Как заменить Qlik и PowerBI с минимальными потерями: Visiology+Loginom+PostgreSQL

«Что делать, когда ТОПовые BI-системы стали недоступны и перспективы работы с ними оказались сильно ограничены?». Эта дилемма встает сегодня перед многими компаниями. Меня часто спрашивают, можем ли мы взять и перенести уже наработанные практики на другие платформы, доступные в России на сегодняшний день? К счастью, ответ на этот вопрос положительный, и об одном из вариантов его решения я расскажу сегодня.
Конечно, ситуация для всех оказалась неожиданной, и люди начали искать решения. Кто-то остановился на временных методах. Например, некоторые просто теперь пользуются VPN для работы с привычными сервисами, другие — подменяют регионы и пока умудряются зайти в систему. Третьи начали работать с использованием казахстанских юридических лиц (как уже имевшихся, так и созданных только что). Но все это похоже скорее на способ пересидеть бурю. Ведь разве может так выглядеть надежная система, которая лежит в основе каких-либо серьезных корпоративных процессов?

Отдельная категория аналитиков пытается найти аналог PowerBI. Но сегодня стоит расставить точки над i и принять тот факт, что полноценного аналога нет. При попытке провести полную замену инструменты российского BI на сегодняшний день предлагают компромиссы, причем довольно жесткие.
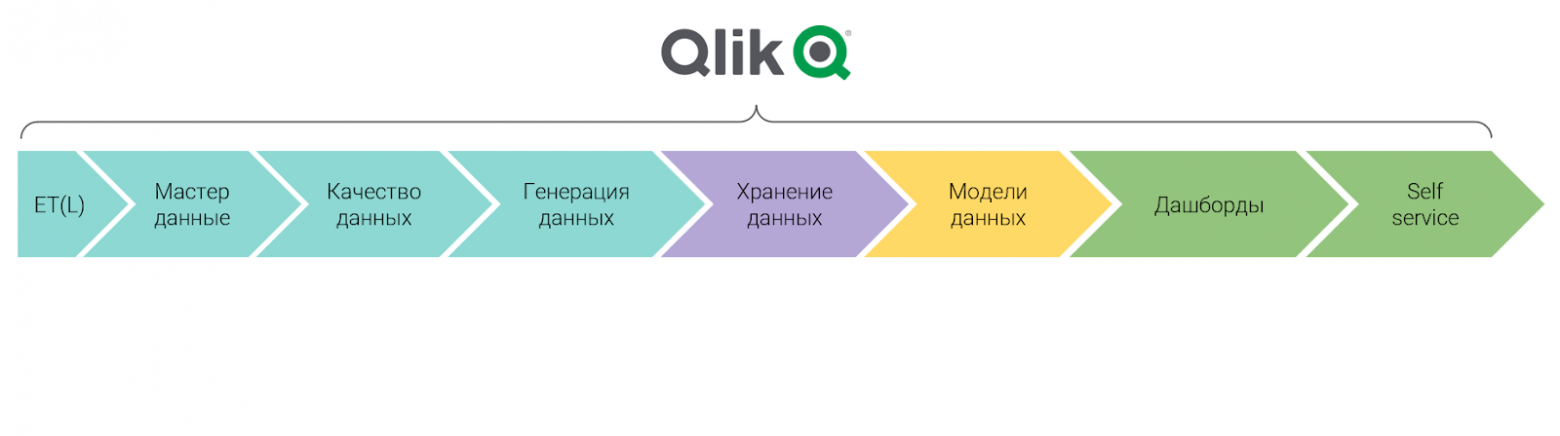
Если посмотреть на эту схему, она включает в себя все элементы, необходимые для превращения сырых данных в готовые средства для принятия решений. Qlik заполнял их полностью, причем предлагая еще запас функционала. PowerBI был не столь хорош, но тоже позволял решить задачу. Однако теперь оба инструмента фактически недоступны.
Значит ли это, что нужно срочно проходить курсы Python и подсаживаться на JS-скрипты? Нет, совсем нет. Есть другое решение. На российских продуктах можно реализовать все эти блоки. В результате даже если у вас нет ИТ-отдела, который готов может провести масштабную разработку, можно вернуть себе эффективность в новой реальности.
В прошлом посте я уже рассказывал о важности выбора модели данных. И эта часть не напрасно была вынесена отдельно — как на Хабре, так и в ходе вебинара. Мой опыт показывает, что даже при наличии хорошо составленных витрин, в которых все прекрасно, на уровне моделей может твориться хаос. А поскольку возможности моделирования данных российских BI-систем с одной стороны очень разнообразны, но с другой — не обладают той гибкостью, к которой многие могли привыкнуть, необходимо осознанно подойти к созданию модели и больше не привязываться ни к какой системе намертво, а то (не дай бог) что-то и почему-то снова придется менять.
Архитектура аналитики
В новой реальности критически важно максимально просто решить основные задачи аналитики. Речь идет о BI, а не о каком-то дичайшем DeepLearning. Поэтому на самом деле с этим вопросом можно разобраться достаточно быстро.
Что фактически нужно бизнес-аналитику?
Объединять данные из множества источников
Причесать их под бизнес-логику
Организовать работу с большим количеством таблиц (которых может стать еще больше в любой момент).
При отсутствии четкого подхода к архитектуре, этот процесс в какой-то момент превращается в боль. А отсутствие единого решения эту боль усиливает — прямо как сейчас.
Кстати, использование «единого решения» далеко не всегда способствует выстраиванию удобной архитектуры. Вместо того, чтобы максимально подготовить данные на стороне ETL и сделать удобные модели, аналитики пишут многоуровневые формулы с DAX и Set Analysis. А это сказывается на производительности, ведет к сложности поддержки и мешает последующему масштабированию. Да, такой подход может быть оправдан при первичном исследовании данных. Но качественное промышленное решение так не построишь, иначе в будущем обязательно появляются проблемы с этим.

В текущей ситуации можно использовать модульный подход, при условии, что мы качественно переработаем саму архитектуру подготовки и хранения данных. При таком подходе ни один из компонентов не будет иметьт критической роли, а система начнет демонстриоватьт идеальную выживаемость при замене любых ее частей.
Компоненты могут быть любыми, но мы для себя определили основной стек решений, который можно быстро освоить, легко поддерживать, быстро разворвачивать и тиражировать. У нас проектная работа — не сидим в одной компании, и нам важна «фабрика дашбордов», качественная и гибкая.
Коннекторы сегодня мы не будем рассматривать. Извлечение данных из источников можно решить разными способами. Иногда может требоваться готовый коннектор или систему ввода и подключить его через API. Но рассмотрим остальные компоненты, которые мы выбрали для себя — это Loginom, СУБД Postgres и Visiology.

Конвейер работы с данными
Очистку, стандартизацию и генерацию данных, включая расчеты и прогнозы, мы решили делать в Loginom.
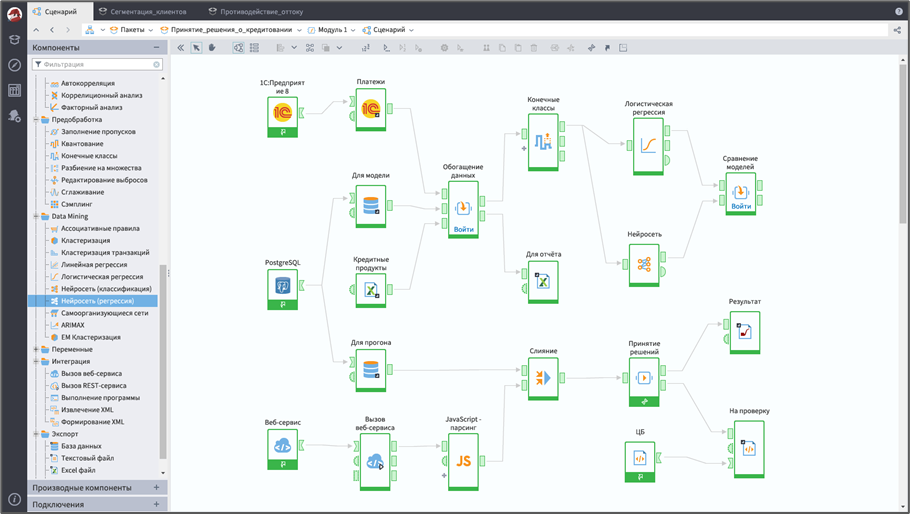
Loginom — это low-code платформа, в процессе работы с ней мы просто графически комбинируем блоки. Это позволяет качественно переработать данные и очистить таблицы, а также сгенерировать новые данные в виде прогнозов и рекомендаций. Очень важно привести их к правильному виду, задав для всех категорий единый идентификатор.

Вопрос хранения данных можно решить различными способами. Например, вслед за выбором Loginom логично будет использовать SQLite, потому что клиент этой СУБД уже встроен в Loginom, а значит можно добиться быстрого развертывания новой системы.
Если же вам требуется аналитическое хранилище, в котором будут работать разные пользователями с разными правами доступа, на мой взгляд, лучше всего подходит. PostgreSQL. Бесплатная СУБД, она легко устанавливается. Я, поверьте, никакой не системный администратор, но установил и настроил ее за 5 минут. Плюс в том, что здесь не нужно делать никаких хардкорных манипуляций.
Конечно, я не мог не рассмотреть ClikHouse, как альтернативу. Но вот как раз ее развернуть у меня не получилось. Все-таки CH — это хранилище для серьезных задач. Но если такая СУБД уже развёрнута у вас в компании или для этого есть или есть ИТ-отдел, можно использовать ClickHouse для повышения производительности. Кстати, тот факт, что в Visiology 3.0 также будет реализована поддержка ClickHouse дает еще один плюс как самой СУБД, так и новой версии Visiology, которую мы все ждем для подробного знакомства.
Узел переноса данных
Перенос данных в СУБД из Loginom происходит очень просто. Для этого предусмотрен специальный узел. С одной стороны происходит настройка подключения, а с другой — передается сама таблица, которую мы сохраняем. Можно сохранить ее по-разному — полностью перезаписывать или сохранять только измененные данные. И сделать это очень просто — достаточно поставить галочку там где нужно.

Визуализация
Данные для визуализации мы отдаем из СУБД в Visiology. Мне лично система понравилась, потому что уже сейчас она демонстрирует гибкий подход к работе с данными, а открытость команды играет очень важную роль, когда мы осваиваем новые инструменты (а значит может потребоваться доработка).

К тому же релиз Visiology 3.0, который планируется этой осенью, выглядит очень перспективно. Коллеги обещают даже поддержку DAX, так что на сегодня эта платформа выглядит фаворитом в целом и подходит для наших задач в частности.
Загрузка данных в Visiology
Перед загрузкой данных настраивается структура. Подробнее об этом я уже рассказывал в предыдущем посте, когда мы рассматривали «Звезду» как основу для создания универсальной модели данных для BI. Вот пример структуры витрин, которую создает инструмент BI2BUSINESS

Каждому из ключевых полей дается определение, равно как и «лучевым» таблицам.

Прелесть решения в том, что после этого мы уже можем работать с дашбордами! Для этого используется конструктор-дашбордов.
В итоге без каких-либо сложностей мы создаем весьма универсальный дашборд. Здесь снова не требуется никакой доработки, все настраивается в режиме self-service.

В результате работа с BI становится похожей на ассоциативный движок Qlik, только теперь все это реализовано в Visiology.

Конструирование
Когда мы создаем какую-то меру, просто выбираем поле из модели данных, по которому будет происходить простая агрегация. Но мы можем указать дополнительную фильтрацию (по другим полям). А поскольку у нас хорошо организованная звезда, можно делать точные и детальные выборки. Например, можно рассчитать меру на дату создания сделки или закрытия сделки. Применить фильтр по полю statusID — сделка успешная или нет.

Правильная подготовка модели позволяет работать «Как в лучших домах Парижа», даже если инструмент не предоставляет продвинутых средств. Мы, конечно, очень ждем Visiology 3.0 с более сложной логикой и поддержкой DAX. Но если вы хорошо все сделали и подготовили модель данных, уже на текущих инструментах можно реализовать практически все привычные нам по опыту с Qlik визуализации.

Вот как выглядит соответствующий запрос в Qlik, Excel и Visiology 2.2Х.

Заключение
Конечно, это не единственный вариант решения в сложившейся ситуации. Но схема подходит для тех случаев, когда нет возможности (и/или желания) и что-то разрабатывать. Вы получаете возможность унифицировать работу с данными, а также снизить зависимость от каких-либо систем.
В конечном счете унификация процессов работы с данными позволяет прийти к консолидации всей аналитики на уровне компании. Наличие единой точки правды гарантирует стабильность — ведь когда все одинаково рассчитывается, а любые новые данные не разрушают структуру и уже принятую картину мира, работать становится намного проще.
