Как запихать нейронку в кофеварку
Мир машинного обучения продолжает стремительно развиваться. Всего за год технология может стать мейнстримом, и разительно измениться, придя в повседневность.
За прошедший год-полтора, одной из таких технологий, стали фреймворки выполнения моделей машинного обучения. Не то, что их не было. Но, за этот год, те которые были — стали сильно проще, удобнее, мощнее.
В статье я попробую осветить всё что повылезало за последнее время. Чтобы вы, решив использовать нейронную сеть в очередном калькуляторе, знали куда смотреть.
Перед началом статьи нужно сразу сказать несколько дисклеймеров:
- Мой обзор будет со стороны ComputerVision. Не стоит забывать что ML это не только CV. Это ещё классические алгоритмы бустинга, это различный NLP (от трансформеров до синтеза речи). И далеко не все задачи ML можно будет исполнять на тех фреймворках про которые я буду говорить.
- Из обозначенных технологий я сам работал где-то с третью. Про остальные читал/минимально щупал/общался с людьми которые интегрировали. Отсюда могут возникнуть какие-то ошибки в статье. Если вы видите что-то что вас покоробило/с чем вы не согласны — пишите в комментариях/в личку — попробую поправить.
- Мир стремительно меняется. Я пробую верифицировать то что пишу на момент выхода статьи. Но не факт что даже существующая документация соответствует истинному положению дел. Не говоря уже о том, что в ближайшие пару недель любой из указанных фреймворков может катастрофически измениться. Если вдруг такие апдейты вам будут интересны — то скорее всего я буду разбирать их в своём блоге CVML (он же в телеге), где я такую мелочь пишу. Тут буду стараться оставлять ссылки на разбор.
Для тех кому лень читать — записал видео с содержимым статьи:
Начнём.
Часть 1. «Что такое инференс»
Мир нейронных сетей можно разбить на две части:
- обучение
- использование
Обучение сложнее. Оно требует больше математики, возможность анализировать какие-то параметры по ходу. Нормой является подключение к TensorBoard и прочим инструментам мониторинга. Нужны простые способы интеграции новых слоёв, быстрота модификации.
Чаще всего для обучения используются Nvidia GPU (да, есть TPU от Google, или Intel Xe, но скорее это редкость). Так что софт для обучения должен хорошо поддерживать одну платформу.
Нужно ли обучение при использовании нейронной сети в проде? Очень редко. Да, у нас было несколько проектов с автоматическим дообучением. Но лучше этого избегать. Это сложно и нестабильно.
Да и если нужно, то проще утащить на внешний сервак и там дообучить.
Как следствие — можно отбросить 90% математики и обвеса, использовать только выполнение. Это и называется «инференс». Он быстрее, чем обучение. Требует сильно меньше математики.
Но вот засада. Не тащить же для инференса GPU. Инференс может быть и на десктопах, и на мобильниках, и на серверах, и в браузере.
В чём его сложность?
Нейронные сети едят много производительности — нужно либо специальное железо и его поддержка, либо максимальная утилизация существующего, чтобы хоть как-то достать производительность.
А железо очень-очень разное. Например в телефонах Android может существовать с десяток различных вычислителей, каждый из которых имеет свою архитектуру. А значит ваш модуль должен быть универсален для большинства.
Часть 2. Железо.
Железо в ML бывает очень разное. Его хотя бы примерное описание на текущий момент будет требовать десятка статей. Могу вам посоветовать очень крутую статью от 3Dvideo про технологии аппаратного ускорения нейронных сетей. И свою статью про то как устроены embedding системы в последнее время.
И то и то уже немного неактуально, ведь всё быстро-быстро меняется;)
Для упрощения понимания статьи, или для тех кто не хочет углубляться я накидал упрощённую схему которой мы будем оперировать (кликабельно): 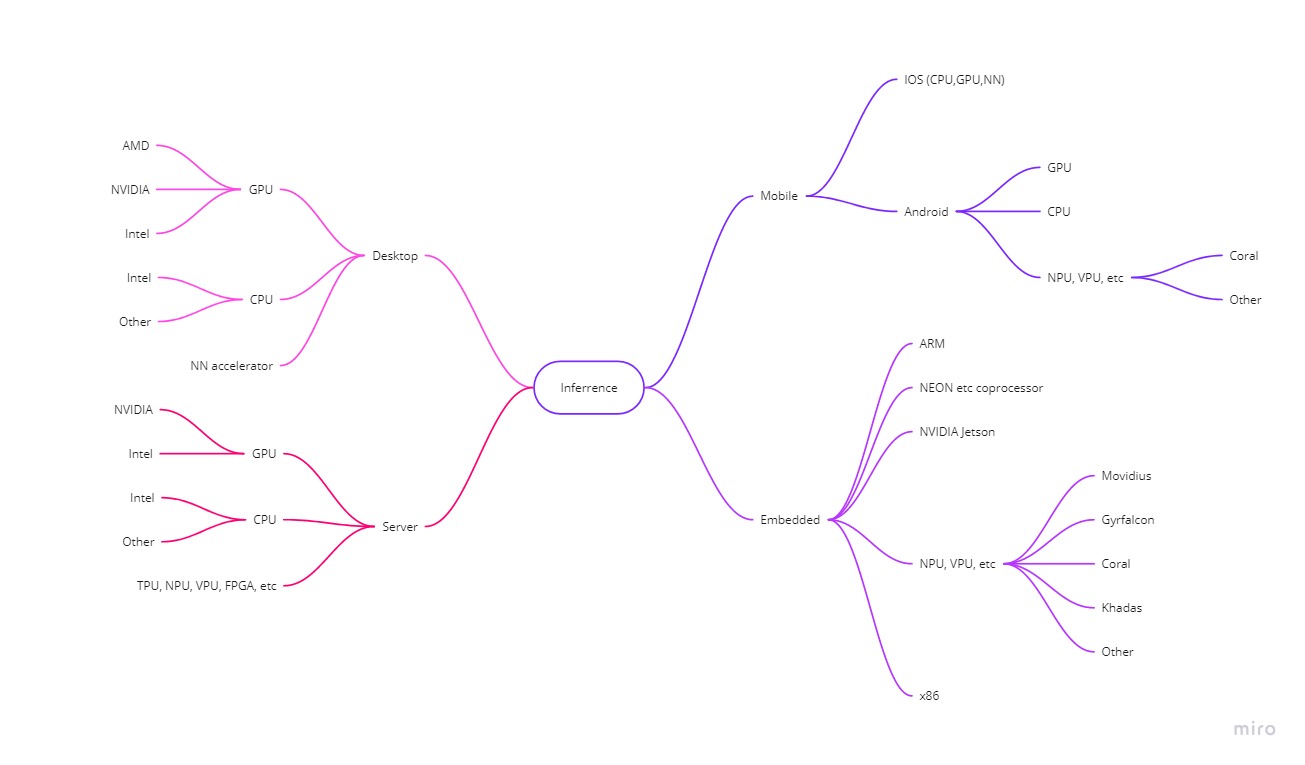
Тут мы видим несколько направлений инференса:
- Серверный инференс. Мы не полезем в него глубоко. Обычно когда вам нужно чтобы сеть выполнялась на сверхпроизводительном сервере — редко нужно чтобы данный алгоритм крутился на старой мобилке. Но, тем не менее, тут будет что помянуть
- Десктопный инференс. Это то, что может крутиться у вас на домашнем компе. Обработка фотографий. Анализ видео, компы которые ставятся на предприятия, и прочее и прочее будет именно здесь.
- Мобильный инференс — всё что касается телефонов, Android и Ios. Тут огромное поле. Есть GPU, есть специальные ускорители, есть сопроцессоры, и прочее и прочее.
- Embedded. Частично эта часть пересекается с десктопами, а частично с мобильными решениями. Но я вынес её в отдельную ветку, так как часть ускорителей ни на что не похожи.
Основная проблема видна уже тут. Большинство конечных точек требуют свою систему инференса. Если вы хотите универсальную систему выполнения нейронной сети которая будет использовать 100% мощности, тогда вам нужно иметь модуль для каждой конечной точки этого дерева.
Есть фреймворки которые теряют в разветвленности, но неплохо работают там где работают. Есть которые используют максимально популярные устройства, но не работают на других. Опять же, если показать это ооочень примерно, то выйдет как-то так: 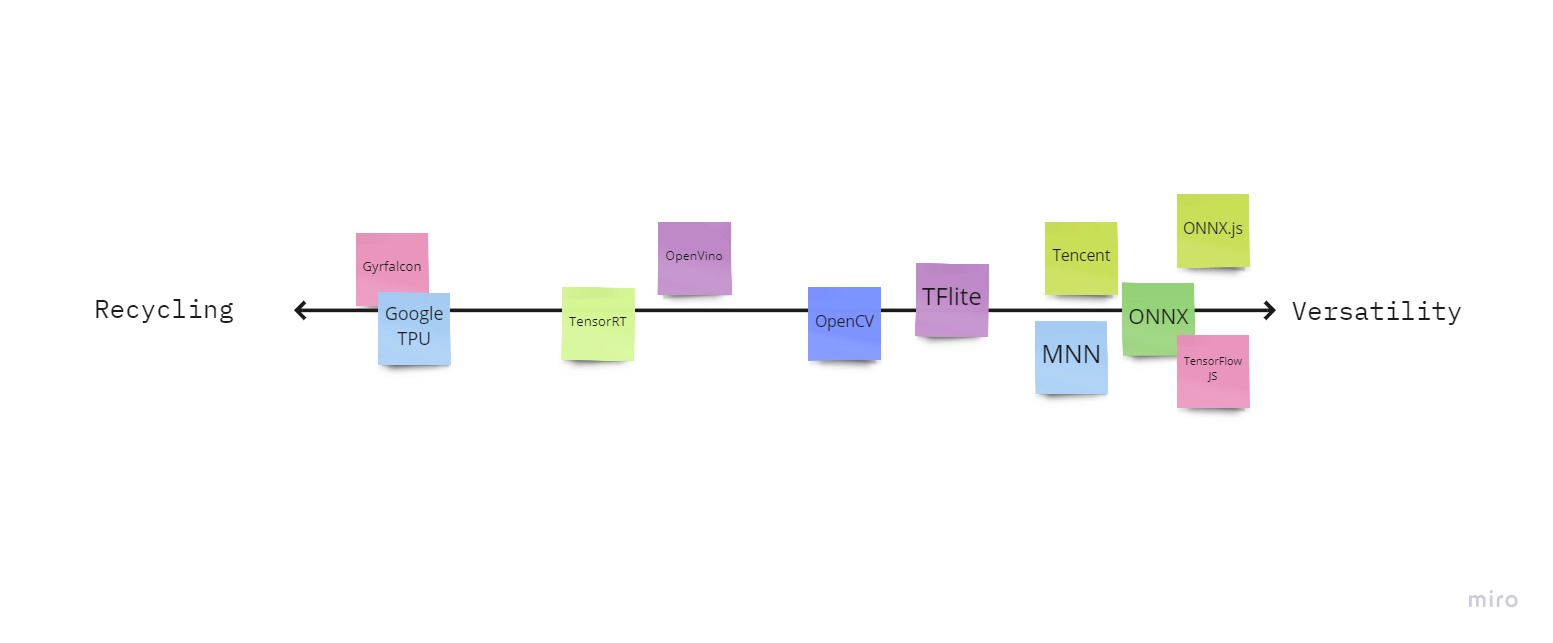
Поговорим подробнее, скорее слева на право.
Специализированное железо: Gyrfalcon, Khadas, Hikvision, и.т.д.
Всё это добро я решил выделить в одну группу. Фреймворком это назвать сложно. Обычно это специализированный софт который может перенести нейронку на железо, чтобы она выполнялась там оптимально. При этом железяка у производителей зачастую одна или две.
Отличительной особенностью таких платформ является:
- Не все слои поддерживаются
- Софт часто не выложен в OpenSource. Поставляется вместе с аппаратной частью или требует подписания дополнительного NDA
Из-за отсутствия публичности работа с такими фреймворками это обычно боль. Но да, есть ситуации когда такое решение это единственный выход, и приходится осваивать.
Более подробно рассказывать про эту часть наверное нет смысла.
Специализированное железо, но от крупных фирм
Крупные производители железа обычно имеют много разного железа, но всё оно программируется в рамках одного фреймворка. Это открытые фреймворки, которые можно спокойно скачать и использовать.
Они позволяют портировать нейронку и использовать её максимально эффективно.
В большинстве случаев поддерживаются все современные архитектуры, а если не поддерживаются, то есть другие способы их использовать или добавить.
Поговорим про них подробнее:
Nvidia — TensorRT
Наверное это самая классика, и не надо рассказывать почему. Больше 90% ресёрча использует именно видюхи NVIDIA. Инференс часто на них же => все стараются выжать максимум, а для этого нужны TensorRT — специальный фреймворк который максимально утилизирует мощь видеокарты для нейронных сетей.
Более того, если вы пишите на CUDA — то можете в рамках одного обработчика обрабатывать данные. Самый классический пример — NMS. Например, когда-то давно мы переписывали кусок одного детектора поз на CUDA чтобы не гонять данные на процессор. И это очень ускоряло его работу.
Нужно понимать, что NVIDIA целит в три области, и везде TensorRT используется:
- Серверные платформы (Tesla)
- Десктопы (видеокарты обычные и полу специализированные)
- Embedded платформы — серии Jetson.
Плюс TensorRT в том, что он достаточно стандартен. Он есть в TensorFlow (tf-trt), есть в OpenCV. Основной минус для меня — под Windows нет поддержки в Python, только через сторонние проекты. А я люблю иногда что-то под виндой потыкать.
Мне кажется, что если вы делаете инференс на Nvidia, то у вас просто нет альтернатив — надо использовать TensorRT. Всё остальное приведёт к падению производительности.
Triton Inference Server
Но, так как мы говорим про инференс, то нужно упомянуть Triton Inference Server (github.com/triton-inference-server/server). Это не совсем TensorRT (хотя TensorRT подразумевается как оптимальный для него фреймворк). Triton может использовать TensorFlow, PyTorch, Caffe. Он сам ограничивает память и настраивает любой из упомянутых фреймворков, управляя выполняющимися сетями.
Triton сам решает какие модели загружать-выгружать из памяти, сам решает какой batch использовать. Может использовать не только TensorRT модели, но и модели *.pd, *.pth, ONNX, и.т.д., (ведь далеко не все можно сконвертировать в tensorrt). Triton может раскладывать по нескольким GPU. И прочее и прочее.
Мы использовали его в продакшне в нескольких проектах — и остались ужасно довольны. Максимальная утилизация GPU с минимумом проблем.
Но… Он не сможет выполнить модель где-то за пределами Nvidia
Intel — OpenVino
Intel представлен на рынке:
- Серверных вычислителей (Intel FPGA, Xe GPU, Xeon)
- Десктопов (с i3 начиная года с 2015 поддерживается почти всё). Intel GPU — работает, но не сверх круто.
- Embedded платформ (movidius)
И для всего можно сварить модель через OpenVino.
Мне нравиться OpenVino так как он достаточно стабилен, прост, и имеет инференс почти везде. Я писал на Хабре статью в которой рассказывал опыт одного хоббийного проекта под Intel. Там я отлаживал на десктопах, а тестировал на RPi с мовидиусом. И все было норм.
В целом, все 2–3 проекта которые мы делали в своей практике под OpenVino, прошли примерно так же. Минимум сложностей, удобный инференс, заказчик доволен.
Open Vino интегрирован в OpenCV про который мы ещё поговорим. OpenCV тоже от Intel, но я бы рассматривал его как отдельный фреймворк/способ инференса и подхода к данным.
Отдельно я бы хотел отметить один забавный момент. Аренда GPU сервера для того чтобы развернуть модель в онлайне будет стоить где-то от 10к. рублей, где-то до 100к. рублей, в зависимости от используемых видюх.
Аренда сервака с I5 на каком-нибудь клауде зачастую возможна за 500–1000 рублей в месяц.
Разница в производительности между TensorRT и ONNX на сравнимых по цене процах может быть в 2–20 раз (зависит от сети). Как следствие — часто можно неплохо сэкономить перенеся онлайн инференс на ONNX.
Google — Edge
Google очень неоднозначная фирма сама по себе. Мало того, что Google имеет свой стек аппаратуры для инференса нейронных сетей. Ещё у Google целый стек различных фреймворков про которые мы поговорим позже. Запутанный и местами бажный. Но в целом это:
- TensorFlow Edge
- TensorFlow lite
- TensorFlow JS
- TensorFlow (чистый, или оптимизированный под какую-то платформу, например Intel TensorFlow)
В этой части мы говорим именно про отдельную ветку Edge (coral.ai). Она используется в Embedded продуктах, и в некоторых mobile продуктах.
Минусом Edge является то, что из коробки поддерживаются не все модели, гарантирована поддержка лишь нескольких (coral.ai/models). А конвертация достаточно усложнена (TF → TF Lite → Edge TPU): 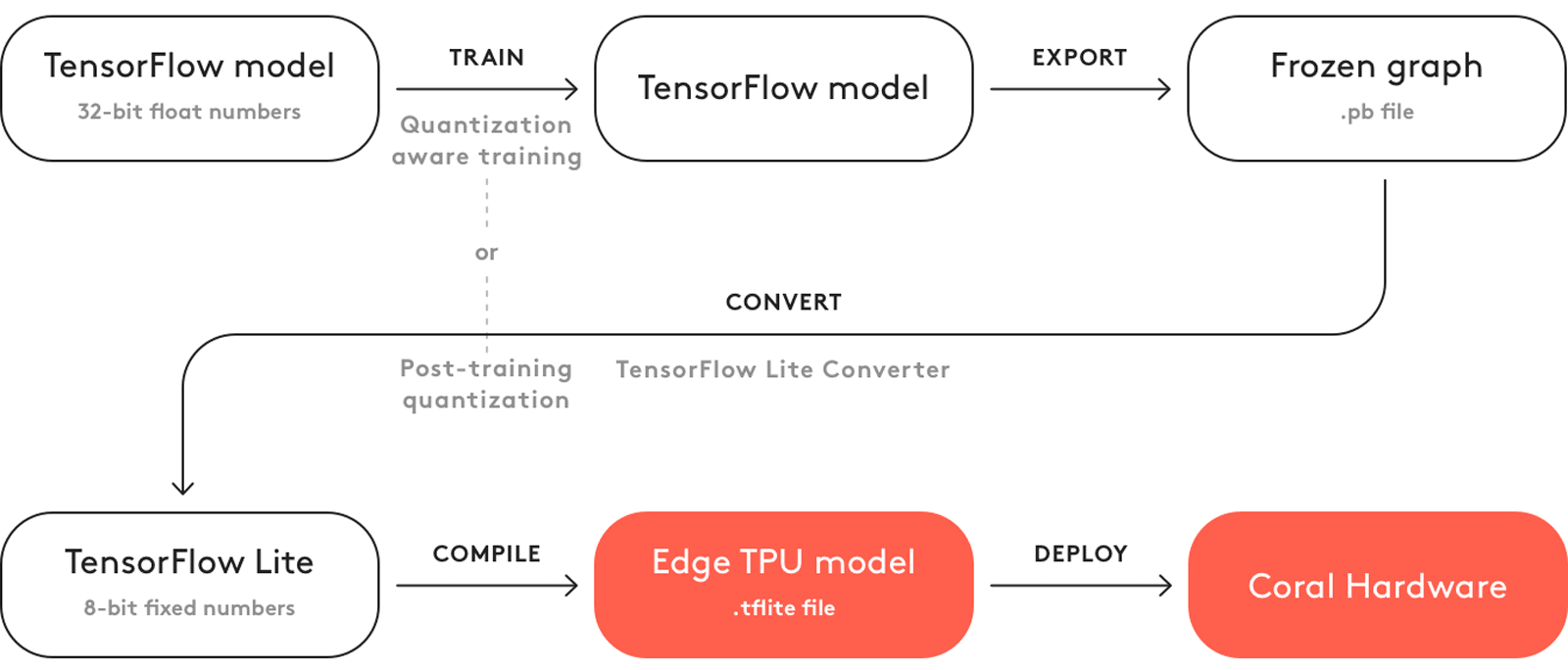
Конвертация в Cloud TPU чуть проще, но и там есть свои особенности.
Я не буду более подробно рассказывать про особенности этого фреймворка. Скажу лишь что каждый раз когда с ним сталкивался — оставались неприятные впечатления, так что не стали тащить его нигде в прод.
Универсализация с хорошей аппаратной поддержкой
Мы переходим в область подходов, которые достаточно оптимально используют железо, но будут требовать немного разный код на разных платформах (нельзя же на Android всё сделать на Python).
Тут я бы упорядочил как-то так (опять же, очень условно): 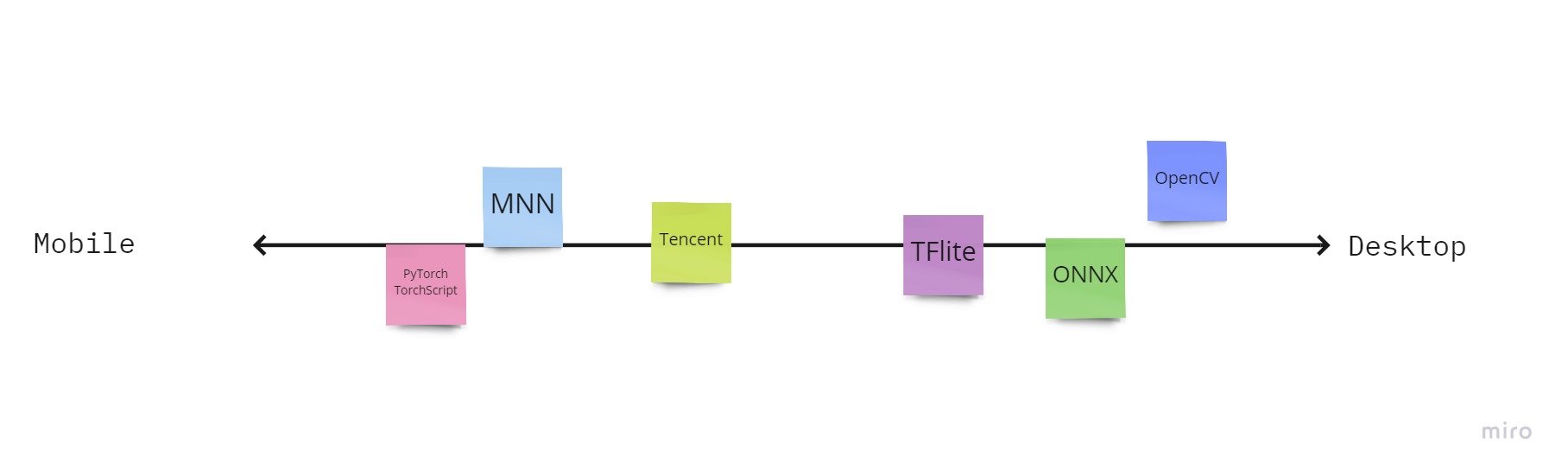
Пройдем по этому списку
OpenCV
OpenCV это легендарный фреймворк ComputerVision появившийся более 15 лет назад. За свои 12 лет занятий ComputerVision я запускал его на Arm году в 2010, на BlackFin примерно тогда же, на мобильниках, на серверах, на RPi, на Jetson, и много-много где. У него есть классные биндинги на Python, Java, JavaScript, когда-то я вовсю использовал его на C#.
OpenCV более чем живой и сейчас. И нейронные сети активно просачиваются туда с самого их появления.
Мне кажется, что на сегодня у OpenCV есть несколько глобальных минусов:
- Очень мало актуальной документации. Попробуйте найти где-нибудь гайд по всем бекендам модуля DNN в OpenCV и по поддержке их на всех платформах?:) Конечно, можно изучить хедеры, но это не говорит о том что где будет работать. Порог входа и первого прототипа достаточно высок. Не в пример того же OpenVino.
- Нейронные сети под Android поддерживаются (docs.opencv.org/master/d0/d6c/tutorial_dnn_android.html). Но я не находил актуального гайда про аппаратную поддержку GPU или других вычислителей.
Тут кажется, что всё грустно. Но! Стоит поставить «НО» даже большими буквами. Главный плюс OpenCV — очень хорошая поддержка CUDA и OpenVINO. Судя по всему запланирована и поддержка любых OpenCL устройств, но пока информации мало.
По нашим тестам в OpenCV нейронные сети на CUDA выполняются медленнее чем в TensorRT всего на 5–10%, что отлично.
Это делает OpenCV весьма ценным фреймворком для серверных решений, где нужно выжимать максимум из имеющегося ускорителя, какой бы он не был.
Так же OpenCV очень неплохо поддерживает различные CPU на ARM-устройствах. На том же RPi он использует NEON.
Tensorflow lite
Чуть ближе к мобильному миру лежит TensorFlow lite. Он может исполнять нейронные сети как и на обычном GPU мобильного устройства, так и на возможных сопроцессорах, если производитель телефона соблюдает какой-то набор стандартов. Для мобильников возможные варианты выглядят примерно так: 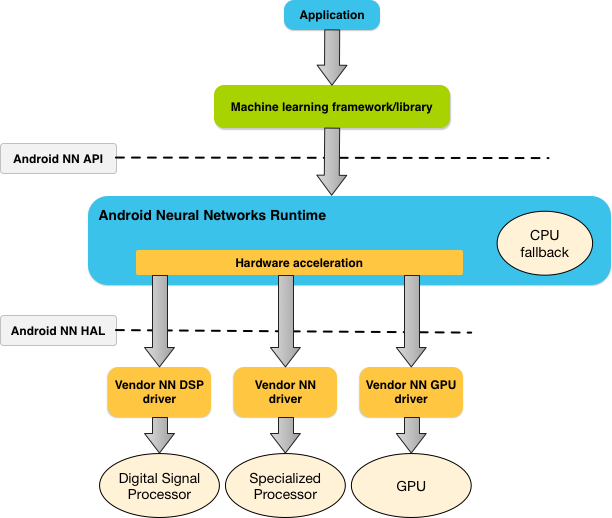
В большинстве случаев вы автоматически можете проверить максимальный уровень ускорения и запустить именно на нём. Детальной карты того какие вендоры предоставляют какую поддержку железа я не нашёл. Но я видел несколько примеров которые начались поддерживаться. Например под Snapdragon мы когда-то портировали сети, а потом TFLite начал его поддерживать.
Чуть более подробно о том что насколько даёт прирост можно посмотреть, например, тут — ai-benchmark.com/ranking_detailed
Так же, стоит упомянуть, что изначально поддержка GPU шла за счёт OpenGL, но в последнее время Google добавила и OpenCL, чем почти в 2 раза ускорила выполнение сетей.
Но прелесть TFlite не только в том что он работает под мобильниками. Он ещё достаточно неплох для части embedded устройств. Например, он достаточно эффективно работает под RaspberryPI.
На последнем DataFest ребята из X5 рассказывали что они используют эту конструкцию в продакшне.
Так же, TFlite, за счёт XNNPACK неплохо работает на процессорах (но не так эффективно как OpenVino на Intel). Это даёт возможность использовать TFLite как способ инферить модели на десктопах. Хоть и без поддержки GPU. Зато без тонны лишних зависимостей.
ONNX runtime
В какой-то момент в гонку ворвался Microsoft, который решил зайти со стороны. Сначала они выпустили универсальный формат сохранения нейронных сетей, который сейчас достаточно популярен, — ONNX.
И, когда уже форматом многие начали пользоваться, — решили сделать свой рантайм для него.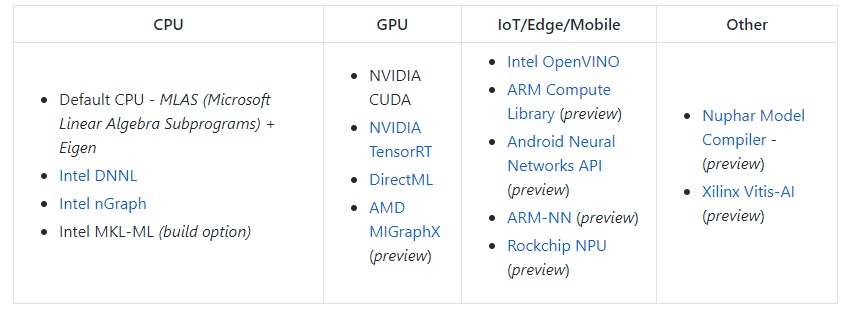
Если честно, то я даже не знаю половину того что представлено в списке…:)
Выглядит всё идеально (а ещё всё поддерживается на Python, Java, C, C++, C# и.т.д.)…
Но пока что мне не довелось использовать ONNX-runtime на практике, кроме ONNX.js, о котором будет ниже. Так что не могу гарантировать что всё работает идеально. В интернетах слишком мало примеров того как всё работает. И знакомых которые бы на этом разворачивали продакшн полноценный тоже не знаю (максимум тестировали, но не решили развернуть).
Но в гайдах уверяется что даже для Raspberry PI и Jetson есть поддержка.
Про поддержку ios явно ничего не сказано. Но местами «ios» встречается по коду. А кто-то билдит.
PyTorch
Одна из проблем использования OpenCV, TFlite, ONNX Runtime: «А почему мне надо обучать в одном фреймворке, а использовать в другом?». И авторы PyTorch тоже задают себе такой вопрос. Так что, прямо из коробки, предоставляют способ использования PyTorch на мобильниках: 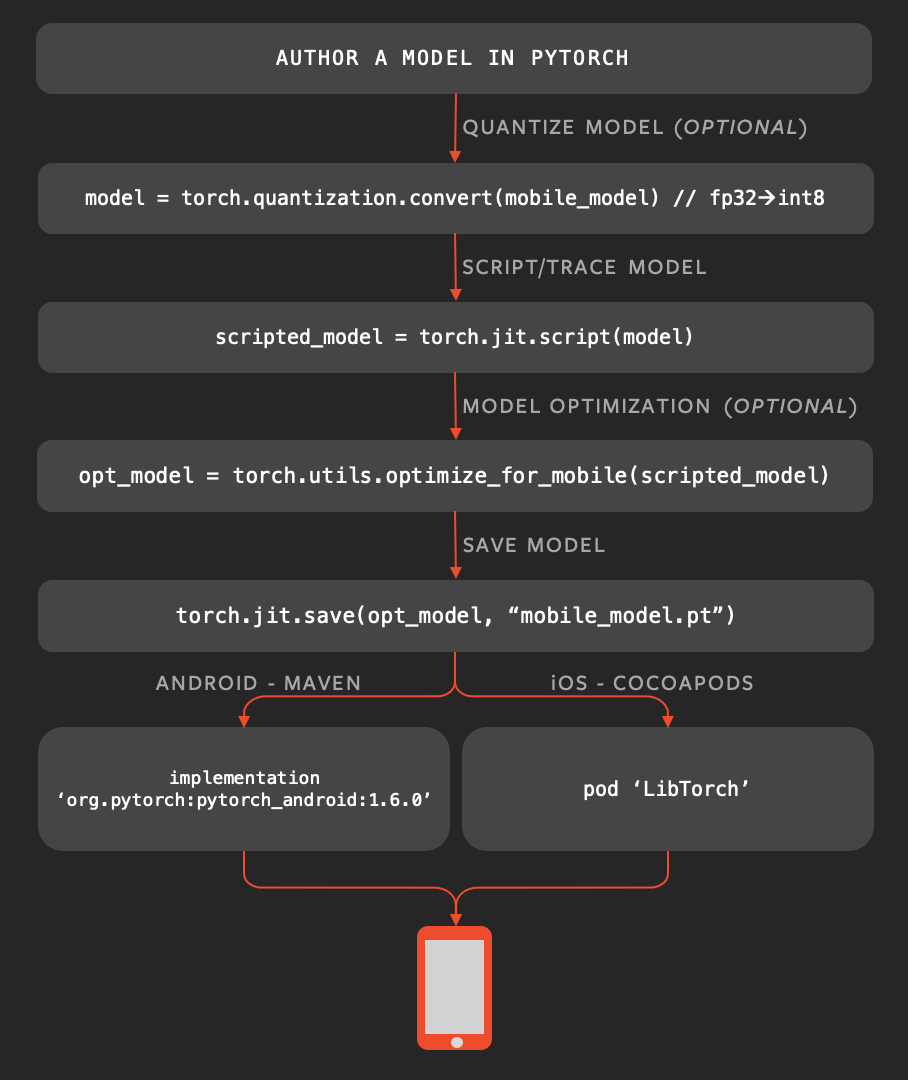
Скажу честно, я не тестировал скорости инференса. Но по опросу знакомых — в целом все считают это медленным вариантом. По крайней мере инференс PyTorch на процессорах и GPU — тоже не самый быстрый. Хотя, опять же, XNNPACK используют.
Но, данный вариант вполне удобен для разработки и пуша в продакшн (нет лишних конвертаций, и.т.д.). Мне кажется, что иногда это хороший вариант (например когда нет требований на очень высокую производительность).
TensorFlow
Кроме использования TFlite можно использовать и оригинальный TF, для развертывания на embedded устройствах и десктопах. При этом TF имеет достаточно высокую степень конфигурируемости. Но, на мой взгляд, это достаточно мертвый вариант в будущем.
Китайское вторжение
Теперь мы переходим к двум вариантам, которые не тестировал почти никто из моих знакомых. Но которые выглядят весьма перспективно.
Первый из них — MNN, вариант от alibaba. 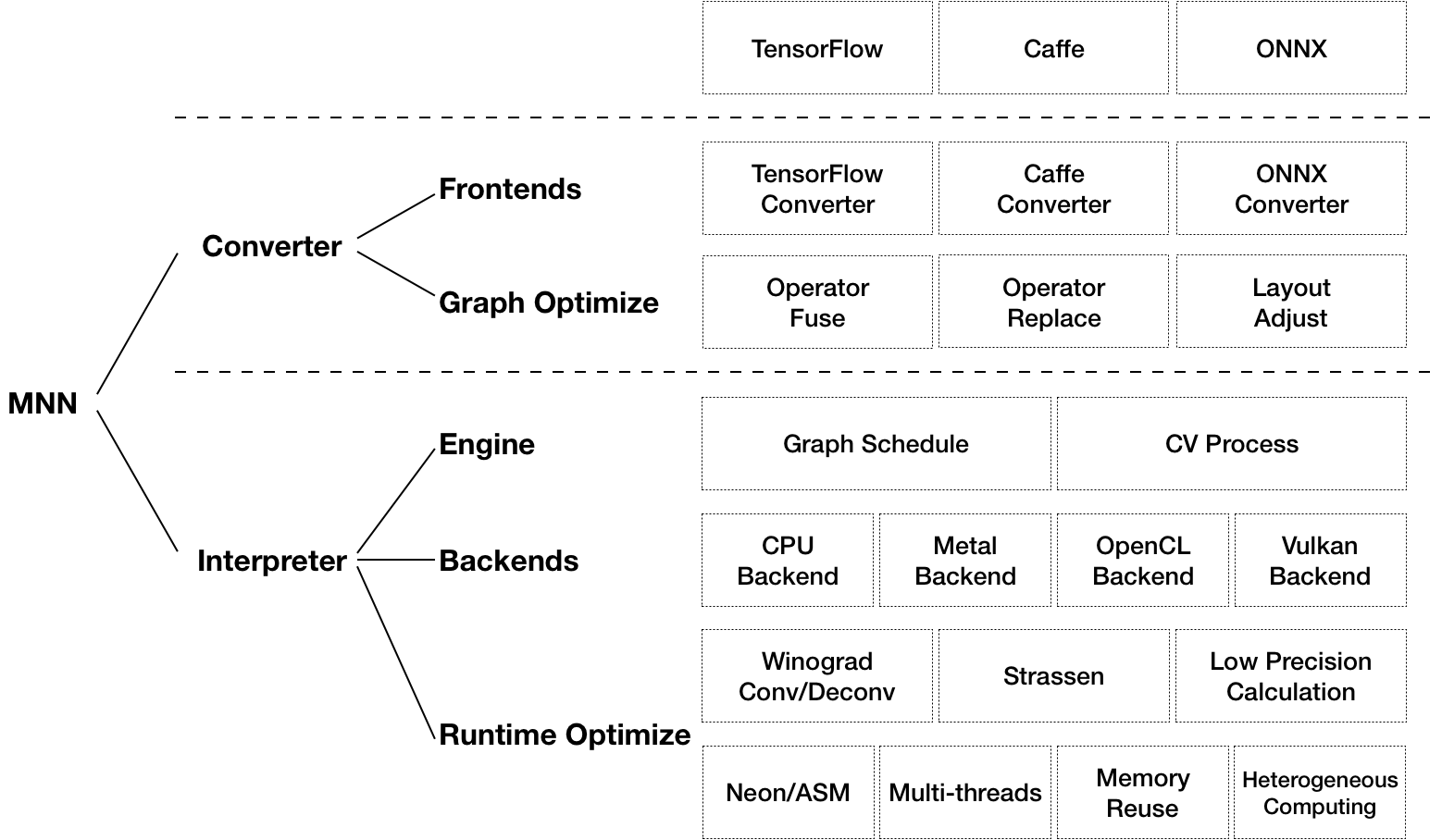
Авторы уверяют, что MNN — самый легковесный из фреймворков, который обеспечивает инференс на большом числе устройств, при использовании GPU или CPU. При этом поддерживает большой спектр моделей.
Второй вариант интереснее, это ncnn от Tencent. Согласно документации библиотека работает на большом числе устройств. Реализована на c++: 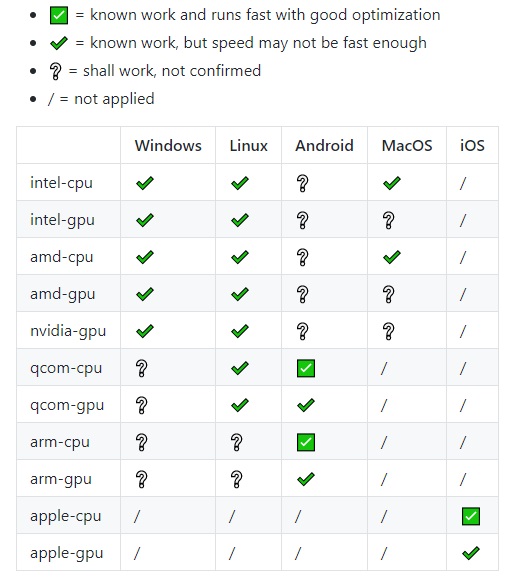
На неё даже Yolov4 спортировано. И в целом, AlexeyAB очень позитивно отзывался.
Но, опять же, у меня достаточно мало информации о практическом применении. Сам не использовал, в проектах которые видел/консультировал — никто не использовал.
При этом можно отметить, что не так много нативных решений одновременно поддерживают и телефоны и nvidia.
JS — Tensorflow.JS, ONNX.js
Я бы объединил эти две категории в общий раздел, хотя, конечно, у TensorFlow.js и ONNX.js есть много различий. TensorFlow чуть лучше поддерживает оптимизацию. ONNX чуть быстрее. LSTM не присутствует в ONNX. И прочее и прочее.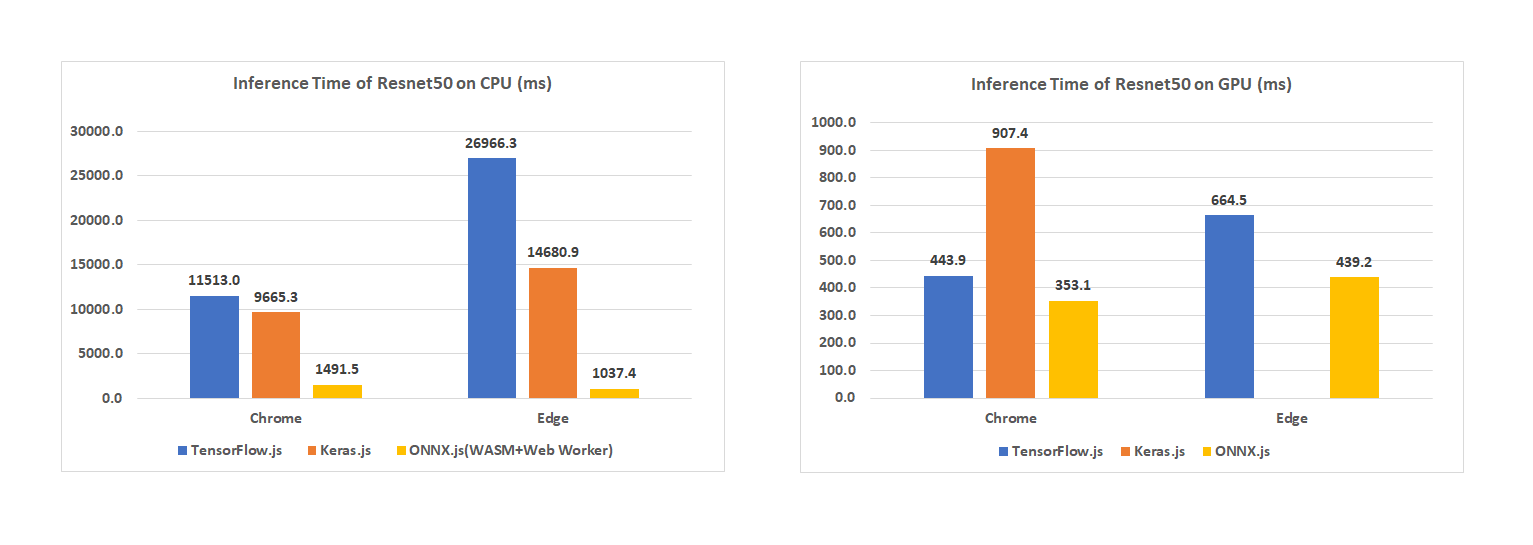
В чем особенность этого класса инференс фреймворков? В том, что они выполняются только на CPU, или на GPU. По сути через WebGL или через WebAssembly. Это наборы инструкций, которые доступны через браузерный JS.
Как плюс — имеем офигенную универсальность такого подхода. Написав один раз код на JS — можно исполнять его на любом устройстве. Если есть GPU — на нём. Если только CPU — на нём.
Основной минус — тоже понятен. Никакой поддержки за пределами CPU или GPU (ускорители/сопроцессоры). Невозможно использовать эффективные способы утилизации CPU и GPU (те же OpenVino или TensorRT).
Правда, под Node.js, TF.js умеет в TPU: 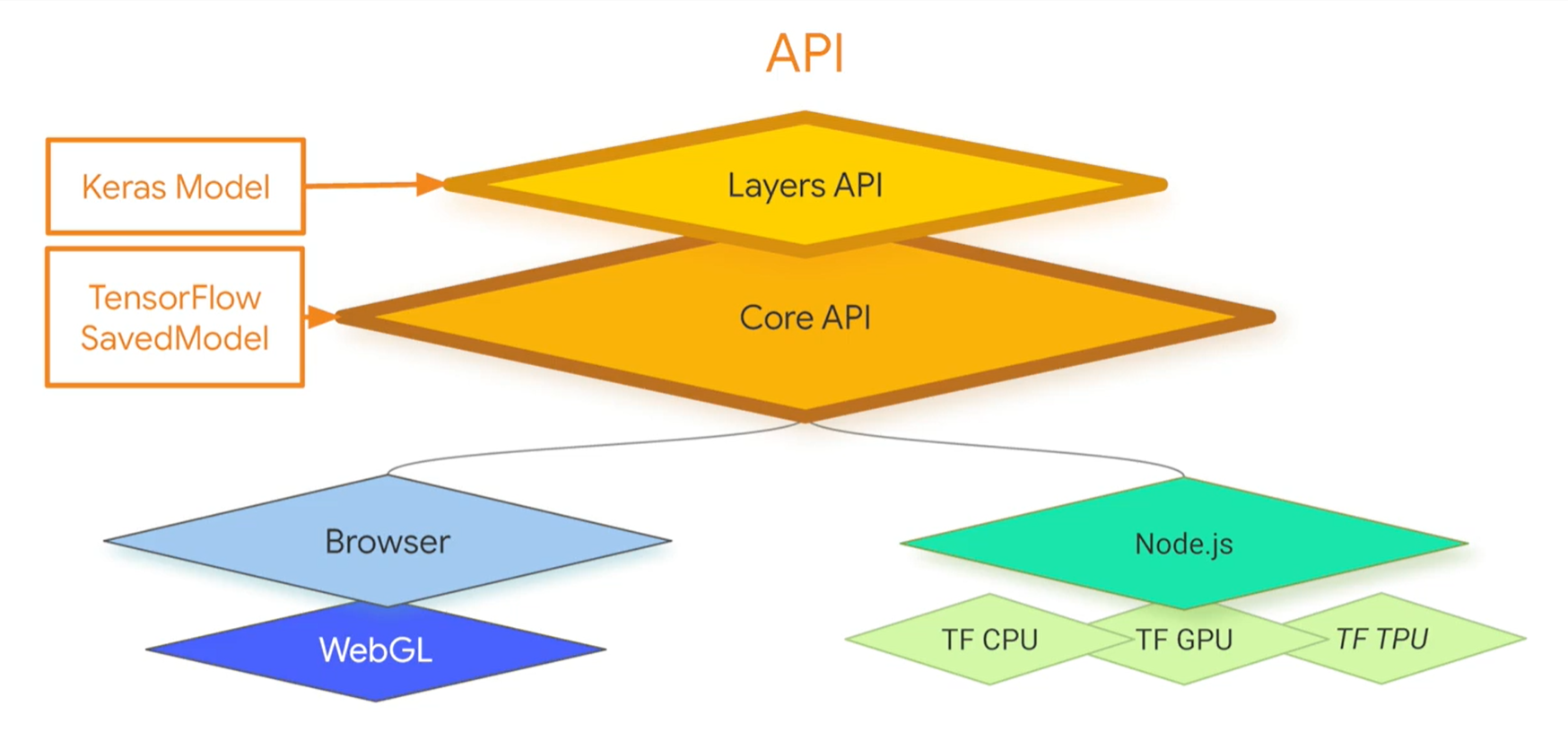
При этом этот вариант явно оптимальный, если вам нужно использовать простые модели, имея кроссплатформенность.
Мы использовали в проектах оба инференса, всё работало хорошо. Но, конечно, производительность немного жалко.
Как небольшое резюме
Выводы сложно делать. Я не смог придумать какого-то однозначного алгоритма который бы помогал выбрать платформу на которой нужно разворачивать ML решение в зависимости от бизнес требований, аппаратуры и сложности сетей.
Как мне кажется:
- Если вам нужно максимально широкое использование на всех платформах, то, похоже, наиболее универсален ONNX runtime. Единственное, он может местами сыроват + ios поддержан весьма просто. Не уверен, что все ускорители одинаково хорошо работают. Вариант — Tencent-ncnn
- Если вам нужно максимум платформ, без мобильных, то я бы взял OpenCV. Он достаточно удобен и стандартен.
- Если вам не нужны десктопные платформы, тогда я бы использовал TFlite
- Если же вы хотите делать на какой-то стандартной платформе, и чётко понимаете что никуда за её пределы не пойдёте — то я бы использовал специализированную платформу под эту платформу. Будь это TensorRT или OpenVino. И на TensorRT и на OpenVino мы разворачивали очень сложные проекты. Непреодолимых проблем не встретили.
В целом (очень условно) как-то так: 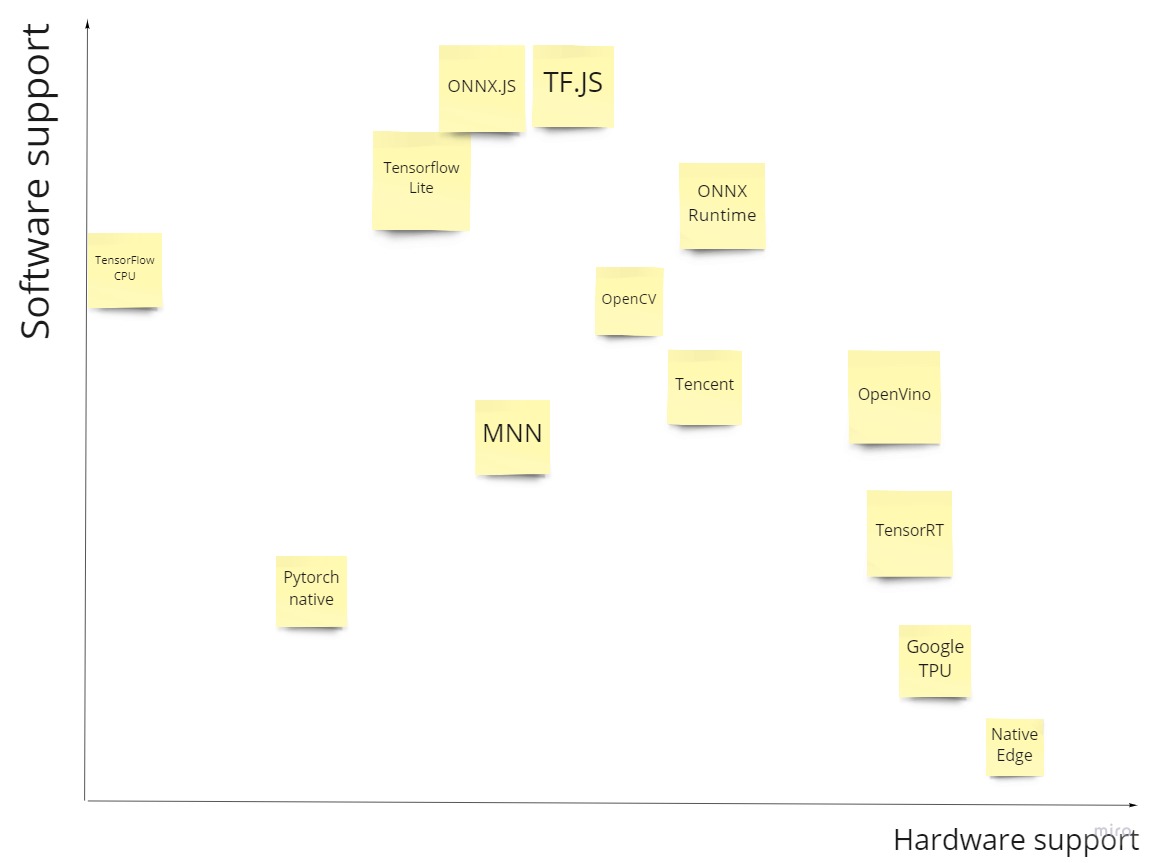
А так… Тема объёмная. Ведь чтобы достаточно подробно рассмотреть TensorFlow lite со всеми плюсами и минусами — надо написать две таких статьи. А для полного обзора OpenCV и десяти не хватит. Но сил написать столько нет.
С другой стороны, я надеюсь, написанное поможет кому-то хоть немного структурировать логику при выборе платформы для инференса.
А если у вас есть и другие идеи как выбирать — пишите!
P.S.
В последнее время делаю много мелких статей/видеороликов. Так как это не формат Хабра — то публикую их в блоге или на ютубе. Подборка всего есть в телеге и вк.
На Хабре обычно публикую, когда рассказ становится уже более самозамкнутым, иногда собрав 2–3 разных мини-рассказа на соседние темы.
