KDD 2018, день пятый, завершающий

Вот и завершился пятый, последний день KDD. Удалось услышать несколько интересных докладов от Facebook и Google AI, помайнить футбольные тактики и погенерировать немного химикатов. Об этом и не только — под катом. До встречи через год в Анкоридже, столице Аляски!
On Big Data Learning for Small Data Problems
Утренний доклад от китайского профессора дался тяжело. Докладчик явно халявил при подготовке, часто сбивался, начинал пропускать слайды и вместо разговоров за жизнь пытался грузить невыспавшийся мозг математикой.
Общая канва рассказа крутилась вокруг мысли о том, что данных далеко не всегда много. Есть, например, длинный хвост в котором много разнообразных примеров. Есть датасеты с большим количеством классов, которые хоть и большие сами по себе, но на каждый класс всего несколько записей. В качестве примера такого датасета привел Omniglot — рукописные символы из 50-ти алфавитов, 1623 класса и по 20 картинок на класс в среднем. Но на самом деле в такой перспективе можно рассматривать и датасеты рекомендательных задач, когда у нас много пользователей и не так много рейтингов для каждого из них в отдельности.
Что можно сделать, чтобы упростить для ML жизнь в такой ситуации? В первую очередь. постараться привнести в него знание из предметной области. Сделать это можно в разной форме: это и инжиниринг признаков, и специфичные регуляризации, и доработка архитектуры сети. Еще одним распространенным решением является transfer learning, думаю, почти все, кто работал с картинками, начинали с дообучения какой-нибудь ImageNet на своих данных. В случае Omniglot естественным донором для трансфера будет MNIST.
Одной из формой трансфера может быть multi-task learning, про который на KDD уже несколько раз говорили. Развитием MTL можно считать подход meta learning — обучая алгоритм на сэмплах из множества задач, мы можем УЧИТЬ не только параметры, но и гиперпараметры (конечно, только если наша процедура дифференцируема).
Продолжая тему multi-task, можно прийти к концепции lifelong continuous learning, которую нагляднее всего можно показать на примере роботехники. Робот должен уметь решать разные задачи, и при обучении новой задаче использовать предыдущий опыт. Но можно рассмотреть такой подход и на примере Omniglot: выучив один из символов, можно перейти к выучивания следующего, используя накопленный опыт. Правда, на этом пути нас ждет опасная проблема catastrophic forgetting, когда алгоритм начинает забывать то, что он выучил раньше (для борьбы с этим советует регуляризацию EWC).
Кроме того, докладчик рассказал про несколько своих работ в этом направлении.
Neural Processes (аналогия Гауссовского процесса для нейросетей) и Distil and Transfer Learning (оптимизация transfer learning для случая, когда мы не берем ранее обученную модель за основу, а обучаем свои в режиме multi-task).
Images And Texts
Сегодня решил походить по прикладным докладам, с утра про работу с текстами, изображениями и видео.
Corpus Conversion Service
Очень быстро растет частота публикаций, работать с этим сложно, особенно с учетом того, что практически весь поиск ведётся по тексту. IBM предлагает свой сервис для разметки корпусов Scientific knowledge 3.0. Основной рабочий процесс выглядит так:
- Парсим PDF, распознаём текст на картинках.
- Проверяем, есть ли модель для данной формы текста, если есть — делаем с её помощью семантический экстракт.
- Если модели нет — отправляем на аннотацию и обучаем.
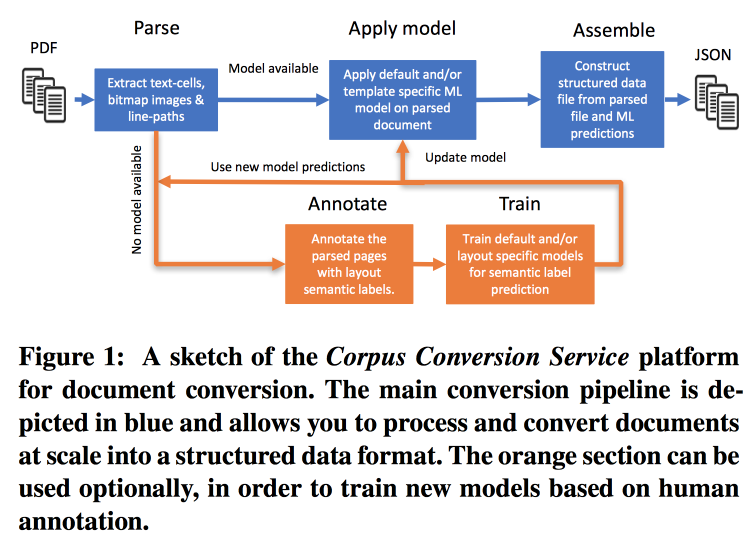
Для обучения моделей начинаем с кластеризации по структуре. В рамках кластера с помощью краудсорсинга размечаем несколько страниц. Получается добиться точности > 98% при обучении на разметке 200–300 документов. В разметке есть сильный дисбаланс класса (почти всё размечено как текст), поэтому смотреть надо на точность по всем классам и на confusion matrix.
Модели имеют иерархическую структуру. Например, одна модель распознаёт таблицу, а другая режет на ряды/колонки/заголовки (и да, таблица может быть вложена в таблицу). В качестве модели используют свёрточную сеть.
Для всего этого собрали конвейер на Docker с Kubernetes и готовы за разумную плату загрузить ваш корпус текстов. Могут работать не только с текстовым PDF, но и со сканами, поддерживают восточные языки. Помимо просто вытаскивания текста работают над извлечением графа знания, обещают рассказать подробности на следующем KDD.
Rare Query Expansion Through Generative Adversarial Networks in Search Advertising
Поисковые движки больше всего денег зарабатывают с рекламы, а реклама показывается в зависимости от того, что искал пользователь. Но сопоставление не всегда очевидно. Например, по запросу airlines tickets показывать рекламу cheap bus tickets не очень правильно, а вот expedia зайдет хорошо, но по ключевым словам этого не понять. Модели машинного обучения могут помочь, но они плохо работают с редкими запросами.
Чтобы решить эту проблему для расширения поискового запроса будем обучать Conditional GAN по sequence-to-sequence модели. В качестве архитектуры используем рекуррентные сети (2-слойный GRU). Модифицируем min-max от GAN, пытаясь нацелить его на добавление ключевых слов, по которым были клики на рекламу.
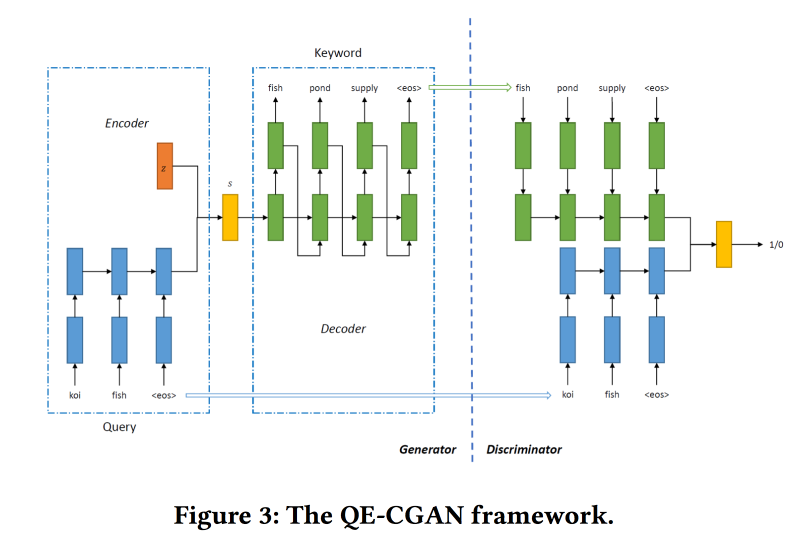
Датасет для обучения на 14 млн запросов и 4 млн рекламных ключевых слов. Предложенная модель лучше работает на длинном хвосте запроса, ради чего её и делали. Но в голове производительность не выше.
Collaborative Deep Metric Learning for Video Understanding
Работу презентуют ребята из Google AI. Хотят строить хорошие эмбединги для видео, чтобы затем использовать в похожих видео, рекомендациях, автоматической аннотации и т.д. Работает следующим образом:
- Из видео сэмплируем фрэймы — картинку и кусок звуковой дорожки.
- Из картинок извлекаем фичи, котоыре предварительно выученыInception.
- То же самое делаем с аудиофрагментом (конкретную архитектуру сети не показали). На полученных признаках вешаем полносвязные сетки с пулингом по кадрам. Нормируем по L2.
- Далее интересный момент — пытаемся добиться, чтобы похожие видео были рядом с точки зрения коллаборативной похожести. Для этого при обучении используем triplet loss (берем объект, сэмплируем на него похожий и непохожий, добиваемся, чтобы эмбединги непохожего были дальше от оригинала, чем похожего). Не забываем, что нужно использовать negative mining.

Используют для холодного старта в похожих видео, но есть пара проблем: по визуальной похожести может найти видео на другом языке или видео на другую тему (особенно актуально для видео формата «доска и лектор»). Советуют использовать дополнительную мета-информации о видео.
С рекомендациями есть проблема: надо матчить историю просмотров и 5 миллиардов видео с Youtube. Чтобы ускорить работу, предрасчитываем для пользователя вектор среднего эмбединга просмотренных видео. Проверяли на movielens, выкачивали трейлеры с Youtube для анализа. Показали, что для пользователей с небольшим количеством рейтингов работает лучше.
В задаче аннотирования видео используют подход mixture of experts: обучают по logreg по эмбедингу на каждую возможную аннотацию. Проверили на Youtube-8 и показали очень хороший результат.
Name Disambiguation in AMiner: Clustering, Maintenance, and Human in the Loop
AMiner — граф для академии, предоставляющий разные сервисы по работе с литературой. Одна из проблем: коллизии имен авторов и сущностей. Для решения предлагают автоматический алгоритм с некой формой активного дообучения.
Процесс состоит из трех этапов: с помощью текстового поиска собираем кандидатов (документы с похожими именами авторов), кластеризуем (с автоматическим определением количества кластеров) и строим профили.

Чтобы считать похожесть при кластеризации нужно некое представление (эмюединг). Его можно получить с помощью глобальной модели (по всему графу) или локальную (по тем кандидатам, что засэмплировали). Глобальная ловит закономерности, которые сможет перенести и на новые документы, а локальная помогает учесть индивидуальные особенности — будем совмещать. Для получения глобальных эмбедингов также используют сиамскую сеть, обученную по triplet loss, а для локальных — графовый автоэнкодер (картинки оставил в статье ради экономии места).
Самый больной вопрос — сколько кластеров делать? Подход X-means не масштабируется на большое количество кластеров, для прогнозирования их количества используют RNN: из размеченного множество сначала сэмплируют K кластеров, затем из этих кластеров N примеров. Тренируют сеть чтобы раскрывала исходное число кластеров.

Данные поступают достаточно быстро, 500 тыс в месяц, но прогонка всей модели занимает недели. Используют для быстрой инициализации подбор кандидатов по текстовому поиску и кНН по глобальным эмбедингам. Важный момент: в процесс обучения включены люди, которые размечают, что должно и что не должно попасть в кластер. На этих данных модель переобучается.
Rosetta: Large scale system for text detection and recognition in images
Ребята из FB презентуют свое решение для извлечения текстов из картинок. Модель работает в два этапа: первая сеть определяет текст, вторая его распознает. В качестве детектора использовали Faster-RCNN с заменой ResNet на SuffleNet для ускорения работы. Для распознавания использовали ResNet18 и обучали с помощью CTC loss.
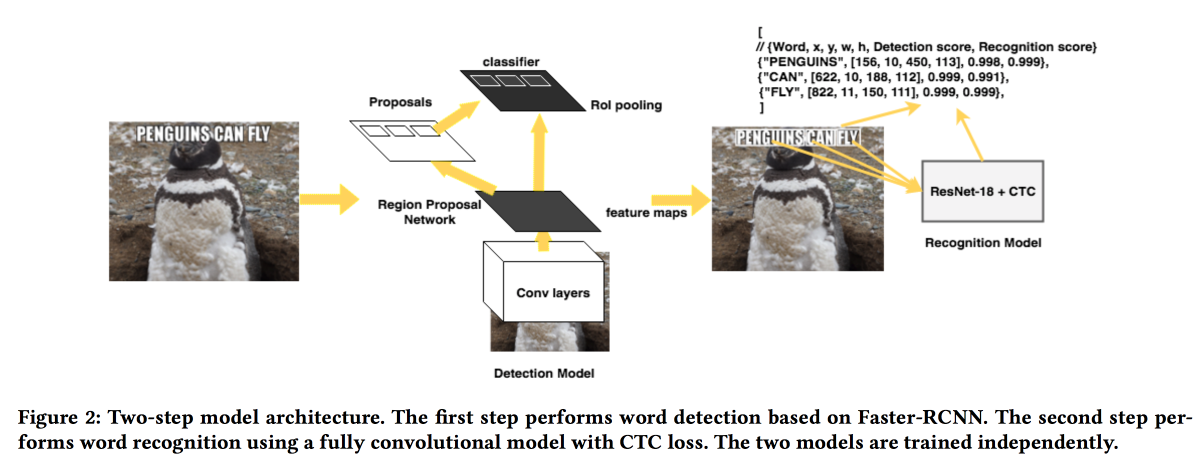
Для улучшения сходимости использовали несколько трюков:
- При обучении внедрили небольшой шум в результат детектора.
- Растянули тексты по горизонтали на 20%.
- Использовали curriculum learning — постепенно усложняли примеры (по количеству символов).
Natural Science
Последняя контентная секция на конференции была посвящена «естественным наукам». Немного химии, футбола и не только.
False Discovery Rate Controlled Heterogeneous Treatment Effect Detection for Online Controlled Experiment
Очень интересная работа по анализу А/Б-тестов. Проблема с большинством систем анализа в том, что они смотрят на средний эффект, тогда как в реальности чаще всего какие-то пользователи реагируют на изменение положительно, а какие-то отрицательно, и можно добиться большего, если понимать, кому фича зашла, а кому нет.

Можно заранее разделить пользователей на когорты и оценивать по ним эффект, но при увеличении количества когорт увеличивается количество ложных срабатываний (их можно попробовать уменьшить с помощью метода Бонферони, но он слишком консервативен). Кроме того, надо знать когорты заранее. Ребята предлагают использовать сочетание нескольких подходов: совместить механизм обнаружения гетерогенного эффекта (HTE) с методами фильтрации ложных срабатываний.
Для обнаружения гетерогенного эффекта преобразуют матрицу с x=0/1 (в группе или нет) и эффектом в матрицу, в которой вместо 0/1 лежит число (x — p)/p(1-p), где p — вероятность включения в тест. Далее обучают модель прогнозирования эффекта от x (линейной или лассо регрессией). Те пользователи, для которых результат значимо отличается от прогноза, являются кандидатами для выделения в «гетерогенный» эффект.
Далее для фильтра ложных срабатываний пробовали два метода: Benjamini-Hochberg и Knockoffs. Первый гораздо проще реализовать, но второй гибче и показал более интересные результаты.
Winner«s Curse: Bias Estimation for Total Effects of Features in Online Controlled Experiments
Ребята из AirBnB немного рассказали про то, как улучшали систему анализа экспериментов. Основная проблема в том, что при экспериментировании много биасов, в этой работе рассмотрели selection bias — мы отбираем эксперименты с лучшим наблюдаемым результатом, но это значит, что мы чаще будем отбирать эксперименты, в которых наблюдаемый результат завышен относительно реального.
В результате при объединение экспериментов итоговый эффект меньше суммы эффектов экспериментов. Но зная об этом биасе, можно попробовать его оценить и вычесть, используя статистический аппарат (предполагая, что различие реального и наблюдаемого эффекта распределено нормально). Если вкратце, то как-то так:

А если добавить bootstrap, то можно даже построить доверительные интервалы для несмещенной оценки эффекта.
Automatic Discovery of Tactics in Spatio-Temporal Soccer Match Data
Интересная работа по раскрытию тактики футбольных команд. Данные матчей доступны в виде последовательностей действий (пас/касание/удар и т.д.), порядка 2000 действий на матч. Сочетают непрерывные (координаты/время) и дискретные (игрок) атрибуты. Важно расширять данные, используя знания предметной области (добавить роль игрока и тип паса, например), но не всегда получается. Кроме того, разные типы пользователей интересуют разные типы паттернов: тренера — успешные, нападающего — защитные, журналиста — уникальные.
Предлагаемый метод выглядит следующим образом:
- Делим поток на фазы по переходу мяча между командами.
- Кластеризуем фазы, в качестве расстояния используя dynamic time warping. Как определить количество кластеров, не рассказали.
- Ранжируем кластеры по цели (для кого ищем тактики).
- Майним паттерны внутри кластера (sequential pattern mining CM-SPADE), дисертизируем координаты по сегментам поля (левый/правый фланг, середина, штрафные).
- Снова ранжируем паттерны.
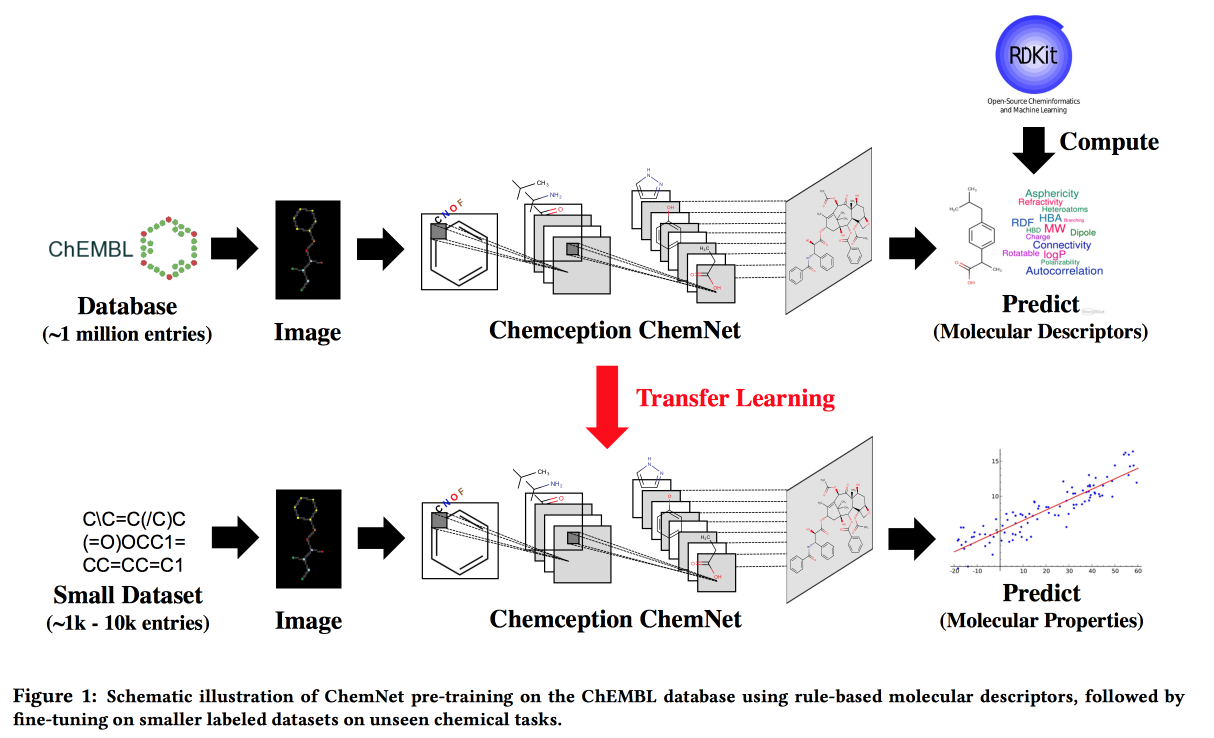
Using Rule-Based Labels for Weak Supervised Learning: A ChemNet for Transferable Chemical Property P
Работа для ситуаций, когда больших данных нет, но есть теоретические модели с иерархическими правилами. Используя теорию, строим «экспертную» нейросетку. Применим к задаче разработки химических соединений с заданными свойствами.
Хочется по аналогии с картинками получить сеть, в которой слои будут соответствовать разным уровням абстракции: атомы/функциональные группы/фрагменты/молекулы. В прошлом были подходы для больших размеченных датасетов, например, SMILE2Vect: использовать SMILE для перевода формулы в текст, а дальше применить техники построения эмбедингов для текстов.
Но что делать, если большого размеченного датасета нет? Учим ChemNet с помощью RDKit на те цели, которые он может предсказать, а затем делаем transfer learning для решения нужной задачи. Показываем, что можем конкурировать с моделями, обученными на размеченных данных. Можно учить послойно, а значит достичь цели — разбить слои по уровням абстракции.
PrePeP — A Tool for the Identification and Characterization of Pan Assay Interference Compounds
Разрабатываем лекарства, используем data science для отбора кандидатов. Есть молекулы, которые реагируют со многими веществами. Они не могут быть использованы как лекарства, но часто всплывают на начальных этапах теста. Именно такие молекулы PAINS будем фильтровать.
Есть сложности: данные разряженные и высокомерные (107 тыс.), классы несбалансированные (позитивов 0,5%), и химики хотят получить интерпретируемую модель. Объединяем данные из графовой структуры (gSpan) молекулы и химических фингерпринтов. С балансом боролись с помощью бэгинга с undersampling негатива, учили деревья, прогнозы агрегировали по majority vote.
