Как улучшить распознавание скелетов в MediaPipe
Я люблю скелетные детекторы из Mediapipe. Чтобы запустить их нужно всего несколько минут. Работает на разных платформах (мобильные, pc, embedded, и.т.д.). И выдает достаточное качество для многих применений.
Но надо признать что не всюду качества хватает. Давайте я расскажу как небольшими силами можно его улучшить. Приведенная тут логика будет построена вокруг Mediapipe, но она им не ограничена. Применяя аналогичные подходы можно улучшить практически любой скелетный алгоритм.

Для начала разберем общую логику работы скелетных детекторов
Пайплайн с скелетами в MediaPipe выглядит следующим образом (подробнее можно посмотреть тут — 1,2,3,4,5):
 Общая логика
Общая логика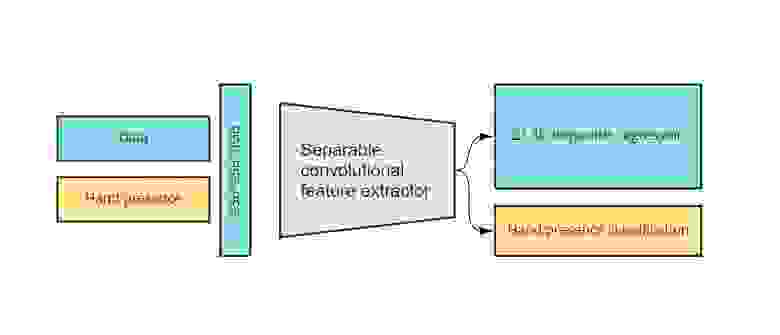 Детектор кейпоинтов на руках
Детектор кейпоинтов на руках
Если в двух словах, на примере руки:
Начало работы
Для области руки :
Если рука присутствует — корректируем область детекции и переходим к п.2
Если рука не присутствует, то переходим к п.1
Давайте теперь поговорим о проблемах алгоритма, и тому как надо их лечить.
Говоря о алгоритме на базе нейронных сетей важно помнить что его качество определяется:
Актуальностью (давно или недавно вышла работа)
Качество датасета
Тяжестью Backbone. (На MobileNet все будет летать, на трансформерах будет медленно.)
В MediaPipe хороший и актуальный алгоритм. Он учитывает физику руки, немножко физику процесса, современные статьи.
В MediaPipe качественный датасет. Они не просто собрали хороший датасет (30к), но и создали синтетический датасет неограниченного размера.
Но, датасет собран исходя из того что использоваться будет на маломощных устройствах, и рука будет около камеры.
А вот Backbone в MediaPipe достаточно прост. Это сделано для быстрой работы.
Если говорить про подробности (тут код, тут статья).
Для детекции используется очень легкая версия FPN где зарезали много якорей
 В статьях другая картинка, но реально сетка детекции какая-то такая
В статьях другая картинка, но реально сетка детекции какая-то такая
Детекции квадратные, это позволяет уменьшить число якорей
Энкодер-декодер позволяют работать с большими разрешениями.
Для оптимизации используется Focal loss
Для особых точек рук используется вот эта работа. Практически идентичные пайплайны и по рукам и по телам. Только чуть разные методы обучения используются.
В чем же проблемы? Да они в целом стандартны:
Не работает в нужных ракурсах
Неправильные условия освещения
Слишком мелкие/слишком крупные руки
Вот несколько примеров с проблемами:
 Проблемы начинаются как только появляется нетипичный домен данных. А их много.
Проблемы начинаются как только появляется нетипичный домен данных. А их много.
А теперь я расскажу про 5–6 простых способов как улучшить качество:
Переобучение / Замена модели
Начнем с наиболее очевидных подходов, которые структурируем по сложности имплементации.
Самый простой
Проще всего улучшить качество (для большинства задач) — переобучить детектор по вашим данным. Ни один другой подход нельзя реализовать так быстро и получить такой прирост качества. Конкретно для MediaPipe нет готового пайплайна обучения. Но можно взять аналогичный FPN детектор отсюда с пайплайном.
И произвести аналогичную настройку якорей. Либо, взять любой другой детектор (yolov5 yolox, и.т.д.).
Самая сложная такого подхода — получить набор данных. Разметка набора данных для обнаружения можно получить очень быстро. Человек может разметить около тысячи изображений в час. А для обучения детектор, который на некоторых выбранных доменах превзойдет MediaPipe, будет достаточно 5–10 тысяч изображений. Так что, как правило, со всей инфраструктурой вам понадобится около недели на процесс переобучения.
 Такая разметка в любом cvat или supervisely делается очень быстро
Такая разметка в любом cvat или supervisely делается очень быстро
Если у вас плохо работает детектор — то ошибка будет влиять на все процессы дальше.
И его фикс улучшает все. Например в одном из проектов где мы использовали MediaPipe на старте — переобучение по актуальному датасету (ракурсы/оптика) — число ошибок уменьшилось примерно в 5 раз. По другому проекту, где детектировали лица и оценивали ориентацию взгляда и мимику — получили уменьшение числа ошибок в 2 раза (но там был не MediaPipe, а предобученные сети OpenVino). По третьему проекту, где мы делали детекцию скелетов — полученный прирост вложили в скорость, и это позволило ускорить в несколько раз.
Чуть сложнее
Вариант сложнее — переобучить алгоритм детекции ключевых точек по вашему датасету.
Это особенно важно когда вы хотите производить какую-то точную оценку действий. Но смысл это имеет не всегда. Из тех трех приведенных выше проектов — мы лишь один раз делали переобучение скелетной модели
Полная замена модели
Так же надо окончательно закрыть варианты переобучить и закрыть модель. Можно зайти на papers with code:
https://paperswithcode.com/task/hand-pose-estimation
https://paperswithcode.com/task/3d-hand-pose-estimation
https://paperswithcode.com/task/pose-estimation
https://paperswithcode.com/task/3d-human-pose-estimation
https://paperswithcode.com/task/facial-landmark-detection
И взять любую понравившуюся модель/подход. По качеству будет сильно лучше чем MediaPipe, по времени сильно больше. И садиться оптимизировать.
Использование временной компоненты
Если вы работаете с видео — у вас есть временная компонента. Вы можете взять набор детекций с разных кадров и вторичной сетью «вылечить его».
Временная компонента может значительно повысить качество — ведь рука не может летать произвольно по кадру, да и действия в рамках одной задачи обычно похожие.
И нет никаких «Но есть же фильтр Калмана!». Но его настройка для сложного объекта будет сложнее чем обучение нейронной сети. Да и для нелинейных процессов он будет хуже.
Не для любой задачи временная компонента может улучшить качество. Например если вы распознаете по одному кадру. Или для быстрых действиях.
Несколько способов как можно использовать временную компоненту
Уменьшить объемы шумов
Для этого достаточно реализовать схему с каким-нибудь понижающим размерность эмбеддингом и восстановлением данных. Берем последовательность кадров, разворачиваем её назад. Высокочастотные компоненты обычно уходят. Полученный embedding можно использовать для OneShot Learning или других быстрых распознаваний.
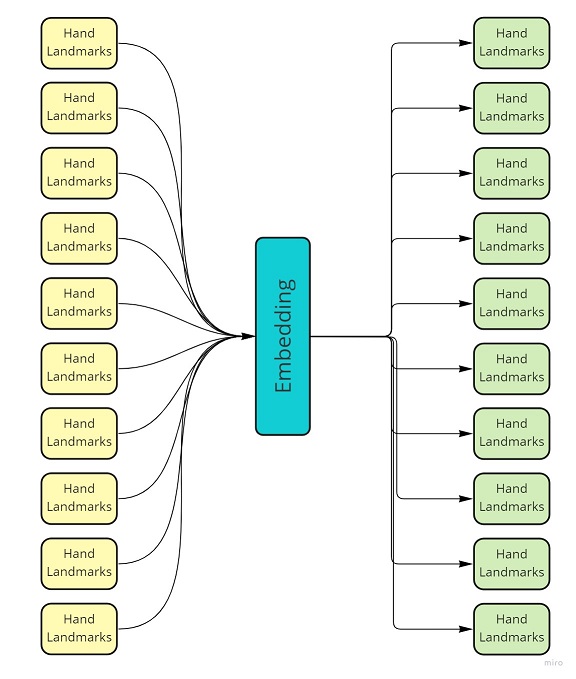 Landmarks слева зашумлены, справа стабилизированные
Landmarks слева зашумлены, справа стабилизированные
«Вылечить» выбитые точки
Если у вас пропадает детекция на части кадров — такие точки не сложно предсказать. Можно обучить сетку восстанавливать все точки с какого-то временного интервала (или предсказать детекцию на текущем кадре, если её нет).
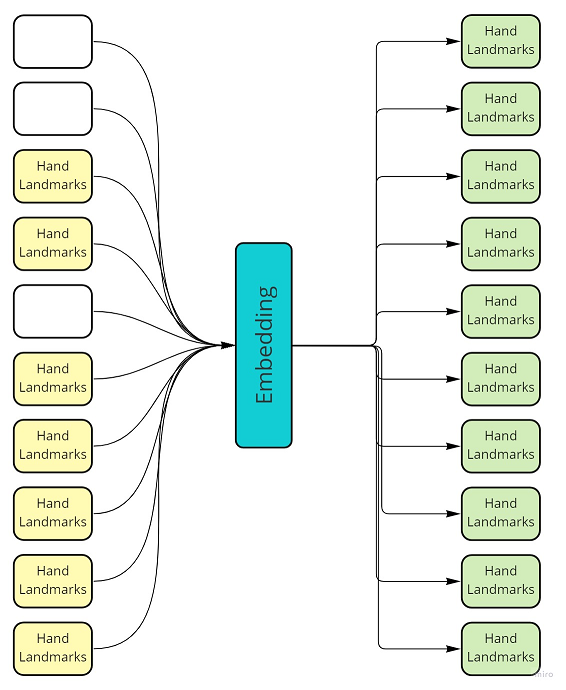 Слева есть выбитые элементы, справа мы их восстановили
Слева есть выбитые элементы, справа мы их восстановили
Классификация действий
Если у вас есть всего несколько целевых действий — то даже по зашумленным данным можно предсказать их, и уйти от точного восстановления скелета.
 Восстановить действия можно через One shot action recognition
Восстановить действия можно через One shot action recognition
Небольшой пример
Чтобы показать что работа с временной компонентой это просто — я сделал небольшой пример. Не используйте его в проде! Он очень простой и сделан только для демонстрации принципа и эффекта.
Для реальных данных нужно делать сложную генерацию, использовать более хитрые активации, и.т.д.
Итак, для простейшего примера мы можем использовать полносвязную сеть:
И в ходе обучения нужно удалить случайные элементы трека:
Добавим немного кода для визуализации и, как-то начинает работать:
Надеюсь это как-то поможет;)
P.S.
Если вам понравилось — подписывайтесь на мой каналы где я рассказываю про похожие проблемы сильно больше. Telegramm, VK, Linkedin, Youtube
А вот тут есть эта статья в формате видео:
