Как стажировка в большой компании может преобразить студенческий проект

Добрый день! Меня зовут Дмитрий Грязнов, я студент УрФу и начинающий разработчик.
Вместе с товарищами мы подумали, что всем студентам и школьникам, которые ищут в интернете информацию, был бы полезен сервис, который может делать смысловую выжимку из текста любого объёма. Мы решили разработать именно такое приложение и выступить с этой идеей на конкурсе «Большие вызовы для студентов». Собрали ансамбль моделей, изучили, много чего переработали.
Коротко: мы используем пайплайн из сжимающих T5, Pegasus, экстракции TextRank, парафразер Bart. Сначала один алгоритм определяет вес каждого предложения и передаёт на вход абстрактивной модели 20% самых значимых предложений. А затем второй перефразирует полученный текст, чтобы сделать его более связанным. Очень много интеграционного кода и тюнинга, чтобы это всё заработало нормально. Сейчас расскажу, как дело было.
Что мы имели до стажировки
В самом начале у нас не было ничего, кроме общей идеи о том, что проект будет посвящён самореализации текста, и только по ходу работы появилась точная направленность: сервис, умеющий сокращать статьи любого объёма. Эта функция будет очень полезна школьникам, студентам и всем, кто собирает какую-то конкретную информацию, так как поможет тратить меньше времени на чтение.
Мы начали работать над ним в ноябре 2022 года, когда готовились к конкурсу «Большие вызовы для студентов» от Сириуса. Когда его объявили, я позвал участвовать всех моих товарищей, у которых уже был опыт разработки.
В нашей команде я отвечаю за PM и проработку UX, Вениамин Бобаков разрабатывает алгоритм сжатия текста без потери смысла, Равиль Камалиев отвечает за frontend и backend, а Алиса Миронова — наш дизайнер.
Мы сделали проект, написали заявку, отправили документы на конкурс и успешно прошли отборочный этап. Представлять команду в Сириус отправилась Алиса — она успешно защитила проект, и его заметили.
Вот так мы и попали на стажировку в Т1.
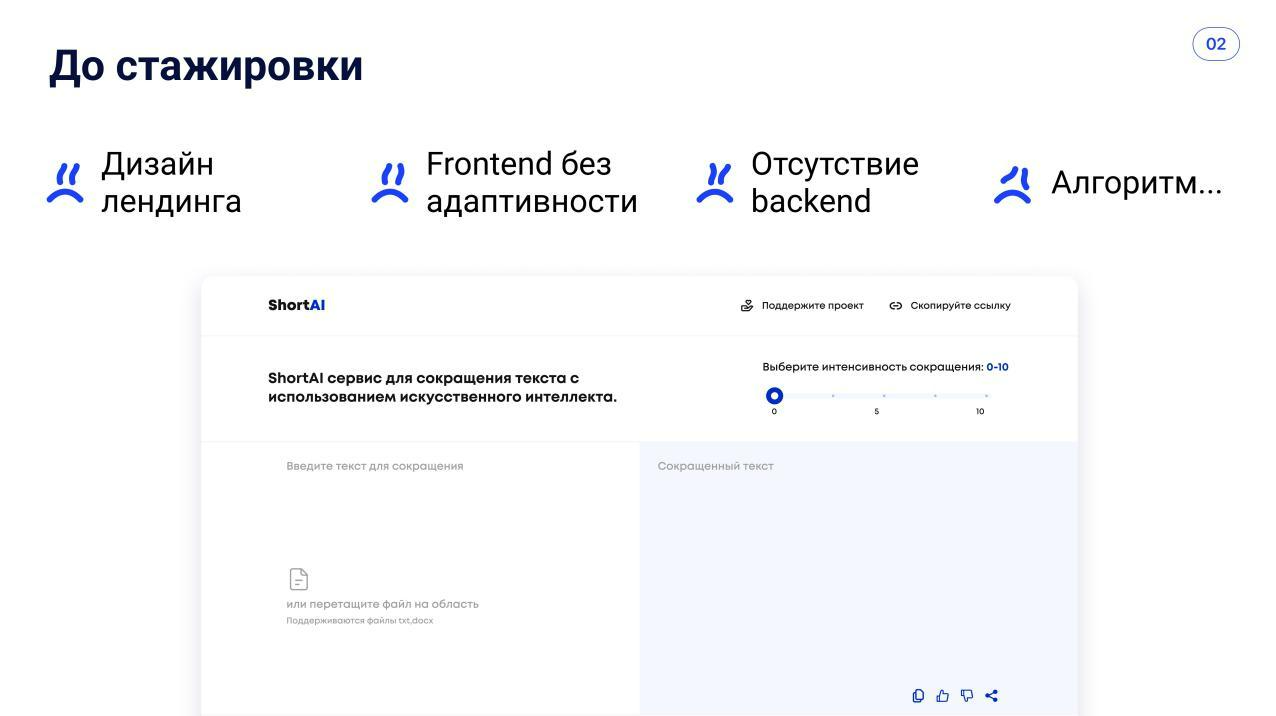

К этому моменту готово было, прямо скажем, немного: сама идея, которой мы горели, да очень сырые зачатки сайта и алгоритма. Вот и всё. С этим мы пришли в Т1.
Как проходила стажировка?
Каждое наше утро начиналось с лекции: по технической работе, софт-скиллам, экономике, управлению командой и так далее. Несмотря на то что у всех участников команды уже был опыт работы над разными проектами, мы получили массу новой полезной информации. Очень крутыми, например, оказались лекции про базы данных, CICD, автоматизацию разработки, девопс, кастдев. Некоторые материалы мы применяли сразу же, по ходу работы. Например, именно благодаря им в конце стажировки удалось посчитать примерную экономику проекта.
Кроме того, у каждого из нас был свой ментор, а то и несколько — у Вени их было вообще пять. В любой момент мы могли позвонить кому-то из наставников, чтобы задать совершенно любой вопрос. Впрочем, и сейчас, когда стажировка уже закончилась, мы продолжаем общаться и советоваться с ними. Это очень приятно, что в такой большой и технологичной компании к нам отнеслись на равных и очень внимательно.
Что мы успели сделать за две недели стажировки
Стажировка — это маленькая жизнь. Сказать, что это были очень продуктивные две недели, — всё равно что скромно промолчать.
Во-первых, была проделана большая теоретическая работа. Мы перечитали уйму научных статей. Выяснили, какие тренды в области работы с текстом существуют, какие алгоритмы или их связки применяются. На это ушло очень много времени. Но и практически мы тоже работали.

Когда пришла пора уезжать, у нас были полностью готовы:
МVP.
Дизайн веб-интерфейса и сайта.
Сам сайт.
APl.
Front, который общается через APl с back«ом, где лежит алгоритм для сжатия текста.
Aрхитектура back«а, простроенная для дальнейшего масштабирования (мы использовали микросервисы, это оказалось очень удобно).
Защита от DDoS-атак (CloudFlare — самое простое, быстрое и дешёвое решение).
Бизнес-план по внедрению сервиса и дорожная карта для дальнейших исследований построения модели.
Сейчас у нас есть почти готовая базовая версия продукта и намечены пути развития сервиса. А ещё есть отличная команда, которая может плодотворно работать как удалённо, так и в офлайн-режиме.
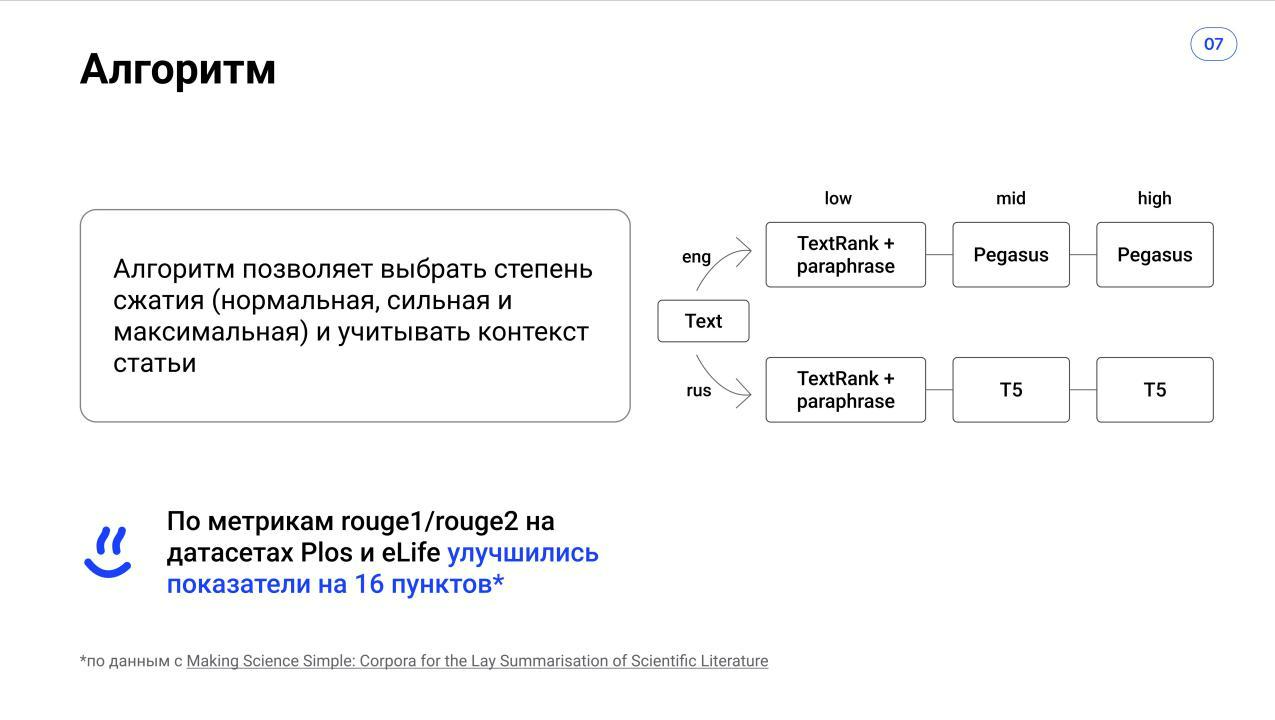
Как работает наш алгоритм
Наше приложение делает связный и красивый краткий пересказ русского или английского текста без потери смысла.
Обработать естественный язык непросто, и создание качественной модели требует достаточно много ресурсов. Особенно если учесть, что главная фича проекта — выбор степени сжатия текста. В готовых решениях ничего подобного нет, и часть алгоритма команда писала самостоятельно.
Мы используем несколько предобученных языковых моделей. Перед подачей текста на них программа классифицирует язык, на котором он написан, с помощью n-грамм. С русскими текстами для сильного сжатия работает T5, для среднего — Pegasus, а для слабого — экстрактивный алгоритм TextRank в связке с Bart парафразером. С английскими текстами для сильного и среднего сжатия мы также взяли T5 и Pegasus, обученные на датасетах Cnn/DalyMail и PubMed, а парафразер сделали на базе T5.
Берем текст
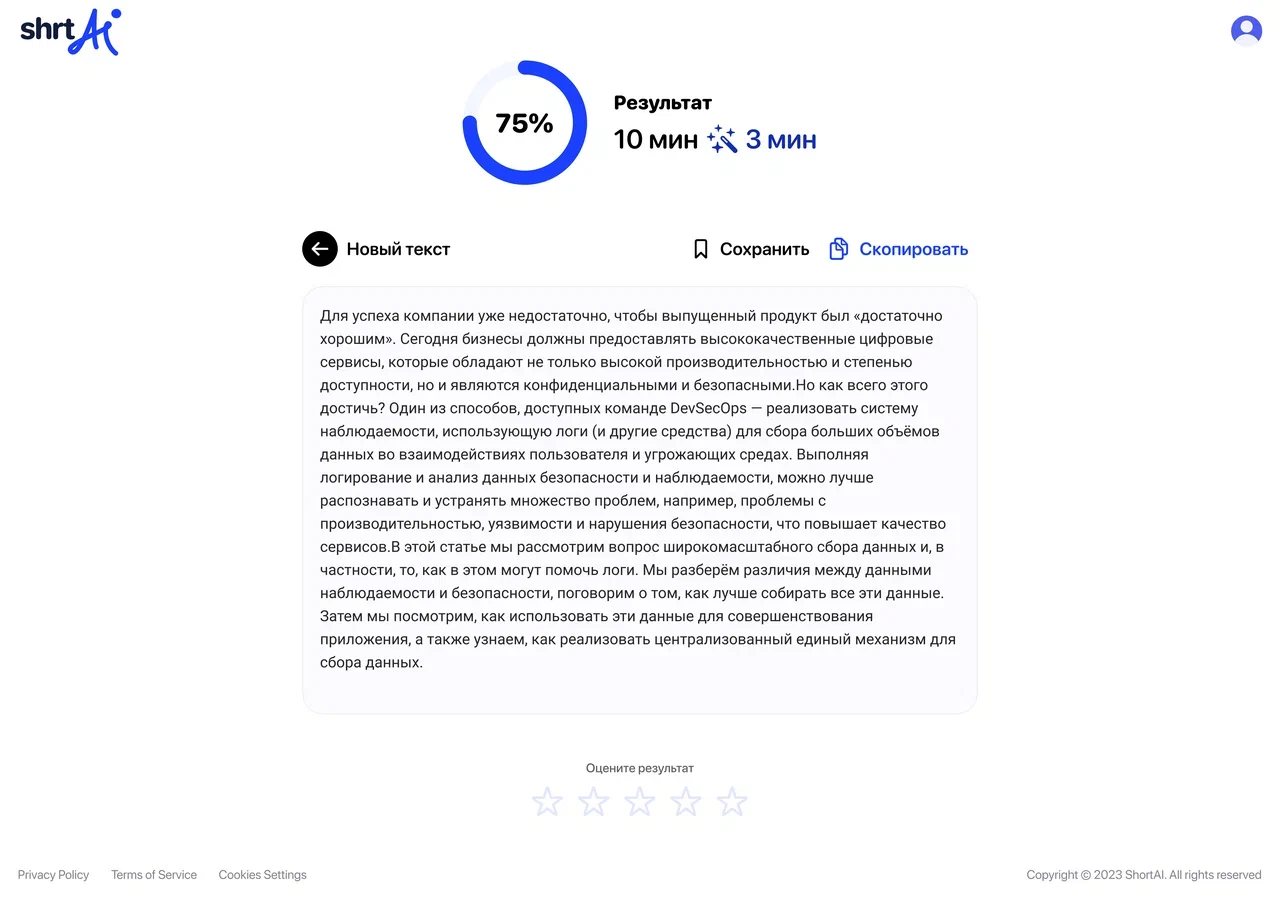
Сжимаем — и вот результат. Три минуты на чтение вместо десяти, смысл не потерян
Сейчас мы строим дополнительную собственную модель, заточенную на научные тексты с большим количеством цифр, фактов, дат, формул, ссылок на изображения и так далее, поскольку наша целевая аудитория — это школьники и студенты, которые будут с ними плотно работать. Классические общедоступные модели делать этого пока не умеют.
Наши ближайшие планы:
Сбор датасета для реферирования статей на русском языке.
Суммаризация данных из таблиц и графиков.
Суммаризация с учётом цитирования.


Главные инсайты стажировки
Когда тебя отрывают от привычной жизни, изолируют от всего мира и на две недели с головой погружают в обучение и работу над проектом, домой возвращаешься немного другим человеком. У тебя есть команда, есть чёткая цель, есть наставники и ещё есть дело, которое ты любишь. А что ещё нужно?
Я почувствовал, что мы попали туда, где очень интересно и где мы сможем многому научиться, уже в самый первый день, хотя он был посвящён только знакомству и презентации проекта. Так в результате и получилось — мы все сильно выросли за эти две недели.
В последние три года я был наставником на школьных проектах и немного зациклился на них: там всё очень понятно и каждый раз происходит примерно одно и то же. Сейчас же я чувствую, что вышел на более высокий уровень, узнал много нового и познакомился с более серьёзными и приближенными к реальности технологиями. А ещё с удивлением узнал про себя, что, несмотря на то что я ехал на стажировку как frontend с чётким планом действий, оказалось, что у меня получается быть project«ом, а иногда даже product«ом.
В очередной раз подтвердилось, что нужно очень много учиться, чтобы применять высокие технологии. Важно хорошо знать математику и уметь находить нужную информацию. От этого напрямую зависит скорость работы. Не откровение, конечно, но мы заново прочувствовали это утверждение на себе. Неожиданно важным оказалось умение читать сложные научные статьи вместо текстов на популяризаторских ресурсах. Времени, конечно, уходит больше, но зато и знания это даёт намного более глубокие.
Серьёзно задуматься заставила информация о том, что у нас в России очень избалованные пользователи. Если сервер долго не отвечает и человек не получает ответа в первую же секунду после обращения, он просто не будет пользоваться сервисом.
И ещё один важный инсайт: оказывается, можно за две недели сделать совершенно работоспособный продукт, готовый к продаже!
Чем мы заняты сейчас?
Мы вернулись со стажировки, отдохнули, выдохнули. И наметили дальнейший план действий по развитию и коммерциализации проекта.

Продавать его мы, правда, пока не начали. Дело в том, что продукт содержит часть с ML, которая требует доработки. Так получилось, что Веня уже знаком с ИИ, поэтому мы использовали именно это решение. На стажировке он усердно занимался теорией, и на реализацию самого алгоритма осталось не так уж много времени. Поэтому мы взяли предобученные модели и теперь собираем основной датасет и обучаем программу.
Но зато у нас уже есть тестеры, которые пользуются сервисом и отлавливают все его баги и фичи.
Кроме того, мы сейчас доделываем мобильную версию сайта, нам очень важно создать качественный адаптив.
Как только всё будет отлажено, мы запустим рекламу в мессенджерах: её соотношение цена/качество нам отлично подходит.
Следующим шагом в развитии должно стать использование алгоритма не только на нашем сайте, но и на других платформах, так что мы активно ищем партнёров. Наш сервис будет интересен не только школьникам и студентам, он ещё отлично впишется в сайты СМИ, издательств или же интернет-ресурсы с длинными интересными статьями (наподобие habr или medium).
Мы будем предлагать им установить наше APl по подписке или единоразовой оплате и интегрировать сервис в сайт в виде отдельного окошка, где можно посмотреть краткое содержание любой статьи.
Во время стажировки мы посчитали финансовую модель проекта на ближайшие пять лет. В наших планах выйти на 2 млн выручки к концу 2027 года.
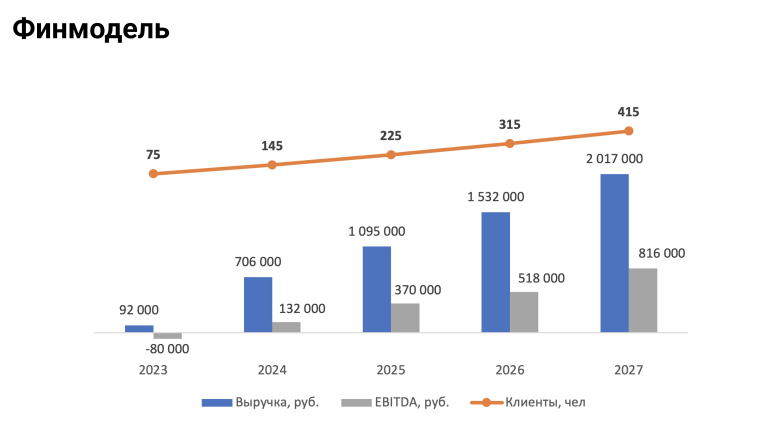
Наша финансовая модель выглядит так
Если подытожить
Я очень благодарен компании Т1 за стажировку, помощь, идеи и советы — всё то, что помогло нам идею превратить в продукт, пусть ещё и не до конца завершённый.
И я уверен, что мы придумали классный, очень полезный сервис и у него большое будущее, что у нас получится следовать нашей финмодели и набрать большую пользовательскую базу.
