Как работает оптимизатор PostgreSQL при большом количестве соединений
SQL — это декларативный язык программирования, используемый для создания и манипулирования объектами в реляционных СУБД. Этот язык описывает что должно быть получено, но не описывает как это получить. Программист пишет запрос и (чаще всего) хочет получить результат от СУБД максимально быстро.
Работу по нахождению самого лучшего способа получения требуемых данных выполняет планировщик (он же оптимизатор) запросов. Он выбирает способы соединения наборов строк и их обработки, строит различные планы выполнения запроса и находит среди них наилучший, для чего используется стоимостная модель оптимизации.
Поэтому оптимизатор — это ключевая часть СУБД, один из самых сложных элементов всей системы.
Для демонстрации работы оптимизатора практически во всех наших (и чужих) примерах на эту тему используются довольно скромные параметры: две-три таблицы, пара JOIN-ов, миллисекунды на выполнение запросов. А что будет, если загрузить оптимизатор десятками таблиц за раз? Как разные конфигурационные параметры влияют на производительность запросов с сотней JOIN-ов? И переживет ли это среднестатистический рабочий ноутбук? Ответы на эти вопросы — со схемами и графиками — вы найдете под катом!
Теоретическая часть
Подробно принципы работы оптимизатора, способы доступа к данным и алгоритмы соединений наборов строк в PostgreSQL изложены, например, компанией Постгрес Профессиональный в учебном курсе «QPT. Оптимизация запросов», в серии статей Егора Рогова «Запросы в PostgreSQL» и в книге того же автора «PostgreSQL изнутри».
Ниже будет рассмотрен этап планирования запросов.
Общий алгоритм работы оптимизаторов современных реляционных СУБД состоит из трех взаимосвязанных частей:
- Строятся все возможные способы соединений перечисленных в запросе наборов строк;
- Оцениваются стоимости этих планов;
- Выбирается план с минимальной оценкой стоимости.
Наиболее известный метод оптимизации — это алгоритм динамического программирования, с помощью которого можно найти наилучший план выполнения для данного запроса.
Однако, хотя с его помощью можно найти наилучший по стоимости план выполнения запроса, но алгоритм динамического программирования требует ресурсов (хоть и меньше, чем при полном переборе всех возможных вариантов) — времени для своего выполнения и памяти для хранения промежуточных планов. И расход этих ресурсов возрастает экспоненциально при увеличении числа таблиц в запросе.
А дальше начинаются детали и уточнения.
Речь будет идти про оптимизатор PostgreSQL.
Сервер выполняет следующие этапы при обработке запроса:
- Разбор (синтаксический и семантический) — текст запроса разбивается на лексемы, проверяется что эти лексемы входят в состав языка. На выходе этого этапа появляется сформированное дерево разбора;
- Переписывание — запрос может быть дописан, например, добавлен текст представления. В результате дерево разбора запроса может быть дополнено;
- Планирование — выбор оптимального плана выполнения запроса. На вход этого этапа поступает дерево разбора;
- Выполнение — непосредственное выполнение найденного оптимального плана.
Акцентируем внимание на важных для данной статьи моментах. Сервер PostgreSQL работает не над текстом запроса, а над деревом разбора, в котором описана только синтаксическая структура запроса, но нет информации в каком порядке проводить операции.
Запрос можно написать разными способами — перечислить таблицы через запятую, использовать ключевое слово JOIN, либо использовать смешанный вариант (не рекомендуется). Хотя результат работы таких запросов будет идентичен, но синтаксическая структура запроса будет отличаться (ниже показано как именно она будет отличаться). А раз отличается синтаксическая структура — то и оптимизатор PostgreSQL будет обрабатывать эти запросы по-разному.
Если в запросе таблицы перечислены через запятую, тогда оптимизатор будет перебирать все возможные комбинации попарных соединений всего списка FROM:
EXPLAIN ANALYZE SELECT * FROM
tb_1, tb_2, tb_3, tb_4, … t_100
WHERE id1 = id2 AND id2 = id3 AND id3 = id4 AND … AND id99 = id100;
Схематично это можно показать так: 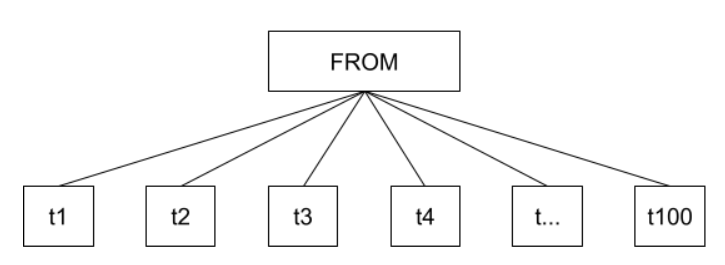
То есть, будут перебираться все возможные способы соединений всех таблиц из списка между собой без какой-либо дополнительной обработки. Сложность и стоимость перебора растет экспоненциально по мере увеличения количества таблиц в списке — вплоть до момента, когда ресурсы сервера будут исчерпаны и он упадет.
PostgreSQL предлагает альтернативу такому подходу с полным перебором — генетический алгоритм GEQO. Он позволяет найти близкий к оптимальному план запроса за гораздо более разумное время. Генетический алгоритм GEQO будет работать, если включен параметр geqo и число элементов в списке FROM равно значению параметра geqo_threshold.
На графике ниже, не вдаваясь в подробности методики тестирования, сразу можно увидеть граничный момент (пик), после которого начинает свою работу генетический оптимизатор. В данном случае значение geqo_threshold установлено в 12, а join_collapse_limit = 14. То есть, используется стандартный способ оптимизации пока в списке не станет 12 таблиц (чтобы был виден экспоненциальный рост времени планирования), а далее «включается» генетический алгоритм — пик на графике:
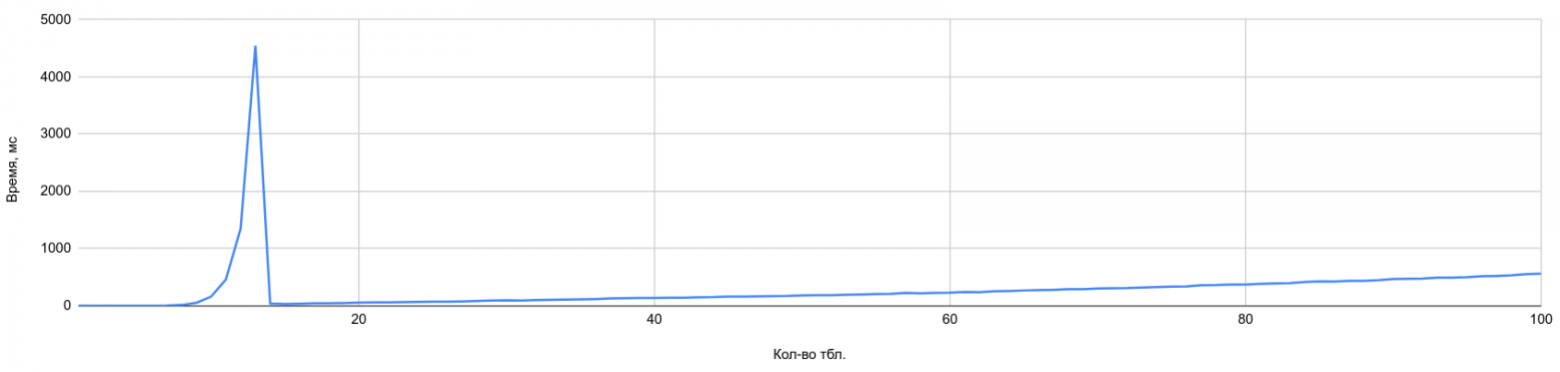
Формально идентичный запрос можно написать иначе — например, воспользовавшись рекомендованным в стандарте SQL ANSI способом соединения таблиц с помощью ключевого слова JOIN. В этом случае часть дерева разбора, где представлены соединения, будет выглядеть следующим образом (рассматривается вариант с настройками сервера по умолчанию): 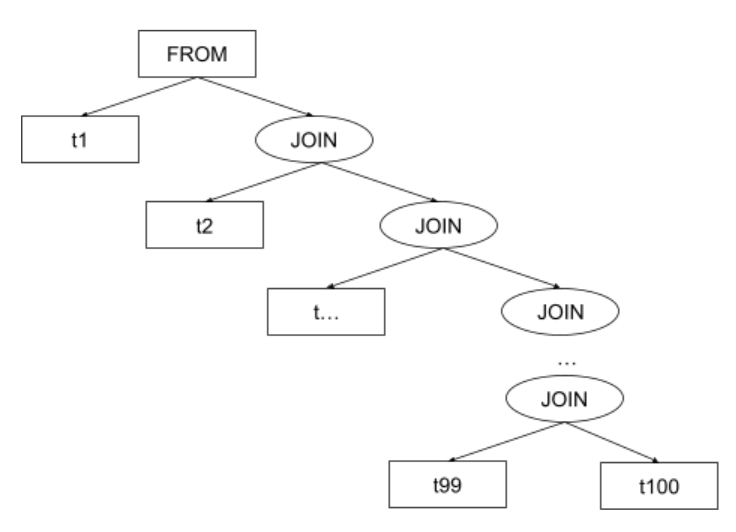
То есть, в отличии от прошлого варианта, здесь есть структура соединений. И, если оставить эту структуру без изменений, то оптимизатор PostgreSQL смог бы только переставлять местами таблицы в уже представленных парах (например, t99 <-> t100), но соединить t1 и t100 он никогда бы не смог. Поэтому, ему нужно каким-то образом обработать дерево соединений — привести его примерно к тому же виду, который был в случае перечисления таблиц через запятую.
Оптимизатор уплощает (выравнивает в одну плоскость) дерево соединений снизу-вверх. Но уплощение происходит только в том случае, если в уплощенном списке будет не больше join_collapse_limit элементов. То есть, для join_collapse_limit и количества таблиц в запросе равным 4 планировщик сначала соединяет (произвольным образом) таблицы t2-t5, а затем результат соединяет с таблицей t1. Уплощенное дерево будет выглядеть следующим образом: 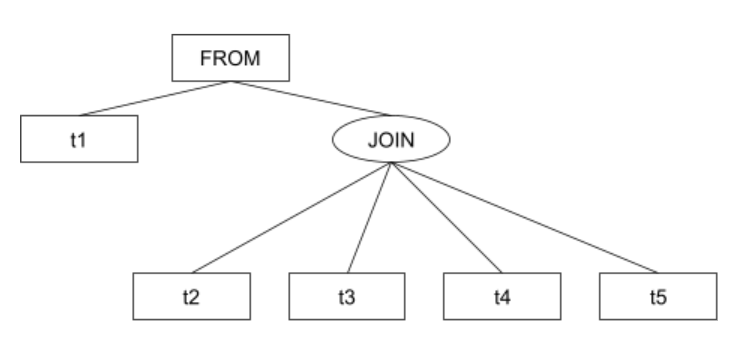
Но еще интереснее посмотреть на дерево для чуть большего количества таблиц в запросе, например — для восьми и join_collapse_limit = 4.
Схематично, принцип работы оптимизатор можно отобразить следующим образом:
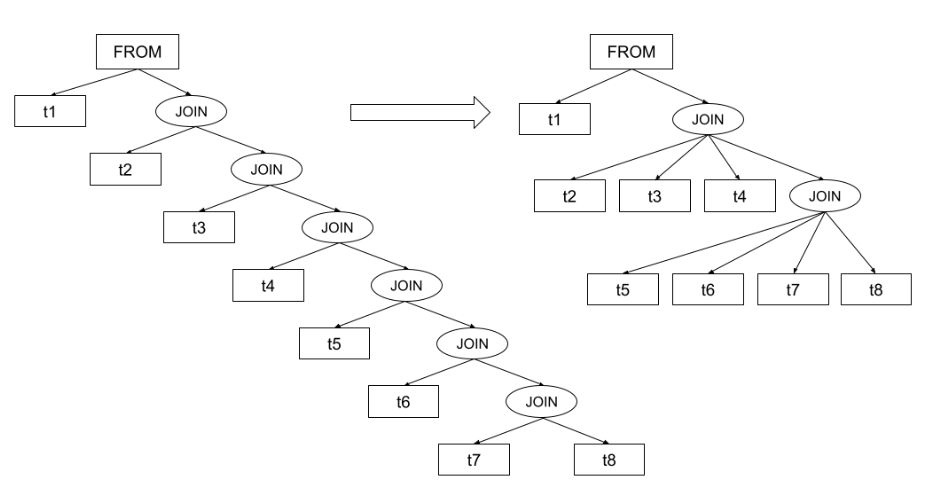
Чем больше таблиц в запросе — тем более глубокое дерево будет получаться. Однако его структура будет состоять из join_collapse_limit-таблиц на нижнем уровне и из (join_collapse_limit-1 таблиц + JOIN) на уровнях выше.
На каждом уплощенном уровне планировщик находит оптимальный способ соединения таблиц (чем их больше — тем больше тратится на это времени, как уже было сказано выше). Если на очередном уплощенном уровне есть узел JOIN, то он воспринимается как набор строк из соединения таблиц нижележащего уровня.
Но давайте проверим выше описанную теоретическую информацию ниже сделанными тестами.
Описание тестов
Для тестирования использовался ноутбук DELL 5390 с 8 Гб оперативной памяти под управлением Ubuntu 21.10; ванильный PostgreSQL 13.1.
Я сгенерировал группу запросов (в каждом следующем запросе количество таблиц увеличивается на единицу), после их выполнения получаю время планирования и высчитываю среднее время планирования десяти попыток. Использую простейшие таблицы из десяти строк:
- 100 запросов двух видов:
- через JOIN;
- через запятую;
- В каждом следующем запросе добавляется новая таблица;
- В таблицах по 10 строк;
- Получаю время планирования и сохраняю;
- Выполняю по 10 тестов, высчитываю среднее значение;
- На основе полученных данных строю графики.
Результаты тестов
В результате выполнения тестов я буду менять некоторые параметры PostgreSQL, поэтому перечислю, какие именно параметры мне потребуются (название и значение по умолчанию):
geqo = on;
geqo_threshold = 12;
join_collapse_limit = 8;
Сначала закончим рассматривать ситуацию с предыдущего графика — запросы написаны через запятую:
geqo = on;
geqo_threshold = 12;
join_collapse_limit = 14;
Напомню график:
Если увеличить значение join_collapse_limit на единицу, тогда на моем ноутбуке заканчиваются ресурсы и сервер падает, появляется ошибка: psql:queries/14:3: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
Если таблицы перечислены через запятую и этих таблиц очень много — когда-нибудь наступит момент, при котором произойдет падение сервера. Его ресурсы не безграничны. Хотя план будет выбран оптимальный (если повезет с мощностью оборудования).
Но как выполнить запрос со ста таблицами на простом ноутбуке?
Посмотрим на график выполнения ста JOIN-запросов со значениями по умолчанию.
Пример запроса:
EXPLAIN ANALYZE SELECT *
FROM tb_1 JOIN tb_2 ON id1 = id2
JOIN tb_3 ON id2 = id3
JOIN tb_4 ON id3 = id4
…
JOIN tb_100 ON id99 = id100;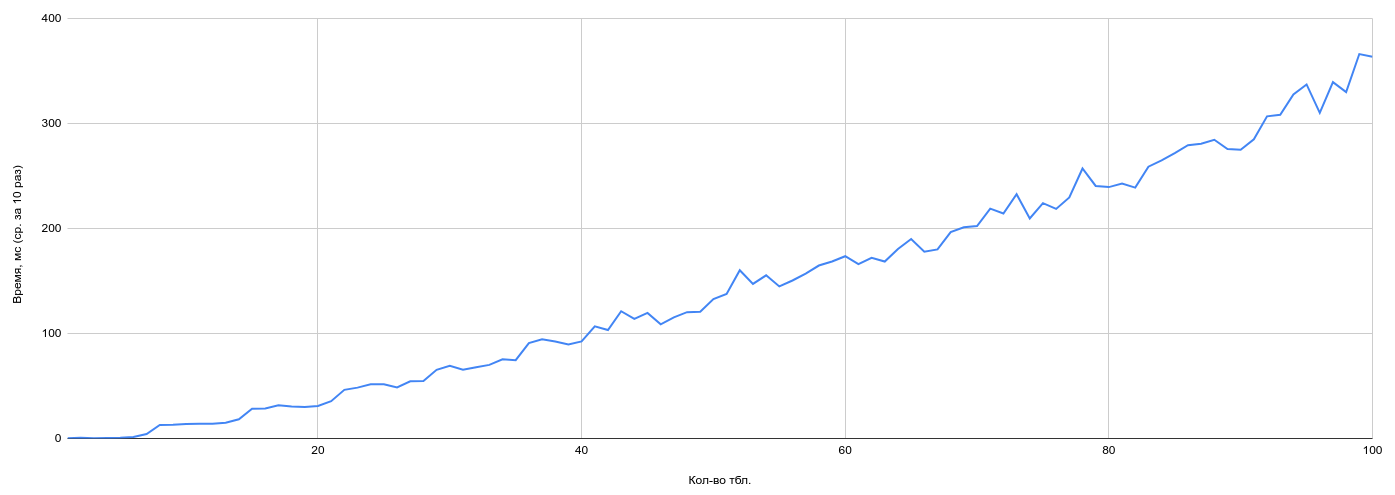
Время планирования стабильно растет в зависимости от числа таблиц в запросе. Экспоненциальный рост затрат времени на планирование здесь есть, но настройки по умолчанию позволяют избежать пика, который мы увидели на предыдущем графике при включении в работу GEQO. И даже при ста таблицах в соединении — время планирования стабильно и примерно-предсказуемо.
Выше говорилось про генетический оптимизатор GEQO — посмотрим на практике что произойдет с результатами, если его отключить:
geqo = off;
geqo_threshold = 12;
join_collapse_limit = 8;
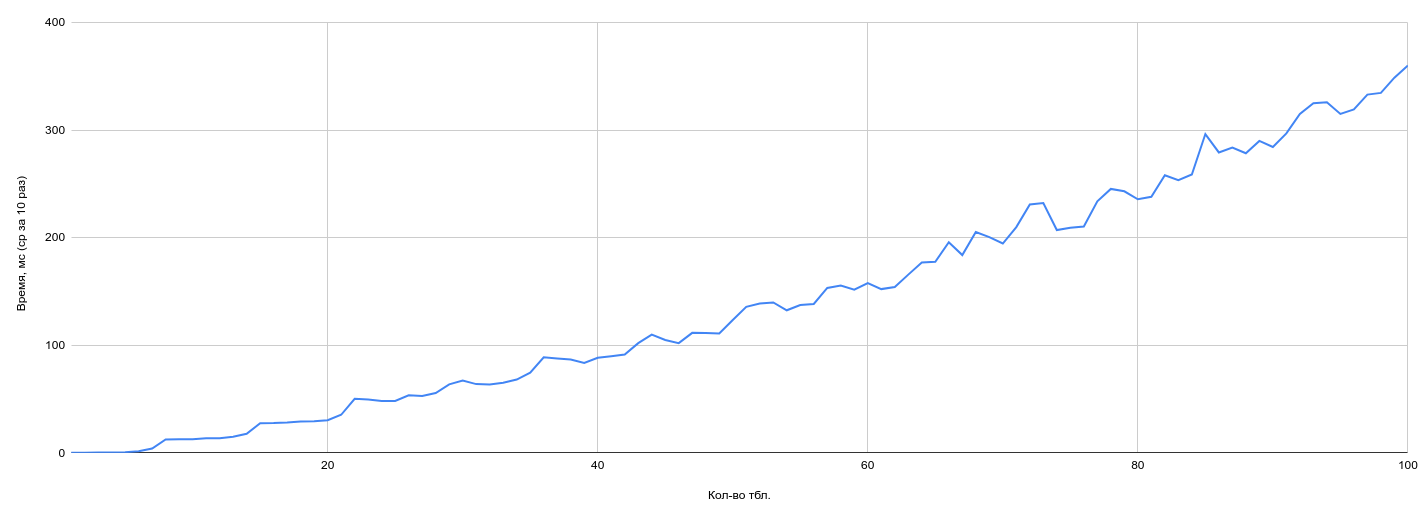
График подозрительно сильно похож на предыдущий. И это действительно так: при текущих параметрах получается что размер уплощенных групп таблиц (join_collapse_limit) меньше размером, чем граничное значение, включающее генетический оптимизатор (geqo_threshold) — при наличии структуры в запросах (использование JOIN«ов) генетический оптимизатор может вовсе не использоваться, сколько бы ни было таблиц в запросе.
А теперь рассмотрим ситуацию равенства параметров join_collapse_limit и geqo_threshold = 12:
geqo = on;
geqo_threshold = 12;
join_collapse_limit = 12;
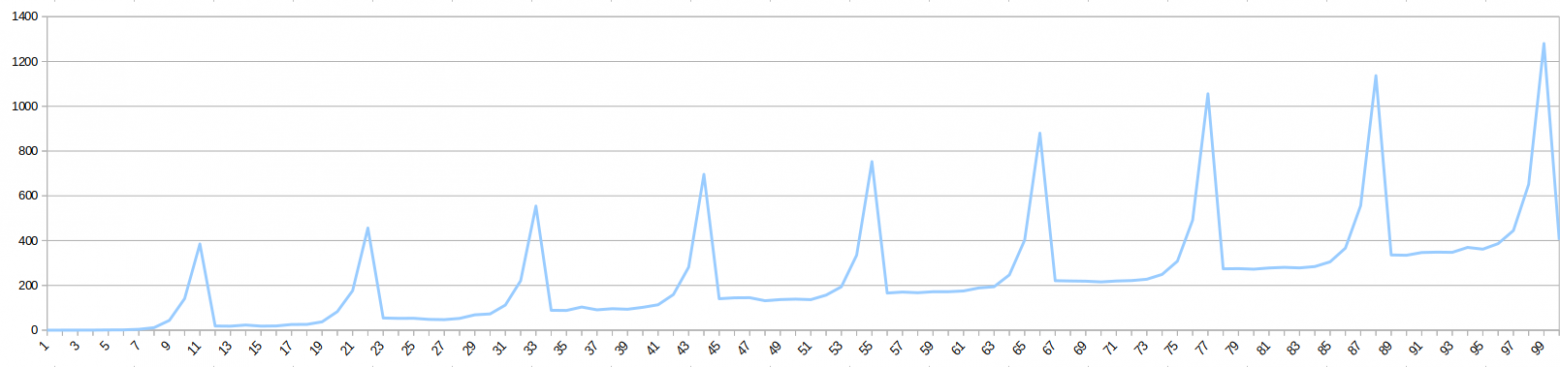
Данный тест иллюстрирует ситуацию, при которой срабатывает генетический оптимизатор — на двенадцатой таблице в запросе, при планировании следующего запроса после пика на графике.
Разберем по шагам. Представим, что в запросе:
- 11 таблиц — верхняя часть пика первого графика — до этой границы работает стандартный алгоритм оптимизации, время экспоненциально растет;
- 12 таблиц — срабатывает генетический оптимизатор — время планирования стремительно уменьшается —, но это последняя таблица в группе join_collapse_limit-элементов;
- 13 таблиц — первые 12 таблиц планируются вышеописанным способом (первый пик на графике) — начиная с 13-й таблицы формируется новый уровень при уплощении таблиц, на нем оптимизация опять происходит обычным способом, с экспоненциальной тратой ресурсов;
- 22 таблицы — верхняя часть второго пика — это два уплощенных таблицами уровня (первый уровень 12 элементов, второй — 10 таблиц плюс соединение с нижележащим уровнем) — то есть, на верхнем уровне получается одиннадцать элементов;
- 23 таблицы — на верхнем уровне суммарно 12 элементов, что опять запускает генетический алгоритм — время планированию снова стремительно уменьшается — два уровня уплощения максимально заполнены;
- 24 таблицы — формируется третий уровень уплощения — планирование происходит аналогично описанным выше шагам.
Но в данном тесте генетический алгоритм включен и в какой-то момент времени выполняет свою работу.
На следующем графике посмотрим вариант обработки ситуации когда geqo_threshold больше чем join_collapse_limit, то есть, генетический оптимизатор не срабатывает, но размер группы для обычной оптимизации большой:
geqo = on;
geqo_threshold = 13;
join_collapse_limit = 12;
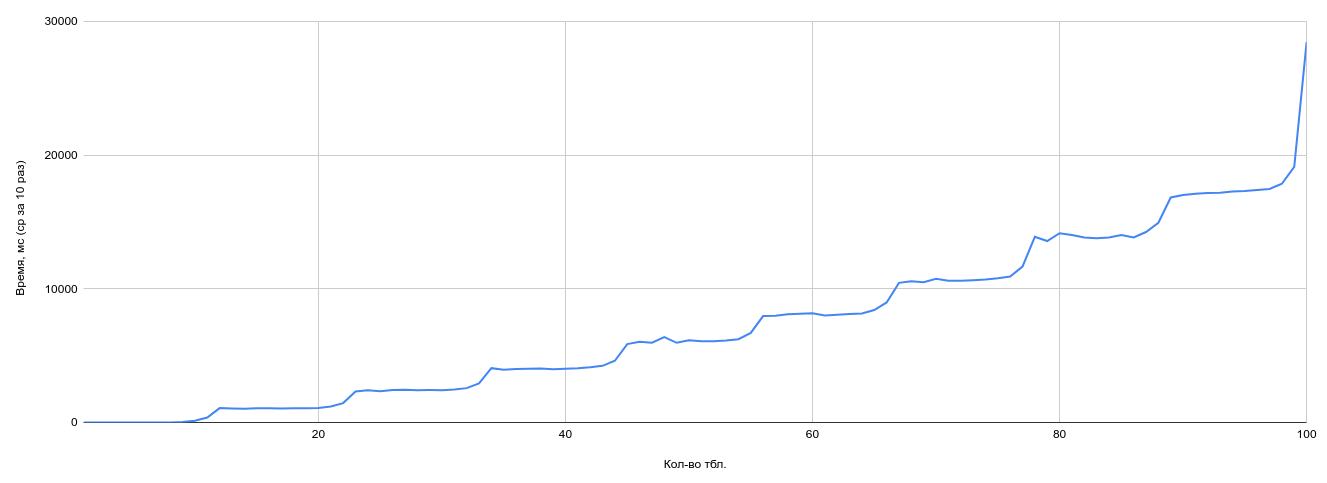
На данном графике ярко видны ступеньки размером в join_collapse_limit-элементов, генетический алгоритм не включается.
То есть, оптимизатор сначала целиком уплощает дерево соединений, затем оптимизирует группы из join_collapse_limit-таблиц стандартным способом. В случае выше — это 11 таблиц и результат первого шага оптимизации (всего двенадцать).
Оптимизация такими группами по join_collapse_limit-элементов позволяет обработать все требуемое количество таблиц в запросе, время планирования ступенчато-монотонно возрастает.
Если сравнить два последних графика и объединить их на одном — то можно увидеть, что время планирования при использовании генетического оптимизатора (синий график) получается существенно меньше, чем при использовании предыдущего способа оптимизации (красный график). Но это не означает что время выполнения тоже будет меньше.

Рассмотрев два варианты работы алгоритма — при включении генетического алгоритма (график с пиками) и без его включения (график со ступеньками), можно схематично отобразить взаимосвязь параметров join_collapse_limit (в случае ниже этот параметр увеличен до 25) и geqo_threshold (равен 11) следующим образом:
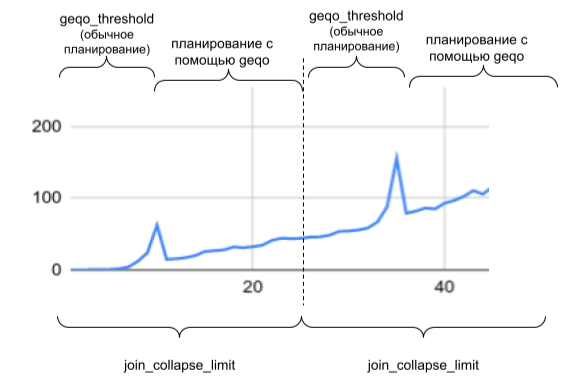
То есть, увеличивая размер join_collapse_limit мы получаем потенциально больший размер группы таблиц, при оптимизации которых будет получен наилучший план. Но слишком высокое значение поставить не получится — сервер может не выдержать.
Помимо этого, мы получаем «ступенькообразную» зависимость времени планирования от количества таблиц. Если количество таблиц в запросе находится на границе «ступеньки» и в запрос добавить еще одну таблицу — то время планирования скачкообразно увеличится. Поэтому, лучше подбирать параметры сервера таким образом, чтобы этих ступенек не было.
Зависимость времени планирования от количества таблиц проявляется и в обратную сторону. Посмотрите на синий график — при количестве таблиц равном geqo_threshold-1 время планирования увеличилось (первый пик) но, если добавить еще одну таблицу в запрос — тогда время планирования сократится почти до нуля, хотя вероятность найти оптимальный план сократится.
Выводы
В результате, для оптимизатора PostgreSQL получаем следующее:
- Если в запросе мало таблиц — можно использовать значения по умолчанию, они подобраны оптимально.
Если количество таблиц > join_collapse_limit — за качество планирования поручиться невозможно:- либо подключится генетический оптимизатор;
- либо будет сформировано несколько групп таблиц и будут перебираться не все порядки соединения.
- И в том, и в другом случае — может повезти, а может не повезти.
Поэтому управлять порядком соединений не просто можно, а нужно (если интересует стабильный результат) о чем будет рассказано в следующий раз.
