Apache Sedona — как быстро работать с геоданными
Привет! В рамках своей работы в beeline tech мы часто взаимодействуем с геоданными. Для решения проблем, связанных с хранением, обработкой и анализом большого объема распределенных пространственных данных, мы используем Apache Sedona (бывший Geospark). Мы — Денис Афанасьев, аналитик больших данных, и Женя @evgeniy_rybalkin Рыбалкин, инженер больших данных, под катом расскажем, почему выбрали именно этот инструмент и что он умеет. А чтобы показать, зачем вообще работать с геоданными, давайте возьмем пример расчета посещаемости хоккейных матчей в Москве, как-никак плей-офф в разгаре.
Давайте по порядку. Почти любой доступный смартфон, умные часы, фитнес-браслеты, оборудование для IoT — всё это может получать и передавать данные о собственном местоположении. Кроме потребительского железа серьезную эволюцию прошёл и интернет вещей в целом, причем как классический IoT для умного дома и других полезностей, так и индустриальный IIoT, заточенный под мониторинг сложных технологических систем, сельское хозяйство, мониторинг окружающей среды и многое другое.
Следствием такого развития, как в количественном, так и в качественном плане, стал ощутимый рост того объёма данных, который все эти устройства генерируют. Ну и что нам с ними делать? Давайте разберемся на примере геоданных!
Зачем вообще кому-то нужны геоданные?
Собирая большой объём обезличенных геоданных, можно решать множество полезных для коммерческой, транспортной и социальной сфер задач, смотрите:
Трансформация городской инфраструктуры. Сейчас почти у каждого человека есть смартфон, который если и не передает GPS, то создает нагрузку на базовые станции сотовых операторов, которые в свою очередь эту информацию могут переводить в человекопотоки. Сбор геоданных поможет создать решения, которые позволят, например, оптимизировать движение общественного транспорта или же разместить очередной пункт проката велосипедов и самокатов.
Развитие туризма. Геоданные помогают анализировать посещаемость разных локаций туристами, создавать look-alike модели и давать релевантные рекомендации по посещению на новых для туриста территориях. Для госуправленцев это в первую очередь информация о предпочтениях туристов и сведения, которые помогут внедрить правильные инфраструктурные изменения, чтобы привлечь больший турпоток в свой регион.
Польза для бизнеса. Чаще всего геоданные используют в банках, ритейле, FMCG и у девелоперов. Знания о точках концентрации своей целевой аудитории помогают кратно снижать расходы на промо-кампании и повышать конверсию рекламных акций в покупки. Как следствие — увеличение доходов благодаря принятию взвешенных продуктовых и маркетинговых решений.
Глобальные задачи. На геоданных можно строить модели, которые помогут мониторить объёмы выбросов в атмосфере больших городов, искать незаконные свалки и места нелегальной вырубки леса, оценивать число людей, на которых может повлиять стихийное бедствие, и многое другое.
Если всё так круто, то почему же не все подряд используют геоданные в своей сфере? Давайте обсудим проблемы, возникающие при обработке геоданных.
Во-первых, необходим доступ к геоданным. Вы либо сами являетесь провайдером данных, либо обращаетесь к ним для получения доступа к ограниченному набору анонимизированных агрегированных данных.
Во-вторых, требуется наличие технических компетенций и настроенных инструментов для сбора и хранения геоданных в выбранной системе координат с учетом необходимой точности и топологии пространственных объектов. В наиболее распространенных СУБД этот функционал либо отсутствует, либо представлен в ограниченном виде.
В-третьих, отсутствие единого стандарта хранения пространственных данных и отсутствие полной интероперабильности (совместимости) между сервисами, поставляемыми разными вендорами, при чтении или обработке файлов геоданных.
В-четвертых, сложность и неоднозначность интерпретации результатов пространственного анализа — выбор итоговых метрик, количественных и качественных показателей зависит исключительного от наработанного опыта или требований конечного заказчика.
В чём плюсы Apache Sedona
Чаще всего для пакетной обработки и аналитики больших данных используют Apache Spark, так как он является одной из самых производительных систем среди аналогов, имеющих возможность выполнять параллельные вычисления в распределенных системах хранения.
Но у него есть слабое место — он не поддерживает обработку пространственных данных. Этот минус можно обойти с помощью Apache Sedona — готового решения для быстрой обработки геоданных в Apache Spark, с июля 2020 оно находится в каталоге проектов Apache Software Foundation.
Apache Sedona может принимать геоданные во множестве форматов: GeoJSON, WKT, WKB, ESRI и других. Для обращения к ним Apache Sedona использует готовые API пространственных SQL-запросов и RDD API. Отдельный плюс — возможность работы с векторным типом данных. Сразу отметим, что Apache Sedona — решение не уникальное (аналогов существует достаточно), но самое популярное благодаря набору инструментов и производительности.
Отлично, так как им пользоваться?
Запускаем spark-shell в командной строке (cli) командой:
spark-shell
Если у вас не установлен Apache Sedona, то его можно добавить при запуске spark-shell с указанием jar-файлов нужных версий Apache Sedona и Spark, например, для версии spark 2.3 и sedona 2.4:
--jars geotools-wrapper-geotools-24.0.jar,,sedona-viz-2.4_2.11-1.2.1-incubating.jar,,sedona-sql-2.4_2.11-1.2.1-incubating.jar
Инициализируем Apache Sedona
// импортируем классы для инициализации
import org.apache.spark.serializer.KryoSerializer
import org.apache.spark.sql.SparkSession
import org.apache.sedona.core.serde.SedonaKryoRegistrator
import org.apache.sedona.sql.utils.SedonaSQLRegistrator
import org.apache.sedona.viz.sql.utils.SedonaVizRegistrator
// задаем конфигурации для spark сессии
val spark: SparkSession = SparkSession.
builder().
config("spark.serializer", classOf[KryoSerializer].getName).
config("spark.kryo.registrator", classOf[SedonaKryoRegistrator].getName).
config("sedona.global.index", "true").
config("sedona.join.gridtype", "kdbtree").
config("spark.sql.session.timeZone", "Europe/Moscow").
config("hive.exec.dynamic.partition", "true").
config("hive.exec.dynamic.partition.mode", "nonstrict").
enableHiveSupport().
getOrCreate()
// регистрируем функции Apache Sedona
SedonaSQLRegistrator.registerAll(spark)
Проверим успешность импорта Apache Sedona следующим запросом:
spark.sql("show functions like 'ST_*'").show(false)Если вывелся список функций, то Apache Sedona готов к работе.

Всё. После всего этого вы можете начинать работать с векторными геоданными. Если вдруг вам надо поставить какие-то задачи на расписание и работать не в интерактивной оболочке, то можно включить в сборку зависимости Apache Sedona, расширив возможности приложения.
Команды Apache Sedona
В библиотеке Apache Sedona SQL при работе с векторным типом данных выделяют несколько групп команд. Подробнее о каждой группе — в таблице ниже.
Группа команд | Для чего используются | Примеры функций |
Конструкторы | Для чтения файлов данных, содержащих пространственные данные, преобразования из текста в геометрию | ST_GeomFromWKT, ST_Point, ST_PolygonFromText |
Функции | Для обработки геометрии, извлечении пространственных характеристик объектов | ST_Length, ST_Area, ST_Transform, ST_XMax, ST_Buffer, ST_Distance |
Предикаты | Для работы с отношениями между пространственными объектами | ST_Contains, ST_Intersects, ST_Covers, ST_Overlaps |
Агрегаты | Для создания агрегированных объектов из всего набора данных | ST_Envelope_Agg, ST_Union_Agg, ST_Intersection |
Описания всех функций можно найти на сайте документации Apache Sedona.
Шайбу! Шайбу! Партицирование пространственных данных
Реализация методов пространственного партицирования является ключевым элементом в составе библиотеки Apache Sedona, позволяющим быстро обрабатывать большой объем распределенных данных.
Данные в Spatial RDD партицированы согласно распределению объектов в пространстве, то есть объекты, расположенные, например, в одном муниципальном образовании, вероятнее всего будут записаны в одну партицию.
Таким образом, Apache Sedona при выполнении пространственных выборок может исключать из расчетов ненужные (или не находящиеся в конкретном регионе) партиции, ускоряя вывод конечного результата.
В дополнении к этому партиции, построенные на основе пространственного индекса, позволяют условно нарезать исходные данные на равнозначные по объему части.
Рассмотрим пример построения нескольких вариантов пространственного партицирования данных на примере всех событий наших абонентов за один день на территории Москвы — это примерно десятки миллиардов событий, имеющих координаты. К событиям абонента могут относиться: звонок, отправка СМС, выход в интернет.
Для начала импортируем необходимые библиотеки:
import com.vividsolutions.jts.geom.{Coordinate, Envelope, Geometry, GeometryFactory}
import org.apache.sedona.core.enums.{GridType, IndexType}
import org.apache.sedona.core.spatialRDD.SpatialRDD
import org.apache.sedona.sql.utils.Adapter
import org.geotools.geometry.jts.JTSFactoryFinder
import scala.collection.JavaConverters.asScalaBufferConverterДля визуализации границ создадим вспомогательный объект GeometryHelper:
/*
Вспомогательный объект для преобразования границ сетки SpatialRDD типа Envelope в тип Geometry
*/
object GeometryHelper {
// Построение объекта Geometry типа Polygon из данных типа Envelope
def getPolygonBBoxByEnvelope(envelope: Envelope): Geometry = {
val geometryFactory: GeometryFactory = JTSFactoryFinder.getGeometryFactory
val points = Array(
new Coordinate(envelope.getMinX, envelope.getMinY),
new Coordinate(envelope.getMinX, envelope.getMaxY),
new Coordinate(envelope.getMaxX, envelope.getMaxY),
new Coordinate(envelope.getMaxX, envelope.getMinY),
new Coordinate(envelope.getMinX, envelope.getMinY)
)
geometryFactory.createPolygon(points)
}
implicit class SpatialRDDExtension(spatialRDD: SpatialRDD[Geometry]) {
// имплист метод SpatialRDD для получения сетки пространственного разбиения
def getBBoxGrids: Seq[Geometry] = {
asScalaBufferConverter(spatialRDD.getPartitioner.getGrids)
.asScala
.map(GeometryHelper.getPolygonBBoxByEnvelope)
}
}
}
import GeometryHelper.SpatialRDDExtension
В текущей версии доступно несколько методов партицирования: QuadTree и KDBTree. Подробнее о работе алгоритмов можно прочитать здесь.
Пример партицирования методом QuadTree с количеством партиций 40 с использованием пространственного индекса RTree приведен ниже:
// создаем DF с нужными геометриями для которых хотим создать пространственное разбиение, например для набора координат lon, lat
val pointsDF = spark.table("points").
withColumn("geom", expr("ST_Point(lon, lat)"))
// указываем желаемое количество партиций
val numPartitions = 40
// создаем пространственное RDD
val spatialRDD = Adapter.toSpatialRdd(pointsDF.select("geom"), "geom")
// для построения пространственного разбиения необходимо выполнить сперва analyze()
spatialRDD.analyze()
// строим пространственное разбиение
spatialRDD.spatialPartitioning(GridType.QUADTREE, numPartitions)
// строим пространственный индекс
spatialRDD.buildIndex(IndexType.RTREE, true)
Для вывода сетки используем созданный ранее имплисит метод getBBoxGrids:
val gridsDF = spatialRDD.
getBBoxGrids. // имплисит метод
map(_.toString).
toDF("geo_wkt")Сопоставление разных вариантов партицирования между собой — ниже на рисунке. Наиболее крупные (по площади) партиции охватывают территории Новой Москвы, где происходит относительно мало событий, и наоборот, площадь партиций становится меньше в центральных районах Москвы, где в обычный день сосредоточено наибольшее количество событий абонентов.
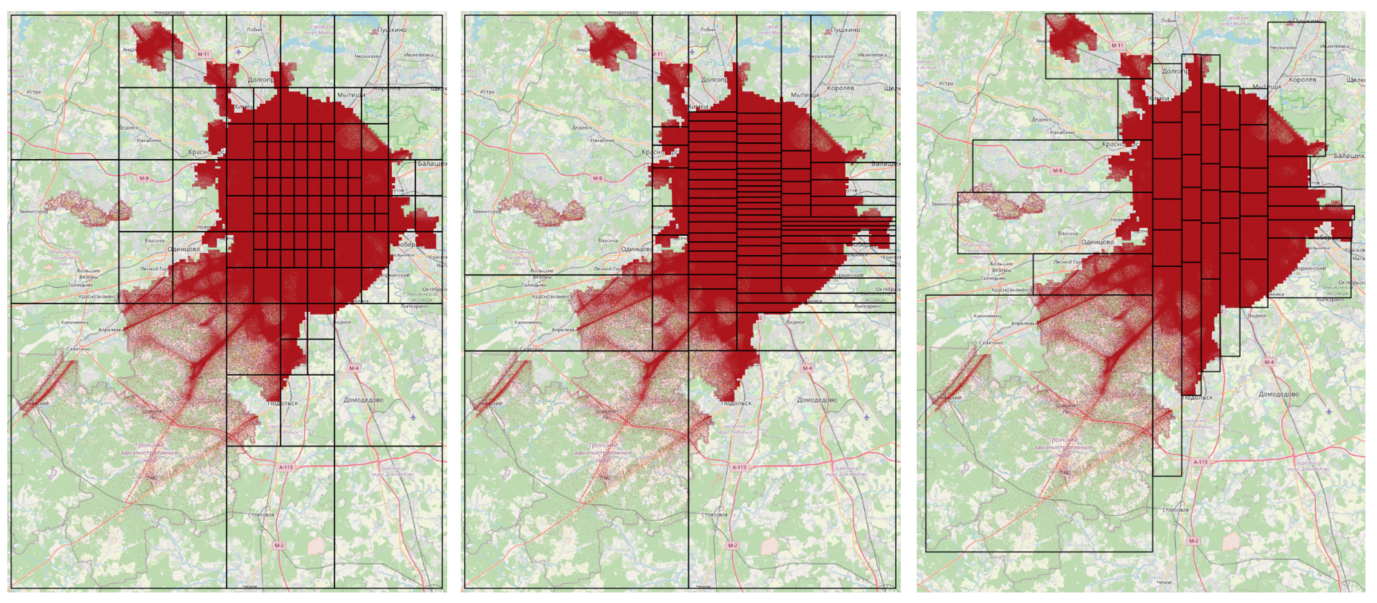
Cетки, построенные с помощью разных методов пространственного партицирования: слева-направо — QuadTree, KDBTree, RTree (был доступен в geospark). Красные точки — события абонентов.
Как сделать пространственную выборку
Apache Sedona, помимо стандартной выборки по значению атрибутов (например, по парам минимальных и максимальных координат), позволяет использовать геометрию для выборки нужных объектов.
Рассмотрим несколько вариантов пространственной выборки на примере локализованных событий абонентов вблизи хоккейной арены ЦСКА.

Уникальные координаты событий абонентов в день проведения хоккейного матча вблизи арены ЦСКА
Перед этим сконвертируем координаты объектов из исходного формата wkt в формат геометрии Apache Sedona. Для этого используем функции ST_GeomFromWKT для полигонального объекта (арена ЦСКА) и ST_Point для точечных объектов (события абонентов):
// источники
val stadium = spark.table("stadiums").filter($"name_en" === "CSKA")
stadium.createOrReplaceTempView("stadium")
val customers = spark.table("customers").
select("customer_id","start_time","end_time", "interval_duration","lat", "lon").
cache
customers.createOrReplaceTempView("customers")
// полигон из текста wkt
val polygon = spark.sql("SELECT name_en, ST_GeomFromWKT(wkt) AS geom_polygon from stadium")
polygon.createOrReplaceTempView("polygon")
// геодатафрейм из точек
val points = spark.sql(
"""SELECT *, ST_Point(cast(lon as decimal(10,4)), cast(lat as decimal(10,4))) AS geom_point
FROM customers
""".stripMargin)
points.createOrReplaceTempView("points")
При наличии данных повышенной точности, например, собранных с помощью A-GPS, можно использовать геометрию здания арены, то есть выбрать только те события, которые попали в ее пределы. Для пересечения геометрии полигона арены и событий абонентов используем функцию ST_Intersects:
// выборка по полигону
var selection = spark.sql(
"""SELECT points.customer_id, points.start_time, points.end_time, points.interval_duration, points.lat, points.lon, polygon.name_en
FROM points, polygon
WHERE ST_Intersects(points.geom_point, polygon.geom_polygon)
""".stripMargin)
Следующий вариант выборки предполагает использование полигона, содержащего пары минимальных и максимальных координат выбранной области (экстента или bbox). Этот способ аналогичен тому, если бы мы выбирали объекты по координатам из таблицы с помощью условия больше или меньше. Используем функцию ST_Envelope:
// выборка по bbox
val bbox = spark.sql("select ST_Envelope(geom_polygon) bbox from polygon")
bbox.createOrReplaceTempView("bbox")
var selection = spark.sql(
"""
SELECT points.customer_id, points.start_time, points.end_time, points.interval_duration, points.lat, points.lon
FROM points, bbox
WHERE ST_Intersects(points.geom_point, bbox.bbox)
""".stripMargin)
Выборка по буферу с указанием его размера в метрах может быть использована, когда мы имеем дело с недостаточно высокой точностью данных геопозиционирования. Используем функцию ST_Buffer для выделения всех событий, произошедших на расстоянии 150 метров от центра арены (ST_Centroid(geom_polygon)). Функция ST_Transform в коде также необходима, потому что мы хотим задать значение в метрах — для этого нужно перейти в метрическую систему координат:
// выборка по буферу 150 метров
val centroid = spark.sql("""select ST_Transform(ST_Centroid(geom_polygon),'epsg:4326','epsg:32637') as stadium_centroid from polygon""".stripMargin)
centroid.createOrReplaceTempView("centroid")
centroid.show()
val buffer = spark.sql("select *, ST_Buffer(stadium_centroid,150) AS buffer_150 FROM centroid")
buffer.createOrReplaceTempView("buffer")
buffer.show()
var selection = spark.sql(
"""
SELECT points.customer_id, points.start_time, points.end_time, points.interval_duration, points.lat, points.lon
FROM points, buffer
WHERE ST_Intersects(ST_Transform(points.geom_point,'epsg:4326','epsg:32637'), buffer.buffer_150)
""".stripMargin)

Сопоставление нескольких вариантов пространственных выборок. Слева–направо: выборка по геометрии полигона, выборка по экстенту (bbox), выборка по буферу
Как мы считали посещаемость
Для расчета посещаемости мы использовали уже готовую собственную витрину данных временных интервалов, собранную на основе событий абонентов.

Пример структуры данных событий абонентов
Дополнительно мы собрали информацию о хоккейных матчах, которые проводились на трех аренах Москвы (ЦСКА, «Мегаспорт» и ВТБ Арена) в период проведения регулярного чемпионата КХЛ с сентября 2022 по январь 2023 года включительно. Всего за это время было сыграно 84 матча, или по 28 на каждую из хоккейных команд: ЦСКА, Спартак и Динамо М.
К ключевым параметрам матча в нашем случае относятся дата и время начала игры, место проведения.

В качестве критерия посещения абонентов определенного матча мы выбрали наличие непрерывного 20-минутного интервала во время проведения матча. Для упрощения подсчетов для каждого матча определена одинаковая продолжительность по времени — 2 часа.
Для пространственной выборки мы использовали метод буфера, то есть искали события абонентов в пределах определенного расстояния от центра арены.
Вначале соберем данные об аренах и параметрах игр:
// геометрия арен
val stadiums_poly = spark.sql("""SELECT name_en, ST_GeomFromWKT(wkt) AS geom_polygon from stadiums""")
// параметры игр
val params = games.join(stadiums, games("stadium") === stadiums("name_en"), "left").
withColumn("time_key", to_date("start_time","dd.MM.yyyy HH:mm")).
withColumn("game_end", $"game_start"+expr("INTERVAL 2 HOURS")).
drop("start_time", "name_en", "wkt").
val games = params.select($"game_id", $"stadium", $"game_start", $"game_end", $"time_key")
Далее подготовим новый пустой датафрейм для записи временных интервалов абонентов, удовлетворяющих критериям посещения матчей:
import org.apache.spark.sql.types.{
StructType, StructField, StringType, IntegerType, DateType, LongType}
import org.apache.spark.sql.Row
val schema = StructType(
StructField("customer_id", StringType, true) ::
StructField("stadium", StringType, true) ::
StructField("start_time", StringType, true) ::
StructField("end_time", StringType, true) ::
StructField("game_start", StringType, true) ::
StructField("game_duration", LongType, true) ::
StructField("game_id", IntegerType, true) :: Nil)
var customers = spark.createDataFrame(sc.emptyRDD[Row], schema)
Составим цикл для отбора нужных нам временных интервалов для каждого матча и добавим конечный результат в датафрейм в следующей последовательности:
Выбор всех интервалов в день проведения матча.
Создание точечного слоя геометрии для всех выделенных интервалов.
Пересечение точечного слоя и буфера арены.
Расчет продолжительности интервала во время матча и отбор только тех, которые равны или больше 20 минут.
games.collect().foreach { row =>
val game_id = row(0)
val stadium = row(1)
val game_start = row(2).toString.substring(0,19)
val game_end = row(3).toString.substring(0,19)
val time_key = row(4)
println(game_id, stadium, game_start, game_end, time_key)
val customers_sr1 = time_int.filter($"time_key" === time_key).
select($"customer_id", $"start_time", $"end_time", $"interval_duration", $"lat", $"lon", $"time_key")
customers_sr1.createOrReplaceTempView("customers")
val customers_sr2 = spark.sql(
"""SELECT *, ST_Point(cast(lon as decimal(10,4)), cast(lat as decimal(10,4))) AS geom_point
FROM customers
""".stripMargin)
customers_sr2.createOrReplaceTempView("customers_points")
val stadium_polygon = stadiums_poly.filter($"name_en" === stadium)
stadium_polygon.createOrReplaceTempView("stadium_polygon")
val stadium_centroid = spark.sql("""select ST_Transform(ST_Centroid(geom_polygon),'epsg:4326','epsg:32637') as stadium_centroid
from stadium_polygon""".stripMargin)
stadium_centroid.createOrReplaceTempView("stadium_centroid")
val stadium_buffer = spark.sql("select *, ST_Buffer(stadium_centroid,150) AS buffer_150 FROM stadium_centroid")
stadium_buffer.createOrReplaceTempView("stadium_buffer")
val customers_sr3 = spark.sql(
"""SELECT customers_points.customer_id, customers_points.start_time, customers_points.end_time, customers_points.interval_duration
FROM customers_points, stadium_buffer
WHERE ST_Intersects(ST_Transform(customers_points.geom_point,'epsg:4326','epsg:32637'), stadium_buffer.buffer_150)
""".stripMargin)
val customers_sr4 = customers_sr3.withColumn("game_start", lit(game_start)).
withColumn("game_end", lit(game_end)).
withColumn("game_id", lit(game_id)).
withColumn("stadium", lit(stadium)).
withColumn("game_duration",
when($"start_time" < $"game_start" && $"end_time" > $"game_start", unix_timestamp($"end_time")-unix_timestamp($"game_start")).
when($"start_time" > $"game_start" && $"end_time" < $"game_end", unix_timestamp($"end_time")-unix_timestamp($"start_time")).
when($"start_time" > $"game_start" && $"start_time" < $"game_end" && $"end_time" > $"game_end", unix_timestamp($"game_end")-unix_timestamp($"start_time")).
when($"start_time" < $"game_start" && $"end_time" > $"game_end", unix_timestamp($"game_end")-unix_timestamp($"game_start")).
otherwise(lit(0))).
select($"customer_id", $"stadium", $"start_time", $"end_time", $"game_start", $"game_duration", $"game_id").
filter($"game_duration" > 20)
customers = customers.union(customers_sr4.toDF)
}
Сопоставление данных с фактическими
Для верификации полученных данных мы сопоставили их с данными по фактической посещаемости, опубликованными на официальном сайте КХЛ для каждого хоккейного матча.
Например, для матчей, состоявшихся на арене ЦСКА, у нас получился следующий график:

Сопоставление фактической посещаемости хоккейных матчей на арене ЦСКА с рассчитанной на основе событий абонентов. Коэффициент корреляции двух метрик равен 0,96
Сопоставляя количество посещений по каждой арене отдельно, мы получили довольно высокие коэффициенты корреляции между рассчитанными и фактическими данными для арен ЦСКА и ВТБ Арены (0,96 и 0,95 соответственно) и относительно низкий для арены «Мегаспорт» (0,66).
Причиной низкой корреляции были абоненты, которые, скорее всего, не посещали матчи, но находились в это время вблизи стадиона. На карте видно, что рядом со стадионом расположен жилой комплекс.

ЖК «Лица» расположен вплотную к арене «Мегаспорт». Часть жителей определяются как посетители матчей
Поскольку чаще всего матчи проводятся в вечернее время, то возвращающиеся домой жители этого ЖК определились у нас как посетители хоккейных матчей Спартака.
Анализируя распределение количества абонентов по количеству посещенных матчей, мы обнаружили, что некоторые абоненты посетили все 28 матчей каждой команды. Это могут быть как и самые настоящие фанаты хоккея, так и члены команд, а также обслуживающий персонал арен.
Для последующего анализа мы отфильтровали абонентов, которые посетили не более 5 матчей одной команды, они составили 95% от всего количества абонентов.
После применения фильтра мы еще раз рассчитали коэффициенты корреляции для каждой арены: для ЦСКА и ВТБ Арены мы получили те же значения (0,96 и 0,95 соответственно), для арены «Мегаспорт» коэффициент повысился до 0,79.

Сопоставление рассчитанной по событиям абонентов посещаемости хоккейных матчей на арене «Мегаспорт» до и после применения фильтра по количеству посещенных матчей
Где живут болельщики
Сопоставляя рассчитанные данные посетителей хоккейных матчей с данными о домашних локациях абонентов (где абоненты провели большую часть времени с 23 до 6 часов в течение месяца), мы определили районы, где вероятнее всего проживают фанаты хоккейных команды Москвы.
Для начала мы определили, из каких районов москвичи чаще всего посещают хоккейные матчи (всех трех команд). Мы просуммировали все визиты на трех аренах для 84 состоявшихся игр.
Сравнивая между собой районы Москвы с разной численностью населения, более корректно будет использовать относительный показатель. Мы использовали количество визитов на хоккейные матчи на 1 тысячу проживающих в данном районе. Стоит добавить, что в расчетах мы учитывали только наших абонентов.

Посещаемость хоккейных матчей жителями районов Москвы и прилегающих к Москве районов Московской области
На карте темным цветом отмечены районы, жители которых чаще всего посещают хоккейные матчи на аренах Москвы. Среди них выделяются районы, где расположены арены (Хорошевский, Аэропорт и Даниловский), а также Савеловский, Беговой, Сокол, Левобережный, Войковский, Хорошево-Мневники.
Часто посещают матчи жители районов, прилегающих к ним. Редко посещают матчи жители восточных районов города.
Где живут фанаты ЦСКА, Спартака и Динамо М
Мы составили аналогичные карты для болельщиков трех московских хоккейных команд. Для них мы учитывали не все визиты, а уникальных абонентов, которые посетили матчи на соответствующих аренах.
Для отображения на картах использован относительный показатель — доля болельщиков команды на 1 тысячу проживающих.
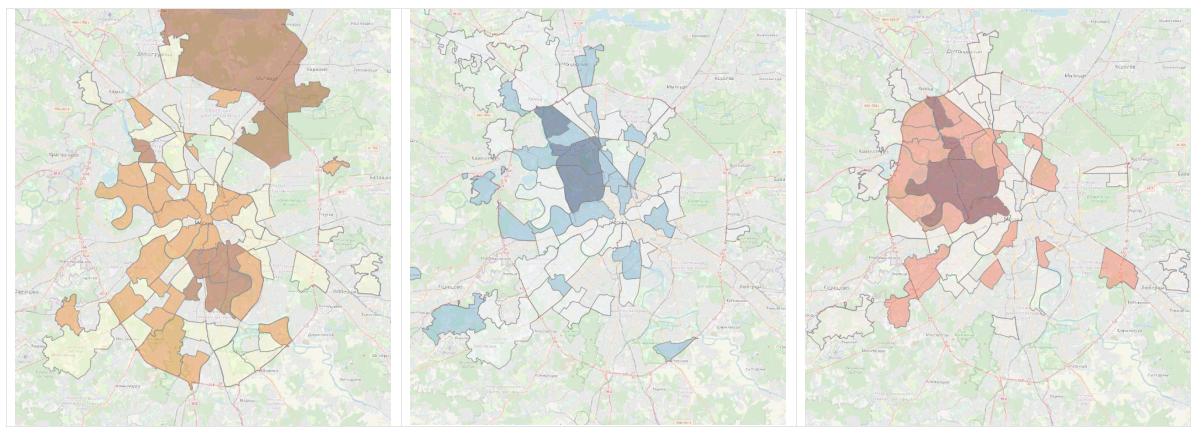
Доля болельщиков хоккейных клубов Москвы по районам слева-направо — ЦСКА, Динамо М, Спартак
Для всех клубов характерно проживание болельщиков вблизи их домашних арен и в прилегающих районах.
Среди районов, где наиболее высокая доля болельщиков ЦСКА, Даниловский, Котловка, Южнопортовый, подмосковные Мытищи, Нагатино-Садовники и Донской.
Доля болельщиков Динамо М высока в районах Савеловский, Аэропорт, Беговой, Левобережный, Хорошевский и Войковский.
В районах Хорошевский, Беговой, Сокол, Аэропорт, Савеловский и Хорошево-Мневники высокая доля болельщиков ХК Спартак.
Сравнивая количество болельщиков по районам в абсолютных значениях, можно выделить районы, где преобладают фанаты определенной команды. По нашим расчетам все районы разделились в основном на болельщиков Динамо М и Спартака.

Преобладание количества болельщиков хоккейных клубов Москвы по районам Московской агломерации. Желтым цветом показаны районы, где преобладают болельщики ЦСКА, красным — Спартак, синим — Динамо М
Болельщики ЦСКА преобладают только в нескольких районах — Даниловский, Донской и Мытищи.

Преобладание количества болельщиков хоккейных клубов Москвы по районам Московской агломерации. Желтым цветом показаны районы, где преобладают болельщики ЦСКА, красным — Спартак, синим Динамо М
Вместо заключения
Мы рассмотрели лишь несколько инструментов для работы с большими пространственными данными на основе библиотек Apache Sedona, но в то же время — наиболее часто применимые при решении регулярных задач на проектах.
