Как с помощью AI-интеграций повысить популярность проекта
 Сергей
СергейВедущий инженер-программист Иностудио
Рассказываем о том, как внедряли новомодные AI-инструменты в проект. Как это повлияло на его популярность и что за этим последовало — читайте в статье.
Технические особенности проекта:
Фреймворк — Laravel
БД — PostgreSQL
Кэш/очереди — Redis
Архитектура — основной кластер DigitalOcean Kubernetes и графический кластер GKE

Как с помощью AI-интеграций повысить популярность проекта
О самом приложении
Изначально проект задумывался как сайт с набором инструментов для работы с документами и изображениями. Сайт содержит различные утилиты конвертации, преобразования и редактирования контента. После удачного старта и растущей популярности клиент принял решение о расширении инструментария.
Было решено интегрировать дополнительные инструменты для работы с видеоконтентом и продолжить работу над актуальностью ранее созданных. Но после анализа состояния проекта один из векторов дальнейшего развития заключался в работе c AI-решениями. О них и пойдёт речь в этой статье.
Утилита «Удаление и замена фона фотографий»
Технические особенности:
OpenCV, Pillow, Numpy, Onnxruntime
Остановимся на особенностях реализации. За основу мы взяли инструмент remBg. Он построен с использованием целого набора библиотек, указанных выше.
Алгоритм работы.
Открывается изначальное изображение:
…
input = cv2.imread(input_path)
…И происходит приведение к объекту Pillow:
…
if isinstance(data, PILImage):
return_type = ReturnType.PILLOW
img = data
elif isinstance(data, bytes):
return_type = ReturnType.BYTES
img = Image.open(io.BytesIO(data))
elif isinstance(data, np.ndarray):
return_type = ReturnType.NDARRAY
img = Image.fromarray(data)
…Прогрузка натренированной ранее модели на основе U2net в данном случае:
…
session = new_session("u2net")
…Получение маски исходного изображения на основе прогноза:
…
ort_outs = self.inner_session.run(
None,
self.normalize(
img, (0.485, 0.456, 0.406), (0.229, 0.224, 0.225), (320, 320)
),
)
pred = ort_outs[0][:, 0, :, :]
ma = np.max(pred)
mi = np.min(pred)
pred = (pred - mi) / (ma - mi)
pred = np.squeeze(pred)
mask = Image.fromarray((pred * 255).astype("uint8"), mode="L")
mask = mask.resize(img.size, Image.LANCZOS)
…Форматирование полученной маски (сглаживание, обработка) с помощью OpenCV:
…
mask = morphologyEx(mask, MORPH_OPEN, kernel)
mask = GaussianBlur(mask, (5, 5), sigmaX=2, sigmaY=2, borderType=BORDER_DEFAULT)
mask = np.where(mask < 127, 0, 255).astype(np.uint8) # convert again to binary
…Наложение маски на исходное изображение:
…
empty = Image.new("RGBA", (img.size), 0)
cutout = Image.composite(img, empty, mask)
…Сохранение нового изображения:
…
cv2.imwrite(output_path, output)
…Это «в двух словах» о принципе работы утилиты.
Для своих целей мы взяли реализацию для CLI, добавили необходимые для работы типы изображений и их обработку. Напомню, что у нас стояла задача не только удалять, но и менять фон, если это необходимо. Поэтому добавили ещё метод заливки фона из изображения или просто цветом:
def add_image_as_background(bg_image_path: str, image: Image.Image) -> Image.Image:
pre_processing = pre_process_file(bg_image_path)
target_image = image.convert("RGBA")
................................................
................................................
# Ресайз, если необходимо из расчётов
target_image = target_image.resize((w_size, h_size), Image.ANTIALIAS)
................................................
................................................
# Совмещение
pre_final = Image.alpha_composite(bg_img, pre_final)
return pre_final
.................................................
def add_background_color(color, image: Image.Image):
new_image = Image.new("RGBA", image.size, color)
new_image.paste(image, (0, 0), image)
return new_imageВ репозитории remBg можно выкачать уже обученные модели или обучить свою. Для уже обученных используется U2net и DUTS-TR dataset. Для более подробной информации есть описание. Для наших целей пока что достаточно обученных.
Скриншот утилиты:
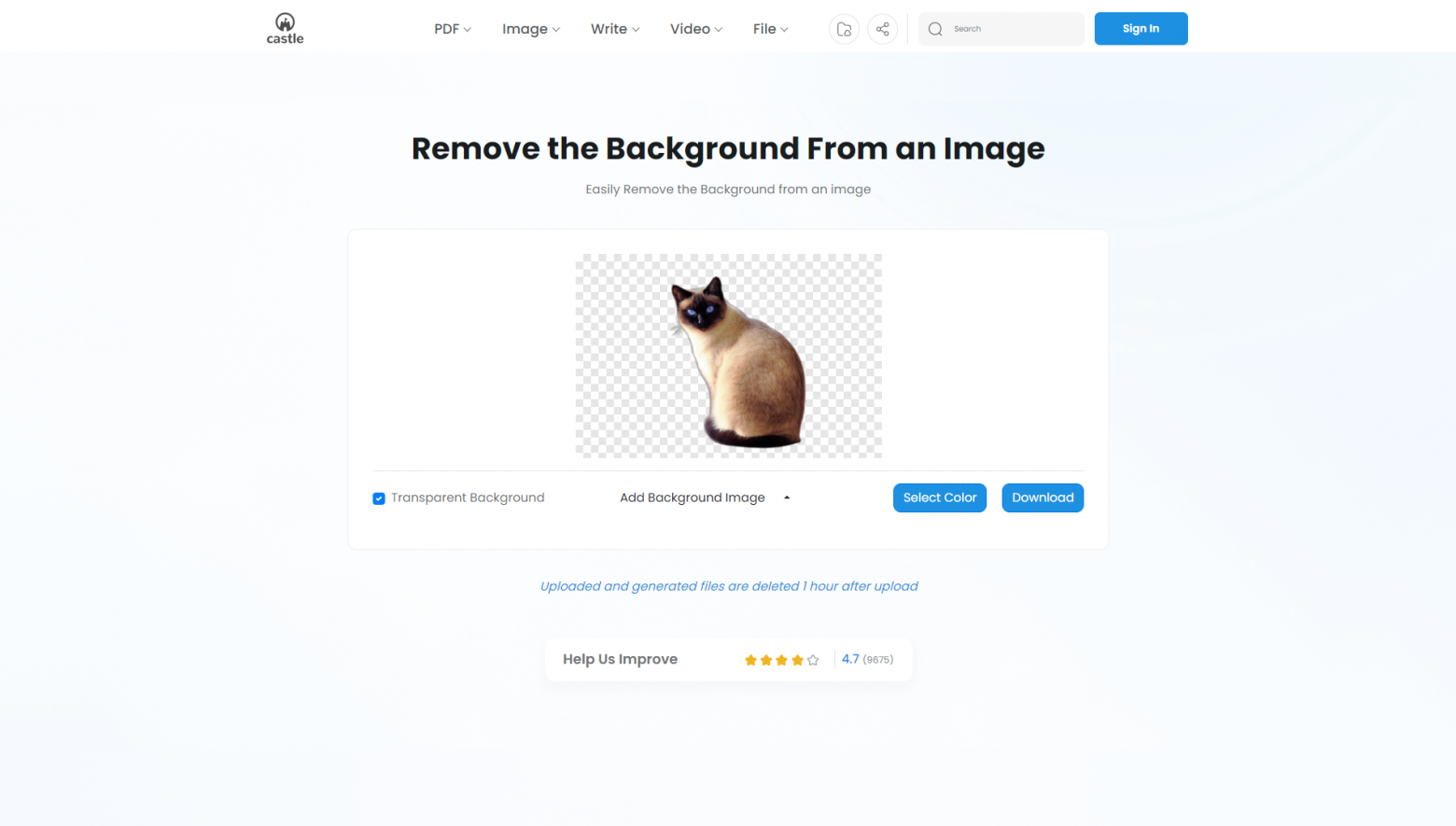
Удаление объектов с картинки
В дальнейшем использовали эту реализацию для Profile Photo Maker — более продвинутого инструмента в виде конструктора.
О «внутренностях» продукта
Для каждого типа утилит используется своя очередь.
При обработке, например джобы, происходит обновление статусов в БД, вытаскивается исходный файл из digitalOcean space. После этого задача отправляется на обработку через драйвер.
В качестве основы для драйвера взяли https://github.com/alchemy-fr/BinaryDriver Он отлично себя зарекомендовал в реализации PHP-FFMPEG.
Используется symfony/process для обработки с необходимой нам обёрткой в виде класса Abstract Binary.
Основной метод формирует CLI-команду в таком виде:
public function removeBg($input, $destination, $bgInput = null, string $color = null): RmbgTranscoder
{
try {
$rembgArg = [
config('services.rembg'),
'--input_path=' . $input,
'--output_path=' . $destination,
];
if (isset($color)) {
$rembgArg[] = '--color=' . $color;
}
if (isset($bgInput)) {
$rembgArg[] = '--bg_image_path=' . $bgInput;
}
$this->command($rembgArg);
} catch (ExecutionFailureException $e) {
throw new Exception('RemBg library was unable to remove background from image (command)', $e->getCode(), $e);
} catch (Exception $e) {
throw new Exception('RemBg library was unable to remove background from image (command) common exception',
$e->getCode(), $e);
}
return $this;
}
Всё просто.
Утилита «Генератор изображений»
Изначально работали со Stable Diffusion версии 1.4.
На huggingface довольно неплохо описан стандартный способ интеграции. Однако на нашей сборке GKE с T4 GPU возникли проблемы производительности, которые не удовлетворяли клиента.
Что такое Stable Diffusion
Stable Diffusion — это целый набор компонентов и моделей для преобразования текста в изображение. На первом этапе происходит преобразование текста в токены с помощью нейронки CLIPText. Далее текстовые токены и массив информации изображения (latent) отправляются в скрытое пространство нейросети Unet. Там происходит процесс диффузии с необходимым количеством итераций и последующая конвертация полученной после обработки информации в картинку.
Здесь, как мне кажется, отлично описали алгоритм.

Stable Diffusion
Сейчас у нас запущена обработка на более современной модели.
В качестве метода обработки входного шума остановились на семплере DDIM (Denoising Diffusion Implicit Models) в 50 шагов. Наиболее оптимальные для нужд клиента результаты и время обработки. Upscaler не используем после получения результата — отдаём в 512×512.
Вернёмся к нашей проблеме.
Для оптимизации стали использовать библиотеку diffusers, которая представляет собой некоторый набор диффузионных моделей, доступ к которым можно получить в две строки. Плюс переключили на загрузку весов float16 вместо float32.
Помимо этого установили xFormers для оптимизации памяти. Библиотека оптимизирует использование видеокарт Nvidia на архитектурах Pascal, Turing, Ampere (30XX), Lovelace (40XX) или Hopper (GH100).
В целом генерация вышла на комфортные 10 секунд. Однако выгрузка модели при «холодном» запуске занимает ещё около 10 секунд. То есть это время просто теряется, несмотря на то, что мы храним модель на ssd volume без предзагрузок. Был вариант написания «демона» для того, чтобы модель была всё время в памяти. Но пообщавшись с разработчиками, пришли к выводу не инициализировать веса с помощью device_map=«auto».
Это привело к значительному ускорению при инициализации. Рекомендации по поводу этого добавили в релиз и документацию, кстати
