Как в Тинькофф создавали Data Catalog

В чем главная задача аналитика? Думать головой и принимать решения. А правильные решения можно принять только при наличии нужных данных. Но как найти данные в большой компании? Раньше мы решали эту проблему с помощью ручного ведения документации о данных в Confluence, но с ростом объемов этот подход становился все менее эффективным. Пришло время что-то менять.
Меня зовут Дмитрий Пичугин, я занимаюсь внедрением Data Governance и Data Quality в Тинькофф. Я расскажу, как мы решали проблему поиска данных. Помогать мне в этом будет Роман Митасов. Он виновен в появлении большей части бэкенда Data Detective и расскажет про технические детали проекта.
Как искать данные
Ни одна история не обходится без злодеев. В нашем случае им стала проблема поиска данных. Представьте себя на месте аналитика: у вас есть вопрос и вам нужен ответ. Но где взять для него данные? На поиск информации можно потратить часы, а иногда и дни. В итоге вы все равно откроете мессенджер и будете писать коллегам, пытаясь найти кого-то, кто знает хоть что-то о нужных вам данных.
Как мы узнали об этой проблеме? Очень просто: спросили пользователей. В период с 2019 по 2020 год опросы показали, что число пользователей, которым сложно искать данные, растет. Однако прежде чем приступить к решению проблемы, мы ее изучили.
 В 2019 году поиск считали неудобным 25% опрошенных, в 2020 — уже 40%
В 2019 году поиск считали неудобным 25% опрошенных, в 2020 — уже 40%
Какие инструменты используют аналитики
Как выглядит рабочий день обычного сферического аналитика в вакууме? Заказчик задает вопросы, а аналитик с помощью данных предоставляет ответы.

Схема кажется простой, но в ней есть подвох, и кроется он в инструментах. Какие инструменты аналитики используют в своей работе? Во-первых, Сonfluence — место, где хранится описание всех данных. Во-вторых — сообщество аналитиков, где можно задать любой вопрос.
Но бывает, что информация в Сonfluence может быть устаревшей, разрозненной или просто отсутствовать. И коллега-аналитик внезапно в отпуске, заболел или вовсе уволился пару лет назад. Вишенкой на торте будет заказчик: ему важно получить ответ здесь и сейчас, а проблемы аналитиков его, мягко говоря, не волнуют. Да и не должны.
 Реальность оказывается куда сложнее
Реальность оказывается куда сложнее
В итоге наш герой остается без нужных данных
По итогам анализа контекста мы выделили четыре проблемы:
огромный объем данных;
неполнота документации;
разрозненность документации;
из-за отсутствия подходящего инструмента самым эффективным способом найти данные были вопросы к коллегам.
Подумав, мы вычеркнули первый пункт и решили сосредоточиться на работе с оставшимися тремя. Почему вычеркнули? Потому что огромный и постоянно растущий объем данных в мире — это данность, с которой придется жить.
Сначала мы попробовали найти решение во внешнем мире, потому что знали, что не единственные столкнулись с подобными проблемами. С ними рано или поздно сталкивается любая компания, которая наняла хотя бы 10—15 аналитиков.
Это подтверждалось исследованиями западных коллег: они выяснили, что средний аналитик тратит 30—50% рабочего времени на поиск данных. Естественно, такая ситуация уже тогда никого не устраивала. Поэтому хорошая новость заключалась в том, что мастодонты вроде Google, Linkedin, Uber и Lyft уже придумали, как решать эту проблему: внедрением систем класса Data Catalog.
Что такое Data Catalog
Для начала погрузимся в контекст, обратившись к великому и могучему DAMA-DMBOK. Остановимся на четырех основных концепциях, которые нам пригодятся.
Данные как актив. Если кратко, данные стоят реальных денег. Это аксиома. А раз они стоят денег, нужно заботиться о них и управлять ими.
Метаданные — данные о данных. Чтобы было понятнее, давайте договоримся, что метаданные — это тип данных, который дает контекст для корректного и эффективного использования ваших объектов данных.
Управление метаданными — процесс, который необходим, чтобы метаданные выполняли свою функцию. С его помощью мы гарантируем пользователям доступ к качественной, интегрированной и объединенной в одном месте информации о данных.
Data Catalog — система, в которой собраны все метаданные. Представьте себе Amazon. Вы ищете товар и получаете кучу информации: рейтинги, комментарии, фотографии и прочее. Data Catalog — то же самое, но для датасетов.
Поиск решения
Мы думали, что на рынке куча решений, которые достаточно немного допилить — и мы готовы внедряться. В итоге ни одно не подошло. Искали по четырем критериям:
Гибкость модели. Тинькофф — сложная и разнообразная экосистема. Многие ее части самописные. Поэтому мы искали инструмент, который смог бы затянуть в себя любые метаданные любой структуры из любой системы.
Детальный data lineage. Наша экосистема очень сложная. Когда аналитики анализируют изменение одного-единственного столбца, это может вылиться в анализ десятков, сотен, а в некоторых случаях и тысяч зависимостей. Чтобы ребята не потерялись и не уволились, нужен удобный и легкий инструмент визуализации.
Удобство. Нужно, чтобы пользователи получали удовольствие от работы с инструментом, а не тратили на него время и нервы.
Стоимость. С этим все понятно — деньги нужно расходовать эффективно.
Всего в 2020 году мы проанализировали около 16 систем. В ходе исследования решений мы умудрились сформировать ещё и пятое требование — возможность свободной доработки инструмента. Так как экосистема Тинькофф быстро эволюционирует, то нам нужен инструмент, который позволит нам эволюционировать вместе с ней. Ни одна из рассмотренных нами систем не удовлетворяла всем критериям.
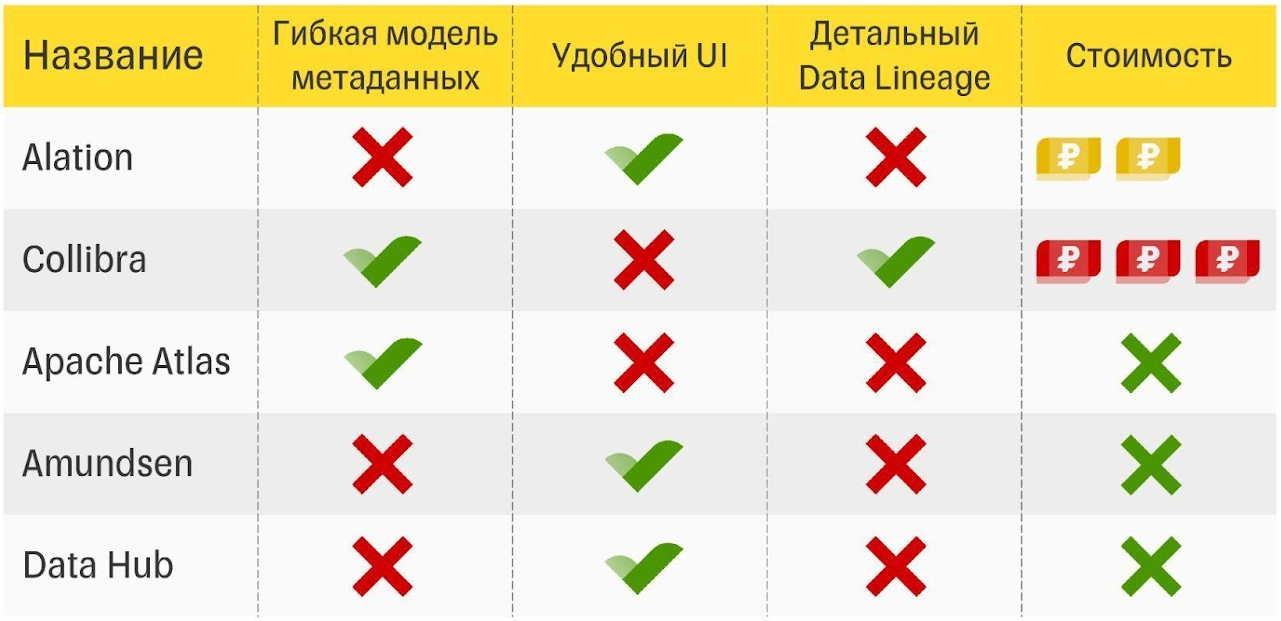 Пять финалистов. Ни одно решение не прошло по всем четырем критериям
Пять финалистов. Ни одно решение не прошло по всем четырем критериям
Если вы не нашли что-то подходящее — придётся строить своё.
Так появился Data Detective: внутренний Data Catalog Tinkoff. Еще мы называем его DD или по старинке MG.
Как устроен Data Detective
Data Detective — созданный в Тинькофф Data Catalog, предназначенный для работы с нашим крайне разнообразным Data-ландшафтом. Его целевая аудитория — все сотрудники, использующие данные, а не только дата-инженеры и дата-стюарды. В Data Detective можно найти любую необходимую аналитику информацию.
В нашем инструменте мы сделали удобный UI. Иногда информация по одному датасету бывает раскидана по десяткам систем и пользователь, которому нужно составить мнение о датасете, не хочет все это изучать. Поэтому мы решили интегрировать всю мету в одну карточку, чтобы дать пользователю всю необходимую информацию, и неважно, из какой системы она пришла.
Карточка — первый базовый элемент DD. Основная информация собрана в центре. Справа еще одна панелька — это связи, второй базовый элемент DD. Они позволяют переходить из одной карточки в другую, ведь метаданные не существуют в вакууме. А слева мы видим дерево объектов каталога, которое позволит найти любую карточку, если вы хотя бы примерно знаете, где она.
 Карточка BI отчета
Карточка BI отчета Кроме поиска в панели слева есть ещё подробный полноэкранный
Кроме поиска в панели слева есть ещё подробный полноэкранный
Также у нас есть Lineage, который может отображать связи вплоть до уровня столбцов. Он не ограничен таблицами, джобами и всем прочим. Туда можно заложить что угодно, загрузив в модели правильные связи.
Туда можно заложить что угодно, загрузив в модели правильные связи.

Визуализация — это хорошо, но не сделали ли мы работу впустую? Чтобы ответить на этот вопрос, приведу некоторые цифры.
Мы начали развитие DD в первых числах февраля 2021 года. По состоянию на конец апреля 2022 года еженедельный поток пользователей платформы составил 650 уникальных аналитиков, которые ежедневно генерируют 6 тысяч с лишним запросов.
Может возникнуть вопрос, почему я говорю про еженедельную аудиторию, а не про ежедневную или ежемесячную. Дело в том, что потребность в поиске возникает не ежедневно, но и не слишком редко, поэтому DAU — слишком часто, а MAU — слишком редко. А WAU — идеальный показатель оценки популярности Data Catalog.
 Отзывы пользователей. Мы читаем их все, чтобы понять, как улучшить продукт
Отзывы пользователей. Мы читаем их все, чтобы понять, как улучшить продукт
Как все реализовано технически
Разберем основные фичи: каталог, поиск и Data Lineage.
Каталог. В начале работы настрой был позитивным. Мы ожидали, что нагрузка на сервис будет небольшой, а объем метаданных — крошечным.
Довольно быстро оказалось, что есть проблема: многообразие метаданных. Мы хотели сделать каталог универсальным, то есть загрузить туда много разных систем помимо баз данных. Это и сервисы отчетности, и ETL-инструменты, и ручная документация, и многое другое. И непонятно, как сложить этот зоопарк в одно место.
В процессе получилась вот такая архитектура. В ней нет ничего сверхсложного: загружаем метаданные с помощью ETL в Postgres, а дальше уже действует наш каталог.
 Получившаяся архитектура
Получившаяся архитектура
Чтобы собрать метаданные, мы сделали ETL-фреймфорк на базе Apache Airflow. Наши дата-инженеры построили крутую инфраструктуру разработки, которая позволила полностью покрыть тестами все ETL-процессы. Конечно, речь не идет о 100%, но о 90% — точно. Сами тесты интеграционные, можно сказать, end to end.
 Схема покрытия тестами
Схема покрытия тестами
Покрывать тестами большое количество ETL-процессов сложно из-за тестовых данных. Их надо откуда-то взять и поддерживать в актуальном состоянии, а это большая головная боль. С ней мы справились, сделав генератор тестовых данных. Мы создаем входные тестовые данные, в ходе шага ETL-процесса из них генерируются выходные, являющиеся входными для следующего шага, и так по цепочке. Потом сгенерированные данные сохраняются и используются как эталонные для последующих запусков.
Но что будет, если дата-инженер допустит ошибку в коде и при первом прогоне сгенерируются «плохие» тестовые данные? Мы это предусмотрели. Помимо тестовых данных генерируется красивая Markdown-презентация. Это позволяет сверить данные на этапе ревью. Конечно, без ручного тестирования тут не обойтись. Зато в итоге получаются интеграционные тесты, которые при последующих запусках и модификациях помогут отловить самые маленькие ошибки.
Данные загружаются в доменную модель — сущность, которая представляет собой объект метаданных. Например, таблицу, отчет или процесс. Между сущностями сохраняются связи. Они могут быть простыми — типа Contains, когда внутри колонки хранится таблица, — и сложными.
Остается вопрос: как сложить разные данные в таблицу в реляционной базе данных? Если бы мы начали создавать по отдельной таблице для каждого типа данных, это поломало бы всю универсальность. Значит, надо сложить все в одну таблицу в PostgreSQL. И это стало возможным благодаря JSONB.
JSONB — прекрасный инструмент, который позволяет не просто хранить динамические данные в PostgreSQL, но даже вешать на них индексы и работать с ними как с обычными колонками. Подробнее — на выступлениях Олега Бартунова.
После того как данные сложили, их надо как-то показать. Сначала была идея создать редактор карточек, чтобы клиенты сами рисовали страницы в каталоге. Начали развивать эту мысль и поняли, что понадобятся админка, ролевая модель, инструмент для редактирования шаблонов, —, а это слишком сложно. Выбрасывать идею мы не стали, но сделали проще: оставили блоки и сделали универсальный дизайн. Клиенты все еще контролируют, как все отображается, но делают это путем заполнения данных.
К нам приходит клиент — какая-нибудь система Тинькофф — и говорит: мы хотим к вам интегрироваться, загрузить данные. Мы даем им документацию и объясняем: если вы что-то положите в это поле, на экране это будет отображаться вот так. И все довольны.

Но разве можно все показывать одинаково? Те же BI-отчеты хочется показывать по-другому, чтобы пользователям было проще ориентироваться. Для этого мы добавили к сущностям специальное поле, которое определяет дизайн. Мы заполняем его вручную, указывая, какой дизайн должен быть у страницы. Можно выбирать: например, есть дизайны «Таблица», «Колонка» или «Отчет». Если готовые варианты не устраивают заказчика, мы заводим задачу на добавление нового дизайна и добавляем его ключ в контракт загрузки данных.

Поиск. Если есть каталог, значит, нужен поиск. Когда мы делали прототип, нашей целевой аудиторией были дата-инженеры, дата-аналитики и DWH. Поэтому хотелось сделать быстрый, четкий и удобный поиск.
Относительно четкости мы решили не заморачиваться и просто использовать триграммный индекс PostgreSQL. Даже смогли уместить весь поиск в один SQL-запрос!
Однако скоро пришли аналитики из других подразделений. Они пытались пользоваться поиском, а тот выдавал им что-то непонятное. Триграммный индекс стал медленным, когда мы загрузили туда все метаданные, и на это тоже часто жаловались.
Но мы не стали выкидывать решение, сохранив фокус на каталоге и удобстве дизайна. Мы улучшили поиск, добавив дополнительные фильтры, которые помогли сузить выборку. Ведь пользователи, как правило, ищут не все метаданные, а только по своей системе, которую уже знают. Выбрав свою систему, они получают более или менее релевантный ответ. На первое время этого хватило, решение помогло нам сэкономить время.
Также мы сделали удобный, интуитивный дизайн. Пока что это все, но мы продолжаем думать, как улучшить движок, добавить ранжирование и сделать поиск нечетким. Вероятно, мы откажемся от текущего решения в пользу нового. Может, на базе PostgreSQL, а может, с использованием какой-нибудь поисковой системы.
Data Lineage. Мы считали колоночный Lineage нашей киллер-фичей. Хотелось, чтобы он был красивым и удобным, и с этим проблем не возникло. Но еще мы хотели, чтобы наш Lineage был глубоким, то есть показывал всю историю изменения данных. Пытались реализовать это через рекурсию, но это не сработало. Сейчас ищем новое решение.
Заключение
За 14 лет на антресолях хранилища данных Тинькофф скопилось 2 петабайта данных,
± 120 000 таблиц, ± 30 000 отчетов и много чего еще. Разгрести такие завалы непросто, но Data Detective почти справился: собрал все в одном месте и дал доступ всем, кому надо. Удобно, универсально и с простой интеграцией. А поскольку нам самим нравится, мы готовы делиться — идти в пилот с перспективой вендоризации. Мы уже выложили в открытый доступ ETL-фреймворк. Всех, кому это может быть полезно, приглашаем в репозиторий.

А мы пока будем добавлять то, что еще не успели. Например, push-сценарий, чтобы клиенты могли как можно быстрее интегрироваться и самостоятельно присылать метаданные. Новый поисковой движок, более глубокий Lineage, и дальше.

Если у вас есть вопросы о Data Detective — пишите в комментарии, мы постараемся ответить. И, конечно же, делитесь опытом создания и использования систем Data Catalog.
P. S.
Эта статья — расшифровка выступления на HighLoad++ Foundation, которое состоялось в мае 2022 года. С того момента прошло уже 5 месяцев, и нам показалось правильным дать в конце небольшой апдейт по тому, что происходило с DD за это время.
Что мы успели сделать:
Реализовали обещанный пуш-сценарий интеграции с Data Detective.
Добавили в Data Detective новый крутой поисковый движок на базе OpenSearch.
Доработали UI инструмента и сделали его еще проще, красивее и понятнее для пользователей.
Сделать еще много небольших, но важных улучшений в продукте.
И это принесло плоды! С мая наша еженедельная аудитория (WAU) выросла еще на 33% и подбирается к 900 довольных аналитиков внутри Тинькофф. А еще мы продолжаем общаться с рынком и узнавать, что вам хотелось бы увидеть в нашем продукте. Поэтому, если вам интересно, заходите в наш канал в Telegram, смотрите другие выступления по продукту и задавайте ваши вопросы. Мы обязательно ответим!
Совсем скоро в Москве начнется HighLoad++. До 24 ноября еще есть время познакомиться с программой докладов и докладчиками. Всего будет 8 секций и 120 новых докладов. Подробности на официальном сайте конференции.
