Как стать GPU-инженером за час
Нужно ли iOS-разработчику, не занимающемуся играми, уметь работать с GPU? Нужно ли ему вообще знать о том, что в айфоне есть GPU? Многие успешно работают в iOS-разработке, никогда не задумываясь об этой теме. Но GPU может быть полезен как для 3D-графики, так и для других задач, в ряде случаев оставляя CPU позади.
Когда на конференции Mobius 2017 Moscow Андрей Володин (Prisma AI) рассказал об использовании GPU в iOS, его доклад стал одним из фаворитов конференции, получив высокие оценки зрителей. А теперь на основе этого доклада мы подготовили хабрапост, позволяющий получить всю ту же информацию текстом. Интересно будет даже тем, кто не работает с iOS: доклад начинается с вещей, не привязанных конкретно к этой платформе.
Осторожно, трафик: под катом очень много изображений со слайдов.
План таков. Сначала посмотрим на историю компьютерной графики: с чего всё начиналось и как мы пришли к тому, что есть сейчас. Затем разберёмся, как происходит рендеринг на современных видеокартах. Что предлагает нам Apple как вендор железа. Что такое GPGPU. Почему Metal Compute Shaders — крутая технология, изменившая всё. И в самом конце поговорим про hype train, то есть популярное сейчас: Metal Performance Shaders, CoreML и тому подобное.

Начнём с истории
Первой известной системой с отдельным железом для видео стала Atari 2600. Это довольно известная классическая игровая консоль, выпущенная в 1977-м. Её особенностью было то, что объём оперативной памяти составлял всего 128 байт, причём доступных не только разработчику: это было и под игру, и под операционную систему самой приставки, и под весь call stack.
В среднем игры рендерились в разрешении 160×192, а в палитре было 128 цветов. Несложно подсчитать, что для хранения одного кадра игры требовалось в разы больше оперативной памяти. Поэтому эта консоль вошла в историю как один большой хак: вся графика в ней генерировалась в режиме реального времени (в прямом смысле этого слова).

На тот момент телевизоры работали с лучевыми пушками, через электронные головки. Изображение сканировалось построчно, и разработчики должны были по мере того, как телевизор сканирует изображение через аналоговый кабель, говорить ему, какой цвет текущего пикселя нужно рисовать. Таким образом изображение появлялось на экране полностью.

Другой особенностью этой консоли было то, что на железном уровне она поддерживала одновременно только пять спрайтов. Два спрайта для игрока, два для так называемых «ракет» и один спрайт для шарика. Понятное дело, что для большинства игр этого недостаточно, потому что интерактивных объектов на экране, как правило, гораздо больше.

Поэтому там использовалась техника, впоследствии вошедшая в историю под названием «гонка с лучом». По мере того, как луч сканировал изображение с приставки, те пиксели, которые уже были нарисованы, оставались на экране до следующего кадра. Поэтому разработчики сдвигали спрайты, пока двигался луч, и таким образом могли отрисовывать больше пяти объектов на экране.
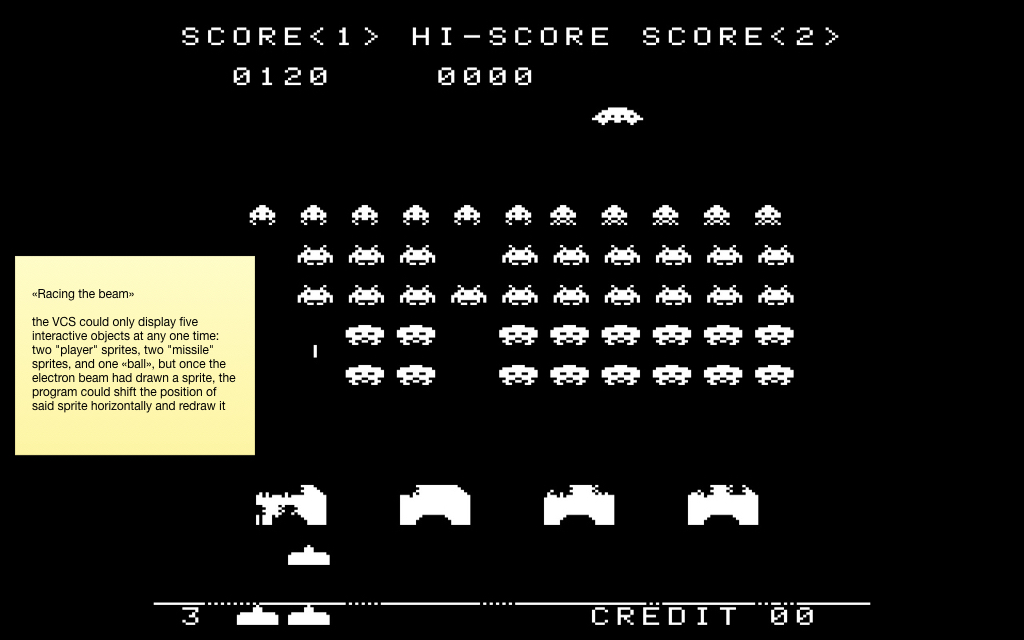
Это скриншот из знаменитой игры Space Invaders, в которой интерактивных объектов гораздо больше пяти. Ровно таким же способом рисовались эффекты вроде параллакса (с волнообразными анимациями) и прочие. По мотивам всей этой лихорадки была написана книга «Racing the Beam». И из неё же я взял вот эту любопытную иллюстрацию:

Дело в том, что телевизор сканировал изображение в режиме нон-стоп, и у разработчиков не оставалось времени считать нажатие на джойстике, посчитать какую-то игровую логику и т.д. Поэтому разрешение делали выше, чем на экране. И зоны «vertical blank», «overscan» и «horizontal blank» — это фальшивое разрешение, которое телевизор сканировал, но в это время не отдавался видеосигнал, а разработчики считали игровую логику. И в игре Pitfall от Activision была настолько сложная по тем временам логика, что им приходилось всё время отрисовывать ещё кроны деревьев вверху и чёрную землю внизу, чтобы было больше времени её обсчитать.

Следующим этапом развития стала Nintendo Entertainment System в 1983-м, и там были схожие проблемы: уже была 8-битная палитра, но всё так же не было frame buffer. Зато там был PPU (picture processing unit) — отдельный чип, который отвечал за видеоряд, и там использовалась тайловая графика. Тайлы — это такие кусочки пикселей, чаще всего они были 8×8 или 8×16. Поэтому все игры того периода выглядят немножко квадратно:

Система сканировала кадр такими блоками и анализировала, какие части изображения нужно рисовать. Это позволяло очень серьёзно экономить видеопамять, а дополнительным плюсом был collision detection «из коробки». В играх появилась гравитация, потому что можно было понимать, какие квадратики с какими пересекаются, можно было собирать монетки, отнимать жизни, когда мы соприкасаемся с врагами, и так далее.

Впоследствии началась 3D-графика, но поначалу она была безумно дорогой, в основном использовалась в авиасимуляторах и каких-то энтерпрайзных решениях. Считалась на вот таких вот страшных, огромных чипах и до обычных потребителей не дошла.

Всем известная компания NVidia в 1999 году с выпуском нового устройства ввела термин GPU (graphics processing unit). На тот момент это был очень узкоспециализированный чип: он решал ряд задач, позволявших немного ускорять 3D-графику, но его нельзя было запрограммировать. Можно было только сказать, что делать, и он возвращал ответ по каким-то заранее встроенным алгоритмам.

В 2001 году та же NVidia выпустила GeForce 3 с пакетом GeForceFX, в котором впервые появились шейдеры. О них мы сегодня обязательно поговорим. Именно этот концепт перевернул всю компьютерную графику, хотя на тот момент это всё ещё программировалось на ассемблере и было достаточно сложно.
Главное, что случилось после этого — наметился тренд. Вы наверняка слышали о такой метрике производительности железа, как флопсы. И стало понятно, что с течением времени видеокарты по сравнению с центральными процессорами просто улетают в космос по производительности:
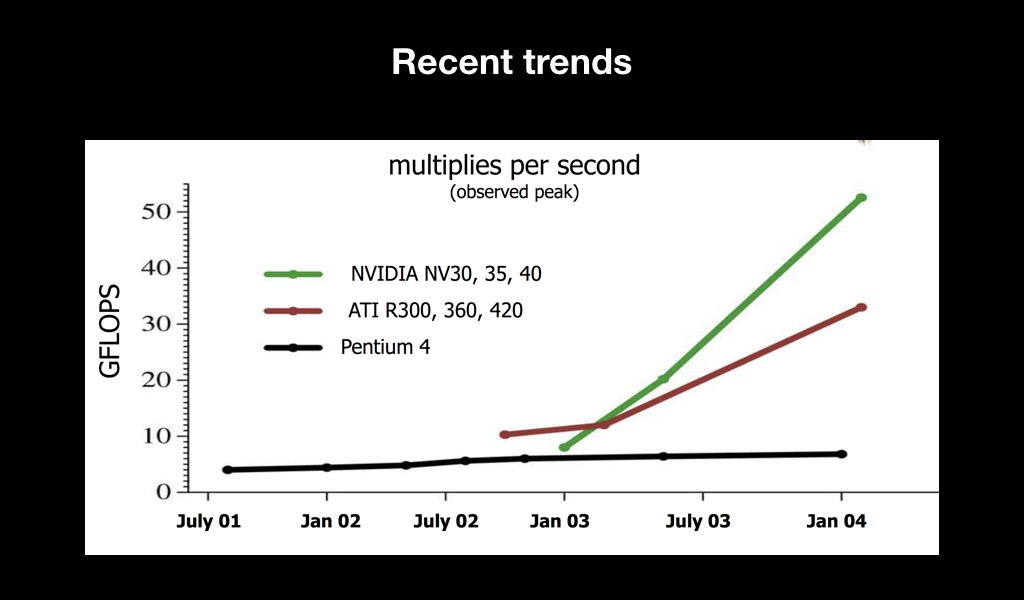
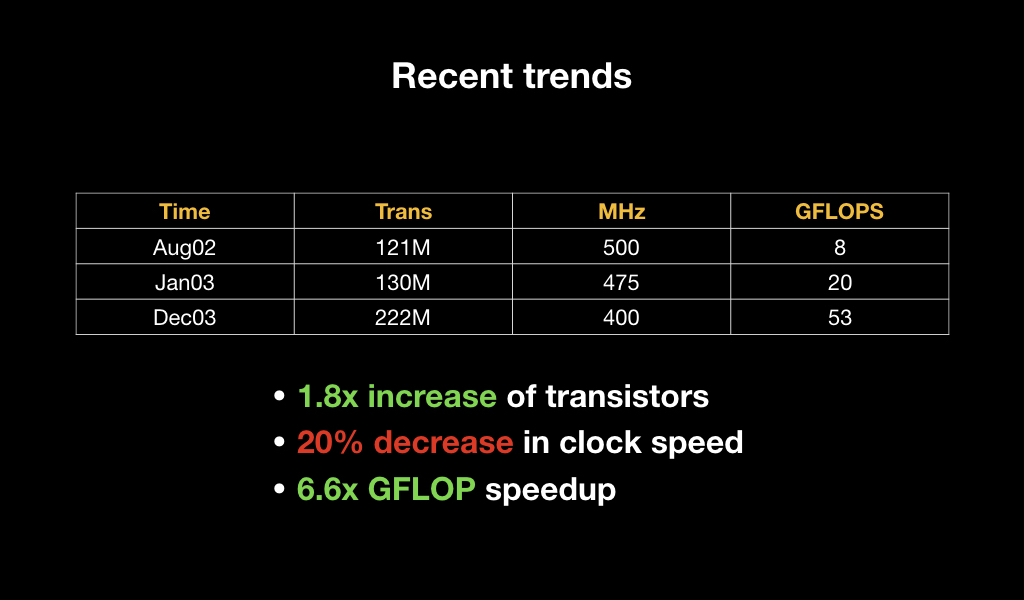
Причём если мы посмотрим на их спецификации, то увидим, что буквально за год количество транзисторов увеличилось в 2 раза, при этом тактовая частота каждого из них снизилась, но общая производительность увеличилась практически в 7 раз. Это говорит о том, что была сделана ставка на параллельность вычислений.
Рендеринг сегодня
Чтобы разобраться, зачем GPU нужно так много считать параллельно, посмотрим, как сейчас происходит рендеринг на большинстве видеокарт — и десктопных, и мобильных.
Для многих из вас может стать главным разочарованием, что GPU — это очень тупая железка. Она может только рисовать треугольники, линии и точки, больше ничего. И она очень оптимизирована для работы с числами с плавающей точкой. Она не умеет считать double и, как правило, очень плохо работает с int. На ней нет никаких абстракций в виде операционной системы и прочего. Это настолько близко к железу, насколько возможно.

По этой причине все 3D-объекты хранятся в виде набора треугольников, на которые чаще всего натянута текстура. Эти треугольники часто называют полигонами (тем, кто играет в игры, знакомы слова вроде «в модельке Кратоса в два раза больше полигонов»).
Для того, чтобы отрендерить это всё, эти треугольники сначала помещаются в игровой мир. Игровой мир — это обычная трёхмерная координатная система, куда мы эти их ставим, и у каждого объекта есть, как правило, своя позиция, поворот, искажение и прочее.

Часто существует такая концепция, как камера, когда мы можем на игровой мир смотреть с разных сторон. Но понятное дело, что на самом деле никакой камеры там нет, и в реальности двигается не она, а весь игровой мир: он поворачивается к монитору так, чтобы вы увидели его в нужном ракурсе.
И последней стадией является проекция, когда эти треугольники попадают к вам на экран.

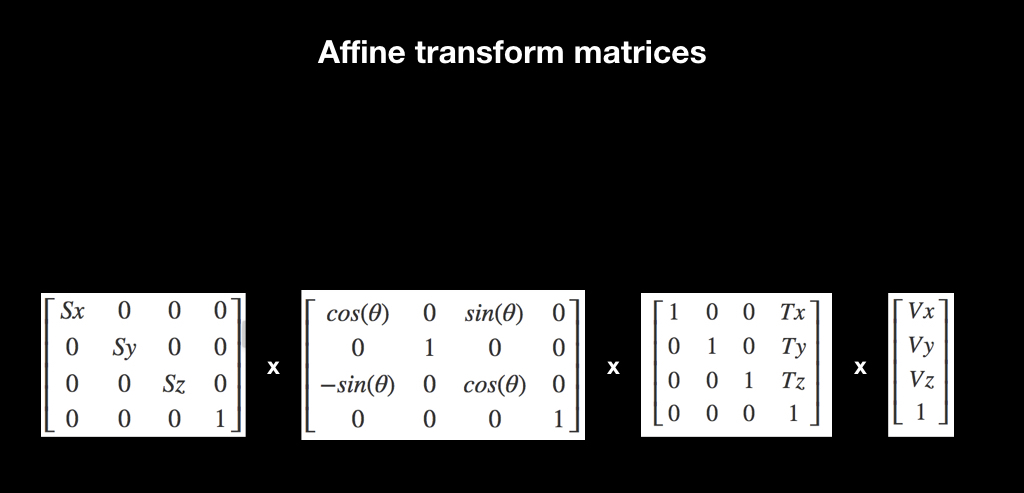
Для всего этого существует прекрасная математическая абстракция в виде аффинных преобразований. Кто работал с UIKit, знаком с этим понятием благодаря CGAffineTransform, там через него сделаны все анимации. Существуют разные матрицы аффинных преобразований, вот для масштаба, для поворота и для переноса:
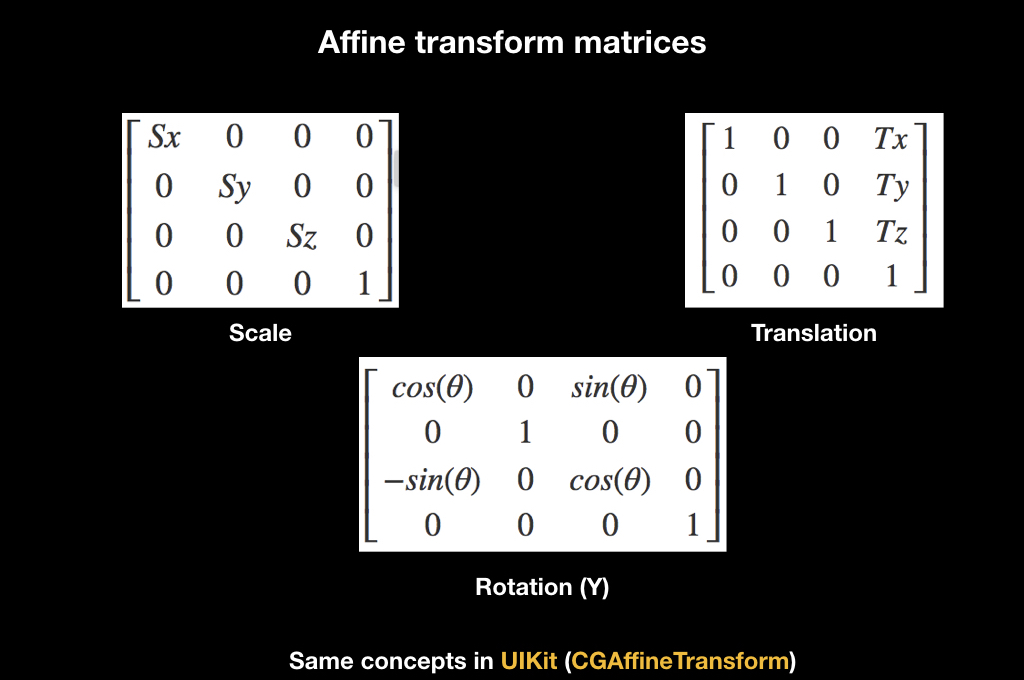
Работают они так: если вы умножите матрицу на какой-то вектор, то к нему применится трансформация. Например, матрица Translation при умножении смещает вектор.
И ещё один интересный факт, связанный с ними: если перемножить несколько таких матриц, а потом умножить их на вектор, то эффект накапливается. Если сначала будет scale, потом поворот, а потом перенос, то при применении всего этого к вектору делается всё это сразу.
Для того, чтобы делать это эффективно, изобрели вертексные шейдеры. Вертексные шейдеры — это такая маленькая программка, которая запускается для каждой точки вашей 3D-модели. У вас есть треугольники, в каждом по три точки. И для каждой из них запускается вертексный шейдер, который принимает на вход позицию вектора в системе координат 3D-модели, а возвращает в системе координат экрана.
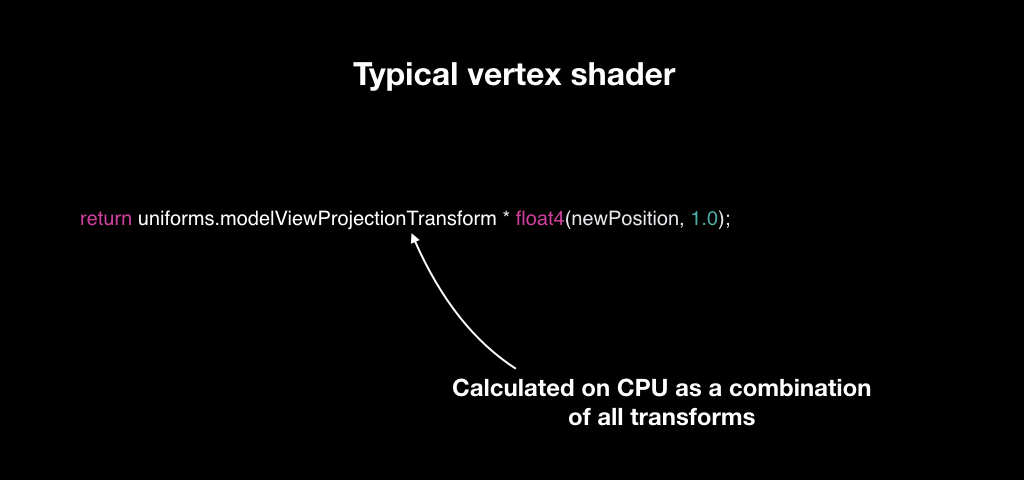
Чаще всего это работает следующим образом: мы подсчитываем для каждого объекта уникальную матрицу преобразований. У нас есть матрица камеры, матрица мира и матрица объекта, мы перемножаем их все и отдаём вертексному шейдеру. И для каждого вектора он берёт, умножает её и возвращает новую.
Наши треугольники появляются на экране, но это всё ещё векторная графика. И тогда включается в игру растеризатор. Он делает очень простую вещь: берёт пиксели на экране и накладывает пиксельную решётку на вашу векторную геометрию, выбирая те пиксели, которые пересекаются с вашей геометрией.
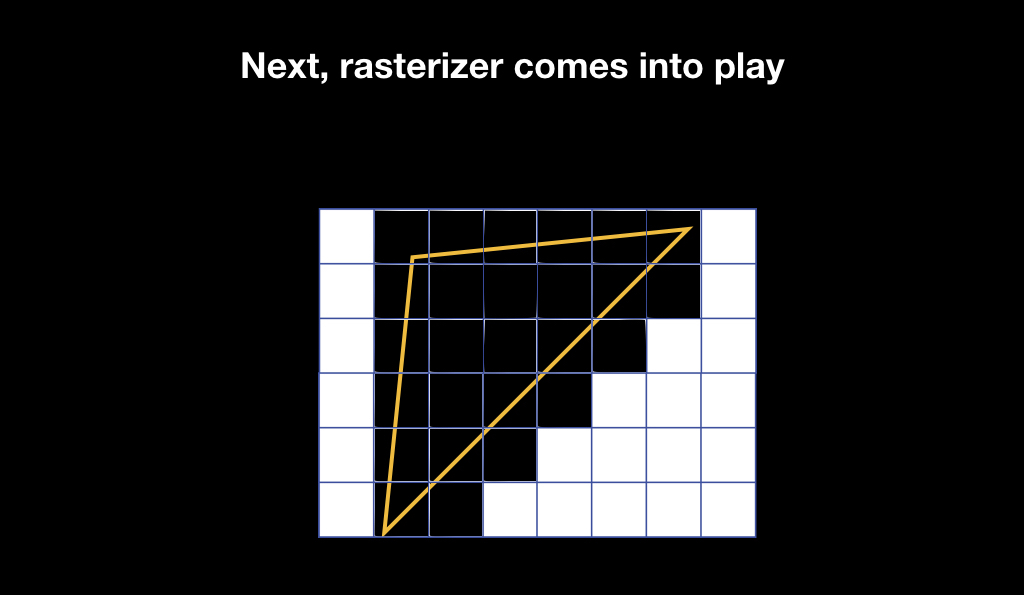
После этого запускаются фрагментные шейдеры. Фрагментные шейдеры — это тоже маленькая программка, она запускается уже для каждого пикселя, который попадает в зону вашей геометрии, и возвращает цвет, который впоследствии будет отображён на экране.
Для того, чтобы объяснить, как это работает, представьте, что мы будем рисовать два треугольника, которые покрывают весь экран (просто для наглядности).

Самый простой фрагментный шейдер, который можно написать — это шейдер, который возвращает константу. Например, красный цвет, и весь экран становится красным. Но это достаточно скучно.
Фрагментные шейдеры принимают на вход координату пикселя, поэтому мы можем, например, посчитать расстояние до центра экрана, и это расстояние использовать в качестве красного канала. Таким образом на экране появится градиент: пиксели близко к центру будут чёрными, потому что расстояние будет стремиться к нулю, а по краям экрана будут красными.

Дальше мы можем добавить, например, униформу. Униформа — это константа, которую мы передаём фрагментному шейдеру, а он применяет её одинаково для каждого пикселя. Чаще всего такой униформой становится время. Как известно, время хранится в виде количества секунд с определённого момента, поэтому мы можем считать синус от него, получая какую-то величину.

И если мы будем умножать наш красный канал на эту величину, получится динамическая анимация: когда синус времени будет обращаться в ноль, всё становится чёрным, когда единица — возвращается на свои места.
Само по себе написание шейдеров переросло в целую культуру. Вот эти изображения нарисованы с помощью математических функций:

В них не используются 3D-модели или текстуры. Это всё чистая математика.
В 1984 году некто Пол Хекберт даже запустил челлендж, когда он раздавал визитки с кодом, запустив который, можно было получить вот такую картинку:

И этот челлендж жив до сих пор на SIGGRAPH, CVPR, крупных конференциях в Калифорнии. До сих пор можно увидеть визитки, которые что-то печатают.
Но вряд ли это всё вошло в массы только из-за того, что это красиво. И чтобы понять, какие возможности это всё открывает, посмотрим, что можно сделать с обычной сферой. Допустим, у нас есть 3D-модель сферы (понятно, что на самом деле это не сфера, а множество треугольников, с какой-то степенью приближения образующее шар). Мы возьмем вот такую текстуру, которую часто называют гладким шумом:

Это просто какие-то рандомные пиксели, которые постепенно перетекают из белого в чёрный. Мы натянем эту текстуру на наш шар, и в вертексном шейдере сделаем следующее: точки, попадающие на более тёмные пиксели, будем смещать слабее, а точки на белых пикселях смещать сильнее.
И примерно то же будем делать во фрагментном шейдере, только несколько иначе. Мы возьмем текстуру градиента, изображённую справа:

И чем белее пиксель, тем будем читать выше, а чем темнее пиксель, который попадает, тем ниже.
А каждый кадр будем немножко смещать зону чтения и зациклим это. В результате из обычной сферы получится анимированный фаербол:

Применение этих шейдеров перевернуло мир компьютерной графики, потому что открыло огромные возможности для создания крутых эффектов путём написания 30–40 строчек кода.
Весь этот процесс повторяется несколько раз, для каждого объекта на экране. На следующем примере вы можете обратить внимание, что GPU не умеет рисовать шрифты, потому что ему не хватает точности, и каждый символ изображается с помощью двух треугольников, на которые натягивается текстура буквы:

После этого получается кадр.
Что предоставляет Apple
Теперь поговорим о том, что предоставляет нам Apple как вендор не только софта, но и железа.

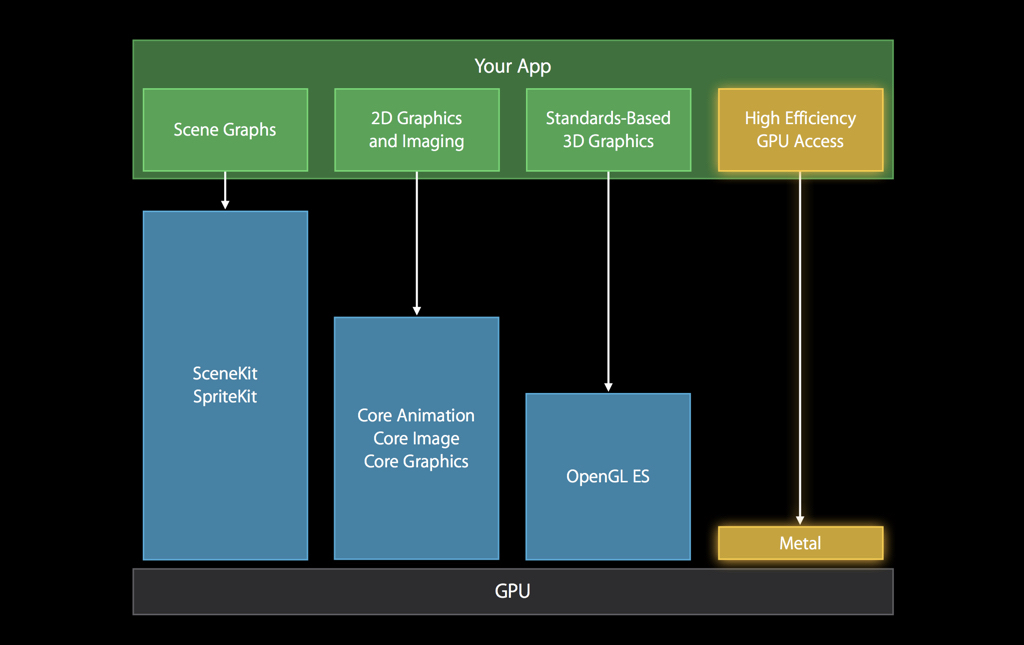
В целом у нас всегда было всё хорошо: с самого первого iPhone поддерживается стандарт OpenGL ES, это такое подмножество десктопного OpenGL для мобильных платформ. Уже на первых iPhone появлялись 3D-игры, которые по уровню графики были сопоставимы с PlayStation 2, и все начали говорить о революции.

В 2010 году вышел iPhone 4. Там была уже вторая версия стандарта, и Epic Games очень хвастались своей игрой Infinity Blade, наделавшей много шума.
А в 2016-м вышла третья версия стандарта, которая оказалась уже никому особо не интересной.

Почему? За это время было выпущено уже очень много фреймворков под экосистему, низкоуровневых, опенсорсных — движки от самой Apple, движки от крупных вендоров:

В 2015-м организация Khronos, которая сертифицирует стандарт OpenGL, анонсировала Vulkan — следующего поколения графических API. И изначально Apple входила в рабочую группу по этому API, но вышла из неё. Главным образом из-за того, что OpenGL, вопреки распространённому заблуждению — это не библиотека, а стандарт. То есть, грубо говоря, это большой протокол или интерфейс, который говорит, что на устройстве должны быть вот такие функции, которые с железом делают то-то и то-то. И вендор должен сам их имплементировать.
А так как Apple славится своей жёсткой интеграцией софта и железа, любая стандартизация вызывает определённые сложности. Поэтому вместо поддержки Vulkan компания в 2014 году анонсировала Metal, как бы намекающий своим названием «очень близко к железу».

Это был API для графики, сделанный исключительно для железа от Apple. Теперь уже понятно, что это было сделано для выпуска своих собственных GPU, но на тот момент об этом ходили только слухи. Сейчас уже не осталось устройств, которые не поддерживают Metal.
На диаграмме от самой Apple видно сравнение оверхеда — даже по сравнению с OpenGL у Metal перформанс гораздо лучше, доступ к GPU гораздо быстрее:
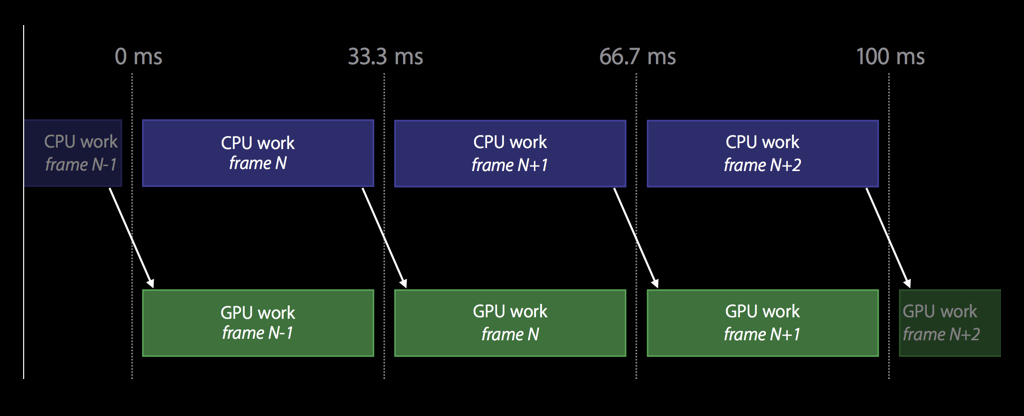
Там были все самые последние фичи вроде тесселяций, подробно их рассматривать сейчас не станем. Основная идея была в том, чтобы сместить большую часть работ в стадию инициализации приложения и не делать много повторяющихся вещей. Другой важной особенностью стало то, что эта API очень бережно относится ко времени центральном процессора, которым вы располагаете.

Поэтому, в отличие от OpenGL, здесь работа устроена так, что CPU и GPU работают параллельно друг с другом. Пока CPU читает кадр номер N, в это время GPU рендерит предыдущий кадр N-1, и так далее: вам не нужно синхронизироваться, и пока GPU что-то рендерит, вы можете продолжать работать над чем-то полезным.
У Metal достаточно тонкий API, и это единственный графический API, который объектно-ориентирован.
Metal API
И как раз по API мы сейчас и пройдёмся. В его сердце лежит класс MTLDevice, представляющий собой один GPU. Чаще всего на iOS его можно получить с помощью функции MTLCreateSystemDefaultDevice.

Несмотря на то, что его получают через глобальную функцию, не нужно относиться к этому классу, как к синглтону. На iOS видеокарта действительно только одна, но на Mac тоже есть Metal, и вот там может быть несколько видеокарт, а вы захотите использовать какую-то конкретную: например, интегрированную, чтобы экономить батарейку пользователя.
Необходимо учитывать, что Metal очень отличается по архитектуре от всех остальных фреймворков Apple. В нём сквозная dependency injection, то есть все объекты создаются в контексте других объектов, и очень важно следовать этой идеологии.
У каждого девайса есть своя программная очередь MTLCommandQueue, которую можно получить с помощью метода makeCommandQueue.
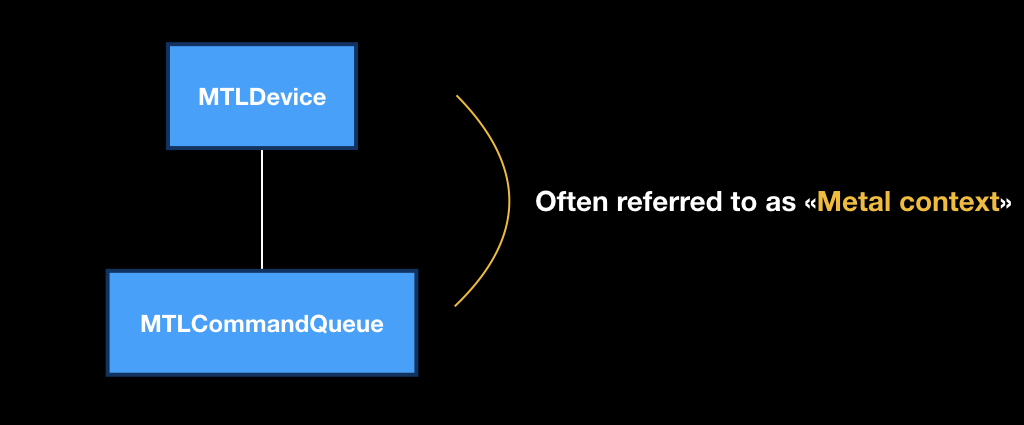
Эта пара из девайса и программной очереди очень часто называется «контекстом Metal», то есть в контексте двух этих объектов мы будем делать все наши операции.
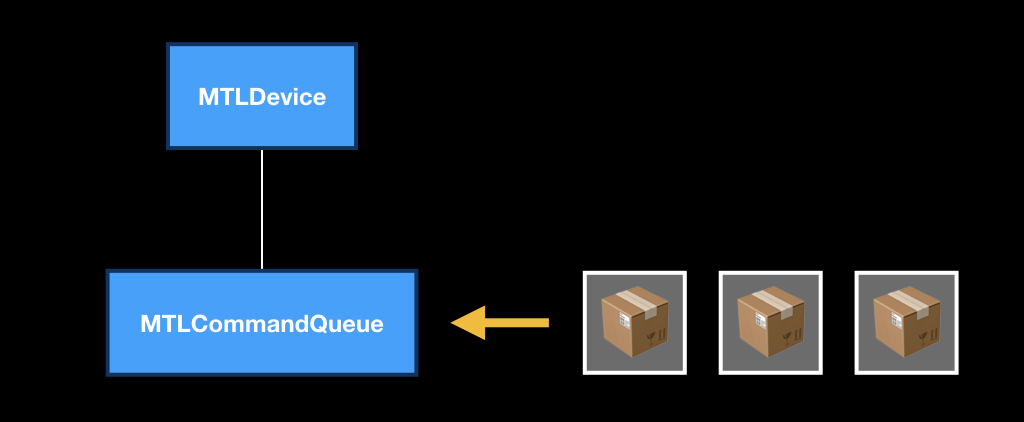
Сама MTLCommandQueue работает как обычная очередь. В неё приходят «коробочки», в которых лежат указания «что делать с GPU». Как только девайс освобождается, берётся следующая коробочка, а остальные пододвигаются. При этом команды в эту очередь кладёте не только вы из вашего потока: их также кладёт сама iOS, какие-то UIKit-фреймворки, MapKit и так далее.
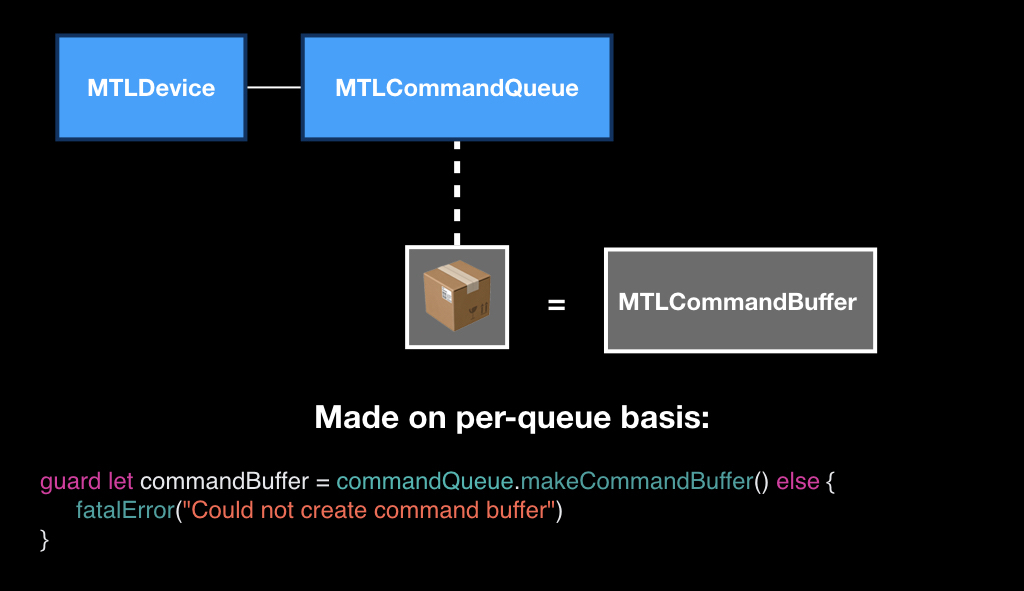
Сами эти коробочки представляют собой класс MTLCommandBuffer, и они тоже создаются в контексте очереди, то есть у каждой очереди свои пустые коробочки. Вы вызываете специальный метод, как бы говоря: «дай нам пустую коробку, мы её будем наполнять».
Наполнять эту коробку можно тремя видами команд. Render-командами для отрисовки примитивов. Blit-командами — это команды для стриминга данных, когда нам нужно часть пикселей из одной текстуры перевести в другую. И compute-командами, о них поговорим чуть позже.
Для того, чтобы положить эти команды в коробку, существуют специальные объекты, у каждого типа команд свой:
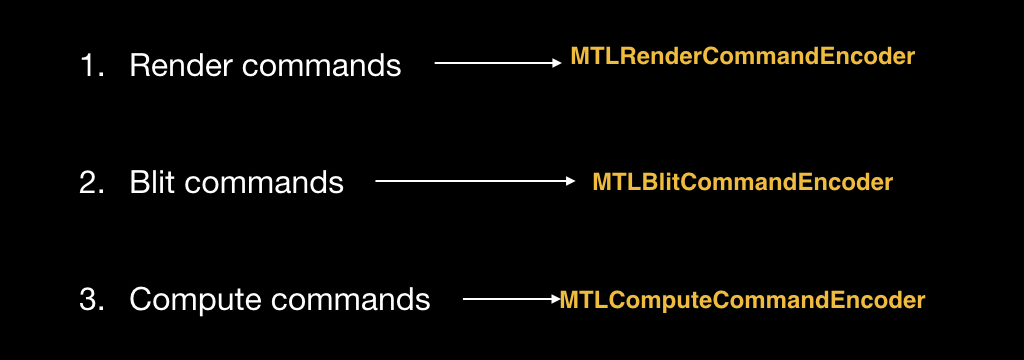
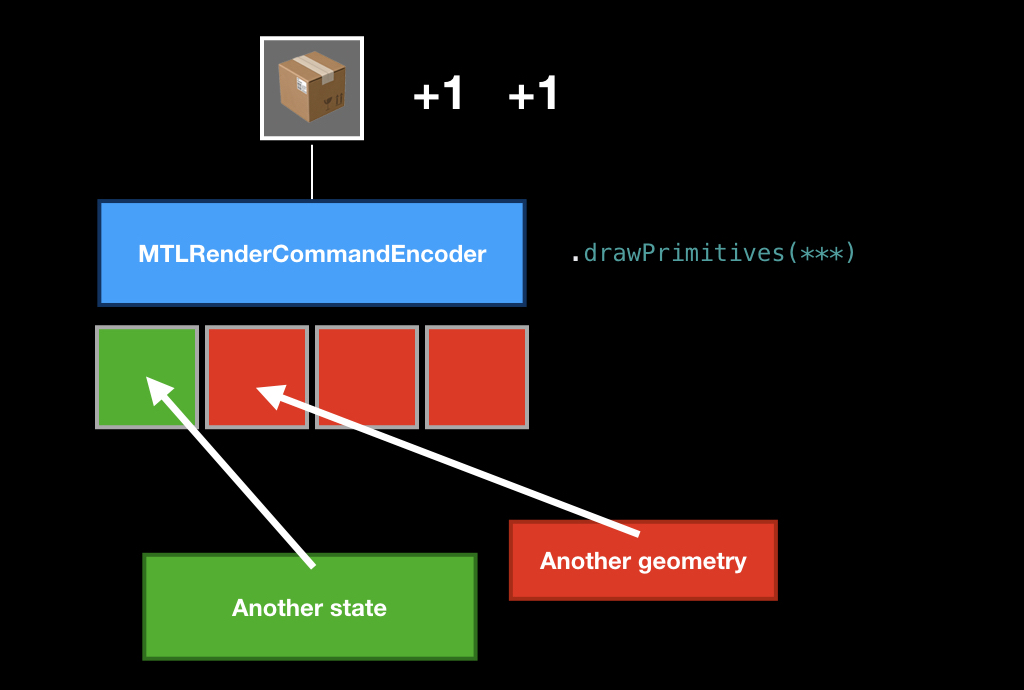
Объекты тоже создаются в контексте коробки. То есть мы получаем коробку от очереди, и в контексте этой коробки создаём специальный объект, который называется Encoder. В данном примере мы будем создавать Encoder для рендер-команды, потому что она самая классическая.
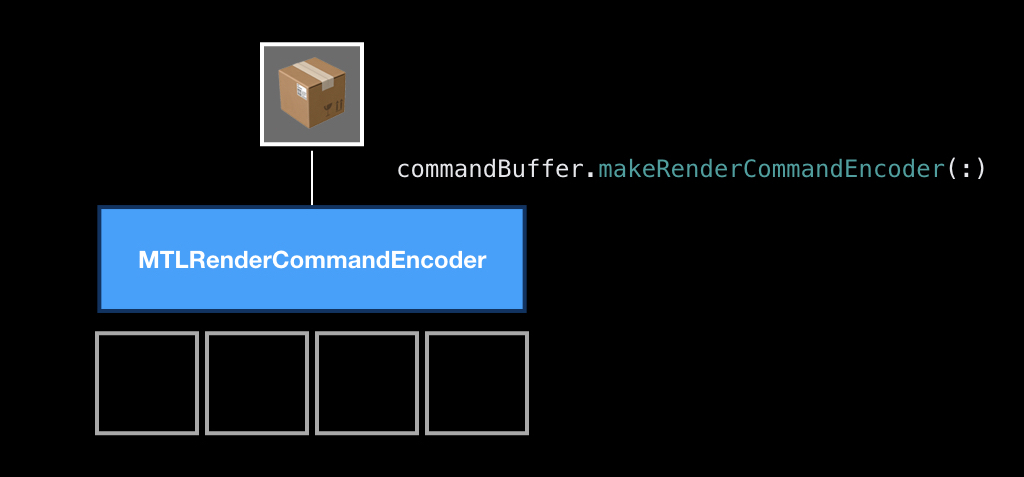
Сам по себе процесс энкодинга команд очень напоминает процесс крафтинга в играх. То есть при энкодинге у вас есть слоты, вы туда что-то кладёте и крафтите из них команду.
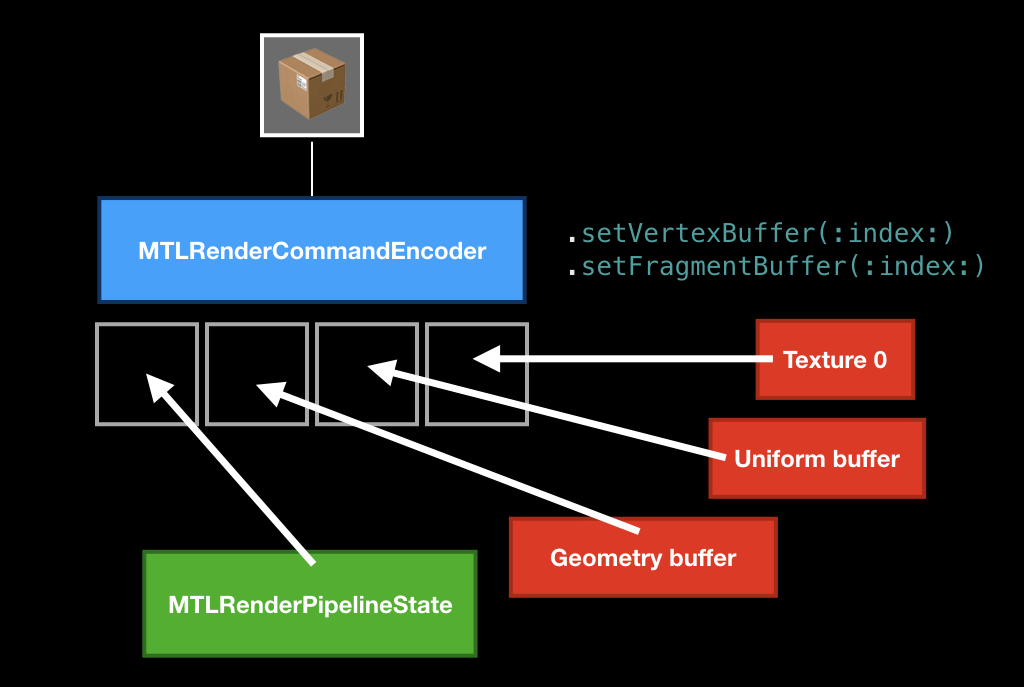
Основной ингредиент, который должен быть обязательно — это pipeline state, объект, который описывает состояние видеокарты, в которое её нужно перевести, чтобы рисовать ваши примитивы.

Основной характеристикой этого состояния является уникальная пара из вертексного шейдера и фрагментного шейдера, но есть ещё какие-то параметры, которые можно изменять, а можно и не изменять. Чаще всего (и Apple рекомендует так делать) вы должны закэшировать этот pipeline state где-то в начале приложения, а потом просто его переиспользовать.
Создаётся он с помощью дескриптора — это простой объект, в котором в поля вы записываете нужные параметры.

И потом с помощью девайса создаете этот pipeline state:

Мы кладём его, потом мы чаще всего кладём какую-то геометрию, которую хотим нарисовать с помощью специальных методов, и опционально можем положить какие-то униформы (например, в виде того же времени, о котором мы сегодня говорили), передать текстуры и прочее.
После этого мы вызываем метод drawPrimitives, и в нашу коробку кладется команда.
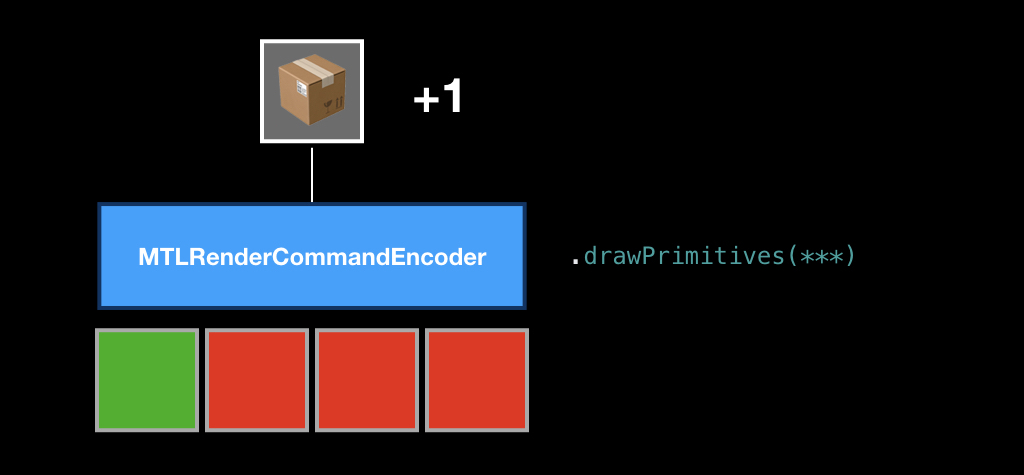
Потом мы можем заменить какие-то ингредиенты, положить другую геометрию или другой pipeline state, снова вызываем этот метод, и в нашей коробке появляется ещё одна команда.
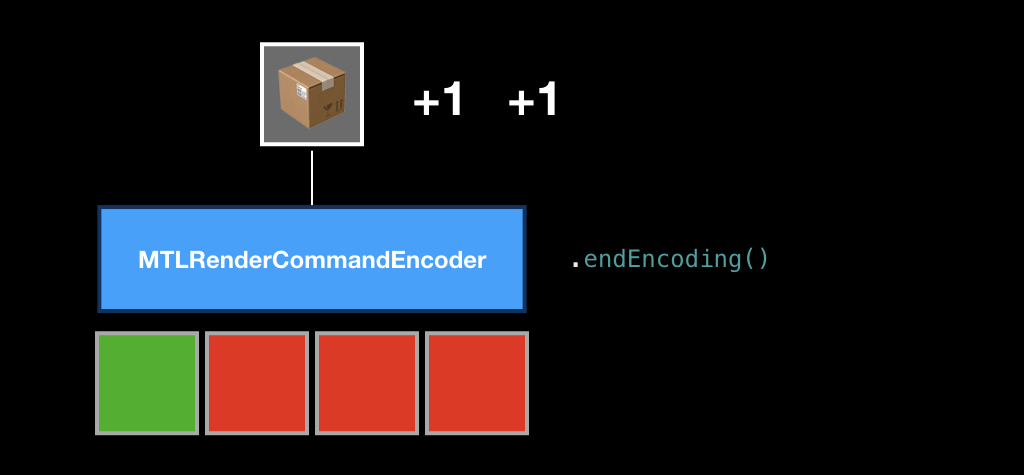
Как только мы заэнкодили все команды в нашем кадре, мы вызываем метод endEncoding, и эта коробка закрывается.
После этого мы отправляем коробку в нашу очередь с помощью метода commit, и с этого момента её судьба нам неизвестна. Мы не знаем, когда она начнёт выполняться, потому что не знаем, насколько нагружен сейчас GPU и как много команд в очереди. В принципе, можно вызывать синхронный метод, который будет заставлять CPU ждать того момента, пока все команды внутри коробки будут выполнены. Но это очень плохая практика, поэтому, как правило, нужно подписываться на addCompletionHandler, который будет вызван асинхронно в тот момент, когда каждая из команд в этой коробке будет выполнена.
Помимо рендеринга
Я думаю, вряд ли многие в зале пришли на этот доклад ради рендеринга. Поэтому мы посмотрим на такую технологию, как Metal Compute Shaders.

Чтобы понять, что это, нужно понять, откуда это всё взялось. Уже в 1999 году, как только появились первые GPU, стали появляться научные исследования о том, как можно использовать видеокарты для общих задач (то есть для задач, не связанных с компьютерной графикой).

Надо понимать, что тогда это было тяжело: нужно было иметь PhD в компьютерной графике, чтобы это делать. Тогда финансовые компании для анализа данных нанимали игровых разработчиков, потому что только они могли разобраться, что вообще происходит.
В 2002-м выпускник Стэнфорда Марк Харрис основал сайт GPGPU и изобрёл сам термин General Purpose GPU, то есть GPU общего назначения.
На тот момент этим интересовались в основном учёные, которые перекладывали задачи из химии, биологии и физики на что-то, представимое в виде графики: например, какие-то химические реакции, которые можно изобразить в виде текстур и как-то прогрессивно их считать.
Работало это немного коряво. Все данные записывались в текстуры и потом каким-то образом интерпретировались во фрагментном шейдере.
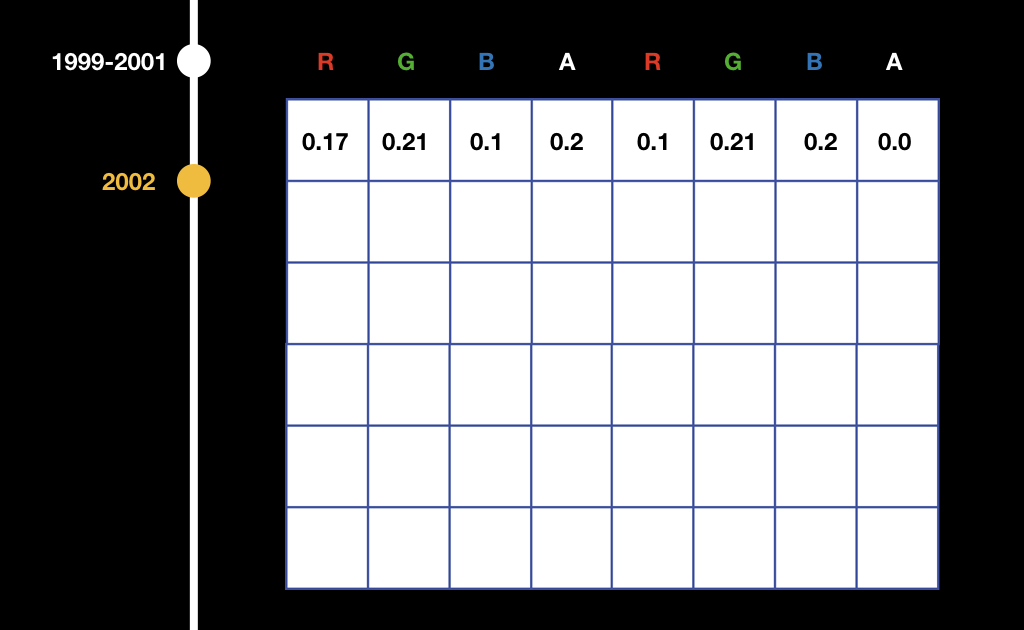
То есть, например, если у нас есть массив из float, мы записываем его в текстуру поканально: в красный канал первого пикселя записываем первое число, в зелёный канал первого пикселя записываем второе, и так далее. Потом во фрагментном шейдере нужно было это считывать и смотреть: если мы рендерим самый левый верхний пиксель, тогда делаем одно, если рендерим самый правый верхний — другое и пр.
Всё это было сложно до того момента, пока не появилась CUDA. Наверняка многие из вас встречали эту аббревиатуру. CUDA — тоже проект компании NVidia, представленный в 2007 году. Это такой похожий на C++ язык, который позволил на GPU писать программы общего назначения и делать какие-то вычисления, не связанные с компьютерной графикой.

Самая главная концепция, которую они поменяли: они изобрели новый вид программ. Если раньше были фрагментные шейдеры, которые принимают на вход координату пикселя, то теперь есть просто какая-то абстрактная программа, которая принимает просто индекс своего потока и считает определённую часть данных.
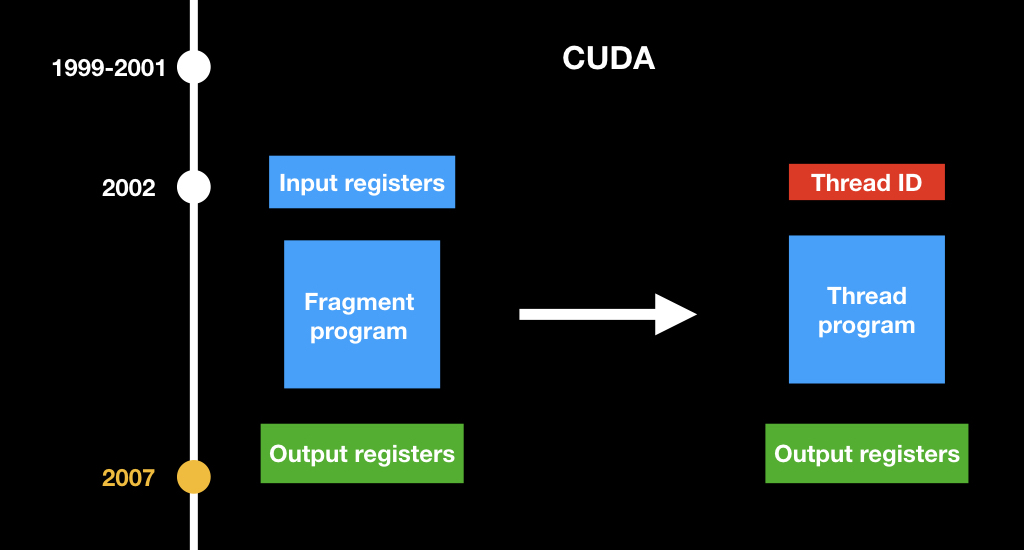
Собственно, эта же технология реализована в Metal Compute Shaders. Это такие же шейдеры, какие есть в GPU на десктопе, они работают так же, как фрагментные и вертексные, то есть запускаются параллельно. Для них есть специальное ключевое слово kernel. Они подходят только для задач, которые на уровне алгоритма очень сильно поддаются параллелизации и могут лежать в одном command buffer«e, то есть в одной коробочке с другими командами. У вас может быть сначала render-команда, потом compute-команда, и потом render-команда, которая использует результаты compute-команды.

Code time
Для того, чтобы показать, как Metal Compute Shaders работают, сделаем небольшую демку. Сценарий довольно близкий к реальности. Я работаю в AI-компании и часто бывает такое, что приходят R&D-шники и говорят, что вот с этим буфером надо что-то сделать. Мы будем просто умножать его на число, а в реальной жизни нужно какую-то функцию применить. Эта задача очень подходит для параллелизации: у нас есть буфер, и нужно каждое число независимо друг от друга умножить на константу.
Будем писать наш класс в парадигме Metal, поэтому он будет принимать в конструкторе на вход ссылку либо на MTLDevice, либо на MTLCommandQueue в качестве dependency injection.

В нашем конструкторе мы всё это будем кешировать и создадим в начале инициализации pipeline state c нашим kernel, который мы впоследствии напишем.

После этого подготовим типы. Нам потребуется только один тип Uniforms — это будет структура, хранящая константу, на которую будем умножать, и поле count, хранящее количество элементов, которые нам нужно будет посчитать.

С этим нужно быть очень осторожным. Многие, особенно программисты на C++, знают, что такое выравнивание данных — это когда компилятор меняет последовательность ваших полей в структуре или классе, или, например, меняет разметку, чтобы наиболее эффективно считывать их побайтово. И Swift делает тоже самое, поэтому, когда вы объявляете свои типы в Swift, нужно быть очень аккуратными. На Metal используется разметка типов С++, и она может не совпадать со свифтовой, поэтому хорошей практикой является, когда вы описываете эти типы где-то в одном хедере C/С++, и потом шарите эти описания между командами.

Нам нужно всего лишь имплементировать один метод, который будет на вход принимать наш массив и число, на которое нужно будет умножить. При этом мы уже закешировали наш девайс, очередь и pipeline state.
Первое, что мы будем делать — возьмём наш девайс и с помощью него создадим два буфера, которые будем передавать GPU.
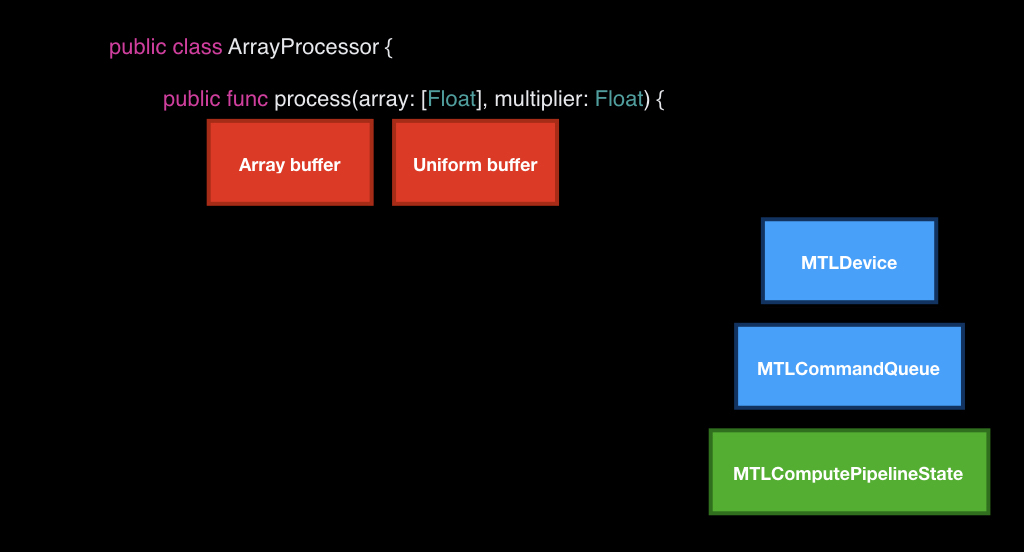
Мы не можем просто передавать данные, нам нужно создавать с помощью девайса специальные объекты. Мы кладём байты из нашего массива и создаём структуру из униформы, куда кладем поле count из массива и нашу пришедшую константу.
После этого в очереди берём пустую коробку. Берём специальный энкодер для compute-команды и загружаем это всё туда.

Возникает вопрос, что мы будем делать дальше. Если в рендер-командах мы вызывали drawPrimitives, то всё было понятно, а как создать команду для Сompute Shader? Для этого нужно познакомиться с таким концептом, как треды и тред-группы.
Все Compute Shaders запускаются поверх такой сетки, она может быть одномерной, двумерной и трёхмерной, выглядит это, как массивы, чтобы легче представлять. Каждый элемент этой сетки — это инстанс вашей функции, принимающий на вход координату в этой сетке. То есть, если сетка одномерная, то это просто индекс, если двумерная — то, понятно, двумерный. Такой инстанс называется thread, то есть «поток». Но, как правило, данных очень много, и GPU не может запустить их все сразу параллельно, поэтому чаще всего они организуются в группы и запускаются по группам.

Например, мы хотим для каждого пикселя в нашей картинке запустить один поток, и мы сделаем тред-группу из 32×16 тредов, которые будут обрабатывать изображение такими прямоугольниками, где для каждого пикселя будет запущен свой собственный поток:

Впоследствии в шейдерном коде мы можем получить текущий индекс нашего потока, и обработать или необходимый пиксель (как в данном случае), или какую-нибудь часть данных, в зависимости от вашей бизнес-логики.

Разбиение тред-групп можно делать двумя способами. Первый — это доверить его Apple. Это плохая идея, потому что чаще всего это неэффективно, а иногда это даже не позволяет алгоритм. Зачастую алгоритмы, например, blur, требуют тред-группы ровно 3×3. Многие алгоритмы требуют, чтобы все тред-группы были одного размера. А Apple самостоятельно разбивает тред-группы так, чтобы они вместили полностью данные, и если количество ваших данных не делится нацело, размер тред-групп будет различаться:
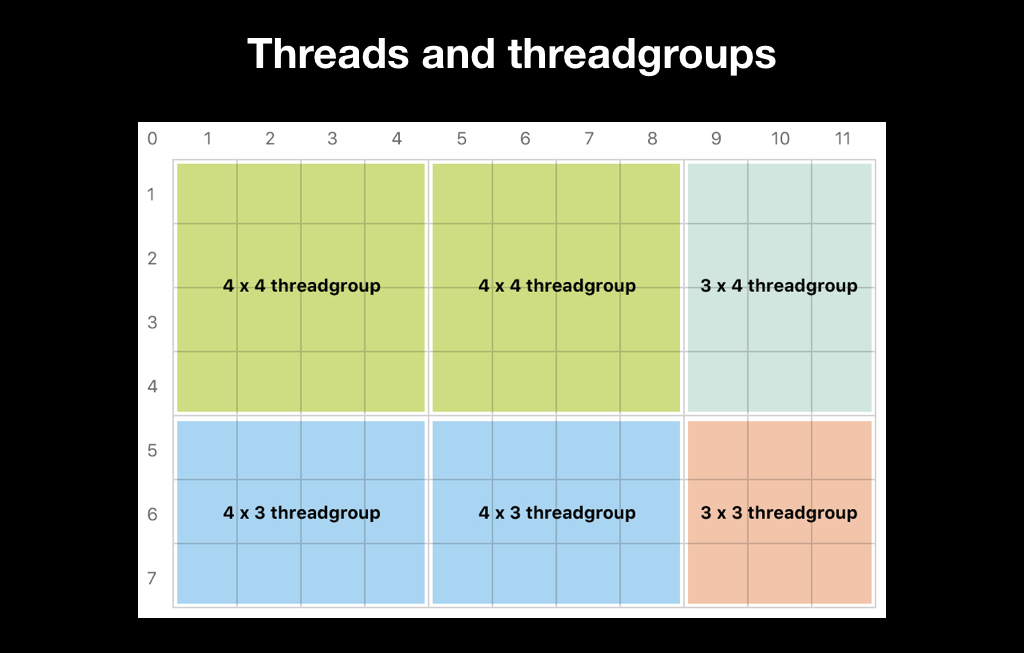
Поэтому чаще всего вы выбираете размер тред-группы сами, и делаете так, чтобы при невозможности поделить нацело потоков было больше, чем ваших данных:

Важно также знать, как работают тред-группы. Внутри они запускаются по принципу SIMD, то есть Single Instruction Multiple Data. Все потоки синхронно исполняют один и тот же набор машинных инструкций, только на вход принимают разные данные, то есть они делают шаг синхронно. И проблемы начинаются, если один из ваших потоков имеет ветвление.

Если бы GPU разбирался, какая из веток правильная, всем остальным приходилось бы ждать. Вместо этого GPU исполняет обе ветки: сколько бы if не встречалось, исполняется весь код, чтобы всё это параллельно работало. Поэтому ветвление в SIMD-коде — это очень плохо, и важно свести его к минимуму. Существуют математические приёмы, которые в определённых случаях помогают этого избежать.
Само разбиение на SIMD-группы неподконтрольно нам, мы можем знать только так называемую ширину вычислений, то есть сколько потоков могут одновременно содержаться в SIMD-группе. Это нужно для случаев, когда нам нужно максимально эффективно разбить данные. Иногда мы разбиваем на потоки по алгоритму, как в приведённом примере с blur, а иногда нужно просто сделать максимально эффективно, и мы используем для этого ширину.

Мы берем её у pipeline state, подсчитываем количество тред-групп, то есть берём сount нашего буфера, добавляем к нему ширину минус 1, и делим на эту ширину. Это простая формула для того, чтобы точно получилось с запасом. И считаем количество потоков в одной группе.

Вызываем вот такой метод dispatchThreadgroups, в который передаём количество тред-групп и количество потоков в каждой группе.
