Книга «Внутри CPYTHON: гид по интерпретатору Python»
 Привет, Хаброжители!
Привет, Хаброжители!
CPython, самая популярная реализация Python, абстрагируется от сложностей ОС и предоставляет платформу для создания масштабируемых и высокопроизводительных приложений. Каждому python-разработчику на какой-то стадии необходимо будет узнать, как работает CPython. Это позволит в полной мере использовать его мощь и оптимизировать приложения. Вы разберетесь с основными концепциями внутреннего устройства CPython и научитесь: читать исходный код интерпретатора CPython и свободно ориентироваться в нем; вносить изменения в синтаксис Python и компилировать их в вашу собственную версию CPython; понимать внутреннюю реализацию таких структур, как списки, словари и генераторы; управлять памятью CPython; масштабировать код Python за счет параллелизма и конкурентного выполнения; дополнять базовые типы новой функциональностью; выполнять наборы тестов; профилировать и проводить бенчмарк Python-кода и исполнительной среды; отлаживать код C и Python на профессиональном уровне; изменять или обновлять компоненты библиотеки CPython, чтобы они могли использоваться в будущих версиях.
Грамматика и язык Python
Компилятор предназначен для преобразования одного языка в другой. Его можно сравнить с переводчиком: вы нанимаете переводчика, который слушает, как вы говорите на английском, а потом повторяет ваши слова на другом языке — скажем, на японском.
Для этого переводчик должен понимать грамматические структуры как исходного, так и целевого языка.
Некоторые компиляторы выполняют компиляцию в низкоуровневый машинный код, который может напрямую выполняться в системе. Другие компиляторы компилируют код в промежуточный язык, который выполняется виртуальной машиной.
Одним из факторов при выборе компилятора становятся требования к портируемости системы. Java и .NET CLR выполняют компиляцию в промежуточный язык, чтобы cкомпилированный код мог переноситься между разными системными архитектурами. C, Go, C++ и Pascal компилируются в исполняемые двоичные файлы. Двоичный файл собирается для той платформы, на которой он компилировался.
Приложения Python обычно поставляются в виде исходного кода. Интерпретатор Python должен преобразовать исходный код Python и выполнить его в один этап. Среда выполнения CPython компилирует код при первом выполнении. Этот шаг остается незаметным для рядового пользователя.
Код Python не компилируется в машинный код. Он компилируется в низкоуровневый промежуточный язык, который называется байт-кодом. Байт-код хранится в файлах .pyc и кэшируется для выполнения. Если одно приложение Python будет выполняться дважды без изменения исходного кода, то второй запуск будет проходить быстрее. Это связано с тем, что приложение запустит cкомпилированный байт-код, вместо того чтобы каждый раз компилировать его заново.
ПОЧЕМУ CPYTHON НАПИСАН НА C, А НЕ НА PYTHON
Буква C в CPython относится к языку программирования C — она означает, что этот дистрибутив Python написан на языке C.
В основном так и есть. Компилятор в CPython написан на чистом C. Тем не менее многие модули стандартной библиотеки написаны на чистом Python или комбинации C и Python.
Так почему же компилятор CPython написан на C, а не на Python?
Ответ основан на принципах работы компиляторов. Существуют две разновидности компиляторов:
1. Автономные компиляторы пишутся на том языке, который они компилируют (как компилятор Go). Для этого используется процесс, называемый самозапуском (bootstrapping).
2. Компиляторы типа «исходный код в исходный код» пишутся на другом языке, для которого уже существует компилятор.
Если вы создаете новый язык программирования с нуля, то вам понадобится исполняемое приложение для компиляции вашего компилятора! Для выполнения чего-либо нужен компилятор, поэтому при разработке новых языков они часто сначала пишутся на старых, более укоренившихся языках.
Также существуют инструменты, которые могут взять спецификацию языка и построить для него парсер; вы узнаете о них позднее в этой главе. Среди популярных «компиляторов компиляторов» можно выделить GNU Bison, Yacc и ANTLR.
СМ. ТАКЖЕЕсли вы захотите больше узнать о парсерах, ознакомьтесь с проектом Lark — парсером для контекстно-независимой грамматики, написанным на Python.
Отличным примером самозапуска компилятора служит язык программирования Go. Первый компилятор Go был написан на C; после того как код Go стал компилироваться, компилятор был переписан на Go.
В отличие от этого, CPython сохраняет свое наследование C. Многие модули стандартной библиотеки (такие, как sslmodule или socketsmodule) переписаны на C для обращения к низкоуровневым API операционной системы.
API ядер Windows и Linux, предназначенные для создания сетевых сокетов, работы с файловой системой или взаимодействия с экраном, были написаны на C, поэтому логично, что уровень расширяемости был ориентирован на язык C. Стандартная библиотека Python и модули C будут рассмотрены далее.
Существует компилятор Python, написанный на Python, — он называется PyPy. На логотипе PyPy изображен уроборос, олицетворяющий природу самодостаточности компилятора.
ПРИМЕЧАНИЕ
В оставшейся части книги обозначение ./python будет относиться к скомпилированной версии CPython. Тем не менее реальная команда будет зависеть от операционной системы.В Windows:
> python.exe
В Linux:$ ./python
В macOS:$ ./python.exe
Другой пример кросс-компилятора для Python — Jython. Jython написан на Java и компилирует исходный код Python в байт-код Java. Подобно тому как CPython упрощает импортирование библиотек C и использование их из Python, Jython упрощает импортирование и использование модулей и классов Java.
Первым шагом создания компилятора становится определение языка. Например, следующий фрагмент не является валидным Python-кодом:
def my_example() :
{
void* result = ;
}
Чтобы компилятор мог обработать код языка, ему необходимы строгие правила грамматической структуры этого языка.
СПЕЦИФИКАЦИЯ ЯЗЫКА PYTHON
В исходном коде CPython содержится определение языка Python. Этот документ представляет собой эталонную спецификацию, используемую всеми интерпретаторами Python.
Спецификация содержит как формат, рассчитанный на чтение человеком, так и формат для машинного чтения. В документации содержится подробное объяснение языка Python с описанием разрешенных конструкций и поведения каждой команды.
Документация языка
Каталог Doc ▶ reference содержит разъяснение особенностей языка Python в формате reStructuredText. Из этих файлов составлено официальное справочное руководство Python на сайте docs.python.org/3/reference.
В каталоге Doc находятся файлы, необходимые для понимания всего языка, его структуры и ключевых слов:

Пример
В файле Doc ▶ reference ▶ compound_stmts.rst встречается простой пример определения оператора with.
Оператор with существует в нескольких формах; простейший вариант — реализация менеджера контекста и вложенного блока кода:
with x():
...
Результат можно присвоить переменной при помощи ключевого слова as:
with x() as y:
...
Также можно объединять менеджеры контекстов в цепочку через запятую:
with x() as y, z() as jk:
...
Документация содержит спецификацию языка, предназначенную для чтения человеком. Спецификация, предназначенная для машинного чтения, располагается в одном файле Grammar ▶ python.gram.
Файл грамматики
Файл грамматики Python использует спецификацию в формате PEG (Parsing Expression Grammar). В файле грамматики могут использоваться следующие обозначения:
- * — повторение;
- + — минимум одно вхождение;
- [] — необязательные части;
- | — альтернативы;
- () — группировка.
Для примера представим, как можно было бы определить чашку кофе:
- Необходима чашка.
- Чашка должна содержать как минимум одну порцию эспрессо, но может содержать несколько порций.
- В чашке может быть молоко, но необязательно.
- В чашке может быть вода, но необязательно.
- Если в чашке молоко, то оно может быть разного типа — жирное, обезжиренное, соевое и т. д.
В формате PEG заказ кофе может выглядеть так:
coffee: 'cup' ('espresso')+ ['water'] [milk]
milk: 'full-fat' | 'skimmed' | 'soy'СМ. ТАКЖЕВ CPython 3.9 исходный код CPython содержит два файла грамматики. Старая — контекстно-свободная грамматика, которая называется формой Бэкуса — Наура (BNF). В CPython 3.10 файл грамматики BNF (Grammar ▶ Grammar) был удален.
Форма BNF не привязана к Python и часто используется для записи грамматики во многих других языках.
В этой главе для наглядного представления грамматики будут использоваться синтаксические диаграммы. Синтаксическая диаграмма для команды coffee выглядит так:
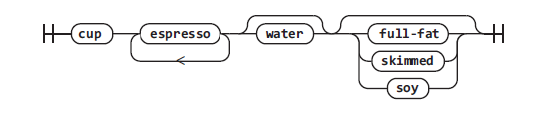
На синтаксической диаграмме каждая возможная комбинация должна располагаться на одной линии слева направо. Необязательные компоненты можно обойти, а некоторые компоненты могут образовывать циклы.
Пример: оператор while
Существует несколько разновидностей оператора while. Простейший вариант использования — когда за завершающим двоеточием (:) следует блок кода:
while finished == True:
do_things()
В альтернативном варианте используется оператор присваивания, которому в грамматике соответствует обозначение named_expression. Эта новая возможность появилась в Python 3.8:
while letters := read(document, 10):
print(letters)
Также за оператором while может следовать оператор else и блок кода:
while item := next(iterable):
print(item)
else:
print("Iterable is empty")
Проведя поиск while_stmt в файле грамматики, вы увидите определение:
while_stmt[stmt_ty]:
| 'while' a=named_expression ':' b=block c=[else_block] ...
Символы в кавычках образуют строковый литерал, который называется терминалом (terminal). В частности, терминалы используются для распознавания ключевых слов.
В этих двух строках содержатся ссылки на два других определения:
1. block обозначает блок кода с одним или несколькими операторами.
2. named_expression обозначает простое выражение или выражение присваивания.
Если представить оператор while в виде синтаксической диаграммы, она будет выглядеть так:

Рассмотрим более сложный пример. Оператор try определяется в грамматике так:
try_stmt[stmt_ty]:
| 'try' ':' b=block f=finally_block { _Py_Try(b, NULL, NULL, f, EXTRA) }
| 'try' ':' b=block ex=except_block+ el=[else_block] f=[finally_block]..
except_block[excepthandler_ty]:
| 'except' e=expression t=['as' z=target { z }] ':' b=block {
_Py_ExceptHandler(e, (t) ? ((expr_ty) t)->v.Name.id : NULL, b, ...
| 'except' ':' b=block { _Py_ExceptHandler(NULL, NULL, b, EXTRA) }
finally_block[asdl_seq*]: 'finally' ':' a=block { a }
У оператора try есть два варианта использования:
1. try только с оператором finally.
2. try с одним или несколькими блоками except, за которыми может следовать необязательный блок else, а после него необязательный finally.
Эти же варианты использования на синтаксической диаграмме:

Оператор try является хорошим примером более сложной структуры.
Если вы захотите понять язык Python на более глубоком уровне, прочитайте определение грамматики в Grammar ▶ python.gram.
ГЕНЕРАТОР ПАРСЕРОВ
Сам файл грамматики никогда не используется компилятором Python. Вместо этого генератор парсеров читает файл и генерирует парсер. Если в файл грамматики будут внесены изменения, вам придется заново сгенерировать парсер и перекомпилировать CPython.
В Python 3.9 парсер CPython был переписан из автомата, заданного в табличной форме (модуль pgen), в контекстный парсер грамматики. В Python 3.9 старый парсер доступен в командной строке (флаг -X oldparser), а в Python 3.10 он полностью удален. В книге речь идет о новом парсере, реализованном в версии 3.9.
ПОВТОРНОЕ ГЕНЕРИРОВАНИЕ ГРАММАТИКИ
Чтобы увидеть в действии pegen — новый генератор PEG, появившийся в CPython 3.9, — можно изменить часть грамматики Python. Проведите в Grammar — python.gram поиск small_stmt, чтобы увидеть определение простых операторов:
small_stmt[stmt_ty] (memo):
| assignment
| e=star_expressions { _Py_Expr(e, EXTRA) }
| &'return' return_stmt
| &('import' | 'from') import_stmt
| &'raise' raise_stmt
| 'pass' { _Py_Pass(EXTRA) }
| &'del' del_stmt
| &'yield' yield_stmt
| &'assert' assert_stmt
| 'break' { _Py_Break(EXTRA) }
| 'continue' { _Py_Continue(EXTRA) }
| &'global' global_stmt
| &'nonlocal' nonlocal_stmt
Строка 'pass' { _Py_Pass (EXTRA) } относится к оператору pass:

Измените эту строку, чтобы в качестве ключевых слов принимались терминалы (ключевые слова) 'pass' или 'proceed'; для этого добавьте конструкцию выбора | и литерал 'proceed':
| ('pass'|'proceed') { _Py_Pass(EXTRA) }
Соберите заново файлы грамматики. В поставку CPython включаются скрипты для автоматизации повторного генерирования грамматики.
В macOS и Linux выполните цель make regen-pegen:
$ make regen-pegen
В Windows откройте командную строку из каталога PCBuild и выполните build.bat с флагом --regen:
> build.bat --regen
Должно появиться сообщение о том, что новый файл Parser ▶ pegen ▶ parse.c был сгенерирован заново.
С заново сгенерированной таблицей парсера при перекомпиляции Python будет использоваться новый синтаксис. Выполните тот же алгоритм компиляции, который был приведен для вашей операционной системы в предыдущей главе.
Если код был скомпилирован успешно, вы можете выполнить новый двоичный файл CPython и запустить REPL.
Теперь попробуйте определить функцию в REPL. Вместо команды pass используйте альтернативное ключевое слово proceed, которое было скомпилировано в грамматике Python:
$ ./python
Python 3.9 (tags/v3.9:9cf67522, Oct 5 2020, 10:00:00)
[Clang 10.0.1 (clang-1001.0.46.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> def example():
... proceed
...
>>> example()
Поздравляю — вы изменили синтаксис CPython и скомпилировали собственную версию CPython!
На следующем этапе будут рассмотрены лексемы и их отношение к грамматике.
Лексемы
Наряду с файлом грамматики в папке Grammar содержится файл Grammar ▶ Tokens, в котором хранятся все уникальные типы, присутствующие в листовых узлах (leaf node) в дереве синтаксического разбора. Каждая лексема обладает именем и сгенерированным уникальным идентификатором. Имена упрощают обращения к лексемам в tokenizer.
ПРИМЕЧАНИЕФайл Grammar ▶ Tokens — одна из новых возможностей Python 3.8.
Например, левая круглая скобка называется LPAR, а символ «точка с запятой» — SEMI. Эти лексемы будут разбираться далее в книге:
LPAR '('
RPAR ')'
LSQB '['
RSQB ']'
COLON ':'
COMMA ','
SEMI ';'
Как и в случае с файлом Grammar, при изменении файла Grammar — Tokens необходимо заново запустить pegen.
Чтобы увидеть лексемы в действии, можно воспользоваться модулем tokenizer в CPython.
ПРИМЕЧАНИЕМодуль tokenizer, написанный на Python, является служебным модулем. Реальный парсер Python использует другой способ распознавания лексем.
Создайте простой Python-скрипт с именем test_tokens.py:
cpython-book-samples ▶ 13 ▶ test_tokens.py
# Demo application
def my_function():
proceed
Передайте файл test_tokens.py модулю стандартной библиотеки с именем tokenize. На экран выводится список лексем с указанием их позиции (строк и столбцов). Используйте флаг -e для вывода имен конкретных лексем:
$ ./python -m tokenize -e test_tokens.py
0,0-0,0: ENCODING 'utf-8'
1,0-1,14: COMMENT '# Demo application'
1,14-1,15: NL '\n'
2,0-2,3: NAME 'def'
2,4-2,15: NAME 'my_function'
2,15-2,16: LPAR '('
2,16-2,17: RPAR ')'
2,17-2,18: COLON ':'
2,18-2,19: NEWLINE '\n'
3,0-3,3: INDENT ' '
3,3-3,7: NAME 'proceed'
3,7-3,8: NEWLINE '\n'
4,0-4,0: DEDENT ''
4,0-4,0: ENDMARKER ''
В первой колонке выводится интервал с номерами строк и столбцов. Вторая содержит имя лексемы, а в последней выводится значение лексемы.
В выводе модуль tokenize подставил ряд подразумеваемых лексем:
- ENCODING для utf-8;
- DEDENT для закрытия объявления функции;
- ENDMARKER для завершения файла;
- пустую строку в конце.
В конце исходных файлов Python рекомендуется оставлять пустую строку. Если не сделать этого, то CPython добавит ее за вас.
Модуль tokenize написан на чистом Python и находится в файле Lib ▶ tokenize.py.
Чтобы увидеть подробный вывод парсера C, можно запустить отладочную версию Python с флагом -d. Запустите скрипт test_tokens.py, созданный ранее, следующей командой:
$ ./python -d test_tokens.py
> file[0-0]: statements? $
> statements[0-0]: statement+
> _loop1_11[0-0]: statement
> statement[0-0]: compound_stmt
...
+ statements[0-10]: statement+ succeeded!
+ file[0-11]: statements? $ succeeded!
Как видите, proceed выделяется как ключевое слово. В следующей главе вы увидите, как при выполнении двоичного файла Python используется tokenizer и что происходит в дальнейшем для выполнения вашего кода.
Чтобы очистить код, отмените изменения в Grammar ▶ python.gram, снова сгенерируйте грамматику, а затем проведите очистку сборки и повторную компиляцию.
В macOS и Linux это делается так:
$ git checkout -- Grammar/python.gram
$ make regen-pegen
$ make -j2 -s
В Windows используются следующие команды:
> git checkout -- Grammar/python.gram
> build.bat --regen
> build.bat -t CleanAll
> build.bat -t BuildВЫВОДЫ
В этой главе вы познакомились с определениями грамматики Python и генератором парсеров. В следующей главе на основе этих знаний будет построен более сложный элемент синтаксиса — оператор «почти равно».
На практике любые изменения в грамматике Python необходимо тщательно продумывать и обсуждать. Для этого есть две причины:
1. Избыток языковых средств или сложная грамматика будут противоречить кредо Python как простого и удобочитаемого языка.
2. Изменения грамматики создают обратные несовместимости, которые усложняют работу всех разработчиков.
Если ключевой Python-разработчик предлагает изменения в грамматике, они должны быть оформлены в виде документа PEP (Python Enhancement Proposal). Все PEP нумеруются и включаются в индекс PEP. PEP 5 документирует рекомендации для развития языка и указывает, что изменения должны предлагаться в виде PEP.
Предлагаемые, отклоненные и принятые PEP для будущих версий CPython можно найти в индексе PEP. Участники, не входящие в группу ключевых разработчиков, также могут предлагать изменения в языке через список рассылки python-ideas.
Когда по поводу PEP будет достигнут консенсус, а черновая версия примет окончательную форму, руководящий совет должен принять или отклонить предложение. Мандат руководящего совета, определенный в PEP 13, утверждает, что члены совета должны работать над «поддержанием качества и стабильности языка Python и интерпретатора CPython».
Энтони занимался программированием с 12 лет. Любовь к Python он обрел спустя 15 лет, когда ему пришлось какое-то время просидеть в отеле в Сиэттле (штат Вашингтон). С тех пор Энтони исследует Python, пишет о нем и создает учебные курсы, забыв обо всех остальных языках, которые он прежде изучал.
Энтони также участвует в малых и больших проектах с открытым исходным кодом, включая CPython, и является участником Apache Software Foundation.
Страсть Энтони — разбираться в сложных системах, упрощать их и обучать других людей.
Джоанна Яблонски — редактор сайта Real Python. Естественные языки интересуют ее не меньше, чем языки программирования. Ее любовь к головоломкам, поиску закономерностей и всевозможным мелочам привела к тому, что она выбрала карьеру переводчика. Прошло совсем немного времени, и она влюбилась в новый язык — Python! Джоанна присоединилась к команде Real Python в 2018 году и с тех пор помогает питонистам повышать их профессиональный уровень.
Джейкоб Шмитт уже много лет занимается редактированием академических и технологических образовательных материалов — как в печатном виде, так и в интернете. После присоединения к команде Real Python в 2020 году он редактирует учебники, статьи и книги, написанные разносторонней командой талантливых писателей и разработчиков.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — CPython
