Кэширование данных в web приложениях. Использование memcached

Юрий Краснощек (Delphi LLC, Dell)
Я немного расскажу вам про кэширование. Кэширование, в общем-то, не сильно интересно, берешь и кэшируешь, поэтому я еще расскажу про memcached, довольно интимные подробности.

Про кэширование начнем с того, что просят вас разработать фабрику по производству омнониевых торсиометров. Это стандартная задача, главное делать скучное лицо и говорить: «Ну, мы применим типовую схему для разработки фабрики».
Вообще, это ближе к фабричному производству, т.е. откуда проблема пошла? Фабрика работает очень быстро, производит наши торсиометры. А для калибровки каждого прибора нужен чистый омноний, за которым надо летать куда-то далеко и, соответственно, пока мы в процессе добычи этого омнония, приборы лежат некалиброванные, и, по сути дела, все производство останавливается. Поэтому мы строим рядом с фабрикой склад. Но это не бесплатно.

Переходим к терминологии. Просто, чтобы мы общались про кэширование на одном языке есть довольно устоявшаяся терминология.

Источник называется origin; объем склада, т.е. размер кэша — cache size; когда мы идем на склад за образцом нужной формы, и кладовщик выдает то, что мы просили — это называется cache hit, а если он говорит: «Нет такого», это называется cache miss.

У данных — у нашего омнониума — есть freshness, буквально — это свежесть. Fresheness используется везде. Как только данные теряют свою природную свежесть, они становятся stale data.

Процесс проверки данных на годность называется validation, а момент, когда мы говорим, что данные негодные, и выбрасываем их со склада — это называется invalidation.

Иногда случается такая обидная ситуация, когда у нас не остается места, но нам лучше держать свежий омнониум, поэтому мы находим по каким-то критериям самый старый и выбрасываем. Это называется eviction.
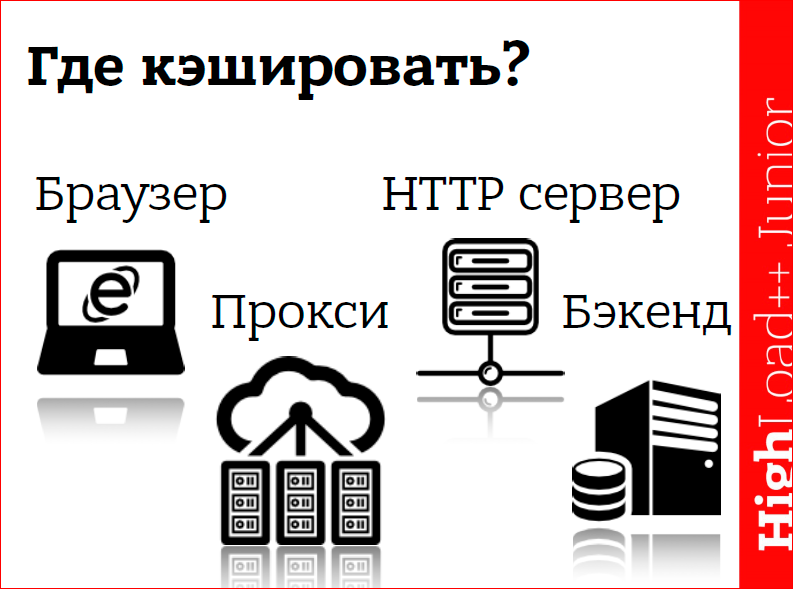
Схема такая, что от нашего браузера до бэкенда есть масса звеньев в цепи. Вопрос: где кэшировать? На самом деле, кэшировать надо абсолютно везде. И, хотите вы этого или нет, данные будут кэшироваться, т.е. вопрос, скорее, — как мы можем на это повлиять?

Для начала нужно найти хорошие данные для кэширования. В связи с тем, что мы делаем какой-то кэш, у нас появляется еще одно промежуточное звено в цепи, и необязательно, что кэш что-то ускорит. Если мы плохо подберем данные, то, в лучшем случае, он не повлияет на скорость, а в худшем — еще и замедлит процесс всего производства, всей системы.
Нет смысла кэшировать данные, которые часто меняются. Нужно кэшировать данные, которые используются часто. Размер данных имеет значение, т.е. если мы решаем кэшировать в памяти blu-ray фильм — классно, мы его очень быстро достанем из памяти, но, скорее всего, нам потом его придется перекачать куда-нибудь по сети, и это будет очень медленно. Такой большой объем данных не соизмерим со скоростью доставки, т.е. нам нет смысла держать такие данные в памяти. Можем на диске держать, но нужно сравнивать по скорости.
Кстати, можете погуглить «programming latencies». Там на сайте очень хорошо даны все стандартные задержки, например, скорость доступа в CPU cache, скорость отправки Round Trip пакета в дата-центре. И когда вы проектируете, что-то прикидываете, хорошо смотреть, там очень наглядно показано, что сколько времени и по сравнению с чем занимает.
Это готовые рецепты для кэширования:

Это релевантный HTTP Headers:

Я немного расскажу про некоторые, но, вообще-то, про это надо читать. В принципе, в вебе единственное, как мы можем влиять на кэширование — это правильно устанавливая вот эти header«ы.

Expires использовался раньше. Мы устанавливаем freshness для наших данных, мы буквально говорим: «Все, этот контент годен до такого вот числа». И сейчас этот header нужно использовать, но только как fallback, т.к. есть более новый header. Опять-таки, эта цепочка очень длинная, вы можете попасть на какую-то прокси, которая понимает только вот этот header — Expires.
Новый header, который сейчас отвечает за кэширование, — это Cache-Control:

Тут вы можете указать сразу же и freshness, и validation механизм, и invalidation механизм, указать, это public данные или private, как их кэшировать…
Кстати, no-cache — это очень интересно. По названию очевидно, что мы говорим: кэшируйте везде, пожалуйста, как угодно кэшируйте, если мы говорим «no-cache». Но каждый раз, когда мы используем какие-то данные из этого контента, например, у нас есть формочка, и мы в этой формочке делаем submit, то мы говорим, что в любом случае все ваши закэшированные данные не актуальны, вам надо их перепроверить.
Если мы хотим, вообще, выключить кэширование для контента, то говорим «no-store»:

Эти «no-cache», «no-store» очень часто применяются для форм аутентификации, т.е. мы не хотим кэшировать неаутентифицированных пользователей, чтобы не получилось странного, чтобы они не увидели лишнего или не было недопонимания. И, кстати, про этот Cache-Control: no-cache… Если, допустим, Cache-Control header не поддерживается, то его поведение можно симулировать. Мы можем взять header Expires и установить дату какую-нибудь в прошлом.
Эти все header«ы, включая даже Content-Length, для кэша актуальны. Некоторые кэшируюшие прокси могут просто даже не кэшировать, если нет Content-Length.
Собственно, мы приходим к memcached, к кэшу на стороне бэкенда.

Опять же мы можем кэшировать по-разному, т.е. мы достали какие-то данные из базы, что-то в коде с ними делаем, но, по сути дела, это кэш, — мы один раз их достали, чтобы много раз переиспользовать. Мы можем использовать в коде какой-то компонент, фреймворк. Этот компонент для кэширования нужен, потому что у нас должны быть разумные лимитэйшны на наш продукт. Все начинается с того, что приходит какой-то инженер по эксплуатации и говорит: «Объясни мне требования на свой продукт». И вы должны ему сказать, что это будет столько-то оперативной памяти, столько-то места на диске, такой-то прогнозируемый объем роста у приложения… Поэтому, если мы что-то кэшируем, мы хотим иметь ограничения. Допустим, первое ограничение, которое мы можем легко обеспечить, — по числу элементов в кэше. Но если у нас элементы разного размера, тогда мы хотим это закрыть рамками фиксированного объема памяти. Т.е. мы говорим какой-нибудь размер кэша — это самый главный лимит, самый главный boundary. Мы используем библиотеку, которая может такую штуку делать.

Ну, или же мы используем отдельный кэширующий сервис, вообще stand-alone. Зачем нам нужен какой-то отдельный кэширующий сервис? Чаще всего бэкенд — это не что-то такое монолитное, один процесс. У нас есть какие-то разрозненные процессы, какие-то скрипты, и если у нас есть отдельный кэширующий сервис, то есть возможность у всей инфраструктуры бэкенда видеть этот кэш, использовать данные из него. Это здорово.
Второй момент — у нас есть возможность расти. Например, мы ставим один сервис, у нас заканчивается кэшсайз, мы ставим еще один сервис. Естественно, это не бесплатно, т.е. «а сегодня мы решили отмасштабироваться» не может случиться. Нужно планировать такие вещи заранее, но отдельный кэширующий сервис такую возможность дает.

Кэш еще дает нам availability практически за бесплатно. Допустим, у нас есть какие-то данные в кэше, и мы пытаемся достать эти данные из кэша. У нас что-то где-то падает, а мы делаем вид, что ничего не упало, отдаем данные с кэша. Оно, может, в это время переподнимется как-то, и будет даже availability.
Собственно, мы подобрались к memcached. Memcached — это типичный noSQL.

Почему noSQL для кэширования — это хорошо?
По структуре. У нас есть обычная хэш-таблица, т.е. мы получаем низкий latency. В случае с memcached и аналогичными key-value storage«ами — это не просто низкий latency, а в нотации big-O у нас сложность большинства операций — это константа от единицы. И поэтому мы можем говорить, что у нас какой-то временной constraint. У нас, например, запрос занимает не больше 10 мс., т.е. можно даже договариваться о каком-то контракте на основании этих latency. Это хорошо.
Чаще всего мы кэшируем что попало — картинки вперемешку с CCS«ом с JS«ом, какие-то фрагменты форм прирендеренных, что-то еще. Это непонятно, какие данные, и структура key-value позволяет их хранить довольно легко. Мы можем завести нотацию, что у нас account.300.avatar — это картинка, и оно там работает. 300 — это ID аккаунта в нашем случае.
Немаловажный момент — то, что упрощается код самого storage«а, если у нас key-value noSQL, потому что самое страшное, что может быть — это мы как-то испортим или потеряем данные. Чем меньше кода работает с данными, тем меньше шанса испортить, поэтом простой кэш с простой структурой — это хорошо.

Про memcached key-value. Можно указывать вместе с данными expiration. Поддерживается работа в фиксированном объеме памяти. Можно устанавливать 16-битные флаги со значением произвольно — они для memcached прозрачны, но чаще всего вы будете с memcached работать и с какого-то клиента, и скорее всего, этот клиент уже загреб эти 16 бит под себя, т.е. он их как-то использует. Такая возможность есть.
memcached может работать с поддержкой викшинов, т.е. когда у нас кончается место, мы самые старые данные выпихиваем, самые новые добавляем. Или же мы можем сказать: «Не удаляй никакие данные», тогда при добавлении новых данных она будет возвращать ошибку out of memory — это флажок »-М».

Структурированной единой документации по memcached нет, лучше всего читать описание протокола. В принципе, если вы наберете в Google «memcached протокол», это будет первая ссылка. В протоколе описаны не только форматы команд — отправка, что мы отправляем, что приходит в ответ… Там описано, что вот эта команда, она будет вести себя вот так и так, т.е. там какие-то корнер кейсы.
Коротенько по командам:

get — получить данные;
set/ add/ delete/ replace — как мы сторим эти данные, т.е.:
- set — это сохранить, добавить новые, либо заменить,
- add — это добавить только, если такого ключа нет,
- delete — удалить;
- replace — заменить, только если такой ключ есть, иначе — ошибка.
Это в среде, когда у нас есть шард. Когда у нас есть кластер, это никакой консистентности нам не гарантирует. Но с одним инстансом консистанси можно поддерживать этими командами. Более или менее можно такие constraint«ы выстраивать.
prepend/ append — это мы берем и перед нашими данными вставляем какой-то кусочек или после наших данных вставляем какой-то кусочек. Они не очень эффективно реализованы внутри memcached, т.е. у вас все равно будет выделяться новый кусок памяти, разницы между ними и set функционально нет.
Мы можем данным, которые сохраняем, указать какой-то expiration и потом мы можем эти данные трогать командой touch, и мы продляем жизнь конкретно вот этому ключу, т.е. он не удалится.
Есть команды инкремента и декремента — incr/decr. Работает оно следующим образом: вы сторите какое-то число в виде строки, потом говорит incr и даете значение какое-то. Оно суммирует. Декремент — то же самое, но вычитает. Там есть интересный момент, например, 2 — 3 = 0, с точки зрения memcached, т.е. она автоматически хэндлит андерфлоу, но она не дает нам сделать отрицательное число, в любом случае вернется ноль.

Единственная команда, с помощью которой можно сделать какую-то консистентность, — это cas (это атомарная операция compare and swap). Мы сравниваем два каких-то значения, если эти значения совпадают, то мы заменяем данные на новые. Значение, которое мы сравниваем, — это глобальный счетчик внутри
memcached, и каждый раз, когда мы добавляем туда данные, этот счетчик инкрементится, и наша пара key-value получает какое-то значение. С помощью команд gets мы получаем это значение и потом в команде cas мы его можем использовать. У этой команды есть все те же проблемы, которые есть у обычных атомиков, т.е. можно наделать кучу raise condition«ов интересных, тем более, что у memcached нет никаких гарантий на порядок выполнения команд.
Есть у memcached ключик »-С» — он выключает cas. Т.е. что происходит? Этот счетчик пропадает из key-value pair, если вы добавляете ключик »-С», то вы экономите 8 байт, потому что это 64-хбитный счетчик на каждом значении. Если у вас значения небольшие, ключи небольшие, то это может быть существенная экономия.
Как работать с memcached эффективно?

Она задизайнена, чтобы работать с множеством сессий. Множества — это сотни. Т.е. начинается от сотен. И дело в том, что в терминах RPS — request per second — вы не выжмете из memcached многого, используя 2–3 сессии, т.е. для того, чтобы ее раскачать, надо много подключений. Сессии должны быть долгоиграющие, потому что создание сессии внутри memcached — довольно дорогостоящий процесс, поэтому вы один раз прицепились и все, эту сессию надо держать.
Запросы надо batch«ить, т.е. мы должны отправлять запросы пачками. Для get-команды у нас есть возможность передать несколько ключей, этим надо пользоваться. Т.е. мы говорим get и ключ-ключ-ключ. Для остальных команд такой возможности нет, но мы все равно можем делать batch, т.е. мы можем формировать запрос у себя, локально, на стороне клиента с использованием нескольких команд, а потом этот запрос целиком отправлять.
memcached многопоточна, но она не очень хорошо многопоточна. У нее внутри много блокировок, довольно ad-hoc, поэтому больше четырех потоков вызывают очень сильный контеншн внутри. Мне верить не надо, надо все перепроверять самим, надо с живыми данными, на живой системе делать какие-то эксперименты, но очень большое число потоков работать не будет. Надо поиграться, подобрать какое-то оптимальное число ключиком »-t».
memcached поддерживает UDP. Это патч, который был добавлен в memcached facebook«ом. То, как использует facebook memcached — они делают все сеты, т.е. всю модификацию данных по TCP, а get«ы они делают по UDP. И получается, когда объем данных существенно большой, то UDP дает серьезный выигрыш за счет того, что меньше размер пакета. Они умудряются больше данных прокачать через сетку.
Я вам рассказывал про incr/decr — эти команды идеально подходят для того, чтобы хранить статистику бэкенда.

Статистика в HighLoad«e — это вещь незаменимая, т.е. вы не сможете понять, что, как, откуда происходит конкретная проблема, если у вас не будет статистики, потому что после получаса работы «система ведет себя странно» и все… Чтобы добавить конкретики, например, каждый тысячный запрос фейлится, нам нужна какая-то статистика. Чем больше статистики будет, тем лучше. И даже, в принципе, чтобы понять, что у нас есть проблема, нам нужна какая-то статистика. Например, бэкенд отдавал за 30 мс страницу, начал за 40, взглядом отличить невозможно, но у нас перформанс просел на четверть — это ужасно.
Memcached тоже сама по себе поддерживает статистику, и если вы уже используете memcached в своей инфраструктуре, то статистика memcached — это часть вашей статистики, поэтому туда заглядывать надо, туда надо смотреть, чтобы понимать, правильно ли бэкенд использует кэш, хорошо ли он данные кэширует.
Первое — по каждой команде есть hits и misses. Когда мы обратились к кэшу, и нам отдали данные, поинкрементился hit по этой команде. Например, сделали delete ключ, у нас будет delete hits 1, так по каждой команде. Естественно, надо, чтобы hits была 100%, misses не было вообще. Надо смотреть. Допустим, у нас может быть очень высокий miss ratio. Самая банальная причина — мы просто лезем не за теми данными. Может быть такой вариант, что мы выделили под кэш мало памяти, и мы постоянно переиспользуем кэш, т.е. мы данные какие-то добавили-добавили-добавили, на каком-то моменте там первые данные выпали из кэша, мы за ними полезли, их там уже нет. Мы полезли за другими, их там тоже нет. И оно вот так все крутится. Т.е. надо либо со стороны бэкенда уменьшить нагрузку на memcached, либо можно увеличить параметром »-m» объем памяти, который мы разрешаем использовать.
Evictions — это очень важный момент. Ситуация, про которую я рассказываю, она будет видна из того, что evictions rate будет очень высокий. Это количество, когда пригодные данные не експайред, т.е. они свежие, хорошие выбрасываются из кэша, у нас тогда растет число evictions.
Я говорил, что надо использовать batch«и. Как подобрать размер batch«a? Серебряной пули нет, надо экспериментально это все подбирать. Зависит все от вашей инфраструктуры, от сети, которую вы используете, от числа инстансов и прочих факторов. Но когда у нас batch очень большой… Представьте ситуацию, что мы выполняем batch, и все остальные конекншны стоят и ждут, пока batch выполнится. Это называется starvation — голодание, т.е. когда остальные конекшны голодают и ждут, пока выполнится один жирный. Чтобы этого избежать, внутри memcached есть механизм, который прерывает выполнение batch«a насильно. Реализовано это довольно грубо, есть ключик »-R», который говорит сколько команд может выполнить один конекшн подряд. По умолчанию это значение 20. И вы, когда посмотрите на статистику, если у вас conn_yields stat будет каким-то очень высоким, это значит, что вы используете batch больше, чем может memcached прожевать, и ему приходится насильно часто переключать контекст этого конекшна. Тут можно либо увеличить размер batch«а ключиком »-R», либо не использовать со стороны бэкенда такие batch«и.
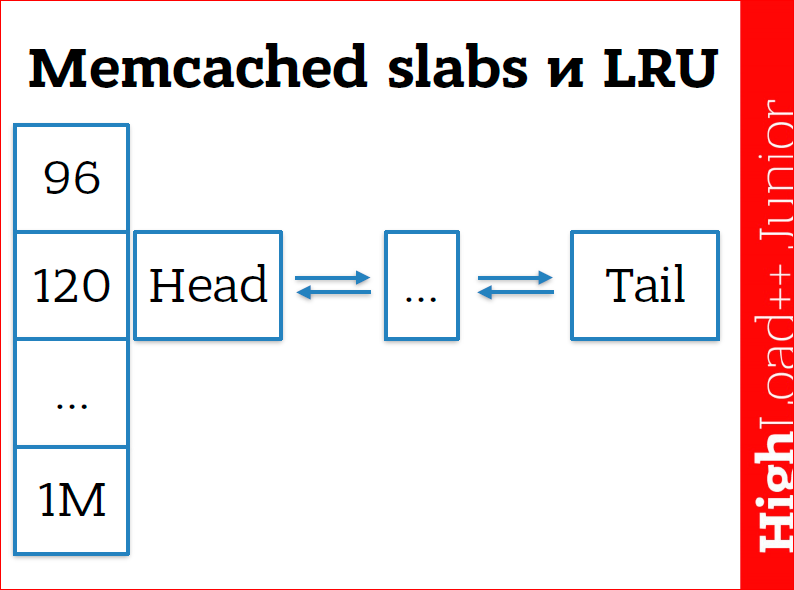
Еще я говорил, что memcached выбрасывает из памяти самые старые данные. Так вот, я соврал. На самом деле это не так. Внутри memcached есть свой memory менеджер, чтобы эффективно работать с этой памятью, чтобы выбрасывать эти атомы. Он устроен таким образом, что у нас есть slabs (буквально «огрызок»). Это устоявшийся термин в программировании memory менеджеров для какого-то куска памяти, т.е. у нас есть просто какой-то большой кусок памяти, который, в свою очередь, делится на pages. Pages внутри memcached по Мб, поэтому вы не сможете создать там данные «ключ-значение» больше одного Мб. Это физическое ограничение — memcached не может создать данные больше, чем одна страница. И, в итоге, все страницы побиты на чанки, это то, что вы видите на картинке по 96, 120 — они определенного размера. Т.е. идут куски по 96 Мб, потом куски по 120, с коэффициентом 1.25, от 32-х до 1 Мб. В пределах этого куска есть двусвязный список. Когда мы добавляем какое-то новое значение, memcached смотрит на размер этого значения (это ключ + значение + экспирейшн + флаги + системная информация, которая memcached нужна (порядка 24–50 байт)), выбирает размер этого чанка и добавляет в двусвязный список наши данные. Она всегда добавляет данные в head. Когда мы к каким-то данным обращаемся, то memcached вынимает их из двусвязного списка и опять бросает в head. Т.о., те данные, которые мало используются, переползают в tail, и в итоге они удаляются.
Если памяти нам не хватает, то memcached начинает удалять память с конца. Механизм list recently used работает в пределах одного чанка, т.е. эти списки выделены для какого-то размера, это не фиксированный размер — это диапазон от 96 до 120 попадут в 120-ый чанк и т.д. Влиять на этот механизм со стороны memcached мы никак не можем, только со стороны бэкенда надо подбирать эти данные.

Можно посмотреть статистику по этим slab«ам. Смотреть статистику по memcached проще всего — протокол полностью текстовый, и мы можем Telnet«ом подсоединиться, набрать stats, Enter, и она вывалит «простыню». Точно так же мы можем набрать stats slabs, stats items — это в принципе, похожая информация, но stats slabs дает картину, больше размазанную во времени, там такие stat«ы — что было, что происходило за весь тот период пока memcached работал, а stat items — там больше о том, что у нас есть сейчас, сколько есть чего. В принципе, обе эти вещи надо смотреть, надо учитывать.

Вот мы подобрались к масштабированию. Естественно, мы поставили еще один сервер memcached — здорово. Что будем делать? Как-то надо выбирать. Либо мы на стороне клиента решаем, к какому из серверов будем присоединяться и почему. Если у нас availability, то все просто — записали туда, записали сюда, читаем откуда-нибудь, не важно, можно Round Robin«ом, как угодно. Либо мы ставим какой-то брокер, и для бэкенда у нас получается, что это выглядит как один инстанс memcached, но на самом деле за этим брокером прячется кластер.
Для чего используется брокер? Чтобы упростить инфраструктуру бэкенда. Например, нам надо из дата-центра в дата-центр поперевозить сервера, и все клиенты должны об этом знать. Либо мы можем хак за этим брокером сделать, и для бэкенда все прозрачно пройдет.
Но вырастает latency. 90% запросов — это сетевой round trip, т.е. memcached внутри себя запрос обрабатывает за мкс — это очень быстро, а по сети данные ходят долго. Когда у нас есть брокер, у нас появляется еще одно звено, т.е. все еще дольше выполняется. Если клиент сразу знает, на какой кластер memcached ему идти, то он данные достанет быстро. А, собственно, как клиент узнает, на какой кластер memcached ему идти? Мы берем, считаем хэш от нашего ключа, берем остаток от деления этого хэша на количество инстанса в memcached и идем на этот кластер — самый простой солюшн.
Но добавился у нас еще один кластер в инфраструктуру, значит, сейчас нам нужно грохнуть весь кэш, потому что он стал неконсистентным, не валидным, и заново все пересчитать — это плохо.

Для этого есть механизм — consistent hashing ring. Т.е. что мы делаем? Мы берем хэш значения, все возможные хэш значения, например int32, берем все возможные значения и располагаем как будто на циферблате часов. Так. мы можем сконфигурировать — допустим, хэши с такого-то по такой-то идут на этот кластер. Мы конфигурируем рэнджи и конфигурируем кластеры, которые отвечают за эти рэнджи. Таким образом, мы можем тасовать сервера как угодно, т.е. нам надо будет поменять в одном месте это кольцо, перегенерировать, и сервера, клиенты или роутер, брокер — у них будет консистентное представление о том, где лежат данные.
Я еще бы хотел немного сказать про консистентность данных. Как только у нас появляется новое звено, как только мы кэшируем где-либо, у нас появляется дубликат данных. И у нас появляется проблема, чтобы эти данные были консистентными. Потому что есть много таких ситуаций — например, мы записываем данные в кэш — локальный или удаленный, потом идем и пишем эти данные в базу, в этот момент база падает, у нас конекшн с базой пропал. По сути дела, по логике, этих данных у нас нет, но в это же время клиенты читают их из кэша — это проблема.
memcached плохо подходит для consistancy каких-то решений, т.е. это больше решения на availability, но в то же время, есть какие-то возможности с cas«ом что-то наколхозить.
Контакты
» cachelot@cachelot.io
» http://cachelot.io/
Этот доклад — расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем HighLoad++ Junior.Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля «Российские интернет-технологии», в который входит восемь конференций, включая HighLoad++ Junior.
