«Как QA в управлении хранилища данных эволюционировал»

Часть 1. Прошлое. Переломные моменты
Профессиональную сферу DWH (Data Warehouse, или, по-нашему, хранилище данных) отличает высокая технологичность, а также огромное многообразие используемых решений. Крупные компании строят хранилища с самыми разными инструментами и технологиями, отличаются архитектуры, процессы. Но необходимость идти в ногу со временем постоянно вносит свои коррективы.
Tinkoff.ru не исключение. Мы постоянно совершенствуем свои процессы и стремимся развивать не только внешние, но и внутренние продукты. И на примере хранилища данных я хочу рассказать о том, как эволюционировали наши процессы по обеспечению качества. В этой статье я расскажу о том, как ранее был устроен наш рабочий процесс, с какими проблемами мы столкнулись и какие события стали переломными в эволюции нашего процесса QA.
Но сначала я дам некоторую вводную по основным определениям, которые используются в статье:
Хранилище данных (или Data Warehouse, DWH) — это предметно-ориентированная база данных, позволяющая хранить данные для построения бизнес-отчетности и принятия управленческих решений на основе анализа данных в хранилище.
Задача на доработку хранилища (или пакет) — отдельная директория в системе контроля версий (VCS), содержащая набор файлов, использующихся для изменения метаинформации и физических данных хранилища.
А вот теперь можно приступить к основной части рассказа. Итак, поехали.
Откуда выросли проблемы
 Рисунок 1. Прошлое: ручной труд облагораживает
Рисунок 1. Прошлое: ручной труд облагораживаетВ самом начале было слово был поиск оптимальных инструментов для организации работы хранилища, отладка процессов внутри управления хранилища данных, а также поиск основных направлений развития.
В рамках flow выделялись три основные функциональные роли:
системный аналитик;
ETL-разработчик;
QA-инженер.
Что получается на выходе каждого этапа flow — показано на рисунке 2.
Давайте выделим перечень проблем, существовавших на тот момент в реализации процесса:
Ручной сбор пакета разработчиками.
Ручное ревью пакета.
Ручной перенос задач на тест.
Необходимость в синхронизации продуктового и тестового контуров.
Проверки данных без использования автоматизации.
 Рисунок 2. Функциональные роли в DWH (SyA — системный аналитик, DEV — разработчик, QA — инженер по тестированию)
Рисунок 2. Функциональные роли в DWH (SyA — системный аналитик, DEV — разработчик, QA — инженер по тестированию)Детальнее остановимся на каждой из проблем.
Ручной сбор пакета
ETL-процесс — это процесс извлечения данных из различных источников (БД, файлы), их дальнейшей очистки и преобразования (фильтрация, агрегация, дедупликация, вычисление дополнительных атрибутов и т. д.) с дальнейшей загрузкой полученного результата в хранилище.
Две основные составляющие, с которыми мы работаем (рисунок 3):
метаинформация;
физические данные.
 Рисунок 3. Составляющие ETL-процесса
Рисунок 3. Составляющие ETL-процессаРазработчик при получении задачи на доработку хранилища:
С помощью конструктора SAS DIS изменяет логику ETL-процесса.
При необходимости пишет SQL (а иногда и python) скрипты для изменения физических данных.
Пишет инструкцию для переноса задачи на тестовый и продуктовый контуры. Кроме того, если сценарий наката задачи специфический и отличается от типовых задач, то он пишет еще и кастомизированный сценарий наката.
Собирает все доработки в отдельную директорию (рисунок 4) для дальнейшей передачи задачи QA-инженеру.
Вот именно эта директория в VCS и является объектом дальнейшего изучения со стороны QA.
 Рисунок 4. Пример содержимого пакета
Рисунок 4. Пример содержимого пакетаНедостатки. Сбор руками неудобен, появляется человеческий фактор: можно что-то упустить при формировании пакета, больше времени разработчика тратится на задачи, не связанные с самой разработкой.
Ручное ревью пакета
Итак, пакет готов: разработчик выполнил все требуемые по ТЗ доработки, сформировал пакет с нужными файлами и готов передать задачу в тестирование. Но стоит ли делать это сразу после завершения работ?
Нет, поскольку выявление проблем на более поздних этапах в разы увеличивает стоимость исправления этих самых проблем. Поэтому как можно больше проверок нужно выполнить на ранних этапах процесса.
И тут помогает ревью. Опытный коллега-разработчик отсматривает пакет на предмет корректности содержимого, структуры и соблюдения общих подходов к разработке, руководствуясь стандартом проектирования — документом, отражающим множество самых разных аспектов разработки и проектирования ETL-процессов.
И вроде все прекрасно, но есть нюансы:
Ревью занимает много времени, поскольку выполняется вручную.
Невозможно отследить глазами выполнение абсолютно всех требований.
Ручной перенос задач на тест
На рисунке 5 показано, как выполнялся перенос пакетов на тестовый контур. QA запасался терпением, изучал инструкцию, написанную разработчиком, и руками переносил всю необходимую информацию на тестовый контур. Далее он запускал нужные скрипты из пакета, выполнял прочие действия и, наконец, запускал ETL-процессы.
 Рисунок 5. Перенос задачи на тестовый контур
Рисунок 5. Перенос задачи на тестовый контурОчевидно, что некоторые недостатки в текущем подходе присутствуют:
Длительность подготовки тестового окружения.
Человеческий фактор и, как следствие, ошибки.
Высокий порог вхождения — нужны глубокие знания, чтобы понимать процесс релиза.
Рутинность и однообразность процесса.
Блокирование метаинформации при выполнении шагов, взаимодействующих с метой, во время наката задачи.
Очень много проблем с откатами и перенакатами задач.
Откаты и перенакаты не всегда можно было выполнить — тогда ждали синхронизации.
Первые три пункта из списка выше, на мой взгляд, очевидны, на них я останавливаться не буду. А вот оставшиеся стоит разобрать подробнее. Начну с блокировки метаинформации.
В рамках экосистемы, завязанной на SAS, инструментом для работы с метаинформацией стал SAS Data Integration Studio (SAS DIS). Объекты хранилища (описание баз, ETL-процессов, таблиц и т. д.) разрабатываются в SAS DIS и хранятся на SAS-сервере в виде метаданных. Физически таблицы находятся в базах Greenplum и SAS. Подробнее про технологии, которые используются в нашем хранилище, можно почитать здесь и здесь, а также просто воспользовавшись поиском по нашему блогу на «Хабре» поискать по ключевому слову «DWH».
Но у каждого инструмента есть тот или иной недостаток. У SAS DIS это блокировки метаинформации. SAS DIS устроен таким образом, что при выполнении одновременно нескольких переносов задач на тестовый контур все операции над метаинформацией (импорт, правка, удаление и т. д.) формируют очередь. И, что самое главное, при выполнении каждой такой операции любые другие манипуляции над метаинформацией, даже простой просмотр, будут недоступны для всех пользователей. То есть при получении большой очереди операций работать с метаинформацией долгое время будет просто невозможно.
Откаты задач и дальнейшие их перенакаты после исправления ошибок требовали повторения ручных действий, но не всегда можно было вернуть тестовый контур в корректное предыдущее состоянии. В этом случае требовалось восстановление данных на тестовом контуре, что достигалось путем его синхронизации с продуктовым контуром. Это тоже требовало времени.
Недостатки: долго, много ручных действий, вынужденные простои.
Необходимость в синхронизации продуктового и тестового контуров
Синхронизация — это актуализация данных на тестовом контуре путем передачи с продуктового контура актуальной метаинформации и самих данных для тестирования.
Синхронизация нужна была достаточно часто, не реже раза в месяц, поскольку за месяц из-за различных проблем (сбои и ошибки при накатах задач, удаление необходимых для отката задачи бэкапов и т. д.) данные и метаинформация на тестовом контуре переставали быть актуальными.
Кроме того, QA-инженеры перезатирали данные друг друга, и зачастую восстановление исходного состояния без синхронизации было невозможно. Это происходило из-за того, что часть объектов могла использоваться как источники в одних и как целевые таблицы в других пакетах. Тогда при изменениях метаинформации или физических данных происходил конфликт. Изолировать данные и метаинформацию при условии выполнения модульного и интеграционного тестирования на одном контуре не представлялось возможным.
Синхронизация проводилась достаточно долго, начиналась в пятницу вечером и завершалась в понедельник — при хорошем стечении обстоятельств. Плюс ко всему в процессе возникало много проблем.
Нужно было что-то делать, и появилось решение: создавать изолированные окружения для модульного тестирования каждого отдельно взятого пакета.
А теперь поговорим о том, какие проверки и каким образом выполнялись на этом этапе нашей эволюции.
Проверки данных без использования автоматизации
Все проверки качества данных в пакете с доработками хранилища на тестовом контуре носили ручной характер. QA-инженеры проверяли:
корректность данных на отсутствие NULL и дублей в ключевых полях;
соответствие DDL-таблицы на тестовом контуре описанию данной таблицы в модели данных;
наполнение каждого из столбцов таблицы;
соответствие данных в таблице эталонному прототипу;
регресс, сравнение с предыдущей версией таблицы, если объект менялся в рамках текущей доработки.
Кроме того, после выполнения всех вышеуказанных проверок запускались все зависимые объекты хранилища (кроме отчетов, то есть только ETL-процессы), чтобы проверить, не поломала ли доработка ранее работавший функционал. Таких ETL-процессов могло быть очень много плюс при прогрузке можно было бы испортить тестовые данные коллеге и т. д.
Итак, общие минусы ручных проверок:
долгое выполнение;
снижение мотивации сотрудников;
низкая производительность.
Также были минусы интеграционного тестирования:
зависимость от окружения;
возможные конфликты объектов из разных задач;
человеческий фактор.
Вот с такими проблемами мы сталкивались ранее, и их решение стало важной задачей для нашего дальнейшего развития. Какие же первые шаги были предприняты для решения описанных выше проблем?
Вот с чего началась наша эра
 Рисунок 6. Переломные моменты — знаковые события в QA
Рисунок 6. Переломные моменты — знаковые события в QAМножество ручных действий, проблемы с тестовым контуром и синхронизациями, долгое тестирование — вот те проблемы, с которыми мы ежедневно сталкивались.
Какие же события стали переломными в этой ежедневной борьбе?
Авторелиз
Автонакат
Ручные переносы пакетов на тестовый контур заставляли дергаться глаза даже самых матерых QA-инженеров. С этим нужно было что-то делать, и команда python-разработки нашего управления создала его — авторелиз!
Это была специальная утилита, позволяющая переносить задачи на соответствующие контуры (dev/test/prod), причем интерфейс взаимодействия с ней был очень простой:
SSH-подключение к серверу;
запуск в терминале команды с указанием номера задачи, нужного контура.
Это позволило автоматизировать процесс переноса задач, но проблемы с зависанием меты при нескольких параллельных переносах задач на тестовый контур остались актуальными.
Демоны
Демоны — наши внутренние сервисы для улучшения и автоматизации процессов.
Первые демоны:
Валькирия — очищает изолированные тестовые окружения по тем задачам, что уже протестированы. То есть попросту удаляет все таблицы с данными на тестовом контуре по задачам со статусом testing done. Запускается демон ежедневно в 22:00, и уже на основе результатов работы этого демона Харон будет очищать буфер.
Харон — удаляет из общего буфера таблицы, которые не используются в задачах, ежедневно в 23:00. Это позволяет экономить место на тестовом контуре и не тратить рабочее время на очистку контура вручную.
Гермес — ищет подходящие бэкапы с продуктового контура, которые нужны для построения изолированных тестовых окружений. Об этом чуть подробнее расскажу в следующем разделе.
Создание авторелиза и демонов позволило сильно упростить процесс подготовки тестовых окружений, а также очистки тестового контура после завершения тестирования.
При описании демонов использовались такие понятия, как буфер, изолированное тестовое окружение. Давайте разберемся, что это такое, и познакомимся с нашей разработкой — vial.
Модульное тестирование
Vial
Итак, у нас уже появился авторелиз, а значит, задача переноса на тестовый контур решена. А что с проблемами тестирования? Их было много: частые синхронизации, проведение всех тестов на одном контуре (частые поломки окружения) и ручное выполнение тестовых проверок. Решение последней проблемы обсудим позже, а сейчас остановимся на первых двух.
Чтобы в процессе тестирования отдельные задачи не конфликтовали между собой и тестовое окружение дольше оставалось актуальным, был придуман механизм пробирок, или vial-контуров.
Что же это такое — давайте разберем более подробно.
Vial (или «пробирка») — изолированное окружение на тестовом контуре, включающее в себя физические данные только дорабатываемых и создаваемых по задаче объектов. При этом остальные объекты хранилища никак не затрагиваются, и любые работы с данными в пробирке не влияют на остальное хранилище.
 Рисунок 7. Как соотносятся vial и test
Рисунок 7. Как соотносятся vial и testС точки зрения хранения данных схема стала такой, как показано на рисунке 7: в базе данных тестового контура создаются отдельные схемы с префиксом preXXXXX (pre — префикс проекта, XXXXX — номер задачи в Jira) и в этих схемах хранятся все необходимые для модульного тестирования данные.
При построении пробирки с продуктового контура берутся бэкапы таблиц источников (Source на рисунке 8) для каждого дорабатываемого в данной задаче ETL-процесса. Причем бэкапы берутся консистентными.
 Рисунок 8. Как формируется vial
Рисунок 8. Как формируется vialА для целевых таблиц ETL-процессов (Target на рисунке 8) берется целых два бэкапа:
За одну и ту же дату, что и таблицы источники, — today.
За предыдущую дату — yesterday.
Зачем берутся два бэкапа?
Для ответа на этот вопрос разберем, как формируются данные на проде.
ETL-процессы хранилища ежедневно запускаются для прогрузки свежих данных из источников в целевые таблицы. Что при этом происходит:
Перед запуском ETL-процесса в источниках накапливаются свежие данные.
В целевой таблице ETL-процесса, Target (yesterday) на рисунке 9, находятся данные с актуальностью на вчера (или на дату прошлого запуска ETL-процесса, если процесс может запускаться несколько раз за сутки).
Далее ETL-процесс запускается и данные в целевой таблице приобретают актуальность на ту же дату, что и данные в источниках, — Target (today).
Все ETL-процессы хранилища делятся на две категории: работающие на полных данных (то есть при каждом запуске они перезагружают все данные в целевой таблице) и работающие на инкременте (при каждом запуске ETL-процесс подтягивает только новые и измененные записи из источников). При таком подходе, независимо от способа загрузки данных, используя самые последние версии источников и предпоследнюю версию таргета, ETL-процесс корректно выгрузит данные в таргет.
С принципом работы ETL-процессов на проде ознакомились, теперь перейдем к созданию виала.
 Рисунок 9. Механизм обновления хранилища на проде
Рисунок 9. Механизм обновления хранилища на продеДанные с прода копируются в огромную специальную схему на тестовом контуре. Это буфер, в котором в специальных таблицах прописана связь каждого бэкапа с определенной задачей, где он используется. Именно отсюда демоны удаляют те бэкапы, что становятся ненужными после завершения тестирования.
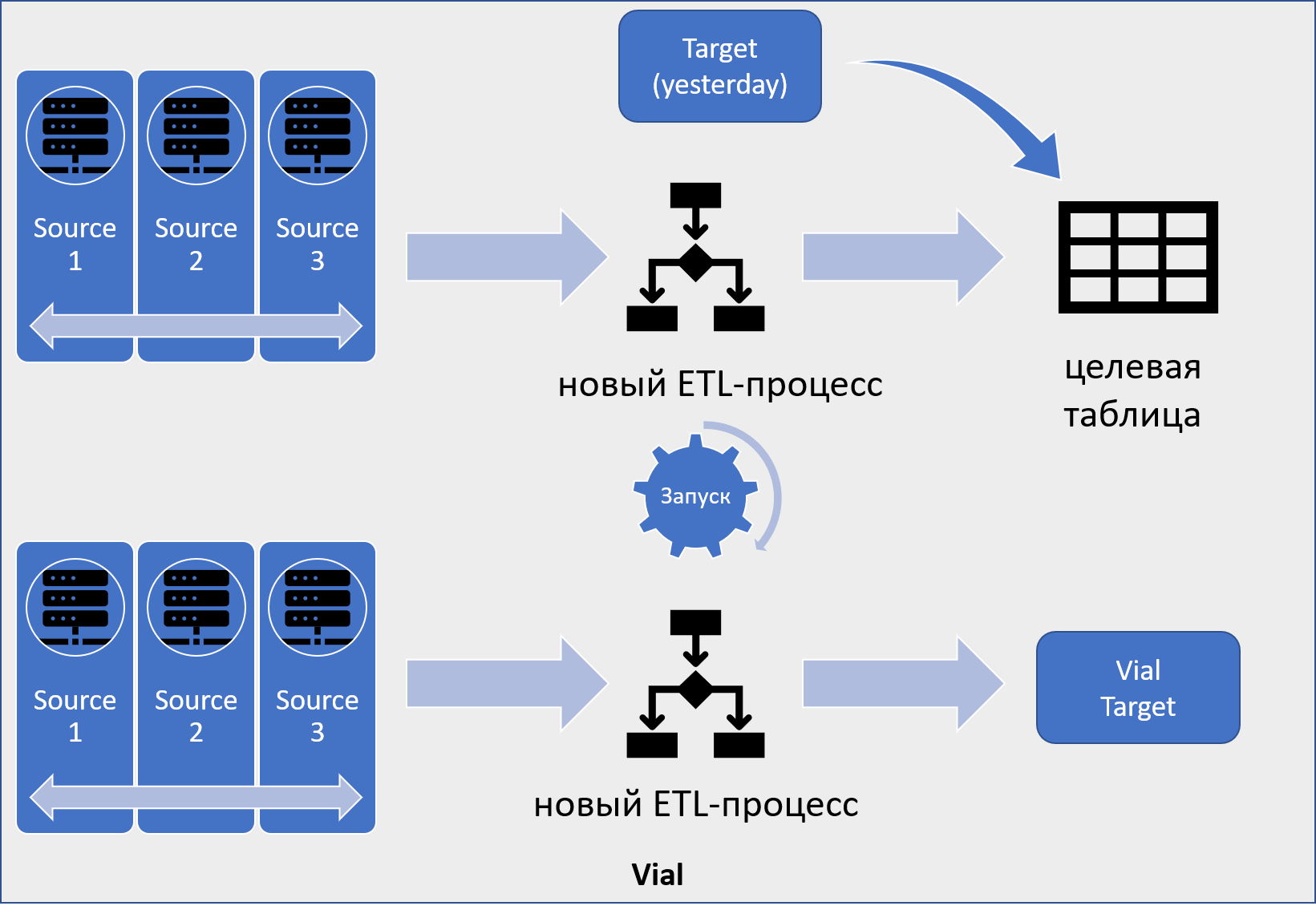 Рисунок 10. Принцип формирования vial
Рисунок 10. Принцип формирования vialНа виале при тестировании новой версии этого ETL-процесса мы будем прогружать данные из тех же самых источников — рисунок 10. Но для этого сначала нужно скопировать данные из Target (yesterday)-бэкапа в целевую таблицу на виале.
Теперь наш ETL-процесс готов для прогрузки.
Если кроме изменения метаинформации в задаче есть правка физических данных, то выполняются соответствующие скрипты. Новая метаинформация деплоится на тестовый сервер, и ETL-процесс запускается.
По аналогии с продом процесс отработал на новых данных и сформировалась новая версия целевой таблицы. И вот именно она будет сравниваться с Target (today)-бэкапом на корректность проведенных доработок.
Данная проверка важна, поскольку позволяет отловить:
Неоднозначность в данных — по одному и тому же ключу при каждом запуске ETL-процесса приходят случайные значения атрибутов. Это происходит из-за того, что в источнике ключу соответствует сразу несколько значений, а в самом ETL-процессе не настроен однозначный критерий отбора нужного значения.
Ошибочные зануления или, наоборот, заполнения атрибутов.
Любые изменения в физических данных, которые не ожидались по ТЗ в конкретной задаче.
Таким образом, для выполнения регресса у нас есть все необходимые данные: целевые таблицы и старого, и нового процесса, прогруженных на одинаковых входных данных. Регресс считаем корректным, если таблицы на виале и таблицы на проде отличаются только выполненными по ТЗ доработками (рисунок 11).
 Рисунок 11. Регресс
Рисунок 11. РегрессИтоговая общая концепция vial-контура изображена на рисунке 12.
 Рисунок 12. Общая концепция vial
Рисунок 12. Общая концепция vialИ что же нам дал vial?
Во-первых, отпала необходимость в синхронизациях. Данные и метаинформация легко стягиваются с продуктового контура точечно для каждой задачи, и это не требует огромных затрат, да и при порче данных достаточно стало перенакатить задачу на виал — и всё! Никаких долгих, муторных ручных откатов.
Во-вторых, разнесение по разным контурам модульного и интеграционного тестирования позволило меньше бояться за надежность интеграционного тестирования, так как окружение реже ломается и QA не портят данные друг другу.
Казалось бы, вот оно — счастье, живи и радуйся! Live-контур-то зачем было придумывать?
Оказывается, не для всех ETL-процессов такая схема регрессионного тестирования подходит. Дело в том, что во многих ETL-процессах источники обновляются гораздо чаще, чем раз в сутки, это так называемые реплики. И в случае с репликами, пока мы перенесем задачу на vial-источники, успеют обновиться и данные в целевой таблице, пробирки будут существенно отличаться от бэкапа, отработавшего еще на прошлой версии источников.
И вот тут на помощь приходит live.
Live
Задача данного контура — прогнать на тех же самых данных, что использовались при создании пробирки на vial, старую версию ETL-процесса. Рассинхрон данных в источниках исключается, и, таким образом, расхождения при сравнении старой и новой целевой таблицы ETL-процесса будут только в случае ошибочной логики или, например, всплывшей неоднозначности — один и тот же SQL-запрос при нескольких запусках возвращает разный результат.
Live позволяет быстрее локализовать источник расхождений и неоднозначность, являясь лучшим другом QA-инженера.
Итак, подытожим. У нас был единственный тестовый контур (test), на котором выполнялось и модульное, и интеграционное тестирование. Причем при выполнении модульного тестирования объекты не были изолированы (да, так получилось) и мы много страдали.
Проблема была решена созданием отдельных изолированных тестовых окружений на vial, а также контура для проведения регресса — live. Таким образом, test перестал использоваться для модульного тестирования.
А что же с ним стало?
Test
Test стал использоваться исключительно в качестве тестового контура для проверки интеграции.
На интеграционный контур мы сначала переносили задачи полностью, чтобы выполнить интеграционное тестирование: запустить все зависимые ETL-процессы и проверить, что они успешно отработали, а затем стали переносить только метаинформацию.
Поскольку все зависимости мы отслеживали с помощью инстанса (дерево взаимосвязей всех ETL-процессов хранилища), для интеграционного тестирования мы поддерживали мету теста в актуальном состоянии. Сами же интеграционные тесты были автоматизированы. Другого инструмента отслеживания зависимостей не было, поэтому отказаться от теста мы не могли.
Авточекер
Авточекер был первым шагом в автоматизации тестирования хранилища. Ряд проверок для интеграционного тестирования был описан в виде функций на python. Далее в сценарий переноса задачи на интеграционный контур была добавлена опция запуска специального шага сценария, на котором и выполнялись эти функции.
Все результаты проверок выводились в командную строку. Сообщения об ошибках подсвечивались красным. В общем, это была теплая ламповая консоль и при этом автоматизация плюс экономия нашего времени.
Время подводить предварительные итоги.
Проблемы на данном этапе
Итак, на текущем этапе мы запустили авторелиз и изолированные тестовые окружения, а также авточекер. Благодаря им была решена проблема ручного переноса задач, а также сделан первый шаг в автоматизации тестирования.
Но по-прежнему остались проблемы:
Ручной сбор пакета разработчиками.
Необходимость в синхронизации продуктового и тестового контуров.
Ручное ревью пакета.
Недоступность операций над метаинформацией при возникновении очереди (изначально выделена не была, но по ходу статьи упоминалась).
Для тестирования интеграции используется отдельный тестовый контур — test.
Решить эти проблемы нам помогли наши внутренние разработки: Портал автоматизации и Авторевью, тестовый фреймворк для автоматизации тестирования. Но об этом я расскажу уже в следующей статье.
Спасибо, заходите почитать про наше хранилище!
