Kandinsky 2.1, или Когда +0,1 значит очень много

В ноябре 2022 года мы выпустили свою первую диффузионную модель для синтеза изображений по текстовым описаниям Kandinsky 2.0, которая собрала как позитивные, так и отрицательные отклики. Её ключевой особенностью была мультиязычность и использование двойного текстового энкодера на входе сети: XLMR-clip и mT5-small. Рефлексия после релиза подтолкнула нас к перестройке планов по развитию архитектуры и к сильному стремлению получить буст в качестве генераций, чтобы выйти на уровень аналогичных решений, названия которых слишком хорошо известны, чтобы их называть. В то же время мы могли наблюдать за появлением новых генеративных моделей и их файнтюнов, таких как ControlNet, GigaGAN, GLIGEN, Instruct Pix2Pix и др. В этих работах представлены и новые взгляды на генерацию, и новые возможности использования латентного пространства для внесения контролируемых изменений через текстовые запросы, а также для смешивания изображений — возможности использования генеративных моделей расширяются постоянно. Бурное развитие прикладных кейсов привело к интенсивно нарастающему числу различных привлекательных для пользователей реализаций этих функций — визуализация городов, изображения известных личностей в нетипичных ситуациях и многие другие.
Протестировать модель на своих запросах можно несколькими способами:
в Telegram‑боте (есть все доступные 4 режима генерации)
на сайте fusionbrain.ai (доступна генерация по тексту и режимы inpainting/outpainting)
на платформе MLSpace в хабе предобученных моделей и датасетов DataHub
в навыке Салют «Включи художника»
на сайте rudalle.ru
В целях повышения качества генераций будущих пользователей мы также разрабатываем специальный промтбук, который позволит вам выжать из модели максимум :)
Архитектура и детали обучения
Решение о внесении изменений в архитектуру пришло после продолжения обучения версии Kandinsky 2.0 и попыток получить устойчивые текстовые эмбеддинги мультиязычной языковой модели mT5. Закономерным выводом стало то, что использование только текстового эмбеддинга было недостаточно для качественного синтеза изображения. Проанализировав еще раз существующее решение DALL-E 2 от OpenAI было принято решение поэкспериментировать с image prior моделью (позволяет генерировать визуальный эмбеддинг CLIP по текстовому промту или текстовому эмбеддингу CLIP), одновременно оставаясь в парадигме латентного визуального пространства, чтобы не пришлось переобучать диффузионную часть UNet модели Kandinsky 2.0. Теперь чуть больше деталей про процесс обучения Kandinsky 2.1.
На первом этапе мы начали учить image prior модель для маппинга текстов и изображений, обучив отдельную диффузионную модель DiffusionMapping на текстовых и картиночных эмбеддингах CLIP. В качестве модели CLIP мы использовали предобученные веса mCLIP, а в основе DiffusionMapping лежит трансформерная архитектура с параметрами:
num_layers=20
num_heads=32
hidden_size=2048
Обучив image prior модель (рисунок 1, слева), мы стали учить целевую модель синтеза изображения по текстовому описанию (рисунок 1, в центре). В этой реализации обученный image prior в виде модели DiffusionMapping использовался для синтеза по входному текстовому промту визуального эмбеддинга mCLIP, который далее применялся в процессе обучения диффузионной модели. Таким образом, мы обучали механизм обратной диффузии восстанавливать латентное представление изображения НЕ только из текстового эмбеддинга как в Kandinsky 2.0, а еще и из визуального эмбеддинга CLIP с condition на этот текстовый эмбеддинг. В паре с дополнительными чистыми данными такое архитектурное изменение привело к существенному росту качества генераций (генерации можно наблюдать в конце статьи). В качестве конечного блока модели выступает новый декодер, который из латентного представления позволяет получить финальное синтезированное изображение.
Среди нескольких возможных способов использования генеративной модели мы особое внимание уделили возможности смешивания изображений (рисунок 1, справа). В отсутствии необходимости использовать текстовые эмбеддинги мы просто подаём в обученную диффузионную модель два визуальных эмбеддинга CLIP, и далее декодером восстанавливаем «смешанное» изображение.
В описании выше я умышленно не погрузился в детали нового декодера изображений, потому что этот этап заслуживает отдельного внимания, и даже отдельной статьи, но кратко о том, почему мы ушли от использованного в прошлых версиях генеративных моделей VQGAN и стали использовать специально обученный для наших целей MoVQGAN модель, я расскажу в отдельном блоке ниже.
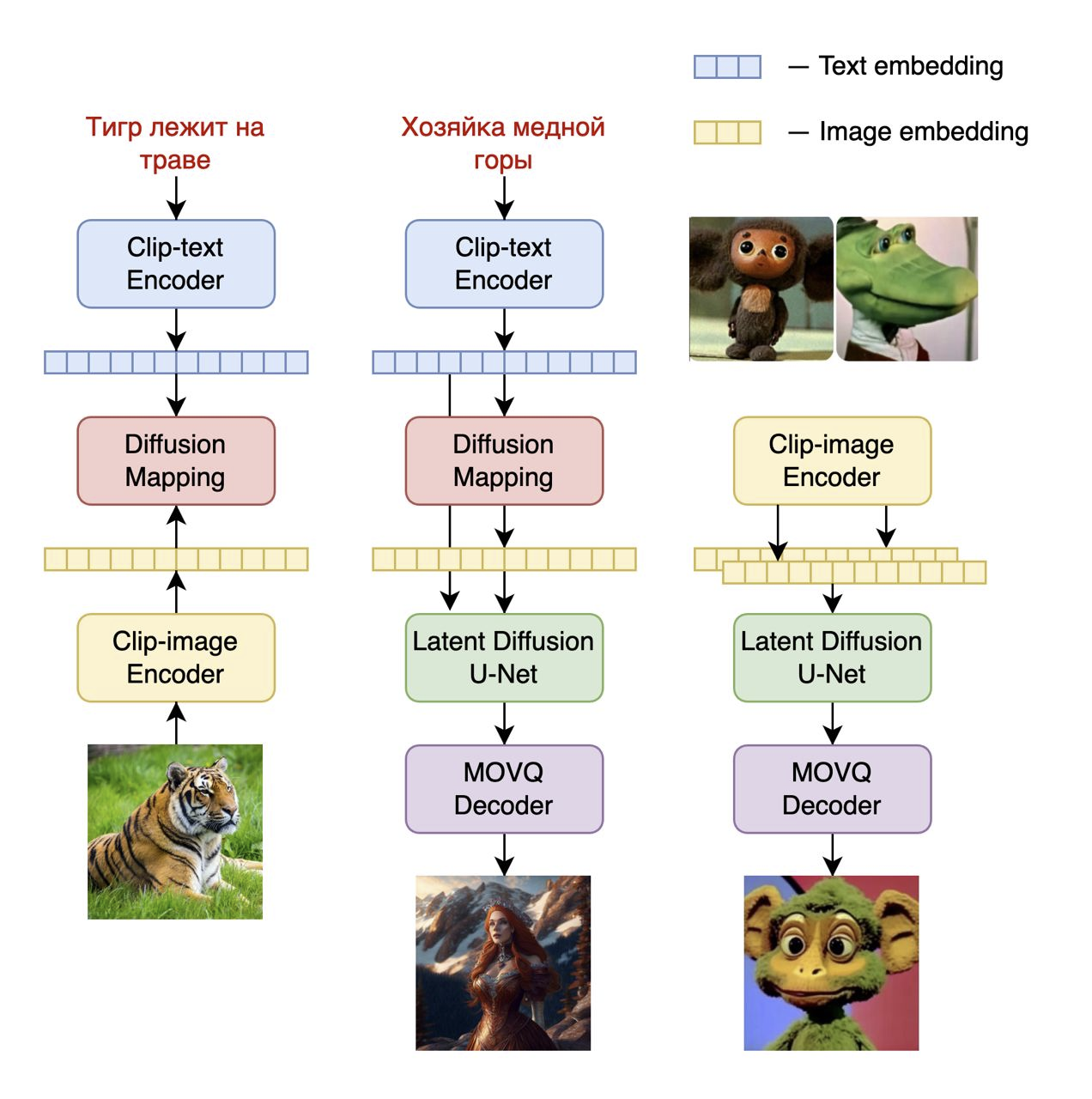
Рисунок 1. Обучение image prior модели (слева), архитектура text2image модели (в центре), механика смешивания изображений (справа).
Архитектура Kandinsky 2.1 содержит 3.3B параметров:
Text encoder (XLM-Roberta-Large-Vit-L-14) — 560M
Image prior — 1B
CLIP image encoder — 427M
Latent Diffusion UNet — 1.22B
MoVQ encoder/decoder — 67M
Для того, чтобы каждый мог оценить качество новой модели Kandinsky 2.1 мы по традиции выкладываем веса в open source на следующих источниках:
Датасеты
Обучение image prior модели выполнялось на датасете LAION Improved Aesthetics, а затем был выполнен файнтюн на данных LAION HighRes.
Обучение основной Text2Image диффузионной модели выполнялось на основе 170M пар «текст-изображение» из датасета LAION HighRes (важным условием было наличие изображений с разрешением не меньше 768×768). Использование 170M пар для претрейна обусловлено тем, что мы сохранили диффузионный блок UNet от версии Kandinsky 2.0, что позволило не обучать его с нуля. Далее на этапе файнтюнинга применяли отдельно собранный из открытых источников датасет из 2М очень качественных изображений в высоком разрешении с описаниями (COYO, anime, landmarks_russia и ряд других).
Визуальный автоэнкодер MoVQGAN
В ранних исследованиях (Kandinsky 1.0 и 2.0) мы использовали VQGAN автоэнкодер, который был специально дообучен под задачи синтеза изображений на таких сложных доменах, как тексты и лица людей. Это позволило добиться определённого успеха в части генераций изображений по сравнению с ванильной моделью VQGAN. Более подробно об экспериментах с VQGAN автоэнкодером мы писали в этой статье.
Очевидно, что весомо в эффектность генераций добавляет именно визуальный декодер, поэтому от его качества зависит очень много. Часто бывает так, что когда долго ищешь решение проблемы, оно приходит не сразу, но стоит немного отпустить мысль, как возникает какой-то новый путь. Получилось так, что на одном из регулярно проводимых в нашей команде ReadingClub мы делали обзор новой модели VQGAN — MoVQ: Modulating Quantized Vectors for High-Fidelity Image Generation [1]. Эта работа дала новую жизнь части модели, отвечающей за представление изображений в пространстве квантованных векторов.
Основное нововведение MoVQ заключается в добавлении слоя spatial conditional нормализации в блоки декодера, что позволило повысить реалистичность восстанавливаемых изображений. Сама идея spatial нормализации не новая и известна со времён StyleGAN и AdaIN слоёв, но авторы MoVQ применили её в пространстве квантованных представлений энкодера, что позволило избежать возникновения типичных повторяющихся артефактов, которые возникают из-за процесса квантования пространственно близких эмбеддингов в одинаковые индексы codebook. Использование spatial нормализации добавляет степеней свободы квантованным представлениям после энкодера и позволяет распространять по слоям декодера более вариативные представления эмбеддингов.
Приведённые в [1] результаты сравнения с известными автоэнкодерами показывают качественное преимущество по всем известным метрикам (PSNR, SSIM, LPIPS и rFID) на двух датасетах: датасет лиц FFHQ и датасет ImageNet (рисунок 2). Отдельно хочется обратить внимание на тот факт, что размер codebook (Num Z) для модели MoVQ самый маленький и составляет всего 1024 вектора. Следует также отметить, что визуально качество MoVQ по изображениям оценить крайне трудно, но далее я приведу примеры декодированных изображений обученной нами модели на самых сложных доменах для автоэнкодеров: лица и текст.
![Рисунок 2. Сравнение MoVQ с другими энкодерами [1]](https://habrastorage.org/r/w1560/getpro/habr/upload_files/045/c35/d5f/045c35d5f34db1ed4862dda77d03e00a.png)
Рисунок 2. Сравнение MoVQ с другими энкодерами [1]
Впечатлившись результатами MoVQ, мы реализовали блок spatial нормализации в рамках нашей модели VQGAN, потому что технически эта операция была совершенно понятна и проста. Модель содержит всего 67M параметров, но результаты восстановления действительно не позволяют в большинстве случаев отличить декодированное изображение от исходного (groundtruth). Модель обучалась на 1 GPU в течение двух недель на данных LAION HighRes. Как и обещал, предлагаю оценить качество восстанавливаемых изображений на ярких примерах с декодированием лиц, текста и сложных сцен. В отдельной статье мы представим более подробное сравнение различных автоэнкодеров c нашей реализацией MoVQ.

Сравнение с другими Text2Image моделями
Далеко не все современные решения делятся результатам качественной оценки своих моделей, ведь куда важнее пользовательский отклик — это лучшая оценка работы модели. Тем не менее, мы как исследовательская команда не можем себе позволить обойти стороной вычислительные эксперименты на уже всем известных датасетах для валидации генеративных моделей. С точки зрения метрики мы всё также используем уже ставшую золотым стандартом оценки Frechet Inception Distance (FID), которая позволяет оценить близость двух вероятностных распределений (распределение оригинальных изображений и распределение синтезированных генеративной моделью изображений):

где r — оригинальные, а g — сгенерированные изображения.
Сравнение Kandinsky 2.1 и аналогичных решений мы проводили на датасете COCO_30k, который содержит 30 тыс. изображений с центральным кропом до 256×256 пикселей. Измерять мы будем в режиме zero-shot, то есть датасет COCO не использовался при обучении модели. Полученные результаты (Таблица 1) позволяют утверждать, что Kandinsky 2.1 сделал большой качественный скачок относительно своих прошлых версий и вышел на уровень зарубежных аналогов, а некоторые из них даже превзошел. Среди известных решений модель Kandinsky 2.1 занимает уверенное третье место.
Таблица 1. Значения метрики FID генеративных моделей на COCO_30k
FID-30K | |
eDiff-I (2022) | 6,95 |
Imagen (2022) | 7,27 |
Kandinsky 2.1 (2023) |
|
