Kandinsky Video — первая российская модель генерации видео по тексту
Если несколько предметов, постоянно меняющих форму и положение, будут последовательно возникать перед глазами через очень короткие промежутки времени и на маленьком расстоянии друг от друга, то изображения, которые они вызывают на сетчатке, сольются, не смешиваясь, и человеку покажется, что он видел предмет, постоянно меняющий форму и положение.
Жозеф Плато, август 1833 года
В недавней статье мы рассказали о возможности создания анимированных видеороликов на основе комбинации синтеза изображений и различных способов преобразования этих изображений (сдвиги в стороны, масштабирование и т. д.). Сегодня же речь пойдёт про нашу новую технологию синтеза полноценного видео по текстовому описанию, которую мы назвали Kandinsky Video (для затравки пара примеров приведена на рисунке 1).

Рисунок 1. Примеры ключевых кадров видео, созданных по текстовому описанию.
Небольшая историческая справка
Хочется обратиться к истории и вспомнить, как в 1832 году Жозеф Плато изобрёл фенакистископ — прибор, который позволял демонстрировать эффект движения на основе набора кадров. Это было особенно занимательно, ведь в то же время исследовались фазы движения человека. Вместе эти исследования позволили передавать инерцию движения через набор картинок, характеризующих фазовые переходы. Через полвека различных экспериментов и изобретений мы плавно подошли к новому открытию, которое стало считаться началом современного кинематографа — братья Люмьер в 1883 году придумали новый способ регистрации аналогового изображения на специальных желатиновых пластинах со слоем бромидом серебра. Люмьеры придумали и такой способ съёмки, как тревеллинг, или движение камеры вместе с объектом.
Бурное развитие технологий съёмки позволило создавать первые кинофильмы, сцены становились сложнее, появлялись спецэффекты и многое другое. Это очень хорошая аналогия с тем исследовательским процессом, который проходит наша команда в области генеративного искусственного интеллекта: от создания комбинаций изображений и эффектов имитации движения до генерации фаз движения различных объектов.
Результатом проведённых за последние полгода исследований стала единая двухэтапная архитектура синтеза видео по текстовым описаниям, о которой я и расскажу далее. Сразу предупрежу, что сейчас мы находимся на первом витке развития таких способов генерации видео (как когда-то были на одной ступени Kandinsky 1.0 и DALL·E), поэтому о высоком качестве результата речь пока не идёт. Тем не менее, степень согласованности кадров на видео, визуальное качество объектов на ключевых кадрах, а также автоматические метрики позволяют утверждать, что наше решение сейчас является одним из лучших в мире. Более того, Kandinsky Video — первая в России архитектура полного цикла синтеза видео по тексту.
Архитектура
Архитектура Kandinsky Video основана на латентной диффузии, о чём подробно описано в статье на arXiv (прим., ссылку добавлю через пару дней). Разработанная модель представляет из себя двухэтапную процедуру:
Генерация ключевых кадров для управления основной сюжетной линией видео.
Синтез интерполяционных кадров позволяет улучшить плавность движений объектов благодаря генерации дополнительных кадров.
Такое разделение на этапы позволяет сохранять согласованность с текстовым описанием на протяжении всего видео как по содержанию, так и по динамике. В итоге наша модель способна генерировать по тексту согласованное по времени видео в разрешении 512 × 512 пикселей.

Рисунок 2. Общая схема модели Kandinsky Video.
На рисунке 2 первый этап выделен зелёным цветом, а второй — оранжевым. Чтобы сосредоточиться на ключевых особенностях, я исключил из описания текстовый энкодер и декодер на основе хорошо зарекомендовавшего себя декодера изображений MoVQ-GAN (используем его со времён Kandinsky 2.1, даже есть отдельная статья),. В таблице 1 приведено сравнение количества параметров компонентов архитектуры.
Таблица 1. Количество параметров в компонентах архитектуры.
Text Encoder | T2I part | Temporal part | Total | |
Keyframe Generator | 8,6 млрд | 3 млрд | 1 млрд | 12,9 млрд |
Interpolation Model | - | 3 млрд | 831 млн | 3,9 млрд |
Sber-MoVQGAN video decoder | - | 160 млн | 395 млн | 556 млн |
Этап 1. Генерация ключевых кадров
Генерация ключевых кадров основана на предобученной латентной диффузионной модели text-to-image Kandinsky 3.0. При синтезе ключевых кадров мы используем веса модели для инициализации пространственных слоёв. При этом в архитектуру добавляются специальные блоки для учёта темпоральных связей. Во всех экспериментах мы замораживаем веса U-Net Kandinsky 3.0 и обучаем только темпоральные компоненты. В рамках общей архитектуры нам удалось исследовать два принципиально различных способа учёта корреляции кадров во времени:
с помощью темпоральных свёрточных слоёв и слоёв темпорального внимания;
с помощью темпоральных блоков.
Первый тип работы с темпоральной размерностью был широко представлен в предыдущих зарубежных работах по text-to-video. А второй подход, который собственно и позволил добиться высоких качественных показателей, является нашей оригинальной разработкой. Мы рассмотрели три типа темпоральных блоков, и все они, спойлер, превзошли по качеству традиционный подход со слоями, но об этом далее. Схемы всех методов изображены на рисунке 3.
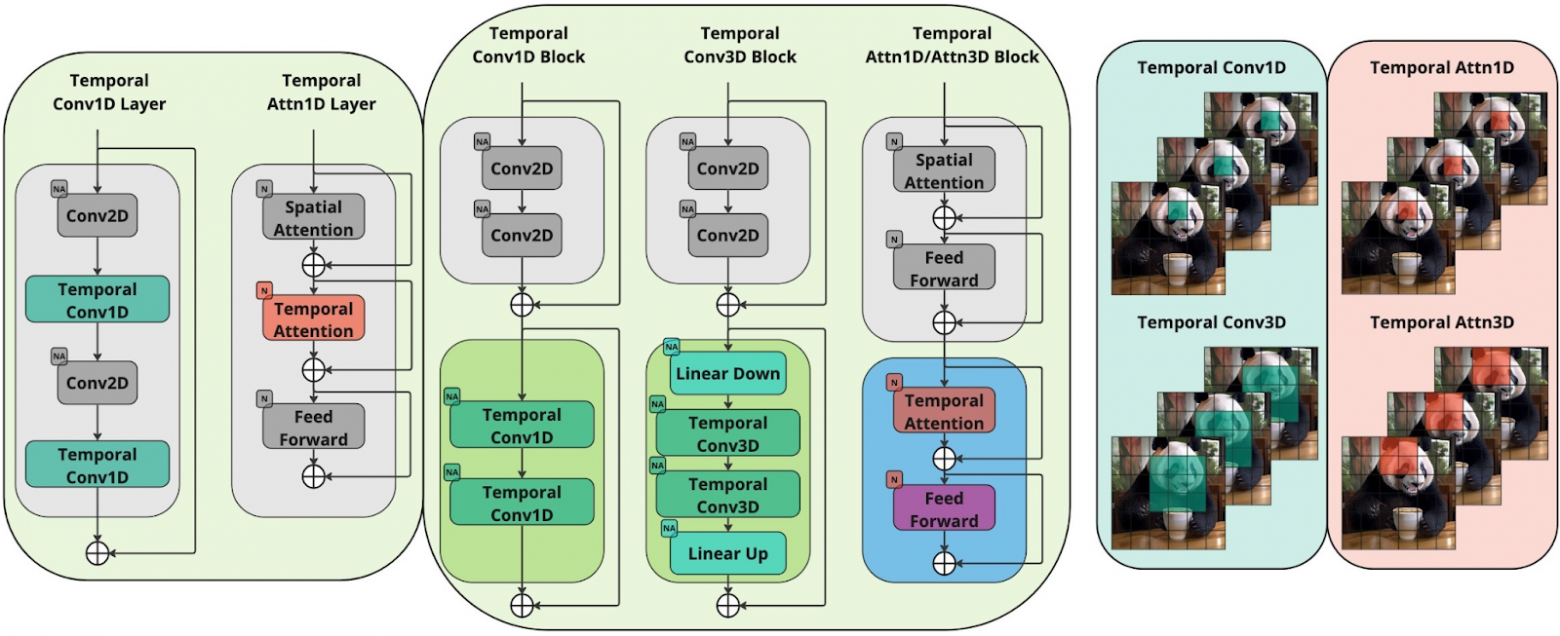
Рисунок 3. Традиционный подход ко внедрению обучаемых темпоральных блоков между замороженными пространственными блоками (слева). Подход Kandinsky Video для выделения темпоральных компонентов в отдельные блоки (в центре). Разные типы темпоральных свёрток и внимания (справа): в 1D-слоях (справа вверху) модель видит значение текущего пикселя в разные моменты времени, в 3D-слоях (справа снизу) модель видит соседние пиксели для текущего.
Этап 2. Генерация интерполяционных кадров
Синтез интерполяционных кадров позволяет добиться плавности генерируемых движений. В противном случае после первого этапа мы получили бы просто слайд-шоу. Мы применяем интерполяцию в латентном пространстве, чтобы предсказать набор из трёх кадров между каждой парой последовательных ключевых кадров. Если кратко: входные свёрточные слои принимают три зашумлённых латентных тензора, соответствующих интерполированным кадрам, и пару ключевых кадров по бокам. На выходе свёртки расшумляют интерполированные кадры. Приходится адаптировать базовую модель генерации изображений с помощью добавления темпоральных свёрток после каждой пространственной свёртки (рисунок 4).

Рисунок 4. Архитектура модели синтеза интерполяционных кадров на примере пары ключевых кадров.
Данные
Для обучения моделей генерации ключевых и интерполяционных кадров мы собрали набор из 220 тысяч пар текст-видео. Тестировали разрабатываемую модель на двух бенчмарках: UCF-101 (набор видео, содержащих различные действия и полнотекстовые описания этих действий) и MSR-VTT (набор описаний видеороликов). Для обучения декодера мы используем 80 тысяч видео из внутреннего набора данных, а тестируем модель на одной из частей набора Vimeo90k. В задаче обучения на этапе интерполяции мы прореживаем кадры со случайным количеством пропускаемых кадров. Для обучения декодера используются последовательности, состоящие из 8 кадров.


Рисунок 5. Примеры из наборов UCF-101 и MSR-VTT для проверки качества модели.
Метрики и количественные результаты
Как и в других работах по анализу качества синтеза видео, мы выбрали следующие показатели оценки качества: Frechet Video Distance (FVD), Inception Score (IS) и CLIPSIM. FVD помогает оценить точность сгенерированного видео. Метрика IS оценивает качество и разнообразие отдельных кадров. CLIPSIM оценивает близость текста и видео. Для расчёта FVD мы используем механику, предложенную в работе Google Brain. IS не имеет унифицированного подхода к расчёту, поэтому мы вычисляем значение метрики на 2048 видео, взяв первые 16 кадров из каждого. Мы сравнили предыдущие модели с нашими, обученными на 100 тысячах шагов, после чего выбрали лучшую из наших моделей и дообучили её ещё до 220 тысяч шагов. Результаты, которые мы получили:
Таблица 2. Результаты генерации text-to-video на наборах UCF-101 и MSR-VTT.
Модель | Генерация zero-shot | FVD (лучше — ниже) | CLIPSIM (лучше — выше) | IS (лучше — выше) |
Проприетарные модели | ||||
GoDIVA | — | — | 0,2402 | — |
Nuwa | — | — | 0,2439 | — |
Magic Video | — | 699,00 | — | — |
Video LDM | — | 550,61 | 0,2929 | — |
Make-A-Video | + | 367,23 | 0,3049 | 33,00 |
Open source модели | ||||
LVDM | — | 641,80 | — | — |
ModelScope | — | — | 0,2930 | — |
LaVie | — | 526,30 | 0,2949 | — |
CogVideo (Chinese) | + | 751,34 | 0,2614 | 23,55 |
CogVideo (English) | + | 710,59 | 0,2631 | 25,27 |
Kandinsky Video | + | 659,61 | 0,2827 | 19,66 |
Kandinsky Video | + | 545,18 | 0,2955 | 23,06 |
Kandinsky Video | + | 573,57 | 0,2956 | 23,38 |
Kandinsky Video | + | 594,92 | 0,2953 | 22,90 |
Kandinsky Video | + | 433,05 | 0,2976 | 24,33 |
Из таблицы 2 видно, что темпоральные блоки превосходят по качеству темпоральные слои, внедрённые в блоки предобученных пространственных слоёв. Кроме того, наша лучшая модель заняла второе место с точки зрения CLIPSIM и FVD и первое место среди open source-решений. Что касается IS, то здесь хотелось бы заметить, что относительно более низкие показатели для этой метрики могут быть объяснены неоднозначностями в её оценке. В существующей литературе отсутствует подробная информация о методологиях, используемых для расчёта IS для видео, в том числе в тех работах, с результатами которых мы сравнивали.
Мы также оценили качество нашего метода интерполяции, сравнив его с методом Masked Frame Interpolation (MFI), описанным в известной статье от NVIDIA. Мы сравнили 2048 видео и получили, что качество нашей интерполяции превосходит упомянутый метод и достигает 24,325 IS и 433,054 FVD против 23,371 IS и 550,932 FVD у MFI соответственно.
Качественное сравнение
Мы также провели качественное side-by-side сравнение наших подходов для учёта темпоральной информации с помощью темпоральных слоёв и трёх типов темпоральных блоков (рисунок 3). Для этого мы создали бота, который каждый раз демонстрировал одну из 6600 пар видео для 31 человека. Каждый участник выбирал лучшее из двух видео с точки зрения:
качества отдельных кадров,
соответствия тексту,
временной согласованности.
На рисунке 6 приведены результаты качественного сравнения. Результаты моделей, включающих в себя наши темпоральные блоки, нравятся значительно чаще.

Рисунок 6. Результаты качественного side-by-side сравнения.
Эффективность
Основную нагрузку на вычислительные ресурсы возлагает этап интерполяции. Поэтому мы также сравнили длительность инференса для нашей модели интерполяции и уже упомянутого выше метода MFI, и выяснили, что наш метод справляется с генерацией полноценного видео из 241 кадра с 30 FPS менее чем за 3 минуты — более чем в три раза быстрее, чем MFI.

Рисунок 7. Сравнение длительности инференса для нашего метода интерполяции и метода Masked Frame Interpolation.
Генерации
Итак, напоследок представляю вашему вниманию немного красивых и залипательных видеогенераций



Заключение
В этой статье мы описали нашу новую архитектуру Kandinsky Video на основе модели Kandinsky 3.0 для генерации видео по тексту. Наша модель побеждает с точки зрения FVD и CLIPSIM среди моделей с открытым исходным кодом. Безусловно, сейчас путь в области синтеза видео только начинается, но первый шаг, на мой взгляд, получился достаточно широким. Можно представить, что в скором будущем мы уже будем смотреть фильмы, синтезированные с помощью AI, часть спецэффектов может быть заменена на генеративные, актёры могут быть созданы с точностью до деталей, которые хочет видеть режиссёр, и многое другое. Самые сложные сцены в кинематографе (свободное падение, замедленная съёмка и др.) можно будет реализовывать на домашнем ПК с доступом в интернет. С точки зрения исследований, впереди у нас огромный ряд задач, связанных как с повышением качества кадров, так и с улучшением динамичности и плавности движений, в том числе за счёт исследования способов обучения модели физике движения тел. В недалёком будущем мы расскажем о ещё одном исследовательском направлении, которое удалось успешно прокопать за последние пару месяцев.
Следите за новостями на каналах CompleteAI, AbstractDL, Dendi Math&AI и на канале Сергея Маркова.
Авторы и их вклад
Модель Kandinsky Video разработана и исследована командой Sber AI при партнёрской поддержке учёных из Института искусственного интеллекта AIRI на объединённом наборе данных Sber AI и компании SberDevices.
Коллектив авторов: Владимир Архипкин, Зейн Шахин, Вячеслав Васильев, Игорь Павлов, Елизавета Дахова, Анастасия Лысенко, Сергей Марков, Денис Димитров и Андрей Кузнецов.
Контакты для коммуникации
По всем возникающим вопросам и предложениям по развитию модели, добавлению новых возможностей и сотрудничеству в части использования наших разработок можно писать Денису или Андрею.
