Как работает DALL-E

В Январе 2021 года Open AI показали DALL-E, генерирующую любые изображения по текстовому описанию, на хабре уже успели разобрать тему генерации изображений нейросетями, но мне захотелось разобраться в теме более детально и показать всё в коде.
Сейчас мы разберём, как работает Text2Image нейросеть DALL-E, посмотрим на хардкор математики, а также убедимся, что это сможет повторить каждый, написав реализацию DALL-E почти с нуля.
GPT
DALL-E состоит из двух нейросетей, одна из них — это GPT.
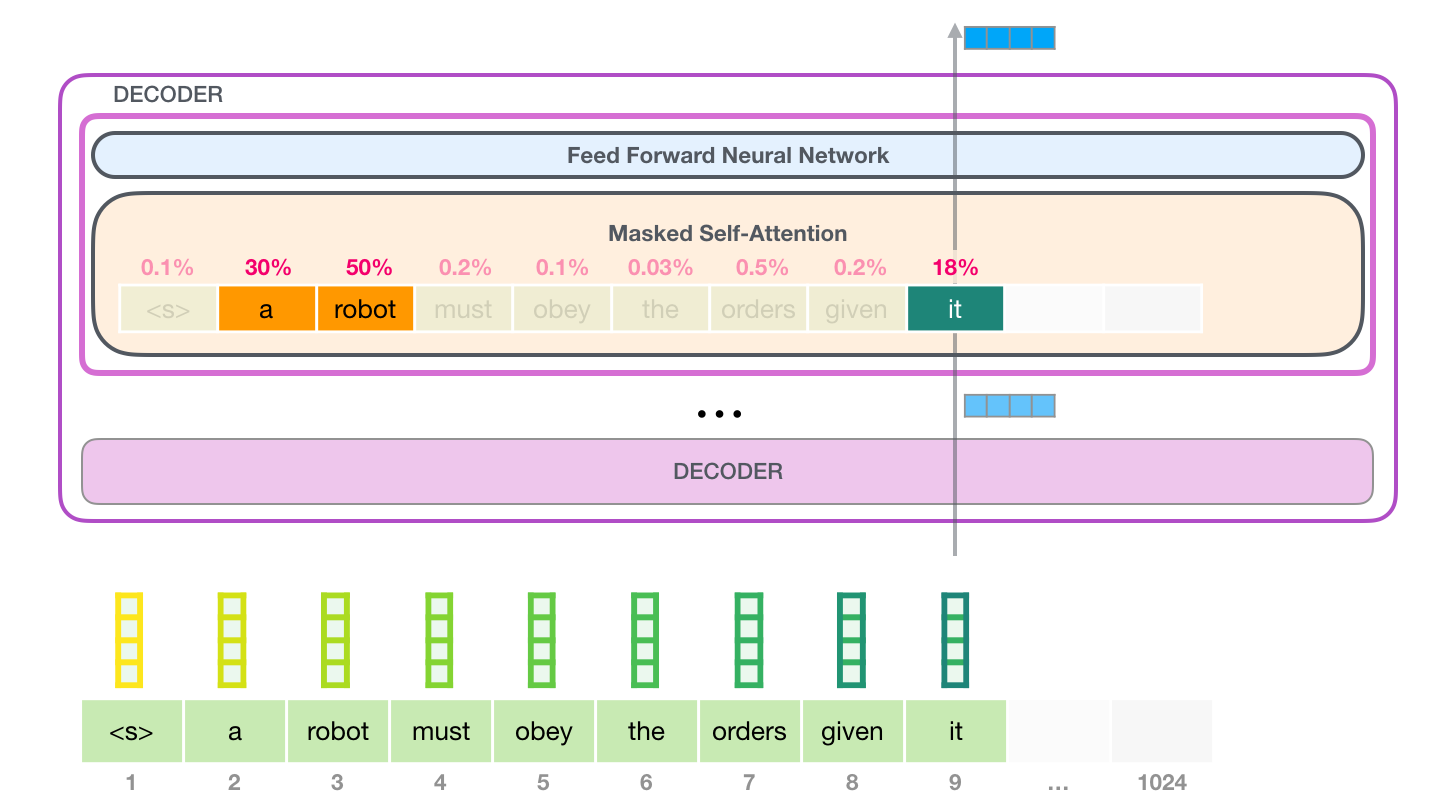
GPT пытается предсказывать последовательность токенов, на основе данной ей последовательности. Модель представляет собой архитектуру Transformers, состоящую только из Декодера. GPT учится фокусировать внимание на предыдущих словах, которые наиболее важны для предсказания следующего слова в предложении, используя механизм внимания.
▍ Attention
Механизм Attention является аналогом когнитивного внимания и позволяет находить связи между токенами, а также предсказывать продолжение этих токенов.
Для каждого токена создаётся набор векторов:
- Key — значимость токена в последовательности, если мы смотрим извне.
- Query — значимость токена в последовательности, если мы смотрим из этого токена.
- Value — репрезентация токена
Умножение вектора Query последнего токена на каждый вектор Key последовательности токенов с применением функции SoftMax даст коэффициенты значимости каждого токена.
Умножив Value каждого токена на его коэффициент, мы получим сумму Внимания всей последовательности.
Получившийся вектор мы умножаем на матрицу эмбендингов модели (всех возможных токенов словаря) и, таким образом, получаем коэффициент каждого токена словаря на соответствие входной последовательности токенов.
Она хорошо показала себя в генерации довольно натуральных текстов, которые порой нельзя отличить от написанных человеком.
VQ-GAN
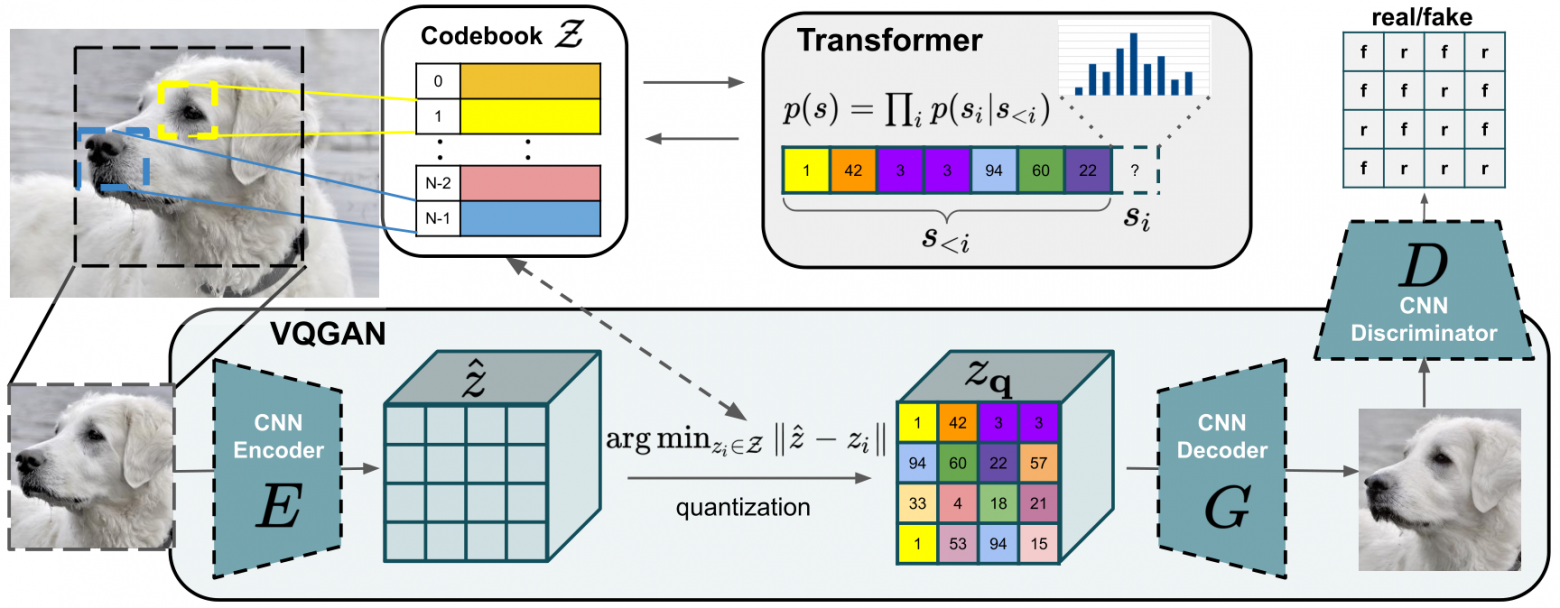
VQ-GAN способна сжимать изображение в сетку векторов (токенов) и реконструировать обратно в изображение. Нейросеть состоит из энкодера, декодера и дискриминатора.
VQ-GAN является совмещением идей VQVAE и GAN.
▍ VQ-VAE (Vector Quantized Variational Autoencoder)
Идея VQ-VAE в том, чтобы научится эффективно сжимать изображение в более низкоразмерное скрытое пространство и разжимать в скрытое пространство изображения с наименьшими потерями.
Энкодер берёт изображение размером 512×512 и сжимает (чаще всего обычными свёрточными сетями) до 256×1, ищет ближайший вектор от получившегося в скрытом пространстве, а после декодер пытается такой маленький вектор разжать обратно в изображение 512×512.
▍ VQ-VAE + GAN = VQ-GAN
Энкодер всё так же принимает на вход изображение и кодирует его в сжатый вектор, после чего подменяет на ближайшего соседа в скрытном пространстве, а Декодер разжимает этот ближайший вектор в изображение.
Тут в игру входит частичка GAN, а именно дискриминатор. Дискриминатор в процессе обучения сравнивает, насколько исходное изображение похоже на реконструированное и возвращает градиент потерь реконструкции, это помогает в дальнейшем понять Энкодеру и Декодеру, как обмануть Дискриминатор и в разы повысить качество конечных изображений.
Как это работает внутри
Энкодер преобразует изображение X в сетку скрытых векторов
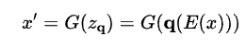
Каждый вектор в сетке подвергается квантованию с использованием функции q (ẑ)

Декодер реконструируют квантованную сетку

Для обучения VQ-GAN реконструкции картинки нам нужно как-то оценивать его работу и для этого у нас есть целых два Лосса (Функции потерь):
Эта функция потерь высчитывает, насколько хорошо модели удалось реконструировать оригинал.
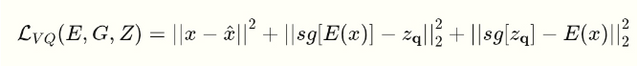
Дискриминатор делает бррр…
Кстати, дискриминатор позволяет добиться лучшей реконструкции изображений, даже из очень сжатой сетки векторов.

Теперь с помощью этой функции мы можем обучить наш декодер:
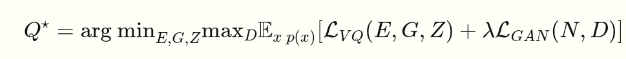
GPT + VQ-GAN = DALL-E
«Мы умеем моделировать последовательность токенов текста с помощью GPT и умеем восстанавливать изображения из набора токенов автоэнкодера, почему бы не совместить?» — подумали разработчики из Open AI и сделали DALL-E.
Далее достаточно было обучить GPT в ответ на входной текст, генерировать токены подобные VQ-GAN соответствующего изображения. На удивление — это сработало, и она научилась «переводить» естественный язык в язык модели синтеза изображений.
Сначала мы собираем датасет в формате: Текст Ӏ Картинка.
Преобразуем картинки обучающего датасета, посредством энкодера VQGAN в матрицу токенов 32×32 и учим GPT сопоставлять 128 токенов текста с соответствующими 1024 токенами изображения.
После обучения, GPT принимая на вход только текст, сможет сгенерировать матрицу токенов, которую посредством декодера VQGAN мы сможем преобразовать в картинку, соответствующую входному тексту.

Что по коду?
И, конечно, после теоретической части хорошо бы перейти к практике.
Сейчас мы воспроизведём все эти математические фокусы в код. Это легче, чем вы думаете!
(Для воспроизведения кода нужно использовать Google Colab)
▍ Установим доступную реализацию GPT
!pip install datasets &>> install.log
!git clone https://github.com/karpathy/minGPT &>> install.log
!cd minGPT; git checkout 3ed14b2cec0dfdad3f4b2831f2b4a86d11aef150
!git clone https://github.com/karpathy/minGPT &>> install.log
import sys
sys.path.append('minGPT')
import numpy as np
import torch
import torch.nn as nn
from torch.nn import functional as F
import math
from torch.utils.data import Dataset
from mingpt.model import GPT, GPTConfig
from mingpt.trainer import Trainer, TrainerConfig
from mingpt.utils import sample
import logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
▍ Установка VQ-GAN
# Это немного запутанно, но цель здесь
# - это просто для того, чтобы подготовить всё к предстоящей демонстрации.
# Загрузка предварительно обученной модели VQGAN
print('Downloading VQGAN model weights')
!curl -L 'https://heibox.uni-heidelberg.de/d/8088892a516d4e3baf92/files/?p=%2Fckpts%2Flast.ckpt&dl=1' > vqgan_im1024.ckpt
!curl -L 'https://heibox.uni-heidelberg.de/d/8088892a516d4e3baf92/files/?p=%2Fconfigs%2Fmodel.yaml&dl=1' > vqgan_im1024.yaml
#Установите требования к VQGAN
print('Installing requirements')
!git clone https://github.com/CompVis/taming-transformers &> /dev/null
!pip install einops omegaconf pytorch_lightning &> /dev/null
# Настройка VQGAN
import sys, einops, torch
sys.path.append('./taming-transformers')
from omegaconf import OmegaConf
from taming.models import cond_transformer, vqgan
from PIL import Image
from matplotlib import pyplot as plt
def load_vqgan_model(config_path, checkpoint_path):
config = OmegaConf.load(config_path)
if config.model.target == 'taming.models.vqgan.VQModel':
model = vqgan.VQModel(**config.model.params)
model.eval().requires_grad_(False)
model.init_from_ckpt(checkpoint_path)
elif config.model.target == 'taming.models.cond_transformer.Net2NetTransformer':
parent_model = cond_transformer.Net2NetTransformer(**config.model.params)
parent_model.eval().requires_grad_(False)
parent_model.init_from_ckpt(checkpoint_path)
model = parent_model.first_stage_model
else:
raise ValueError(f'unknown model type: {config.model.target}')
del model.loss
return model
print('Loading VQGAN model')
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
vqgan_model = load_vqgan_model('vqgan_im1024.yaml', 'vqgan_im1024.ckpt').to(device)
print('Dataset Prep')
!pip install openimages
!wget https://storage.googleapis.com/localized-narratives/annotations/open_images_validation_captions.jsonl
import json
with open('/content/open_images_validation_captions.jsonl', 'r') as json_file:
json_list = list(json_file)
for json_str in json_list[:5]:
result = json.loads(json_str)
import urllib3
import boto3
import botocore
import concurrent.futures
import os
from tqdm.notebook import tqdm
def _download_single_image(arguments):
if os.path.exists(arguments["dest_file_path"]):
return
try:
with open(arguments["dest_file_path"], "wb") as dest_file:
arguments["s3_client"].download_fileobj(
"open-images-dataset",
arguments["image_file_object_path"],
dest_file,
)
except urllib3.exceptions.ProtocolError as error:
_logger.warning(
f"Unable to download image {arguments['image_file_object_path']} -- skipping",
error,
)
def download_images_by_id(image_ids,section, images_directory):
# мы загрузим изображения из AWS S3, поэтому нам понадобится клиент boto S3
s3_client = boto3.client(
's3',
config=botocore.config.Config(signature_version=botocore.UNSIGNED),
)
# создайте повторяющийся список аргументов функции
# который мы сопоставим с функцией загрузки
download_args_list = []
for image_id in image_ids:
image_file_name = image_id + ".jpg"
download_args = {
"s3_client": s3_client,
"image_file_object_path": section + "/" + image_file_name,
"dest_file_path": os.path.join(images_directory, image_file_name),
}
download_args_list.append(download_args)
# используйте ThreadPoolExecutor для параллельной загрузки изображений
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
# используйте исполнитель для сопоставления функции загрузки с итерируемым набором аргументов
list(tqdm(executor.map(_download_single_image, download_args_list),
total=len(download_args_list), desc="Downloading images"))
!mkdir -p ims
def get_openimages(n_images=2000):
print('Downloading images')
download_images_by_id([json.loads(s)['image_id'] for s in json_list[:n_images]], 'validation', 'ims/')
data = [json.loads(s) for s in json_list[:n_images]]
return data
type(vqgan_model) # Наша модель vqgan загружена
▍ Настраиваем датасет
# @title изменённый набор данных теперь включает текстовые маркеры перед графическими
from torch.utils.data import Dataset
import numpy as np
max_text_length = 128
vocab = 'abcdefghijklmnopqrstuvwxzy '
def encode_char(c):
if c in vocab:
return vocab.index(c)
return 50 # 'special character'
class PatchDataset(Dataset):
def __init__(self, image_fns, labels, block_size=255, max_text_length=128):
# Перебирайте изображения, получая токены VQGAN из версий размером 256 пикселей и встраиваний эмбендингов CLIP
self.ims = [] # # Изображения, закодированные VQGAN
self.conds = []
for fn, caption in tqdm(zip(image_fns, labels)):
self.ims.append(fn)
self.conds.append(caption)
# 1024 возможных кода VQGAN + наша кодировка текста
chars = range(1024+53)
data_size, vocab_size = len(image_fns), len(chars)
print('data has %d characters, %d unique.' % (data_size, vocab_size))
self.stoi = { ch:i for i,ch in enumerate(chars) }
self.itos = { i:ch for i,ch in enumerate(chars) }
self.block_size = block_size # + max_text_length << TODO?
self.vocab_size = vocab_size
def __len__(self):
return len(self.ims)# was len(self.data) - self.block_size
def __getitem__(self, idx):
fn = self.ims[idx]
caption = self.conds[idx]
# Закодируйте изображение с помощью vegan
pil_im = Image.open(fn).convert('RGB').resize((256, 256))
im_tensor = torch.tensor(np.array(pil_im)).permute(2, 0, 1) / 255
with torch.no_grad():
z, a, b = vqgan_model.encode(im_tensor.to(device).unsqueeze(0) * 2 - 1)
im_idxs = b[-1] # 16*16
# Закодируйте текст:
char_idxs = [encode_char(c) for c in caption.lower()[:max_text_length]]
while len(char_idxs) < max_text_length:
char_idxs += [51]
# 52 - это конец текстовых токенов.
char_idxs += [52]
# На данный момент они будут конфликтовать с токенами от vegan, поэтому мы добавляем 1024
char_idxs = [c+1024 for c in char_idxs]
# Комбинируем
dix = [self.stoi[int(s)] for s in char_idxs]
dix += [self.stoi[int(s)] for s in im_idxs]
# Разделить на x и y
x = torch.tensor(dix[:-1], dtype=torch.long)
y = torch.tensor(dix[1:], dtype=torch.long)
return x, y
data = get_openimages(n_images=6000) # 2 тысячи на быструю демонстрацию, 20 тысяч на лучшую попытку обучения
# Наш новый набор данных
image_fns = ['ims/'+d['image_id']+'.jpg' for d in data]
labels = [d['caption'] for d in data]
dset = PatchDataset(image_fns, labels, max_text_length=max_text_length)
x, y = dset[0]
x.shape, y.shape, x[-3:], y[-3:] # Y - это x, смещённый на 1.
▍ Обучение модели делает брррр…
Можете попробовать разные параметры обучения, чем больше max_epochs и n_images (на этом датасете до 20000) — тем лучше, но дольше обучение.
Так-же советую в будущем попробовать использовать более большие датасеты для лучших результатов.
block_size=255+max_text_length+1 # Чтобы также установить кондиционирование
mconf = GPTConfig(dset.vocab_size, block_size,
n_layer=8, n_head=8, n_embd=512)
model = GPT(mconf)
# Обучение
tconf = TrainerConfig(max_epochs=10, batch_size=32, learning_rate=6e-4,
lr_decay=True, warmup_tokens=512*20, final_tokens=2*len(dset)*block_size,
num_workers=0) # num_workers=0, чтобы избежать некоторых ошибок многопроцессорной обработки
trainer = Trainer(model, dset, None, tconf)
trainer.train()
▍ Наконец генерируем картинки
prompt = 'Green cat' #@param
# Закодируйте промт так, как мы это делаем в наборе данных
char_idxs = [encode_char(c) for c in prompt.lower()[:max_text_length]]
while len(char_idxs) < max_text_length:
char_idxs += [51]
char_idxs += [52]
char_idxs = [c+1024 for c in char_idxs]
# Брррр...
fig, axs = plt.subplots(3, 3, figsize=(12, 12))
for i in tqdm(range(9)):
x = torch.tensor([dset.stoi[s] for s in char_idxs], dtype=torch.long)[None,...].to(device)
y = sample(model, x, 256, temperature=1., sample=True, top_k=200)[0]
completion = [dset.itos[int(i)] for i in y]
ccc = completion[-256:]
ccc = [min(c, 1023) for c in ccc]
with torch.no_grad():
zs = vqgan_model.quantize.get_codebook_entry(torch.tensor(ccc).to(device), (1, 16, 16, 256))
axs[i%3, i//3].imshow(vqgan_model.decode(zs).add(1).div(2).cpu().squeeze().permute(1, 2, 0).clip(0, 1))
Выводы
Работа Open AI над первой версией DALL-E дала толчок к бурному развитию Text-to-image, и позволило нам уже сейчас увидеть реально эффективные модели с разными подходами, приспособленные к коммерческому использованию:
DALL-E 2, Midjourney, Imagen, Stable Diffusion и т.д.
Сегодня мы рассмотрели эту модель со всех сторон и получили чуть больше ответов на ваши вопросы, которые вы не могли найти.
Потыкать код и обучить модельку можно в этом колабе.

Результат из очень большой модели RuDALL-E от Сбера
0×0A-0×5B=?

