Как проводить A/B-тестирование на 15 000 офлайн-магазинах
Привет! На связи команда Ad-hoc аналитики Big Data из X5 Retail Group.
В этой статье мы расскажем о нашей методологии A/B-тестирования и сложностях, с которыми мы ежедневно сталкиваемся.
В Big Data Х5 работает около 200 человек, среди которых 70 дата сайентистов и дата аналитиков. Основная наша часть занимается конкретными продуктами — спросом, ассортиментом, промо-кампаниями и т.д. Помимо них, есть наша отдельная команда Ad-hoc аналитики.
Мы:
- помогаем бизнес-подразделениям с запросами по анализу данных, которые не вписываются в существующие продукты;
- помогаем продуктовым командам, если им нужны дополнительные руки;
- занимаемся A/B-тестированием — и это основная функция команды.
Ситуация, в которой мы работаем, сильно отличается от типичных A/B-тестов. Обычно методика ассоциируется с онлайном и онлайн-метриками: как изменения повлияли на конверсию, ретеншн, CTR и т.п. Большая часть экспериментов связаны с изменениями интерфейса: переставили баннер, перекрасили кнопку, заменили текст и т.п.
Бизнес Х5 другой — это живые 15 000 офлайн-магазинов разных форматов, распределенные по стране. Эта особенность накладывает определенные ограничения. Во-первых, сильно меняется набор метрик, которые можно тестировать, во-вторых, накладывается ограничение на эксперименты. Задача изменения дизайна витрины интернет-магазина не сопоставима по трудозатратам с задачей изменения порядка отделов в офлайн-магазинах.
В компании есть команда, которая занимается программой лояльности и их пилоты ближе всего к классическому представлению об А/В-тестировании. Вопросы же, с которым приходят к нам, очень нетипичны для «обычных» A/B-тестов. Например:
- Как изменятся финансовые показатели магазина, если поменять порядок отделов «Колбаса» и «Торты»?
- Как повлияет модель оттока клиентов на финансовый результат?
- Как установка постаматов повлияет на показатели магазинов?
Заказчики верят, что определенное изменение положительно повлияет на какой-то из показателей (о них поговорим дальше). Наша работа — помочь им достоверно проверить их гипотезы на основе данных.
Метрики
Какие показатели мы тестируем? РТО, средний чек и трафик — самые часто используемые слова в нашем крыле опен-спейса.
- РТО (розничный товарооборот) — сумма денег, вырученная магазином.
Одна из основных метрик для бизнеса и самая сложная для тестирования.
Ежедневный оборот магазина измеряется в миллионах рублей. Соответственно, разброс показателя измеряется, как минимум, в тысячах рублей. Сложная и длинная формула определения размера выборки гласит, что чем больше дисперсия, тем больше данных нужно для сколь-нибудь значимых выводов. Чтобы поймать эффект даже в десятые процента с такой большой дисперсией РТО, пилоты в магазинах нужно проводить по полгода.
Представляете реакцию правления, если на встрече с ними сказать, что пилот нужно проводить полгода, а то и год на всех магазинах? =)
У нас есть два стандартных подхода.
Первый подход: мы рассматриваем РТО не всего магазина, а какой-то продуктовой категории. Например, в результате перестановки двух секций в магазине («Торты» и «Колбасы») ожидается увеличение РТО в обеих категориях. РТО одной категории сильно меньше, чем РТО всего магазина, следовательно, ниже дисперсия. В данном случае мы надеемся, что пилот на этих категориях изолирован от остальных категорий.
Второй подход: мы дискретизируем время. Единицей наблюдения становится не РТО магазина в течение всего пилота, а РТО в неделю или день. Таким образом, мы увеличиваем количество наблюдений, сохраняя дисперсию «сырых» данных.
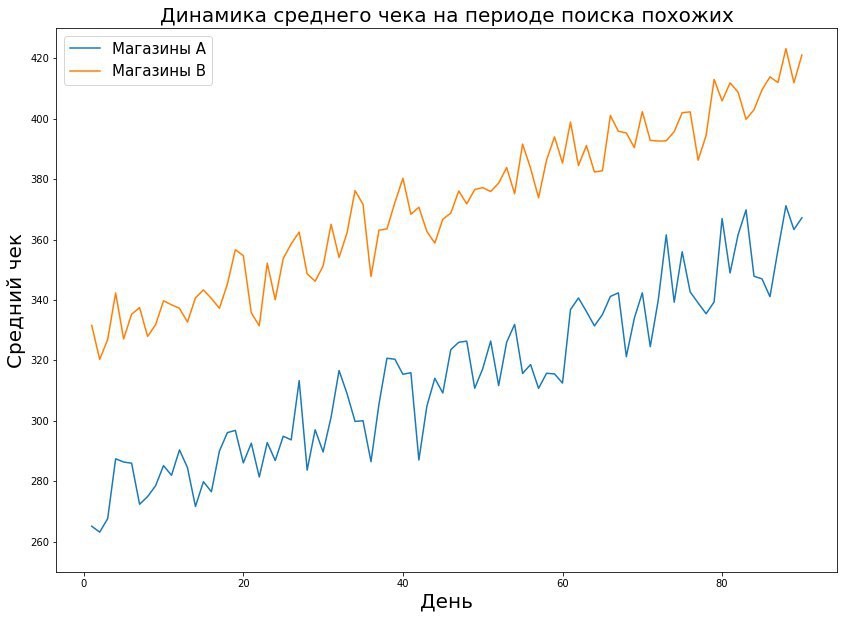
- Средний чек, или РТО / количество чеков — средняя сумма денег в одном чеке.
Часть изменений нацелены на то, чтобы люди стали покупать больше, поэтому мы тестируем РТО / количество чеков, или средний чек, если проводить аналогии с привычными метриками.
Сложность в тестировании этой метрики связана со спецификой ритейла. Например, при пилотном запуске акции »3 по цене 2» человек, планировавший купить один товар, купит три, и сумма чека у него увеличится. Но вдруг в последствии он станет реже ходить в магазин и пилот на деле окажется не так успешен?
- Трафик — количество чеков в магазине за определенный период времени.
Чтобы избежать ошибочных выводов при тестировании гипотез, влияющих на средний чек, мы одновременно смотрим на изменения трафика. Мы не можем непосредственно отследить сколько людей пришли в магазин, т.к. не все посетители — клиенты программы лояльности, поэтому для A/B-тестирования каждый чек — это «уникальное посещение» клиента. По аналогии с РТО трафик мы рассматриваем в различных временных интервалах: трафик в день, трафик в час.
Взаимосвязь среднего чека и трафика очень важна: не мог ли пилот увеличить средний чек, но сократить трафик и в итоге привести не к увеличению РТО, а к его уменьшению? Мог ли пилот способствовать увеличению трафика, не изменив при этом средний чек?
- Маржа — разница между ценой товара и его себестоимостью
Бывают пилоты, в рамках которых мы меняем цены на товары — на какие-то цена повысилась, на какие-то наоборот. Так как на себестоимость мы не влияем, то, меняя цены, мы меняем маржу товаров. Такой пилот может привести и к повышению трафика, и к повышению среднего чека. Но означает ли это, что пилот успешен и стоит менять цены во всех магазинах сети? Нет, вполне могло получиться так, что люди стали чаще покупать товары с отрицательной или маленькой маржой и отказались от товаров с высокой маржой. Поэтому не всегда за увеличением РТО следует увеличение суммарной маржи, в силу этого стоит тестировать эти показатели отдельно.
Хорошо, допустим, что мы определились с целевыми метриками. Следующие вопросы:
- Эффект какого размера планирует получить заказчик?
- Какой эффект реально можно обнаружить в эксперименте?
- Как долго проводить эксперимент?
- На каких группах?
Обобщающая способность эксперимента
У A/B-тестов, проводимых над онлайн-пользователями есть значительное преимущество — у них высокая обобщающая способность. Иными словами, те выводы, которые получены в ходе эксперимента, можно масштабировать на всех пользователей. Обобщающая способность гарантируется постановкой эксперимента: контрольная и тестовая группы формируются случайно, почти точно обе группы из одного распределения, в обе группы можно нагнать много трафика — был бы бюджет.
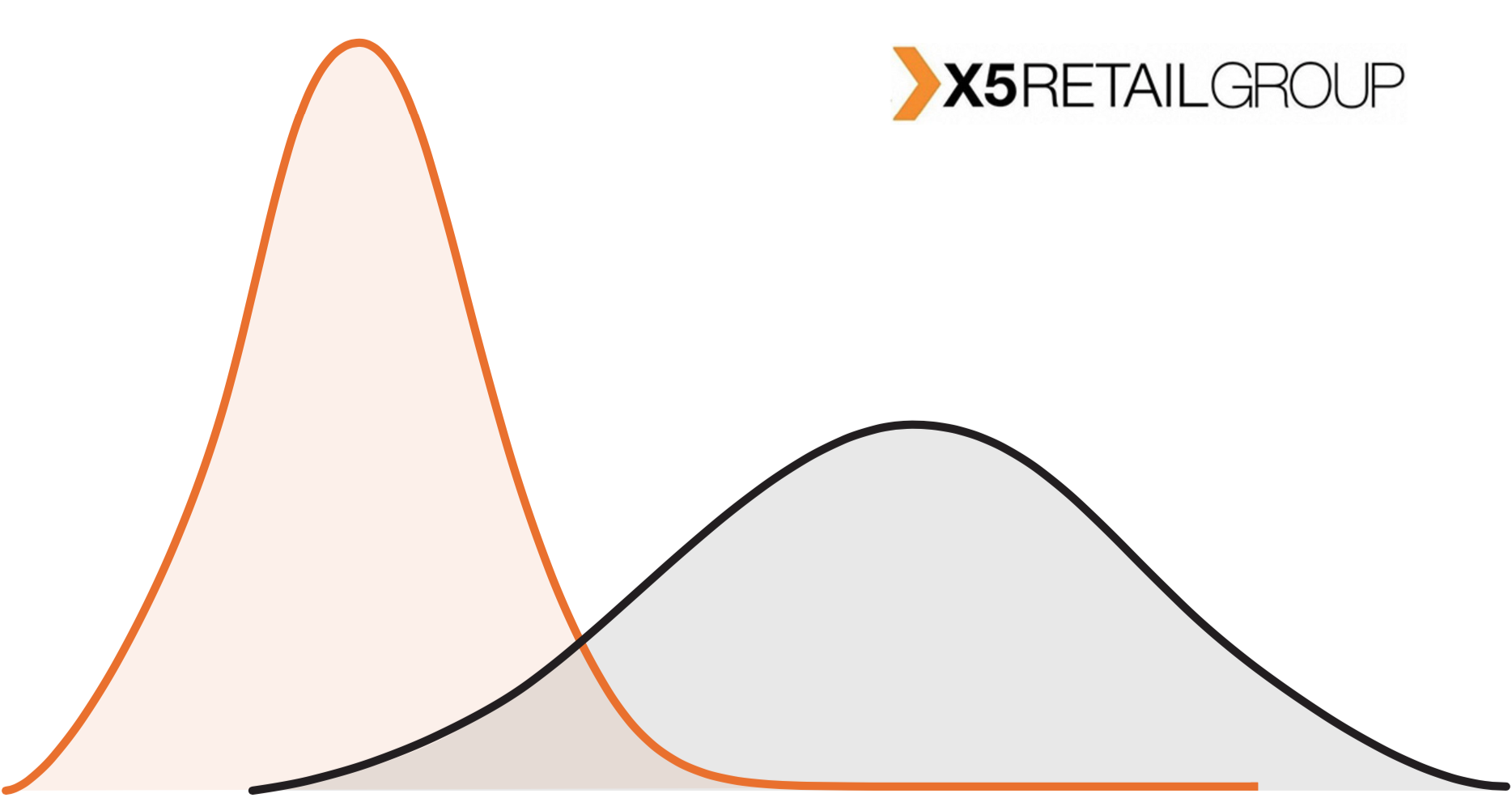
В случае с офлайн-ритейлом не работает ни одна из этих установок. Во-первых, есть ограничение на количество магазинов. Во-вторых, магазины сильно отличаются друг от друга. Магазин «Перекресток» в спальном районе и «Перекресток» около бизнес-центра — это, по сути, очень различные объекты из разных распределений.

На графике видим, что магазины из тестовой группы отличаются от магазинов всей сети. Это довольно типичная ситуация: в сети «Пятерочка» магазины расположены не только в городах, но и в маленьких поселениях. Крупные пилоты чаще всего проводятся в городах. Какой бы мы эффект ни поймали, масштабировать его на всю сеть — неправильно.
Совокупный эффект Є пилота мы оцениваем по формуле:

a — площадь пересечения распределений пилотной группы и всех магазинов сети.
Отметим, что это не следствие статистических законов, а наше предположение о том, как логично считать совокупный эффект.
Идеальным вариантом кажется набирать в тестовую группу репрезентативную выборку, то есть такие магазины, которые правдиво отражают все состояние сети. Но репрезентативность ведет к неоднородности выборки, т.к. в выборку попадут магазины с низким или высоким РТО.
Размеры групп, длительность пилота и минимальный детектируемый эффект
А теперь к самому важному — размеры эффекта и срок пилота. Как правило, мы сталкиваемся с одной из трех ситуаций:
- заказчик имеет ограничение по времени пилота и количеству магазинов, с которыми можно работать;
- заказчик знает, эффект какого размера ожидает получить и просит обозначить количество магазинов, которые нужно для пилота (а потом и сами магазины);
- заказчик открыт к нашим предложениям.
Нельзя сказать, что какой-то из сценариев проще, потому что в любом случае мы готовим таблицу эффекта-ошибки.
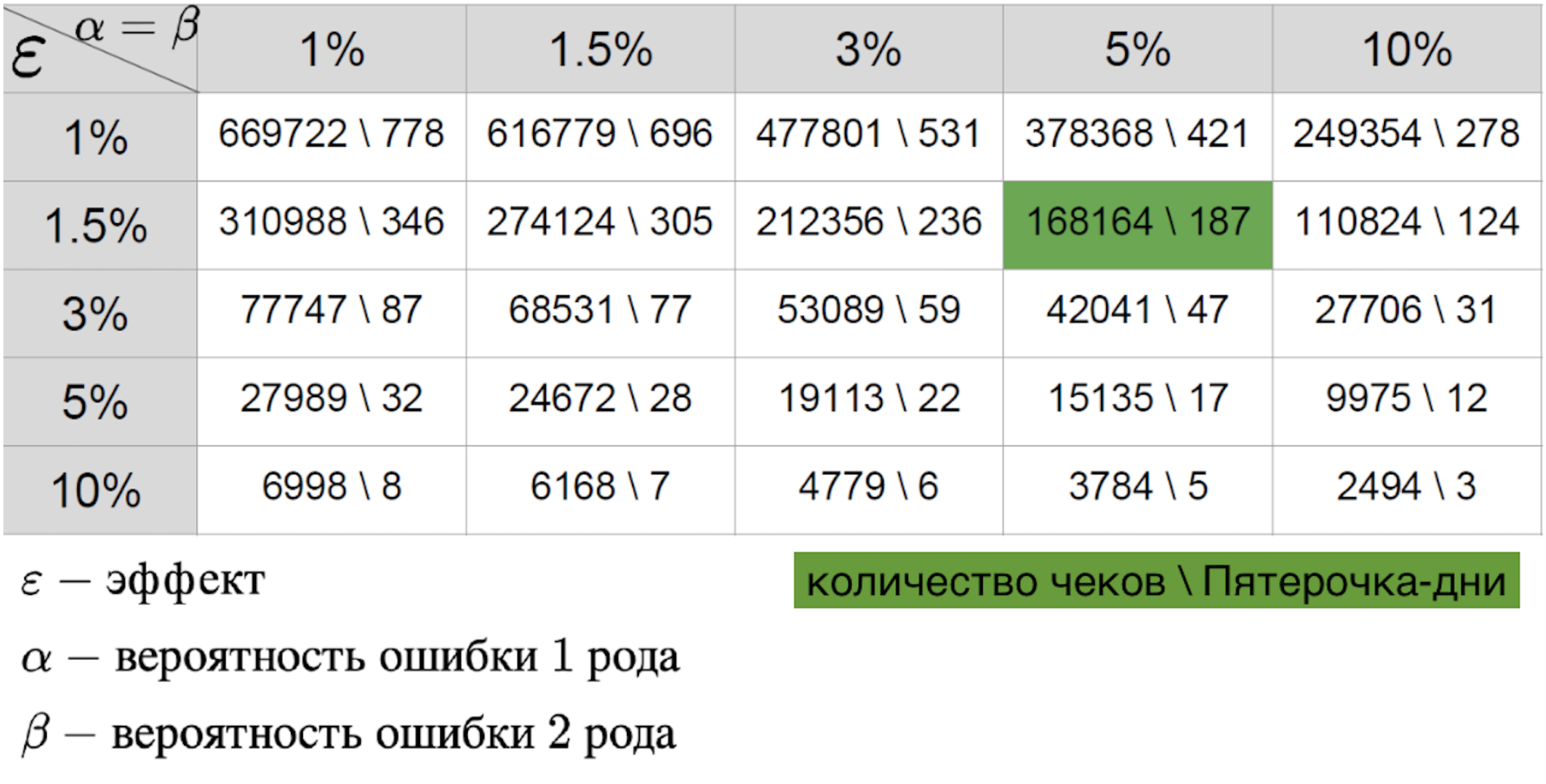
Для нее важны:
- ошибка первого рода — вероятность увидеть эффект, когда его нет;
- ошибка второго рода — вероятность пропустить эффект, когда он есть;
- размер эффекта, который ожидается увидеть при успешном пилоте.
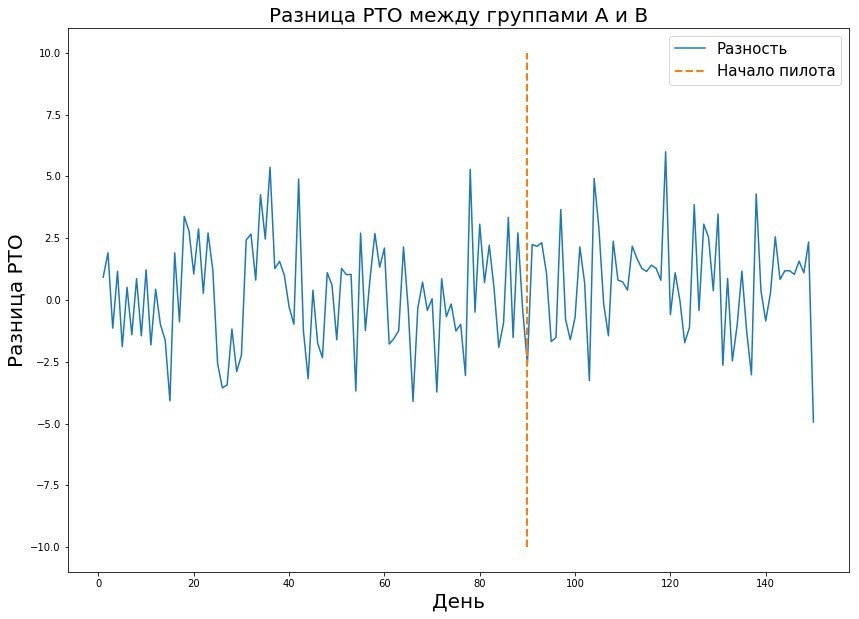
Совокупность этих трех параметров позволяет рассчитать необходимую длительность пилота. Значением в таблице является размер выборки — в данном случае количество чеков либо среднее значение метрики в магазине за день, которые нужны для проведения пилота. Если мы говорим о реальном мире, то обычно устраивают вероятности ошибок первого и второго родов в 5–10 процентов. Как видно из таблицы, при таких фиксированных ошибках нам нужен 421 Пятерочка-день, чтобы отловить эффект в один процент. Кажется, что цифра довольно неплохая — ведь 421 Пятерочка-день — это пилот на 40 магазинах в течение 10 дней. Однако, здесь есть одно «но» — очень мало пилотов, на которых действительно предвидится эффект в один процент. Обычно речь идет о десятых долях процента. Учитывая, что РТО измеряется в миллиардах, то десятая доля процента эффекта от успешного пилота может дать большой прирост к выручке. В силу этого хочется измерять даже малейший эффект. Но чем меньше размер эффекта, тем выше ошибка второго рода. Это объяснимо: маленький эффект похож на случайный шум и редко будет считаться реальным отклонением от нормы. Это хорошо видно на графике ниже, где мы хотим поймать маленький эффект в данных с большой дисперсией.

А/А-тестирование
До начала пилота нужно определиться с тестовой и контрольной группой. У заказчика может быть пилотная группа, а может и не быть. Мы готовы ему помочь в обоих случаях, запросив ограничения — например, магазины должны быть строго трех определенных регионов.
Допустим, что мы подобрали каким-то способом тестовую и контрольную группу. Как быть уверенными в том, что подобранные группы хороши и на них действительно можно проводить A/B-тестирование? Вроде все звучит стройно: набрали необходимое количество наблюдений, по формуле сможем отловить эффект в 0.7%, нашли похожие магазины. Что теперь нас не устраивает?
К сожалению, много серьезных фактов:
- элементы выборки не из одного распределения — наша выборка представляет из себя смесь наблюдений из разных магазинов, а у каждого магазина свое распределение.
- элементы выборки не независимы — в выборке присутствует много наблюдений из одного магазина, соответственно, между ними есть связь;
- равенство средних не гарантируется при отсутствии пилота — т.е. мы никак не уверены, что не будь пилота, статистики магазина бы не различались.
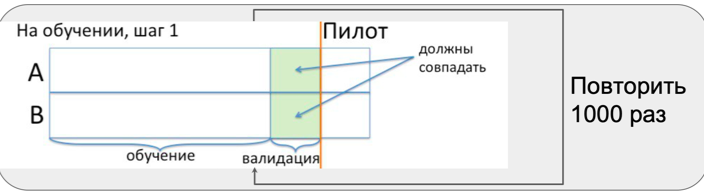
Все эти проблемы не учитываются в расчете формулы подбора количества наблюдений в зависимости от ошибок и эффекта. Чтобы понять масштаб влияния вышеизложенных проблем, мы проводим А/А-тестирование. По сути, это симулирование всего пилота на магазинах в период, когда на нем никакого пилота в магазинах нет. Этот период называем предпилотным. 
Во время предпилотного периода мы много раз повторяем три шага:
- подбор похожих групп;
- тестирование средних на равенство в двух группах;
- добавление эффекта в тестовую группу и тестирование средних на равенство.

Подбор похожих групп
Мы не изобретаем велосипед, поэтому похожие группы ищем старым-добрым методом ближайших соседей. Стратегия генерации фичей для магазина — отдельное искусство. Мы нашли три работающих способа:
- Каждый магазин описать вектором признаков по метрике, которую мы тестируем. Например, при исследовании среднего чека описываем ежедневными средними чеками на протяжении 8 недель — получаем 56 признаков на магазин. Затем берем евклидово расстояние между признаками пары магазинов.
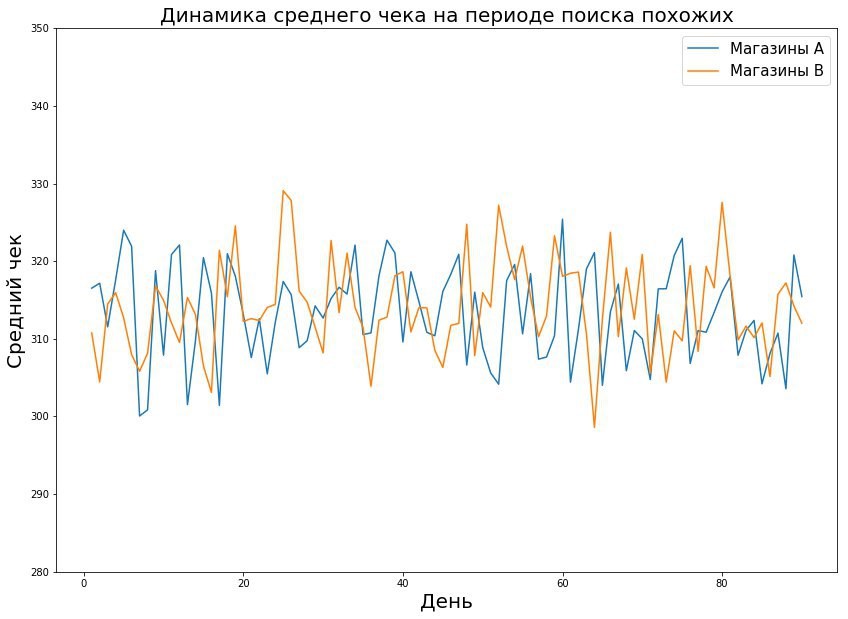
- Найти похожие по динамике магазины. Магазины могут отличаться по абсолютным значениям метрик, но совпадать по трендам — и при определенных математических манипуляциях эти магазины можно считать одинаковыми.
- прогнозировать показатели магазина на периоде пилота (в будущем) и по ним подбирать похожих –, но здесь нужен оракул, который умеет довольно точно предсказывать показатели на пилот.
Мы придерживаемся очень простой гипотезы: если магазины были похожи до пилота, то не будь пилотных изменений, они оставались бы похожими.
Вы можете заметить, что даже в этих трех работающих способах есть много аспектов, которые можно варьировать: количество дней/недель, по которым считается фича, метод оценки динамики показателя и тп.
Универсальной таблетки нет, в каждом эксперименте мы перебираем разные варианты исходя из нашей цели. А она очень простая: найти метод подбора ближайших соседей, который дает разумные ошибки первого и второго рода. Откуда они берутся, рассказываем дальше.
Тестирование на равенство средних, или ошибка первого рода метода
Напомним, что к этому моменту мы:
- определили с заказчиком размер эффекта и длительность пилота
- объяснили суть ошибок первого и второго рода
- построили метод подбора похожих групп
Задача этого этапа — убедиться, что подобранный нами метод в п.3 находит такие группы, что до начала пилота показатель (РТО, средний чек, трафик) в этих магазинах статистически не различается.
В цикле подобранные группы мы многократно тестируем на равенство каким-то статистическим тестом и бутстрапом. Если доля ошибок (т.е. группы между собой не равны) выше порога, то метод бракуется и подбирается новый. Так до тех пор, пока мы не достигнем искомого порога ошибки.
Важно узнать, как часто мы ловим эффект, когда его нет, т.е. реагирует ли наш метод подбора на случайные различия между магазинами или нет.
Добавление эффекта, или ошибка второго рода метода
Резонный вопрос, а не переобучимся ли мы так, что настоящие эффекты тоже будем воспринимать за шум и игнорировать их? Иными словами, умеем ли мы детектировать эффект, когда он есть?
Убедившись на прошлом шаге, что группы совпадают, мы добавляем в одну из групп искусственный эффект, т.е. гарантируем, что пилот успешный и эффект должен быть.
В этот раз цель — узнать, как часто гипотеза о равенстве отвергается, т.е. тест смог различить две группы. Ошибка в данном случае — это считать, что группы равны. Эту ошибку мы называем ошибкой второго рода.
Снова в цикле мы тестируем на равенство контрольную группу и «зашумленную» тестовую. Если ошибаемся достаточно редко, то мы считаем, что метод подбора групп прошел валидацию. Его можно использовать для подбора групп в пилотный период и быть уверенными, что если пилот даст эффект, то мы сумеем его обнаружить.

О неоднородности
Мы уже упомянули, что неоднородность данных — один из самых злейших врагов, с которым мы боремся. Неоднородности проистекают из разных первопричин:
- неоднородность по магазинам — у каждого магазина свое среднее значение по метрике (у московских магазинов РТО и трафик значительно больше, чем у деревенских)
- неоднородность по дням недели — в разные дни недели разное распределение трафика и разный средний чек: трафик во вторник не похож на трафик в пятницу
- неоднородность по погоде — в разные погодные условия люди ходят в магазины по-разному
- неоднородность по времени года — трафик в зимние месяцы отличается от трафика летом — это надо учитывать, если пилот длится несколько недель.
Неоднородность увеличивает дисперсию, которая, как упоминалось выше, при оценке РТО магазинов и без того принимает огромные значения. Размер улавливаемого эффекта напрямую зависит от дисперсии. Например, уменьшение дисперсии в четыре раза позволяет детектировать в два раза меньший эффект.
В самом простом случае мы боремся с неоднородностью линеаризацией.
Допустим, у нас был пилот в двух магазинах в течение трех дней (да-да, это противоречит всем расписанным формулам про размер эффекта, но это пример). Средние РТО в магазинах соответственно 200 тысяч и 500 тысяч, при этом дисперсия в обеих группах 10000, а по всем наблюдениям — 35000
После пилота средние в группах 300 и 600 и дисперсии 10000 и 22500 соответственно, а всей группы — 40000.

Простой и изящный ход — линеаризовать данные, т.е. вычесть из каждого значения периода среднее за предыдущий.

На выходе выборка: 100, 0, 200, -50, 100, 250. Дисперсия на пилотном периоде сократилась в 3 раза до 13000.
Значит, мы можем увидеть гораздо более тонкий эффект, чем с изначальными абсолютными значениями.
Это не единственный способ борьбы с неоднородностью. О других мы расскажем в следующей статье.
Общий подход к A/B-тестированию
Подготовка к крупным пилотам и их оценка проходят через нашу команду и подвергаются тщательной проверке.
Наш протокол:
- получить от заказчика информацию о метрике и ожидаемому эффекту;
- определить размер групп и длительностью пилота;
- разработать алгоритм распределения магазинов по группам;
- провести А/А-тест между группами и валидировать этот алгоритм;
- дождаться окончания пилота и рассчитать эффект.
Ни один из этих этапов не проходит без сложностей, на каждом из них есть особенности. Как мы разбираемся с частью из них, мы рассказали в этой статье. В следующей расскажем о ….
Команда
В конце хотелось бы упомянуть всех действующих лиц:
- Валерий Бабушкин
- Александр Сахнов
- Денис Иванов
- Сергей Демченко
- Николай Назаров
- Сергей Кабанов
- Юрий Галимуллин
- Элен Теванян
- Владислав Ладенков
- Сергей Захаров
- Василий Рассказов
- Александр Беляев
- Кисмат Магомедов
- Егор Крашенниников
- Егор Карнаух
- Святослав Орешин
- Юрий Трубицын
