Как сделать мониторинг инженерной инфраструктуры ЦОД на примере DataLine

Я продолжаю исследовать объекты, на которые устанавливается оборудование Wiren Board. Ранее я рассказывал читателям о нескольких умных домах и квартирах, а также умной теплице. Настало время посетить что-то более масштабное. Компания DataLine пригласила меня в один из центров обработки данных, чтобы рассказать о системе мониторинга.

Контроллер Wiren Board 6 в составе системы мониторинга инженерной инфраструктуры ЦОД
В январе 2017 года DataLine опубликовала статью, в которой приведены основные сведения о системе мониторинга ЦОД. Но с тех пор утекло много воды, были добавлены дашборды Grafana, осуществлен переход на новую облачную систему мониторинга, внесены другие оптимизации, поэтому я расскажу о текущем состоянии системы мониторинга. А чтобы статья была максимально полезной, я рассмотрю основные задачи системы мониторинга ЦОД и подводные камни, которые помогут создать или улучшить собственную систему мониторинга, опираясь на опыт специалистов DataLine.

Что такое мониторинг и когда о нем думать?
Система мониторинга непрерывно собирает и анализирует параметры оборудования дата-центра. Это своего рода нервная система дата-центра. На основе полученных данных инженеры делают выводы о текущем состоянии и вероятном развитии событий. Но мониторинг — это не просто сбор данных. В организации должны быть регламенты взаимодействия между сотрудниками в штатных и аварийных ситуациях, выстроена система уведомления ответственных лиц. Все это превращает мониторинг в инструмент управления инфраструктурой.
Мониторинг следует проектировать вместе с остальной инженерной инфраструктурой, то есть до запуска дата-центра. Если заниматься мониторингом уже после запуска дата-центра, то какое-то время служба эксплуатации будет работать вслепую. Дежурные инженеры не смогут отслеживать ошибки в работе оборудования, пропустят предаварийные ситуации. Единственный доступный способ мониторинга в такой ситуации — это физический обход всех инженерных систем и ИТ-оборудования.

Есть хорошее выражение: невозможно управлять тем, что нельзя измерить. Поэтому мониторинг следует продумывать заранее и не запускать инженерную инфраструктуру без мониторинга.
Приведу пример. Дата-центр запустили в эксплуатацию. Первые месяцы зал был почти пустой и из трех кондиционеров работал только один. С заполнением зала температура в нем выросла. Поскольку мониторинга нет, то службе эксплуатации будет сложно определить момент, когда включить второй кондиционер, а в случае аварии — резервный.
Сервис мониторинга DataLine решает следующие задачи:
формирует алерты в консоли мониторинга;
создает инциденты в Service Desk;
отправляет оповещения по email, SMS, Telegram или голосом по телефону — для звонка уже подключается дежурный;
хранит исторические значения метрик в виде данных временного ряда и графиков;
визуализирует текущие статусы объектов мониторинга на дашбордах;
генерирует отчеты.

Общая схема мониторинга DataLine
За каждый этап сбора данных отвечает свой элемент:
Nagios Core получает значения метрик и выполняет проверку мониторинга. Почему именно Nagios? Ответ простой: так сложилось исторически. Во-первых, инженеры DataLine не хотели привязываться к проприетарным системам мониторинга, в том числе SCADA-системам. Во-вторых, его функциональность устраивает, и нет серьезных аргументов миграции на другой продукт. В-третьих, за 10 лет эксплуатации решения в DataLine для него было создано множество скриптов, плагинов и кастомизаций. Zabbix, Prometheus и Victoria Metrics тоже используются в компании, но не как основное решение для мониторинга инженерной и ИТ-инфраструктуры.
InfluxDB используется как историческое хранилище. Значения метрик сохраняются в базу с помощью Nagflux.
Grafana используется для отображения графиков на дашбордах. Для совместной работы с Nagflux применяется плагин Histou.
Thruk используется в качестве web-интерфейса для консоли мониторинга.
Система мониторинга DataLine базируется на Nagios. В общей сложности в DataLine сейчас заведено в мониторинг 12 000 хостов и 182 000 проверок на них.
Что нужно отслеживать?
Я бы выделил три уровня мониторинга инженерной инфраструктуры: автономные датчики, оборудование и система в целом.
Датчики
В ЦОД установлены датчики протечек, температурные датчики, датчики объема/движения, открытия и закрытия дверей стоек.

Контроллер Wiren Board 6 в составе системы мониторинга инженерной инфраструктуры ЦОД
Датчики протечек нужны всегда, особенно если в дата-центре используется система охлаждения с жидким теплоносителем или фреоновая с увлажнением. Компания DataLine размещает их под каждым кондиционером, узлом и краном трубопровода, то есть в тех местах, где может «закапать». В щите дата-центра установлены контроллеры Wiren Board 6 или 7 и модули сухих контактов WBIO-DI-WD-14, к которым подключены датчики протечки. Используется датчик H2O-Контакт исп.2, заведенный в модуль сухих контактов. Сервер опрашивает контроллер по SNMP, Nagios получает информацию о статусе сухого контакта и, исходя из логики, оповещает о протечке. Затем срабатывает запорная арматура.
Температурные датчики vutlan устанавливаются в холодных и горячих коридорах машинных залов, в помещениях с инженерной инфраструктурой (насосные, помещения АКБ, ГРЩ и другие).
Датчики объема/движения, открытия и закрытия дверей стоек. В отличие от предыдущих, они опциональны. Их можно использовать в залах или для группы стоек, огороженной забором (cage).
Оборудование
Лучше всего, если будет проводиться мониторинг всего оборудования: ИБП, ДГУ, кондиционеры, PDU, АВР, камеры и так далее. По каждому устройству важно получать следующую информацию:
работает или нет;
есть ли ошибки в работе, какие именно ошибки;
значения отдельных параметров (напряжение в ИБП, сила тока, уровень топлива в баке ДГУ, температура на входе и выходе кондиционера, скорость вращения вентилятора и так далее)
Система в целом
Важно не просто следить за каждой единицей оборудования, а видеть картину в целом. Тогда можно отследить цепочки оборудования, взаимосвязи, что позволяет понять, на каком этапе возникла неисправность. Взаимосвязи оборудования в системе можно визуализировать с помощью логических схем.
Здесь можно привести такой пример: отключился распределительный щит в машинном зале. Если отслеживать оборудование отдельно друг от друга, то сразу причину поломки нельзя понять — проблема может быть как в щите, так и в ИБП, от которого он питается. Если же перед глазами будет схема всей системы, то можно быстро найти слабое звено.

Схема системы энергоснабжения, показывающая все оборудование в одной цепочке.
С инженерного оборудования данные собираются по протоколам Modbus и SNMP. Для мониторинга по Modbus используются преобразователи Moxa Mgate. Для сбора информации из ИТ-систем используются вендорские API. В качестве агентов мониторинга применяются стандартные NRPE-агенты для Linux и NSClient++ для Windows.
Документация мониторинга
Специалисты DataLine составляют документацию по системе мониторинга после того, как определятся с объектами и параметрами мониторинга. В ней приведены следующие пункты:
список датчиков и оборудования на мониторинге;
место их установки;
отслеживаемые параметры и конкретные значения;
схемы подключения;
пороговые значения для уведомлений об аварийных ситуациях.
Причем все эти пункты лучше делать на этапе проектирования, чтобы у службы эксплуатации была полная документация с самого начала. Служба эксплуатации должна ответить на следующие вопросы:
все ли интересующие объекты поставлены на мониторинг;
где искать проблему в случае неисправности самой системы мониторинга;
какие пороговые значения используются.
Такая «шпаргалка» позволит службе эксплуатации не исследовать систему мониторинга заново.
Независимость и резервирование системы мониторинга
Под мониторинг лучше использовать отдельное серверное и сетевое оборудование с выделенным сетевым сегментом.
Серверы должны быть зарезервированы таким образом, чтобы при выходе из строя одного из серверов мониторинг продолжил работать на втором. Совсем хорошо, если серверы кластера разнесены по разным машинным залам.
Мониторы, на которые выводятся схемы, уведомления, также должны быть подключены к бесперебойному питанию с резервом. По сети также — сетевые розетки подключены к разным коммутаторам. Так дежурные инженеры не останутся наедине с потухшими экранами, когда в дата-центре происходит что-то интересное.
Чтобы обеспечить отказоустойчивость и высокую доступность системы, в DataLine используются инструменты кластеризации Pacemaker и DRBD. Каждый кластер состоит из двух нод. Они разнесены физически по разным залам в дата-центре.

Схема кластеризации DataLine
В нормальном повседневном режиме на каждой ноде работает свой инстанс Nagios Core. При этом между ними непрерывно происходит репликация файловых систем. В случае отказа одной из нод кластерные ресурсы переезжают на исправную ноду, и оба инстанса Nagios продолжают работать на ней. После восстановления отказавшей ноды кластерные ресурсы соответствующего инстанса Nagios возвращаются обратно.

Схема повседневной работы
Консоль Thruk тоже поднята в двух экземплярах на разных площадках. Каждый экземпляр Thruk подключается ко всем инстансам Nagios. В случае отказа одного из экземпляров дежурные инженеры просто переключаются на вторую консоль.
Каждый инстанс Nagios покрывает свой скоуп объектов мониторинга. Конфигурации в Nagios хранятся в текстовых файлах, и реляционные БД для этого не используются. Каждый экземпляр Nagios хранит только свою конфигурацию, так что единой точки отказа нет. Сейчас в DataLine 26 инстансов, инженеры компании не сталкивались с какими-то существенными проблемами производительности.
Единый центр мониторинга
Вся информация с датчиков, оборудования и систем сводится в единый интерфейс —она выборочно отображается на экранах в центре мониторинга.
Система мониторинга DataLine работает в более чем 10 дата-центрах и собирает сотни тысяч метрик о работе оборудования. Ее используют сразу несколько групп инженеров с разной специализацией.
Дежурные инженеры. За работой ЦОД необходимо следить круглосуточно, поэтому всегда есть дежурные инженеры. Они следят за видеостеной в центре мониторинга, разбирают падающие в систему оповещения о неисправности оборудования и ИТ-систем. Все уведомления в центре мониторинга регистрируются в виде инцидентов, после чего передаются на ответственным лицам или отделам.
Профильные инженеры из групп холодоснабжения, энергетики, сети и других, они отслеживают показатели здоровья конкретной системы: от нагрузки на оборудование до статистики замены запчастей.
Для небольших серверных оповещения по email, Telegram и SMS могут заменить круглосуточного дежурного инженера. В большом ЦОД они выполняют задачу резервирования дежурного. Но и здесь важно не перестараться и не рассылать уведомления ответственным лицам по любому чиху.
Если будет много оповещений по некритичным ошибкам (выше мы называли их warning), то со временем их просто начнут игнорировать, и серьезная авария останется незамеченной.

Центр мониторинга на площадке OST
Каждой группе требуются разные данные для разных целей, поэтому для системы мониторинга важна гибкость в представлении информации:
На видеостену в «дежурке» выносятся ключевые показатели, чтобы инженеры на смене сразу замечали проблемы и быстро принимали решения. Работа дежурных ведется по четким инструкциям, которые оттачивались годами, и следование им отрабатывается чуть ли не поминутно. Инженеры могут ротироваться между объектами. Поэтому отображение информации для видеостен стандартизировано и постоянно совершенствовалось группой разработки DataLine.
Профильные инженеры «проваливаются» в базу мониторинга глубже. Например, если дежурным достаточно знать статус работы кондиционера и температуру в зале, то инженерам-холодильщикам для своевременного обслуживания понадобятся десятки параметров: давление в контуре, степень открытия клапана, степень загрузки чиллера и так далее. Такие оперативные данные нужны по каждой конкретной единице оборудования. Выносить их на общую видеостену не имеет смысла — не хватит места, либо дашборд получится настолько перегруженным, что его придется читать с лупой.
В каждом профильном отделе установлены экраны со схемами и оповещениями, которые входят в зону ответственности данного отдела: для инженеров эксплуатации — одни экраны, для сетевиков — другие.

Так представлены в базе Nagios параметры одного из кондиционеров.
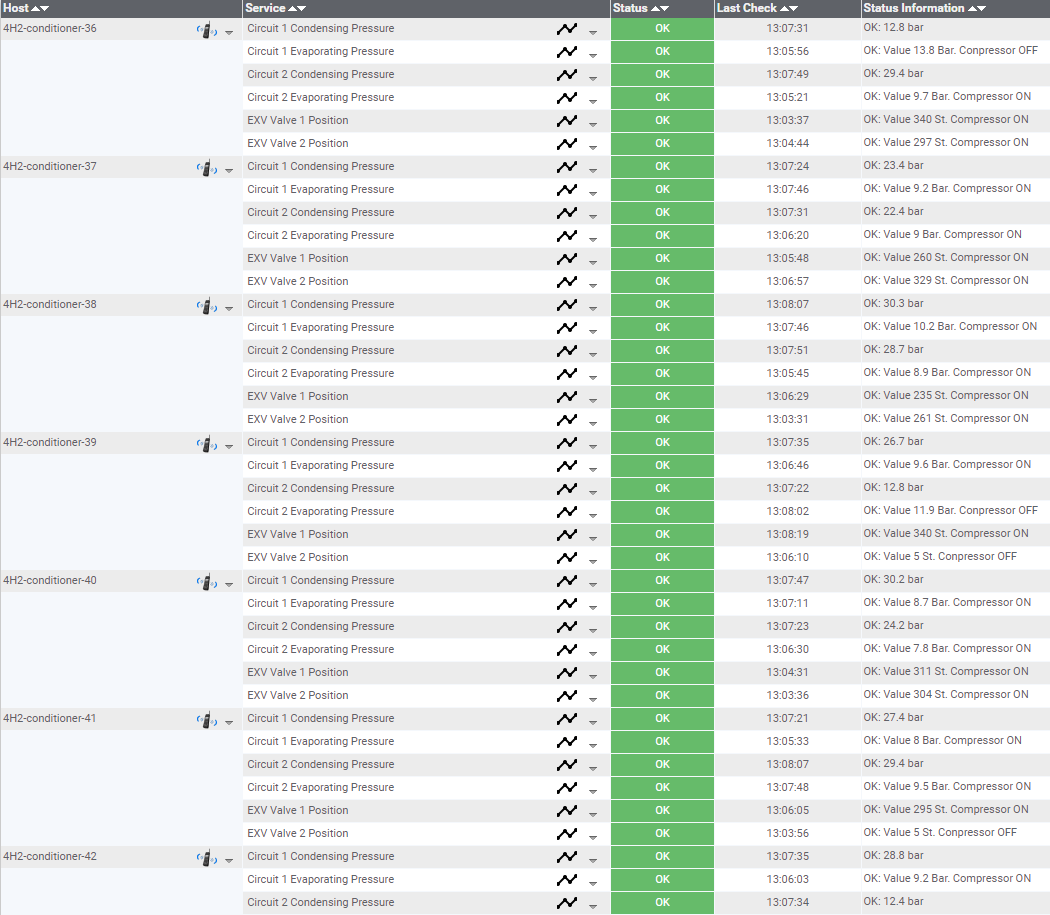
Так выглядит часть параметров одного зала.
Визуализация — это важно!
Теоретически следить за работой ЦОД можно только с помощью уведомлений и таблиц параметров, все же есть фильтрация, группировка. Но воспринимаются они тяжело. От множества одинаковых строчек с мелким текстом быстро устаешь и замыливается глаз.
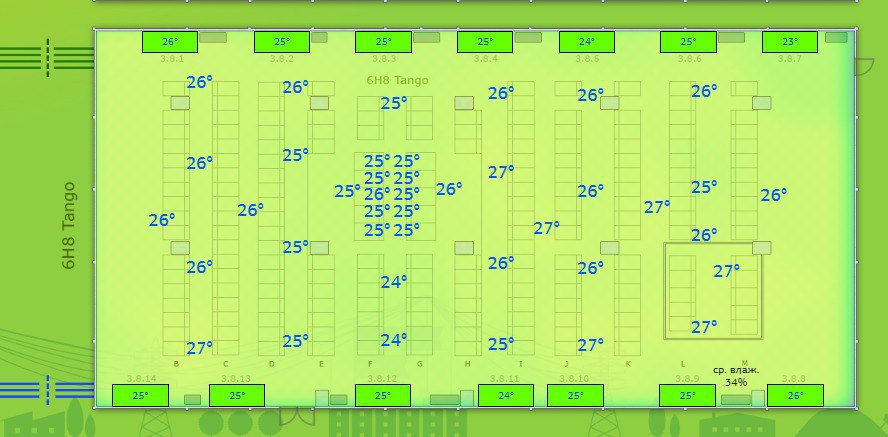
Сводная схема зала дата-центра Nord
Для наглядности лучше визуализировать основные инженерные системы и их параметры. Долгое время в центре мониторинга использовались классические схемы и карты. С такой схемой дежурному инженеру будет легче понять, в каком машинном зале находится сломанный кондиционер, что происходит с температурой в ближайшем холодном коридоре. Кроме того, визуализация дает возможность увидеть взаимосвязь между отдельными элементами инженерной системы и быстрее определить источник проблемы.
К схемам и картам было решено добавить более наглядные дашборды для специализированных групп, где каждый инженер может настроить представление под себя. Все же функциональность схем Nagios была сильно ограничена. Идея «повесить» дашборды на группу разработки тоже оказалась не лучшей — программистам пришлось бы плотно общаться с каждой группой инженеров, а они в DataLine обычно сильно загружены «в полях».
Было решено найти надстройку, с помощью которой можно делать простые визуализации с понятным пользовательским интерфейсом и минимальным конфигурированием. В этом случае Nagios выступает в роли сборщика данных, а для интерфейса используется стороннее решение с возможностью визуального конфигурирования.
В итоге была выбрана надстройка Grafana: она использовалась в DataLine и ранее для отображения графиков на дашбордах, так что такой опыт есть. Это Open Source — есть платная лицензионная версия Grafana Enterprise, но решились обойтись бесплатной.
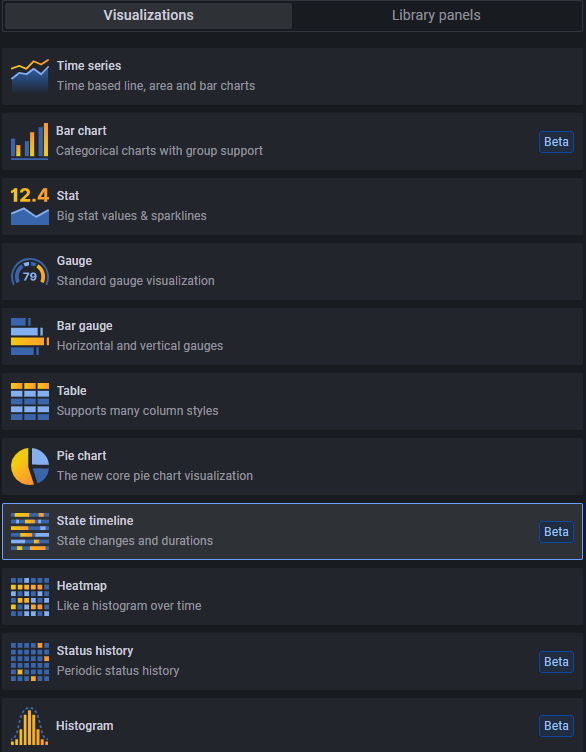
В Grafana есть и классические графики, и диаграммы, и тепловые карты
Как показала практика, создать простую визуализацию инженер может самостоятельно всего за пару часов. По трудозатратам это выходит очень дешево, можно экспериментировать и не бояться сделать ошибку.
Сначала DataLine усовершенствовала систему мониторинга системы кондиционирования на площадке NORD. Возможность видеть на одном экране основные параметры всех кондиционеров ЦОД пришлась инженерам холодоснабжения очень кстати. Быстро сделали несколько дашбордов, которые выведены на мониторы в кабинетах холодильщиков. Если вам интересны подробности, то рекомендую обратиться к статье «Кастомизируем дашборды в Grafana для инженеров по холодоснабжению ЦОДа».

Визуализация метрик в Grafana

Еще один вариант визуализации
На один дашборд требовалось уместить много метрик, причем отражающих актуальные данные в реальном времени (типовые графики Grafana визуализируют временные ряды). Поэтому был добавлен сторонний плагин FlowCharting для рисования сложных диаграмм в Grafana.

Вот такой получился «бутерброд»
Чтобы избежать риска утечки данных через гипотетически возможные уязвимости в Open Source, графическая система была развернута во внутренней инфраструктуре DataLine, без доступа во внешнюю сеть.

Общение инженера с ботом телеграм
Кроме того, чтобы помочь профильным инженерам «в полях», где пользоваться ноутбуком и планшетом не всегда удобно, с помощью BotFather был создан телеграм-бот, который умеет по запросу отправлять в мессенджер скриншоты дашбордов. Был написан скрипт, который ежеминутно скринит выбранные дашборды и сохраняет под заданными именами. Процесс цикличен: названия остаются, сами скрины регулярно меняются на свежие. В папке всегда лежит одинаковое число скриншотов. Получив запрос, бот по названию находит в папке нужный файл и отправляет его в мессенджер пользователю.
Опросы и оповещения
При настройке времени опроса следует учитывать специфику инженерных систем. Например, для системы энергоснабжения чем чаще будут сниматься показания, тем лучше. В ЦОД DataLine значения напряжения снимаются каждую секунду. Но для тех же кондиционеров это слишком часто, достаточно и минутного интервала.
Конечно, в системе мониторинга должны быть прописаны критические значения, по достижении которых будут срабатывать оповещения. Минимумом здесь будет два уровня оповещения — предупреждения и критические ошибки. В Nаgios, например, такому разделению соответствуют warning и critical:
Warning предупреждает о том, что какие-то параметры оборудования или системы подходят к критическому значению;
Critical означает аварийную ситуацию, когда что-то сломалось, ошибка в оборудовании.
Правильное разделение уведомлений позволит сократить количество ложных тревог. Провести четкую черту между warning и critical сложно, но понимание приходит с опытом. Если монитор перманентно красный от аварий, значит что-то настроено неправильно. Для инженера такой мониторинг быстро станет неинформативным, будут возникать ложные тревоги, а настоящие аварии могут остаться незамеченными среди рутинных оповещений.

Примеры warning и alarm
Все сообщения об авариях должны быть актуальными. Если на экране висит сообщение об аварии, то значит, что она произошла только что. Как только это уведомление зарегистрировано в виде инцидента на ответственное лицо, оно должно пропасть с экрана.
Регламент действий при аварийных ситуациях
Важно не только не пропустить аварию, но и правильно отреагировать на нее, запустить процесс реакции на инцидент.
У дежурного инженера должна быть четкая инструкция, по которой он действует, и контакты людей, которых нужно оповестить в случае аварийной ситуации.

Специальное контекстное меню позволяет автоматизировать создание инцидента в Service Desk и заполнение формы заявки
Вся информация должна быть перед глазами и ясно сформулирована, чтобы инженеру не приходилось тратить время на поиски или расшифровывание пунктов инструкции.
Для удобства дежурных инженеров каждое уведомление можно сопроводить всплывающей подсказкой с контактами ответственного лица и инструкцией. Регламенты же прописываются заранее и проверяются на жизнеспособность во время плановых тестирований.

После создания инцидента и оповещения инженер действует по инструкции, просмотреть ее можно из консоли Thruk
Не заставляйте дежурного инженера придумывать план действий с нуля, когда в дата-центре авария.
Сбор статистики
Помимо онлайн-мониторинга, полезно собирать и долгосрочную статистику. Это позволит оценить параметры в динамике, выявить значения, приводящие к аварийным ситуациям. Со статистикой на руках можно делать выводы по работе оборудования при различной нагрузке, разных погодных условиях. Эта же информация потом используется для «разбора полетов» после аварий.
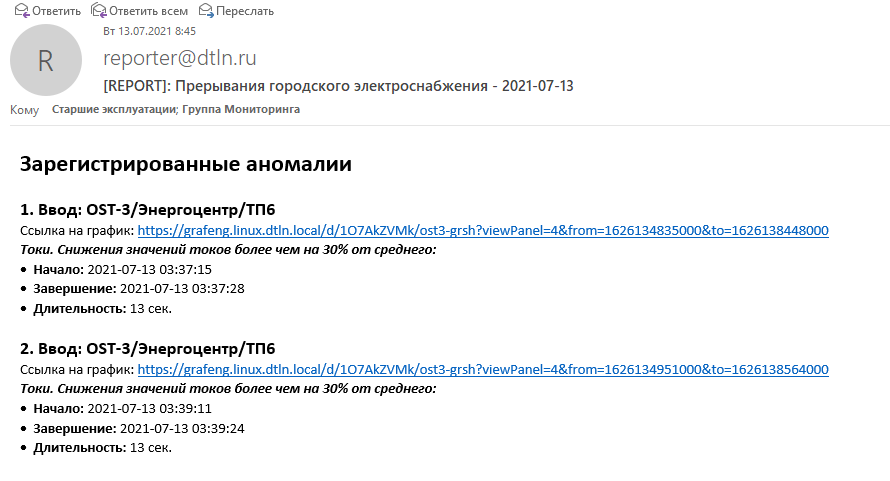
Отчет о просадках на городских линиях электроэнергии

Отчет по обработке алертов
Заключение
В статье я рассмотрел задачи, которые следует учитывать при развертывании системы мониторинга ЦОД. Если нужна конкретика, то специалисты DataLine подготовили подробные статьи по мониторингу энергоснабжения дата-центра и серверной, холодоснабжения и сетевой инфраструктуры и оборудования. Если заинтересовали технические подробности мониторинга DataLine, то рекомендую прочитать статью «Как мы наблюдаем за метриками в дата-центре и развиваем наш мониторинг».

Я надеюсь, что статья была полезной, и вы сможете улучшить систему мониторинга вашей серверной или ЦОД. Если остались какие-то вопросы, то не стесняйтесь спрашивать в комментариях, специалисты DataLine всегда готовы прийти на помощь.

А это оборудование Wiren Board 6 в другом ЦОД, про который мы скоро расскажем
