Как сделать хорошую интеграцию? Часть 2. Идемпотентные операции – основа устойчивой интеграции
В прошлой статье мы говорили о том, что основой хорошей интеграции является админка, которая позволяет быстро решать инциденты. Сегодня мы поговорим, как реализовать интеграцию, чтобы получить ее устойчивую работу — толерантность к потере сообщений, падению процессов и ошибкам обработки.
Потому что процессы, которые обрабатывают сообщения и удаленные вызовы, могут падать из-за собственных ошибок в середине обработки. Или по другим причинам. Например, при исчерпании места на диске, которое обнаружилось при попытке вставить очередную запись в журнал обработки. Или по таймауту или deadlock обращения к базе данных. Или без всяких ошибок процессы убивает наблюдатель за работоспособностью сервера в целом, выбрав их в качестве жертвы. Может быть, просто потому, что процесс активно работал с памятью, а сборщик мусора вызваться не успел, вот наблюдатель и решил, что процесс съел памяти слишком много… То есть даже если разработчик написал обработчик аккуратно и позаботился о надлежащей обработке ошибок, она все равно может оказаться невозможной.
А сами сообщения? Теряются, приходят в неверном порядке, дублируются. А у нас не всегда есть выбор по использованию конкретного протокола. Exactly one — большая редкость, и в ее реализации обычно есть большая серая зона, связанная со заложенным в транспортный уровень алгоритмами определения: было ли сообщение успешно доставлено, обработал ли его получатель? Важно не просто доставить сообщение, а успешно его обработать в условиях, когда гарантий безошибочной обработки не существует.
Для решения этих проблем устойчивости работы мы можем использовать шаблон «Идемпотентные операции». Для интеграции это значит, что если нам неизвестен результат выполнения операции, то мы можем повторно ее выполнять, повторно отправив то же самое сообщение, — и это не приведет к дублированию действий, даже если предыдущая операция была выполнена полностью или частично.
Покажем, как это происходит на схеме, на примере заказа для интернет-магазина. Для удобства представим, что работу отдельных сервисов делают гномики, которые живут внутри компьютеров:
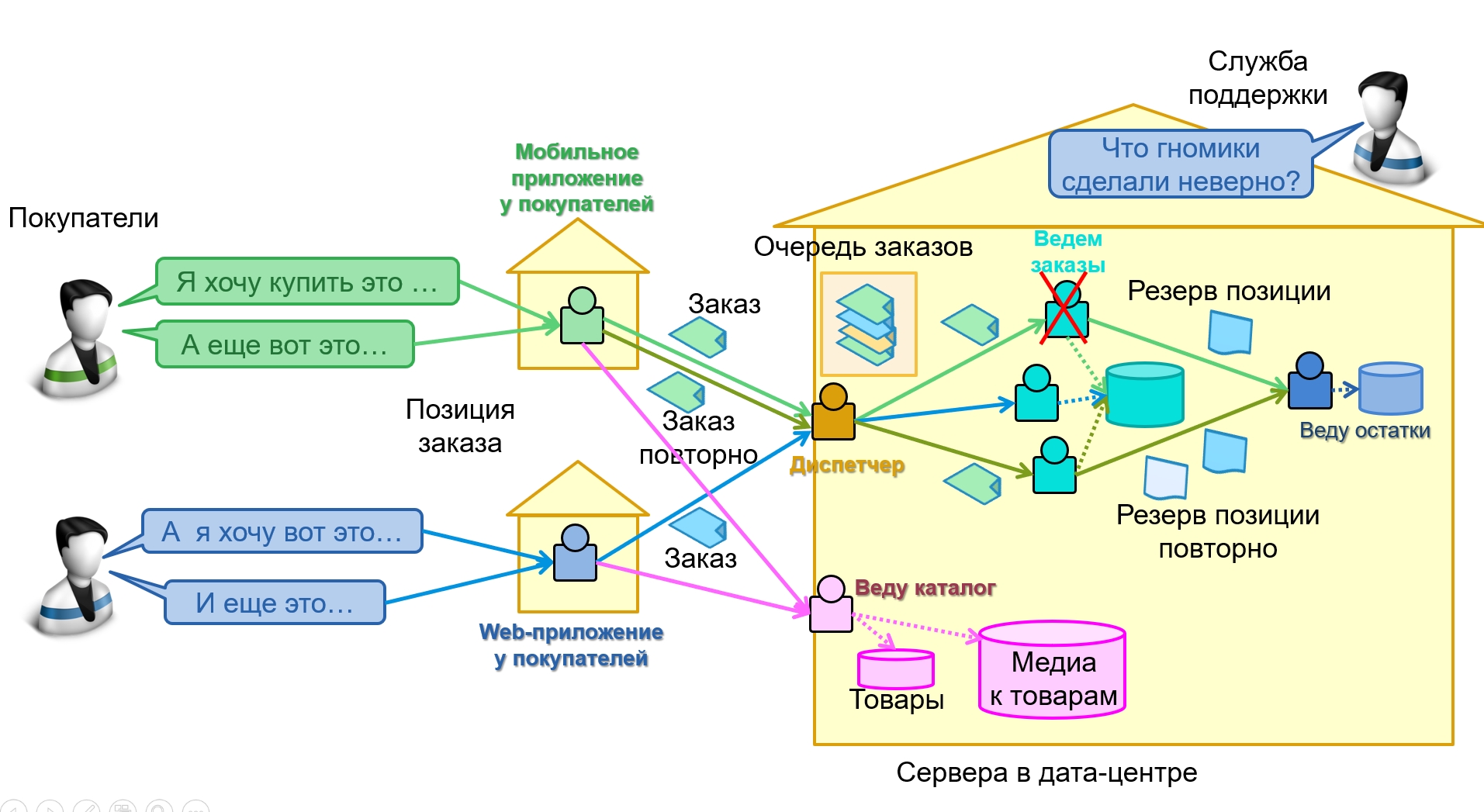 Каждый сервис-гномик обозначен своим цветом
Каждый сервис-гномик обозначен своим цветомНа схеме изображена часть реализации интернет-магазина:
мобильные приложения у пользователей, отправляющие заказы диспетчеру на единую точку входа;
сервисы ведения заказов, которые обрабатывают полученные диспетчером заказы, сохраняя их в общую базу данных, а для резервирования обращаются к отдельному сервису ведения остатков;
отдельный сервис для запроса каталога товаров, работающей не только с базой товаров, но и большой базой медиаданных по товарам.
Пусть одно из мобильных приложений отправило заказ (показан зеленым), сервис заказов начал его обрабатывать, успел зарезервировать одну из позиций и упал по какой-то ошибке. Если взаимодействие сделано по шаблону идемпотентных операций, то мобильное приложение, не получив ответа, просто отправит заказ повторно — это показано темно-зелеными стрелками. Его получит другой экземпляр сервиса обработки заказов, проверит наличие в базе данных — и не будет создавать новый.
В результате сервис заказов продолжит обработку заказа, просто отправив этот резерв сервису резервирования. А тот в свою очередь поймет, что одну позицию он уже зарезервировал и не будет это делать повторно, а вот вторую — зарезервирует.
Теперь рассмотрим подробнее, как такой протокол реализовывать и использовать.
Как реализовывать идемпотентные операции
Как же должна быть устроена, например, обработка платежей, чтобы обеспечивать идемпотентность? Отправляющая система должна нумеровать каждый платеж уникальным номером. Принимающая система на обработке платежа должна проверять — возможно, платеж с таким номером уже приходил раньше, и мы имеем дело с дублем сообщения. Если нет — создавать новый платеж. Если же платеж уже существует, и его атрибуты совпадают — выдавать текущий статус обработки. А при различии атрибутов, — когда с тем же самым номером пришел другой платеж — выдавать ошибку.
Замечу, что это важная часть шаблона — сверить атрибуты создаваемого платежа при обнаружении, что платеж с таким номером уже есть. Потому что если мы просто возвращаем ответ «Такой платеж уже есть», то передающая система не знает: то ли сообщение было дублировано по каким-то причинам и ситуация решена, то ли из-за каких-то других ошибок один и тот же номер использовали дважды для разных сообщений. В идеале такие ситуации должна решать система, а не сотрудник службы сопровождения, тем более, что сверить атрибуты несложно.
Это аналогично UPSERT
Замечу, что такой протокол, если его применять для операций с объектами, очень похож на оператор UPSERT или MERGE — гибрид из INSERT и UPDATE, который обновляет записи, а при их отсутствии — создает новые. Это — относительно свежее расширение SQL, оно появилось в 2003 году и далеко не везде реализовано, поэтому в учебники в качестве основного шаблона работы с СУБД не попало: пятнадцать лет — вовсе не срок для обновления учебников. А зря.
Потому что именно здесь лежит проблема. Протокол идемпотентных операций не часто реализуют в принимающих системах. А даже если он реализован, пользователи протокола не всегда умеют его правильно использовать. Учились все мы от простого к сложному, и работу с объектами постигали именно на приложениях работы с базой данных. В которых для создания объекта (например, покупателя) надо выполнить INSERT и получить от базы данных уникальный ключ, который далее идентифицирует объект и позволяет с ним работать — изменять при указании адреса, или ссылаться на него из других объектов, создавая заказы для покупателя.
Поэтому именно этот шаблон и воспроизводят в интеграции — обращение для создания объекта возвращает его ключ, который используется далее. А обнаружив, что протокол не поддерживает возврат ключа, делают генерацию уникального ключа в момент отправки на транспортном уровне, например, используя guid, и не сохраняя его в базу локально. Когда при этом может возникнуть проблема? Возникает она в том случае, когда отправляющая система не получила ответа о создании объекта — например, из-за разрыва соединения по таймауту или падению связи. Потери могут быть на любом из этапов, — как при отправке и обработке сообщения, так и при получении и обработке его ответа. А отправляющая система не может различить эти ситуации .
Тогда как в случае идемпотентных операций это не проблема — достаточно повторно отправить сообщение создания платежа.Если ключ выдает принимающая система, и уникальных номеров у нас нет, то автоматически решить такую ситуацию сложно или даже невозможно. Конечно, можно, запросить выписку по своему счету и там этот платеж поискать, и только не найдя — отправить повторно. Но вполне может оказаться, что в выписке этого платежа, конечно, нет, но в очереди на обработку он стоит, просто еще не обработался. И отправив повторно, мы выполним операцию дважды.
Замечу, что для работы с базой данных шаблон, в котором ключ определяет база данных — правильный, потому что одна база данных обслуживает много клиентских приложений. В этом случае устойчивость работы обеспечивается не за счет идемпотентных операций, а за счет транзакционной работы, которая при интеграции обычно отсутствует.
Впрочем, некоторые современные базы данных, рассчитанные на работу в нагруженных системах, например, Cassandra, могут воспроизводить шаблон идемпотентных операций — в них UPDATE создает запись при ее отсутствии, а INSERT отсутствует. Мне, кстати, это как-то здорово помогло, когда я отстаивал протокол идемпотентных операций перед разработчиками, которым он казался каким-то чересчур сложным и непривычным — они осознали: «А, это же так, как в Кассандре сделано, только нам придется вручную написать! OK, это понятно».
Создание уникальных идентификаторов
Таким образом, идемпотентные операции, прежде всего, должна обеспечивать принимающая система. Но и передающая должна понимать такую организацию протокола и корректно его использовать. Сложный момент в этом случае — уникальная идентификация объектов, например, платежей или покупателей, если они могут создаваться из разных систем. А еще одна система может их создавать из нескольких агентов, процессов или потоков, запущенных параллельно и обрабатывающих различные входящие потоки. И здесь появляется вопрос — откуда взять уникальный номер?
Есть два варианта. В-первых, можно использовать номера из последовательности или guid. Но тогда важно сначала записать этот номер в собственную БД и завершить транзакцию, и только потом — отправлять сообщение. А в следующий раз отправлять сообщение с использованием этого номера. Почему? Потому что процесс мог упасть сразу после отправки сообщения, которое, тем не менее, успело уйти адресату и было обработано. Об этой тонкой разнице — что изменения в БД сбрасываются и фиксируются только по завершении транзакции, в то время как сообщение в очередь улетает по другим каналам и сразу после обращения, — часто забывают, что приводит к дубликатам, причем не всегда на уровне кода, который разработчик пишет явно. Это может быть скрыто в недрах фреймворка, который облегчил труд разработчика, но создал проблемы для службы поддержки, разбирающейся с инцидентами.
Поэтому лучше использовать второй вариант — когда мы конструируем уникальный идентификатор на основе данных, доступных и видимых пользователю. Например, использовать уникальные в передающей системе номера документов с префиксом типа. А при необходимости добавить номер экземпляра приложения для распределенных систем — тоже в терминах пользователя, а не внутренних, — например, в виде номера магазина или номера склада. Такой подход дает дополнительное преимущество при разборке инцидентов: номера документов уже представлены на интерфейсах пользователя и в случае проблем он может всегда визуально проверить идентичность документов и понять, прошла ли передача свежих изменений или он работает со старой версией.
Правда, тут нужно учитывать, что уникальные атрибуты иногда изменяют свои значения, чтобы корректно с этим работать. Например, в справочнике сотрудников часто их обозначение по умолчанию формируется из имени-фамилии, а в тех редких случаях, когда есть два сотрудника с совпадающими именами, забота об уникальном обозначении возлагается на пользователя, который создает запись. Он может решать ее по-разному, например, добавить подразделение для одного или для обоих. Если однофамилец уже уволился, может быть изменено именно его обозначение, а не у вновь поступающего. Еще в справочниках сотрудников надо учитывать, что люди меняют документы, имена и фамилии, но остаются при этом теми же самыми людьми. В том числе — в памяти людей новая фамилия может не сразу запомниться всеми сотрудниками — потому поиск полезен по обоим.
Отдельно нужно решать задачу, когда мы проектируем централизованный сервис ведения сотрудников или покупателей, а заведение объектов может выполняться не через собственные интерфейсы, а через интеграцию из других систем. Различайте ситуации online-интеграции — когда сервис обеспечивает уникальность обозначения через специальные вызовы API и периодическую интеграцию, когда новый клиент уже заведен в передающей системе и для него зарегистрированы заказы и договора, связанные ссылками. Таких систем может быть несколько, и нам нужно различать, занесен ли в базу данных один и тоже клиент дважды или совершенно случайно и практически одновременно пришли делать заказ однофамильцы. В этом случае мы можем использовать дополнительную идентификацию — по номеру телефона, электронной почте или номеру паспорта, — только опять же учитывая, что у человека может быть несколько телефонов и паспортов, а еще муж может делать заказ для жены, указывая при этом свой email, но ее телефон — для курьера (или наоборот).
Так что идентификация сущностей — нужна, и очень плохо, когда в какой-то системе она невозможна. Как-то, разрабатывая интеграцию с одной легаси-системой, мы столкнулись с тем, что таблица платежей при выгрузке не имеет первичного ключа — платежи были привязаны к договорам, имели платежные реквизиты, дату и сумму. И оказалось, что платеж на крупную сумму клиент технически мог разбить на несколько из-за каких-то своих соображений, например, прислав два одинаковых платежа на 50 тысяч вместо одного на 100. Или пять по 20. В одной выгрузке могли прийти четыре одинаковых платежа по 30 тысяч, а в следующей одна из сумм менялась — приходило 20 + 30 + 30 + 30, — потому, что при вводе платежей сумму последнего забыли поправить, а потом ошибку заметили. Полная витрина выгружалась несколько раз в день, и приходилось сопоставлять поступившие данные с уже существующими, учитывая эту особенность платежей.
Во всех этих ситуациях надо опираться на бизнес-уровень, устройство мира, чтобы сделать для пользователей эргономичное решение. Типичная ошибка — отказ от разбора всех этих сложностей и использование каких-нибудь автогенерируемых ключей или guid, которые начинают фигурировать во всех внутренних журналах обмена, а на интерфейсах остаются недоступными. Я хорошо понимаю чувства сотрудников поддержки, которым в запросе к БД приходится вводить guid с print screen, который прислал пользователь в описании инцидента. И желаю разработчикам беречь свою карму, не становясь объектом таких эмоций.
Таким образом, остаются и ключи, и идентификация сущностей, и номера версий, используемые чтобы избежать параллельного двойного редактирования. Просто шаблоны использования в случае интеграции сервисов нужны другие, чем при реализации обычного клиент-серверного приложения, работающего с базой данных. Шаблоны нужно выбирать сознательно, а не механически переносить. Например, номера версий важны даже в том случае, когда отправляющая система сама заботиться о последовательном редактировании и набор записей по бизнесу поступает только из нее (потому что она является владельцем справочника или записей в нем), — как защита от нарушения последовательности обработки сообщений и их потери.
Потери и дубли сообщений
Контроль последовательности сообщений может быть возложен и на базовый уровень, обеспечивающий передачу сообщений –, но только если этот уровень реально это может реализовать. Далеко не всякая очередь обеспечивает гарантированную доставку, а механизмы, обеспечивающие гарантию доставки, могут порождать дублирование сообщений — так уж оно устроено. Поэтому все подобные решения нужно принимать с учетом конкретных выбранных технологий, понимая, что в будущем они могут ограничивать их смену для интеграции того же справочника с другой системой (которая выбранную технологию не поддерживает). А всякие гейты между разнотипными очередями часто хорошо работают только с простой передачей, но не со сложными случаями потерь и дублирования сообщений на каналах связи.
Дублирование и потери могут возникать не только на транспортном уровне, но и при обработке сообщений. Часто производительность обработки обеспечивается тем, что запускается несколько обработчиков сообщений для одной очереди. И возникает следующая проблема: если такой обработчик выбрал сообщение и упал по ошибке, то сообщение теряется. А если он удаляет сообщение только после обработки, то необходимы специальные меры, чтобы несколько обработчиков не начали обрабатывать одно и то же сообщение.
Хорошо, если корректную многопоточную очереди обеспечивает базовый уровень. Если же нет, приходится реализовывать это самостоятельно, исключая одновременную выборку сообщения несколькими обработчиками, но отслеживая ситуации, когда сообщение так и осталось необработанным, потому что процесс его забрал и умер.
Идемпотентные операции в этом случае хороши тем, что сообщение действительно можно попробовать обработать повторно, и если проблема была временной и связана, например, с блокировкой ресурсов, приводившей к отказу по timeout или deadlock, то повторная обработка будет безопасна и успешна. А вот в случае повторяемых ошибок это не поможет, и надо принять меры, чтобы после запуска очередного задания на обработку не начиналась обработка 100500 сообщений с воспроизводимыми ошибками, с которыми служба поддержки еще не успела разобраться по каким-то причинам.
Пример — передача документов
Идемпотентные операции можно и нужно применять на любых технологических стеках, а не только на современных очередях с передачей сообщений.
Когда-то давно мы именно таким образом реализовывали передачу накладных в старую систему, за которой к тому же сохранялась функция параллельного учета, пока переносился весь ее фунционал в новые системы. Транспорт был файловый, поскольку технологические стеки были плохо совместимые. Специальная задача просматривала директорию с появляющимися файлами и по одному их обрабатывала. Начинала она с того, что проверяла имя файла, которое формировалось из номера документа, в технологической таблице в принимающей системе. Если эту накладную уже начали обрабатывать, задача находила ее в системе и проверяла, до какой строки дошла обработка накладной, чтобы продолжить с прерванного места. Накладные могли быть очень большие, поэтому мы использовали построчный commit.
Через некоторое время после внедрения поток возрос так, что одна задача уже не успевала передавать накладные, поэтому мы создали несколько процессов и механизм, исключающий параллельную передачу, но учитывающий, что процесс задача могла взять накладную в работу и упасть, не завершив передачу.
Кстати, там выяснилась интересная особенность файлового транспорта в использовавшейся операционной системе: она не позволяла блокировать файл на уровне ОС, пока он полностью не записался, хотя документация говорила, что это возможно. И несколько раз были инциденты, когда читающая задача записывала неполную накладную — передающая система просто не успевала записать файл до конца. Выходом оказалась запись в файл с другим шаблоном имени и ее переименование. Как альтернативу можно применять перемещение между директориями, но тут может возникнуть нюанс, зависящей от физического расположения файлов — в одних случаях такое перемещение выполняется на уровне каталогов и мгновенно, а в других ОС превращает его в копирование, и тогда могут быть инциденты с чтением неполного файла.
Если вы думаете, что вопросы файлового транспорта — это далекое прошлое и не актуально сейчас, то вы ошибаетесь. При большой разнородности технологических стеков, при интеграции с legacy это часто оказывается наиболее простым и устойчивым способом интеграции, а иногда — и единственно возможным. Файловый транспорт может выручить в совершенно неожиданных ситуациях технологических ограничений.
Например, в одной компании с древних времен была развернута система файловой интеграции для передачи между разными площадками различных данных. Постепенно, с обновлением технологий, ее использовали все меньше и меньше систем, и казалось, что она вот-вот умрет. Но неожиданно у нее появилась вторая жизнь и место в новой экосистеме. Между площадками потребовалось передавать рекламное видео в HD-формате. Именно передавать — показывать с удаленного сервера было нельзя, так как при локальных провалах скорости канала связи возникали проблемы воспроизведения. И вдруг выяснилось, что невозможно просто цеплять видео к письмам. Да, письмо доходит. Но почтовая система на время передачи этого письма съедает весь доступный канал, она не умеет иначе. На практике это означало, что на несколько минут связь между площадками прерывалась. И конечно, никому не хотелось, чтобы эта часть трафика существенно грузила канал. Вот тут-то и вспомнили про развернутую систему старой интеграции — так как она была сделана еще во время очень слабых каналов, она умела уверенно передавать по ним даже большие файлы, а также конфигурировать ограничения для разных типов передачи.
Публичные протоколы
Использование идемпотентных операций особенно важно при проектировании публичных протоколов. Я хочу отметить протокол обмена документами с таможенной службой, который как раз ориентирован на то, что отправитель сам присваивает номер документа при отправке, а потом дальнейшие изменения к документу посылает с использованием этого номера. Создание и изменение различаются, и это — защита от случайного повторного использования номера. Также нужно позаботиться о сохранении присвоенного номера в собственной базе данных отказоустойчивым способом до отправки сообщения, чтобы в случае различных сбоев можно было восстановить состояние обмена.
И этим протокол таможенной службы выгодно отличается от отправки чеков в налоговую. В ФНС протокол сделан без всяких уникальных номеров, что легко приводит к дублированию чеков. В случае сбоя и отсутствия кода ответа у вас нет надежного способа выяснить, был ли чек отправлен в налоговую. А дополнительную прелесть интеграции приносит тот факт, что отправка происходит не напрямую, а через фискальные принтеры с проприетарной прошивкой, которая сама по себе работает неустойчиво и с ошибками. В некоторых версиях прошивки это приводило к тому, что содержимое фискальной памяти могло рассинхронизоваться с отправленными в налоговую чеками, что требовало отдельного урегулирования.
На этом я завершаю вторую статью про интеграцию. Продолжение следует…
28 января в 19:00 МСК ждём вас на онлайн-митап «DevOps Life Cycle», который вместе проводят Онтико и Deutsche Telekom IT Solutions.
Инженеры и технические менеджеры Deutsche Telekom IT Solutions поделятся опытом, как они находят узкие места, используют метрики, ищут пути решения для разных кейсов и готовят IAC. Поговорим о жизненных циклах создания продукта и обсудим проблемы, возникающие на разных итерациях жизненных циклов, pipelines и workflows и подходы к их решению.
Участие бесплатное, необходима регистрация.
А на конференциюDevOpsConf 2021 открыт прием заявок на доклады. Конференция пройдет 20 и 21 мая в Radisson Slavyanskaya. Это хорошая возможность предложить свои инсайты экспертному сообществу и в то же время обсудить идеи и предложения по развитию своих процессов и помочь единомышленникам в их задачах. А еще можно получить тренинги и консультации от ведущих специалистов отрасли и гуру публичных выступлений, да и просто засветиться на всю страну :)
Мы ждем ваши заявки!
