно 16 миллионов операций записи в секунду. Для создания такой нагрузки потребовалось четыре машины (m3.xlarge instance). Тестовые данные были подготовлены заранее (максимально приближенные к тому что выдает реальный коллектор, в RESP формате, 16GB в сжатом виде), т.к. для того, чтобы генерировать их на лету, потребовалось бы еще больше вычислительных ресурсов. Я запустил тест через parallel-ssh одновременно на всех машинах и меньше чем через три минуты все было записано. Во время теста БД писала на диск со скоростью 64МБ/сек.
Еще я тестировал скорость чтения вот здесь. Объемы данных там довольно небольшие и все помещается в память, но перед началом тестирования я перезапускал сервер БД и очищал дисковый кэш. Я уверен, что на больших объемах данных и при активной записи в БД Akumuli будет вести себя очень хорошо.
Планы на будущее
В данный момент я работаю над решением проблемы записи в прошлое. Это нужно в том числе и для того, чтобы можно было реализовать репликацию данных и HA. У меня уже есть одна реализация на основе shadow pages, теперь работаю над альтернативным вариантом, использующим WAL. Думаю один из этих двух вариантов попадет в итоге в master, но произойдет это не скоро, т.к. требует серьезного тестирования и железа, а из железа у меня есть только ультрабук, так что привет AWS ES2.
Еще одно направление развития это всевозможные интеграции и инструменты. Я реализовал поддержку протокола OpenTSDB и теперь Akumuli можно использовать вместе с большим количеством коллекторов, вроде collectd. Еще у меня есть плагин для Grafana, который ждет своей очереди на включение в их plugin store. Еще я поглядываю на Redash, правда пока не уверен, что это кому-нибудь может быть нужно.
Akumuli это open source проект, опубликованный под лицензией Apache 2.0. Вы можете найти исходный код здесь. Здесь можно взять docker контейнер с последней стабильной сборкой, а здесь — плагин для графаны. Проекту можно помочь прислав pull-request или bug report.
