Как в ВТБ меняли парадигму доступа к данным
Big Data-мания имеет под собой реальное основание. Объемы данных, которые собирают компании, стремительно растут, и бизнес при их грамотном анализе может получить большое конкурентное преимущество. Как «причесать» систему, в которой распределенные по разным хранилищам данные соседствуют с зоопарком малофункциональных инструментов для их обработки? Мы в банке ВТБ перешли на Hadoop, внедрив единую экосистему от Teradata по технологии QueryGrid. Нашей болью, муками, собственно интеграцией и результатами мы хотим с вами поделиться.
Big Data — Big Problem
Большие данные приобретают все большее значение для бизнеса банка. Аналитики могут использовать их для повышения качества оказания услуг, поддержания лояльности существующих клиентов и привлечения новых. Огромные массивы разнородных данных — это огромный пласт полезной информации. Если суметь ее достать.
»
Без аналитики больших данных компании слепые и глухие, они блуждают по сети как олень по автостраде
Джеффри Мур (Geoffrey Moore), автор бестселлера «Пересечение пропасти»
В крупных компаниях данные хранятся в разнообразных по скорости доступа и уровню безопасности хранилищах. Аналитики данных, подобно алхимикам, колдуют над результатом, используя максимально возможный набор инструментов. Но современные инструменты далеки от совершенства и выдают ответы только на простые и конкретные запросы. В итоге данные дают огромные возможности, а аналитики не могут воспользоваться ими.
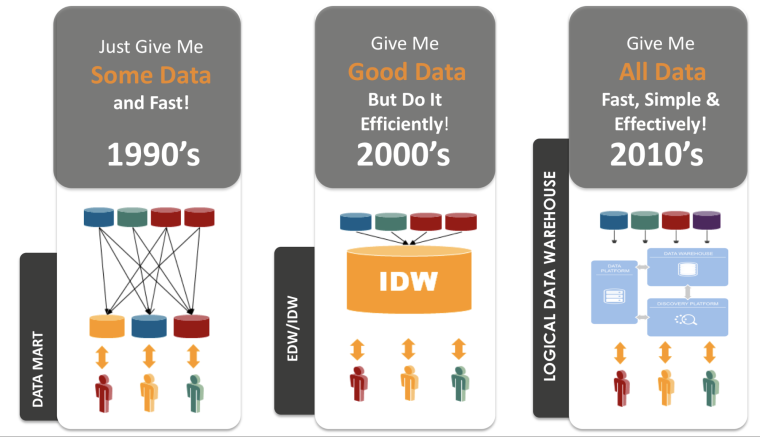
Эволюция интеграции данных
С этой проблемой столкнулись и мы. И в качестве решения нам подошел бы не просто хороший инструмент для обработки данных -, а тот, который бы соответствовал всем нашим — непростым и в некоторых случаях специфическим — требованиям. Например, нам нужно было, чтобы он мог обрабатывать любой запрос в режиме «одного окна», отображая информацию из разных источников в едином и понятном виде. Аналитику требовалась возможность легко залезать в дебри данных на любом источнике. Сам инструмент при этом не должен был перегружать системы хранения данных своими алгоритмами. Банк нуждался в интеграции с корпоративным хранилищем данных, с основной функцией — хранением холодных данных за прошлые периоды. Интеграция при этом должна была пройти безболезненно и без информационных потерь.
Еще момент. В сегодняшних реалиях BigData любое жизнеспособное решение должно сводить к минимуму перемещение данных. Важно, чтобы инструмент обработки данных был как можно более эффективным — для этого можно использовать параллелизм, сжимать трафик, настраивать буферы пакетной передачи данных. При этом нужно организовать все так, чтобы передача данных между системами с разными контурами доступа была безопасной.
Хранилище данных в ВТБ: что есть сейчас
Теперь о том, с чем мы подошли к проекту. Корпоративное хранилище данных розничного бизнеса ВТБ построено на платформе Teradata, которая служит центром консолидации данных и обеспечивает все системы единой аналитикой.
Платформа Teradata поставляет данные для онлайн-конвейера кредитов и предоставляет информацию о клиентах для аналитической CRM (Teradata Customer Interaction Manager). Другими словами, это важное звено инфраструктуры банка, и оно не должно было пострадать от новых инструментов аналитиков.
Как мы выбирали инструменты по анализу данных
Итак, нам нужно было осуществить внедрение новых инструментов обработки данных в общую экосистему банка: связать Teradata с другими платформами, наделить аналитиков новыми возможностями запросов и не потерять уже имеющиеся данные. В принципе, есть несколько общих вопросов, на которые ориентируется бизнес при выборе инструментов для работы с данными:
- Стабильность — требования к данным известны и меняются довольно редко?
- Конкуренция — сколько одновременных сессий/запросов должно поддерживать решение?
- SLA’s — какое время отклика ожидается по сформулированным задачам?
- Каков объем анализируемых данных?
- Нужно ли перемещение данных?
Ответы на эти вопросы помогут сузить круг поисков -, но универсальной таблетки нет: в каждом случае есть определенные требования к глубине запросов и ограничения безопасности по обработке данных.
Как и у большинства крупных организаций, лучшим вариантом стал Hadoop — это набор вычислительных средств для надежных, масштабируемых и распределенных вычислений, который может применяться и как хранилище файлов общего назначения, способное вместить петабайты данных.
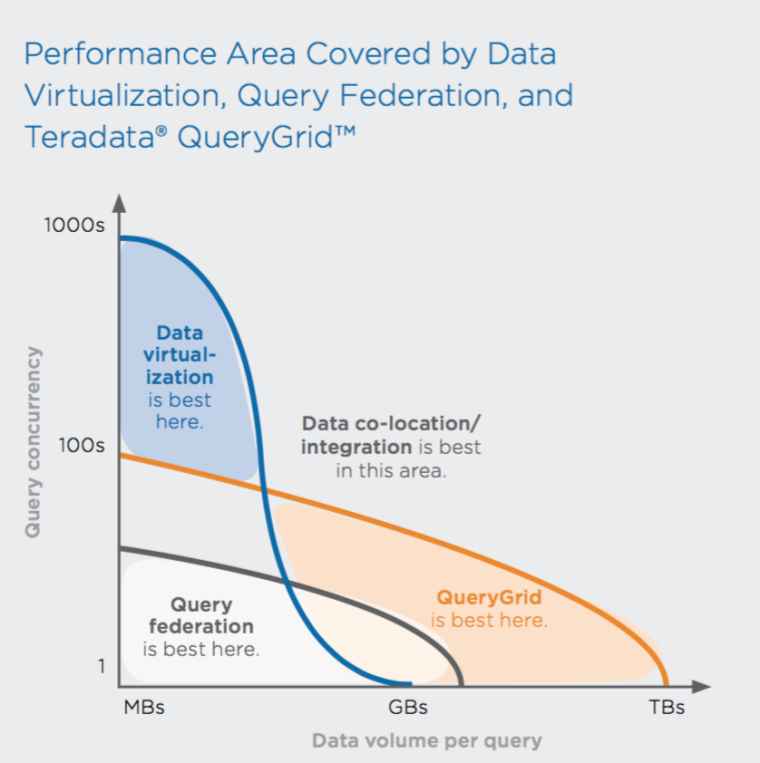
Чтобы объединить имеющуюся платформу Teradata с Hadoop, мы использовали технологию Teradata QueryGrid 2.0. Она позволяет бесшовно объединять инструменты аналитики в единую систему. Технологию демонстрировали на различных докладах Teradata Universe и Teradata Partners, приводя кейсы других компаний — Ebay и PayPal. Для примера приведем график исследования компании Third Nature, показывающий, когда лучше использовать виртуализацию данных, федерацию данных и Teratada QueryGrid. Как видите, чем больше объем данных, тем выгоднее использовать QueryGrid.
До полноценного внедрения Hadoop был разработан тестовый стенд, на котором проходили испытания по интеграции. Результаты тестов по скорости и удобству решения нас полностью удовлетворили: трансформация инфраструктуры хранилища прошла максимально комфортно для пользователей. Многие даже не заметили, что информация хранится в разных системах. Для нас это был идеальный вариант — хоть внешне ничего и не изменилось, Hadoop успешно подключился и использовался вместе с Teradata.
Разбираем инструменты: Teradata QueryGrid 2.0 и Execution Engine
Технология Teradata QueryGrid 2.0 позволяет организовать множество разнородных систем в так называемую фабрику данных, где они могут выступать как удаленным источником, так и инициатором запросов к любой или ко всем системам фабрики сразу.
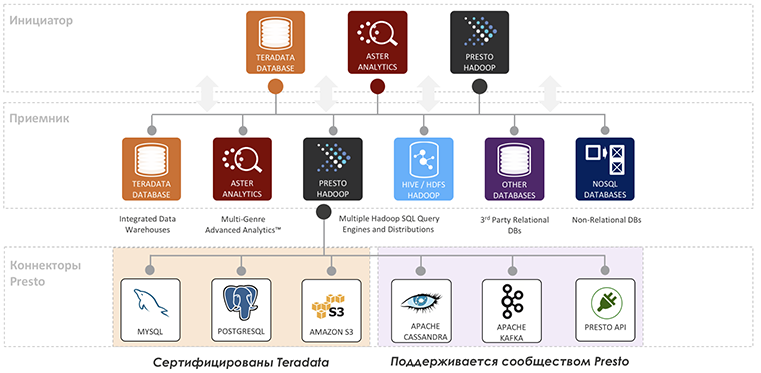
QueryGrid имеет множество настроек безопасности, несколько ролевых моделей, позволяет шифровать и сжимать трафик, автоматически делать Push Down простых предикатов и более сложных конструкций, используя особенности удаленной системы, вручную пробрасывать синтаксис, выполнять DDL операции, вызов процедур.
Однако технология не претендует на роль средства виртуализации данных общего назначения, это все-таки средство высокопроизводительной мультисистемой аналитики.
Teradata QueryGrid имеет модульную архитектуру, которая позволяет изменять, обновлять и добавлять компоненты фабрики данных, не затрагивая при этом всю систему в целом.
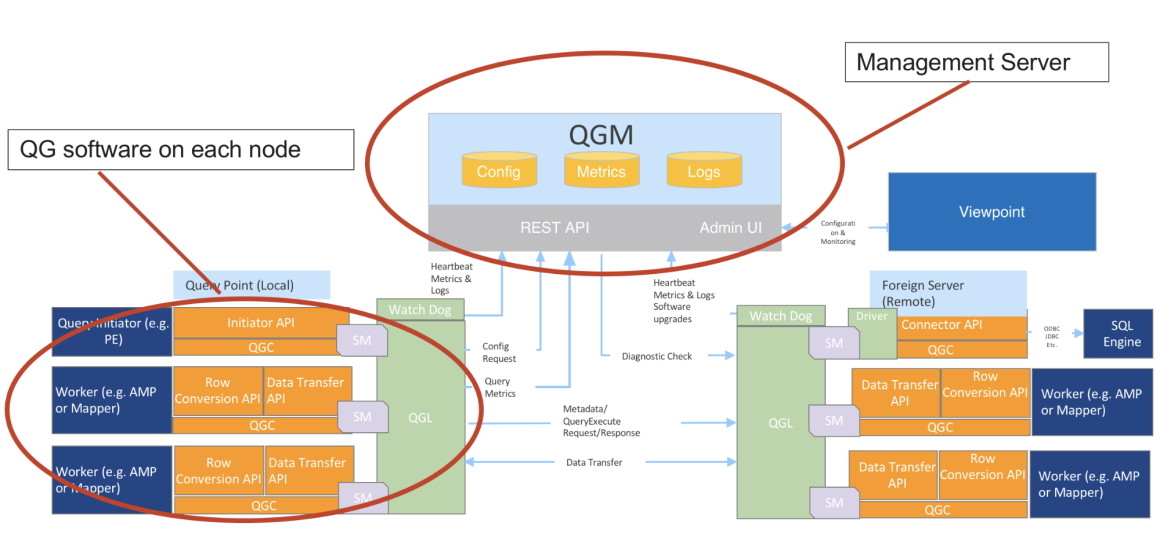
У Teradata QueryGrid есть несколько компонентов.
QGM — Query Grid Manager — осуществляет централизованное администрирование и мониторинг.
Он отвечает за установку и обновление всех компонентов фабрики, мониторинг и уведомление о возникающих проблемах. QGM позволяет управлять ключами защищенного доступа по сетям фабрики, захватывает метрики производительности запросов (время его выполнения на серверной и клиентской стороне), а также всех логов, генерируемых компонентами фабрики.
QGM работает на Cassandra, а для анализа логов использует связку Elastic Search и Kibana. Предоставляет REST API для встраивания в интерфейс Teradata Viewpoint. QGM требует для себя отдельного сервера, а будучи кластеризованным (High Availability решение), — сводит к нулю время даунтайма при обновлении любого компонента системы.
Коротко о других компонентах QueryGrid:
- Watch Dog — управляет процессами на каждом из узлов систем, а также пересылает QGM логи и отчеты о статусе работы узлов QG;
- Fabric — объединяет в себе системы, коннекторы и линки;
- QGC — Query Grid Connector — коннектор к источнику данных;
- QGL — Query Grid Link — пара коннекторов (инициатор запроса и удаленная система);
- Viewpoint — единый инструмент мониторинга Teradata.
Следующий шаг — выбор движка обработки Hadoop. Для этого нам нужно было подобрать подходящий по производительности и совместимости с версией Teradata у ВТБ. Было три варианта: MapReduce, TEZ и Presto.
TEZ отпал сразу, поскольку не поддерживал выбранный нами дистрибутив Hadoop от компании Cloudera (5.9 A MR). На бенчмарках отличную производительность как в изолированных тестах, так и в условиях конкурентной нагрузки показал Presto. И поскольку высокая производительность имеет большое значение для мультисистемной аналитики, мы остановились на Presto.
Еще один плюс Presto — полная совместимость с QuerryGrid 2.0: с 2015 года его разработку и поддержку ведет Teradata. Teradata, как говорится, born to be parallel. Presto — тоже parrallel, MPP (massive parallel processing) движок, QueryGrid умеет использовать эти преимущества.
Для нашего проекта нужно было два вида коннекторов:
- коннектор к СУБД Teradata для включения в фабрику любой из систем Teradata;
- коннектор к Presto, позволяющий включить в фабрику любую инсталляцию Presto.
Ниже представлена схема взаимодействия между Teradata и Presto.

Наиболее полное тестирование инструментов проводила компания AtScale, ниже приведем их результаты. С подробностями и методикой тестирования можно ознакомиться по ссылке.
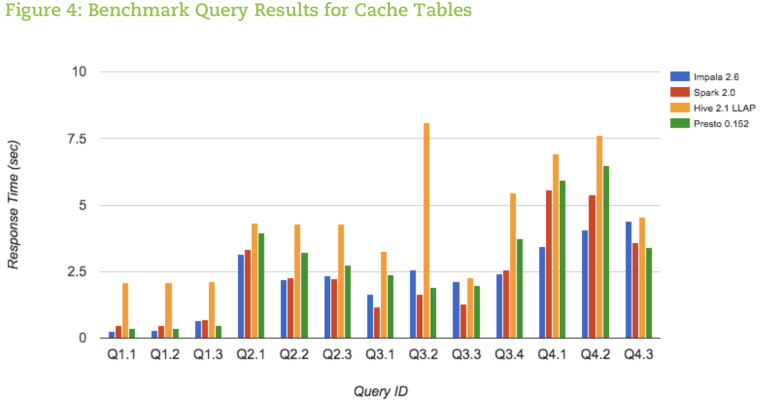
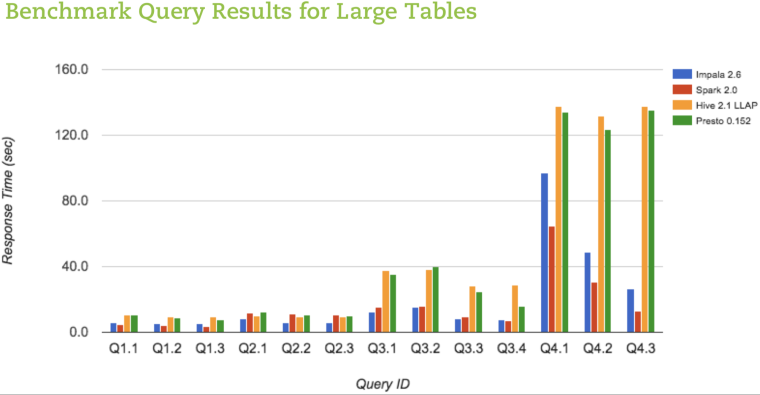
Стоит взглянуть на графики — и выбор компонентов станет понятен.
Физическая реализация системы
Корпоративное хранилище данных в ВТБ состоит из двух промышленных stand-by контуров Teradata, одинаковых по содержанию.
На PROD1 работает ETL и регламентные процессы банка. PROD2 служит системой для работы пользователей и запуска маркетинговых кампаний. В основе системы PROD1/PROD2 — концепция частного облака. Данные между системами PROD1 и PROD2 постоянно реплицируются на основе разработанного фреймворка, в том числе и с помощью QueryGrid.
Обратите внимание на то, как соединен Hadoop с системой PROD2. Во-первых, это шесть Infiniband-линков по 56 Гбит/с (по три на каждый IB свитч). Во-вторых, системы скоммутированы как единое целое — свитч в свитч (Multi System Configuration). А это значит — широчайший канал и минимальные задержки.
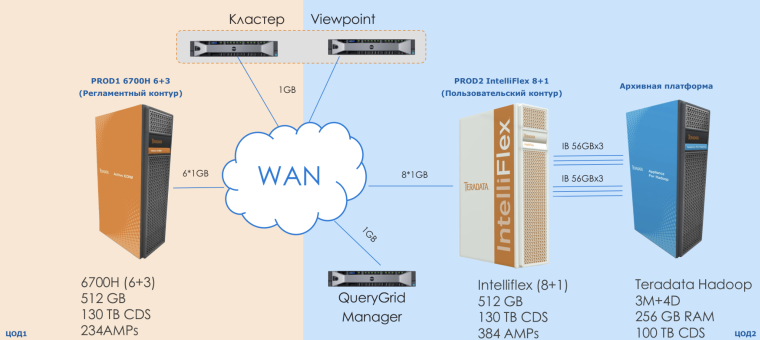
Еще один момент, который не отражен на картинке, — кластер Presto, установленный прямо на узлах Hadoop: 4 worker-ноды Presto на 4 data-нодах Hadoop. Это значит, что для Presto данные Hadoop локальны, лишней передачи данных по сети не происходит.
Теперь нам остается настроить QueryGrid и попробовать сначала загрузить через него информацию в Hadoop, а потом использовать ее в запросах. Доступ ко всем настройкам и функциям, в том числе, установке пакетов на узлы системы, делается через веб-интерфейс.
Выглядит это вот так:
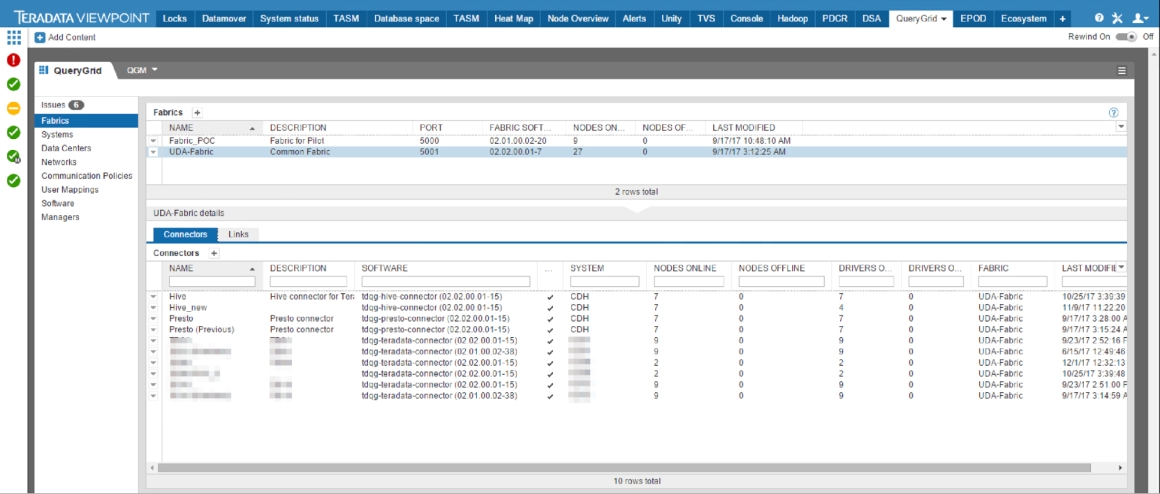
После того как коннекторы и линки настроены, можно переходить к написанию запросов. Продемонстрируем, как объединить две системы. Для этого напишем несколько запросов: создадим объект, через который обращаемся к данным Hadoop; зальем данные с нашего хранилища Teradata в Hadoop и запросами продемонстрируем бесшовный доступ к обоим хранилищам и общей их обработке.
Первым делом создаем в базе объект, через который будем обращаться к Hadoop:
CREATE FOREIGN SERVER TD_SERVER_DB.presto USING
LINK ('presto')
version ('active')
DO IMPORT WITH TD_SYSFNLIB.QGINITIATORIMPORT ,
DO EXPORT WITH TD_SYSFNLIB.QGINITIATOREXPORT ;Все, можно заливать данные из Teradata в Hadoop.
INSERT INTO DEMO.SOME_HISTORY_DATA@PRESTO
SELECT REPORT_DT
, ACCOUNT_RK
, ACCOUNT_NUM
, CURRENCY_RK
, CURRENCY_ISO_CD
, BALANCE
FROM DEMO.SOME_DATA
WHERE REPORT_DT BETWEEN DATE '2014-01-31' AND DATE '2014-12-31' Создаем слой представлений
Просмотр данных Hadoop
REPLACE VIEW SYSDBA.v_SOME_HISTORY_DATA AS
SELECT REPORT_DT
, ACCOUNT_RK
, ACCOUNT_NUM
, CURRENCY_RK
, CURRENCY_ISO_CD
, BALANCE
FROM DEMO.SOME_HISTORY_DATA@PRESTO
WHERE REPORT_DT BETWEEN DATE '2014-01-31' AND DATE '2014-12-31'
AND REPORT_YEAR = 2014;Просмотр данных Teradata
REPLACE VIEW SYSDBA.v_SOME_HOT_DATA AS
LOCK ROW FOR ACCESS
SELECT REPORT_DT
, ACCOUNT_RK
, ACCOUNT_NUM
, CURRENCY_RK
, CURRENCY_ISO_CD
, BALANCE
FROM SYSDBA.SOME_HOT_DATA
WHERE REPORT_DT > DATE '2014-12-31';А вот и он — бесшовный доступ к данным: итоговая выдача, которую получает пользователь.
REPLACE VIEW SYSDBA.v_UNITED_DATA AS
SELECT *
FROM SYSDBA.v_SOME_HOT_DATA
UNION ALL
SELECT *
FROM SYSDBA.v_SOME_HISTORY_DATA
;
Теперь данные можно брать из итоговой, объединенной выдачи, а QueryGrid разберется, как и откуда их достать.
SELECT *
FROM SYSDBA.v_UNITED_DATA
WHERE report_dt = DATE '2014-01-31'; --данные только из Hadoop, Teradata не задействуется
SELECT *
FROM SYSDBA.v_UNITED_DATA
WHERE report_dt = DATE '2016-01-31'; --данные только из Teradata, Hadoop не задействуется
SELECT *
FROM SYSDBA.v_UNITED_DATA --данные берутся из обеих систем
WHERE report_dt BETWEEN DATE '2014-11-30' AND DATE'2015-01-31';Что в итоге
С помощью Teradata EasyGrid удалось построить логическое хранилище данных, где все разрозненные источники данных собраны в единую экосистему.
Новый инструмент позволил аналитикам получать максимально подробные ответы на «глубокие» запросы, не используя, как раньше, целый зоопарк приложений.
В планах по развитию — использование исторических данных, вынесенных в Hadoop и регламентные ETL-процессы, и подключение новых источников данных к фабрике через технологию QueryGrid.
