Как прогнозировать спрос и автоматизировать закупки с помощью machine learning: кейс Ozon

В интернет магазине Ozon есть примерно всё: холодильники, детское питание, ноутбуки за 100 тысяч и т.д. Значит, все это есть и на складах компании — и чем дольше товары там лежат, тем дороже обходятся компании. Чтобы выяснить, сколько и чего людям захочется заказать, а Ozon нужно будет закупить, мы использовали machine learning.
Прогноз продаж: сложности задачи
Прежде чем углубляться в постановку задачи, начнем с примера. Это реальный график продаж товара на Ozon за какое-то время. Вопрос: куда он пойдет дальше?
У человека с околотехническим образованием к такой постановке задачи появятся вопросы: А где оси? А что за товар? А в каких единицах? Какой институт окончил? — и многие другие, не вошедшие в эту статью по этическим соображениям.
В самом деле, правильно ответить на вопрос в такой постановке не может никто, а если кто-то и может, то скорее всего ошибется.
Добавим к этому графику еще немного информации: оси и изменения цены на сайте Ozon (синий) и сайте конкурента (оранжевый).
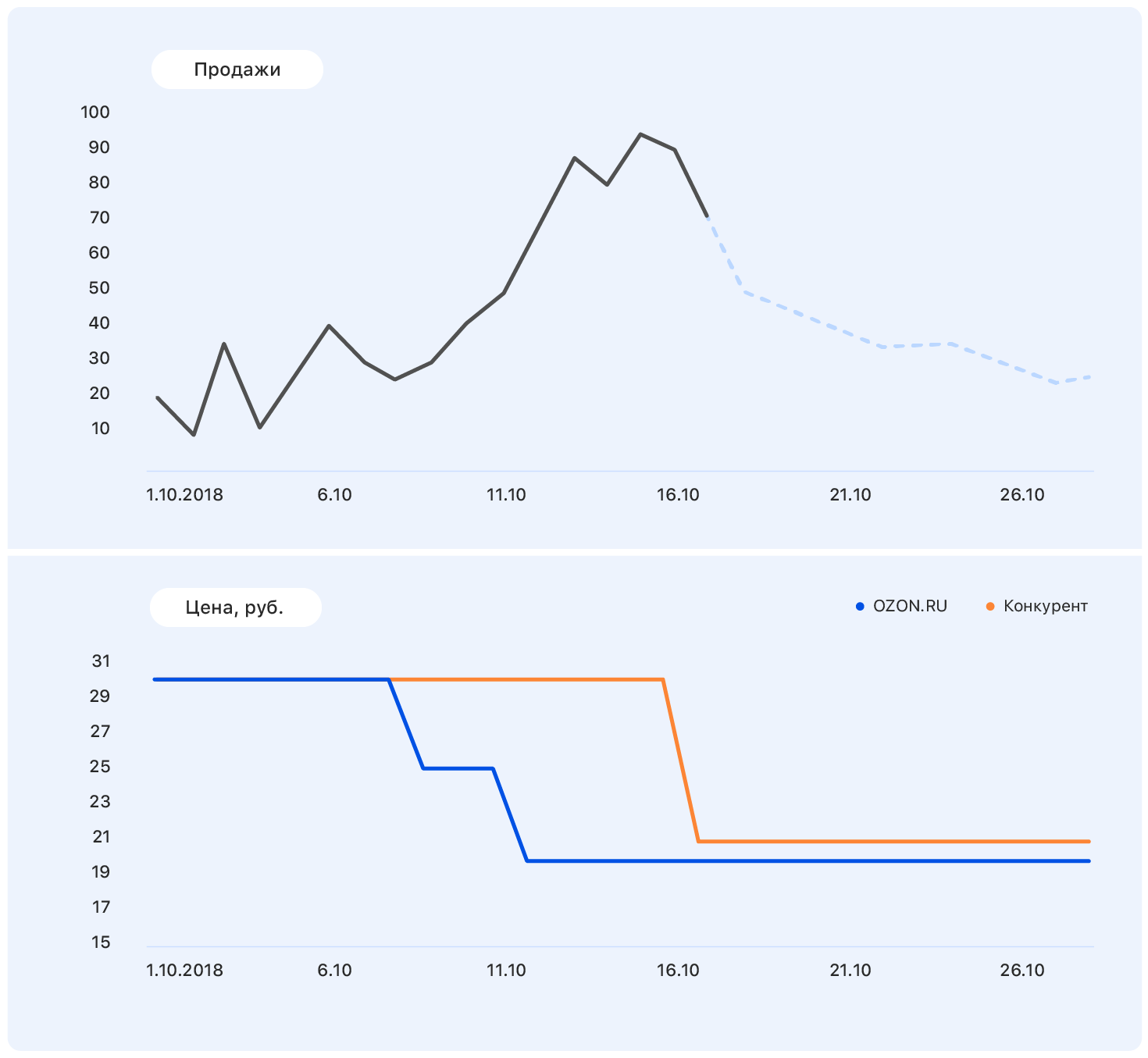
У нас цена в какой-то момент снизилась, а у конкурентов осталась прежней — и продажи у Ozon пошли вверх. Планы ценообразования мы знаем: у нас цена останется на том же уровне, но и конкурент вслед за Ozon снизил цену почти до уровня нашей.
Этих данных достаточно, чтобы сделать осмысленные предположение — например, что продажи вернутся на прежний уровень. И если посмотреть на график, выяснится, что так оно и будет.
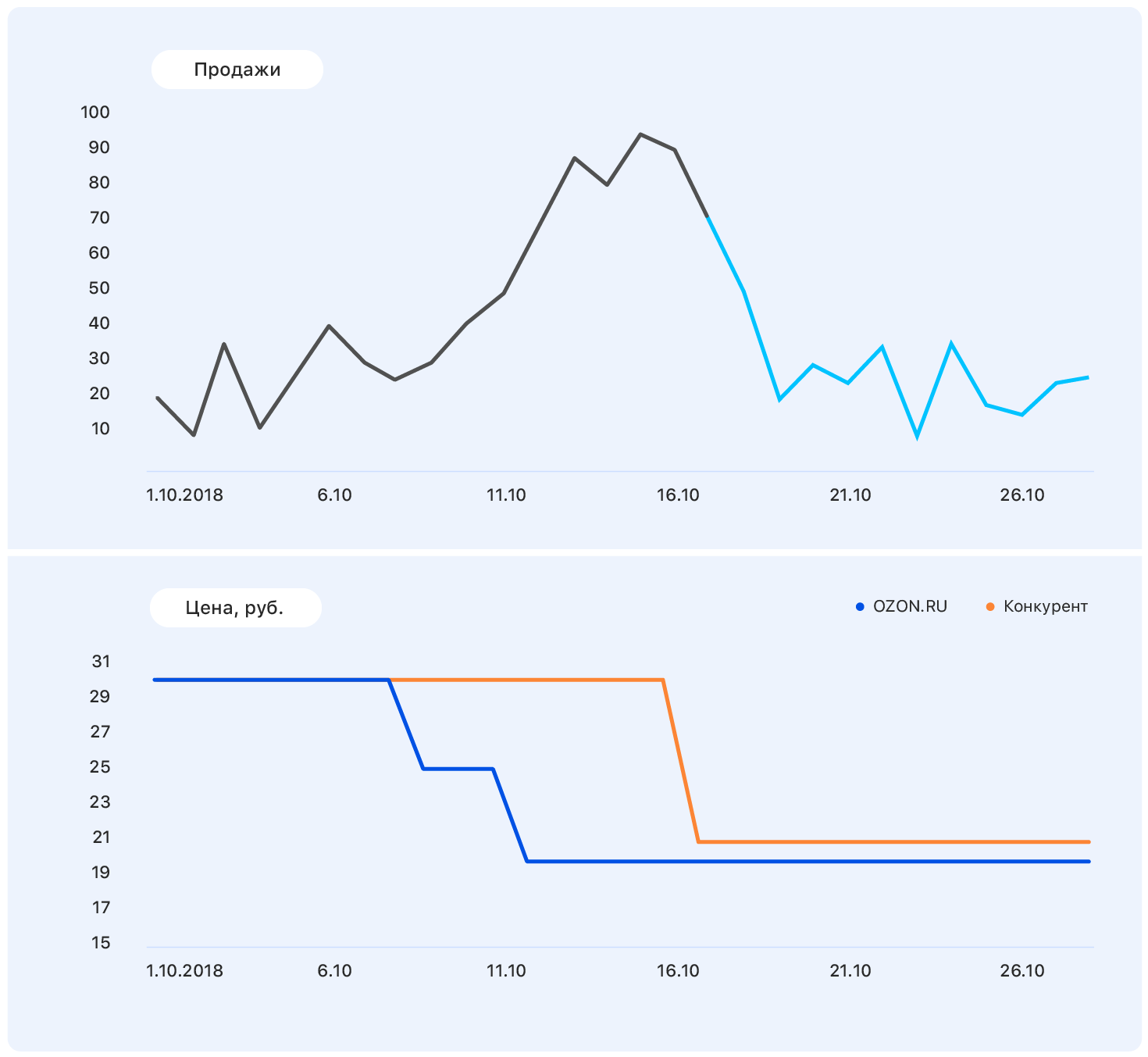
Проблема в том, что на самом деле спрос на этот товар далеко не так сильно подвержен влиянию цены, и рост продаж был вызван в том числе отсутствием большей части конкурентов этого товара в нашем магазине. Остается еще множество факторов, которые мы не учли: рекламировался ли товар по ТВ? или, может, это конфеты, а скоро 8 марта?
Ясно одно: составить прогноз «на коленке» не получится. Мы пошли по стандартному пути граблей и костылей построения любого ML алгоритма. И вот как это было.
Выбор метрики
Выбор метрики — то, с чего нужно начать, если ваши прогнозом будет пользоваться еще хотя бы один человек, помимо вас.
Рассмотрим пример: у нас есть три варианта прогноза. Какой лучше?
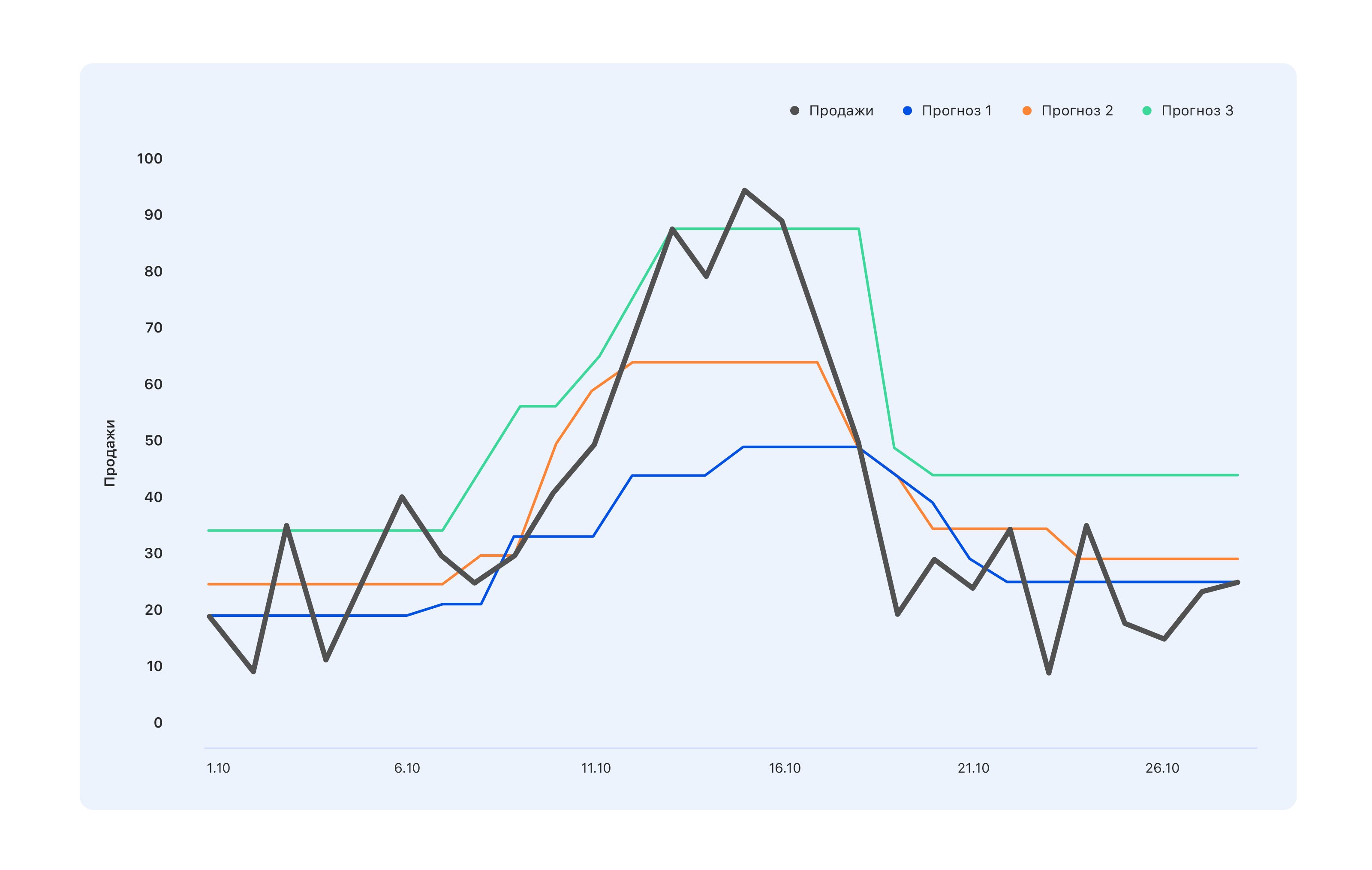
С точки зрения специалистов на складе, нам нужен синий прогноз — купим чуть меньше, и пусть упустим пик в середине октября, зато на складе ничего не залежится. У специалистов, чьи KPI завязаны на продажи, мнение противоположное: даже бирюзовый прогноз не совсем правильный, не все скачки спроса отразили — идите дорабатывайте. А с точки зрения человека со стороны вообще лучше что-то среднее — чтоб всем было хорошо или наоборот плохо.
Поэтому, прежде чем строить прогноз, нужно определить, кто и зачем будет им пользоваться. То есть, выбрать метрику и понять, чего от прогноза, построенного по такой метрике, ждать. И ждать именно этого.
Мы выбрали MAE — средняя абсолютная ошибка. Такая метрика подходит для нашей сильно несбалансированной обучающей выборки. Поскольку ассортимент очень широкий (1.5 млн наименований), каждый товар в отдельности в конкретном регионе продается в небольших количествах. И если в сумме мы продаем сотни зеленых платьев, то конкретное зеленое платье с котиками продается по 2–3 в день. В итоге выборка смещается в сторону небольших значений. С другой стороны, есть айфоны, спиннеры, новая книга Ольги Бузовой (шутка) и т.д. — и они продаются в любом городе в огромных количествах. MAE позволяет не получать огромных штрафов на условных айфонах и в целом хорошо работать на основной массе товаров.
Первые шаги
Мы начали с того, что построили самый глупый прогноз, какой только может быть: за следующую неделю будет продано случайное число от 0 до 1000 — и получили метрику MAE = 496. Наверное, можно и хуже, но и это уже очень плохо. Так у нас появился ориентир: если мы получим такое значение метрики, то явно что-то делаем не так.
Дальше мы начали играть в людей, которые знают, как сделать прогноз без машинного обучения, и попробовали предсказывать продажи товара за следующую неделю равными средним продажам за все прошлые недели, и получили метрику МАЕ = 1,45 — что уже значительно лучше.
Продолжая рассуждать, мы решили, что более релевантными для прогноза продаж за будущую неделю будет не средние, а продажи за прошлую неделю. У такого прогноза MAE был равен 1,26. На следующем витке прогностической мысли мы решили учесть оба фактора и предсказывать продажи на следующую неделю как сумму 50% средних продаж и 50% продаж за последнюю неделю — получили МАЕ = 1,23.
Но и это нам показалось слишком просто, и мы решили все усложнить. Мы собрали небольшую обучающую выборку, в которой признаками являлись прошлые и средние продажи, а таргетами — продажи за следующую неделю, и обучили на ней простенькую линейную регрессию. Получили веса 0,46 и 0,55 для средней и прошлой недель и MAE на тестовой выборке, равное 1,2.
Вывод: у наших данных есть прогностический потенциал.
Feature engineering
Решив, что строить прогноз по двум признакам — это не наш уровень, мы сели за генерацию новых сложных фичей. Это и информация о прошлых продажах — за 1, 2, 3, 4 недели назад, за неделю ровно год назад и т.д. И просмотры за прошлые недели, добавления в корзину, конверсии просмотров и добавлений в корзину в заказы — и все это за разные периоды.
Нам нужно было дать модели знания о том, как товар в целом продается, как меняется динамика его продаж в последнее время, как эволюционирует интерес к нему, как его продажи зависят от цены и других факторов, которые по нашему мнению, могут быть полезны.
Когда у нас идеи кончились, мы пошли к экспертам отдела продаж. Там мы, например, узнали, что следующий год — год свиньи, следовательно товары хотя бы отдаленно напоминающие свиней, будут пользоваться повышенной популярностью. Или, например, что «незамерзайку» наши люди покупают не заранее, а ровно в день первых морозов — так что будьте добры, учтите прогноз погоды. В общем, все остались довольны. Мы — тем, что получили кучу новых идей, до которых никогда бы не додумались сами, а коммерсанты — тем, что скоро можно будет заняться чем-нибудь более интересным, чем прогноз продаж.
Но это все еще слишком просто — и мы добавили комбинированные признаки:
- конверсию из просмотров в продажи — какой она была, как менялась;
- отношение продаж за 4 недели к продажам за последнюю неделю (если эта цифра сильно отличается от 4, в данный момент спрос на этот товар подвержен «турбулентности»);
- отношение продаж товара к продажам во всей категории — если эта цифра близка к единице, значит, товар «монополист».
На этом этапе нужно придумать как можно больше — неинформативные признаки выбросите на этапе обучения.
В итоге у нас получилось 170 признаков. Забегая вперед, наибольший feature importance имели
- Продажи за прошлую неделю (за две, три и четыре).
- Доступность товара на прошлой неделе — процент времени, когда товар присутствовал на сайте.
- Угловой коэффициент графика продаж товара за последние 7 дней.
- Отношение прошлой цены к будущей — с огромной скидкой товар начнуть покупать активнее.
- Количество прямых конкурентов внутри нашего сайта. Если, например, эта ручка единственная в своей категории, продажи будут довольно стационарными.
- Габариты товара — выяснилось, что длина и ширина значительно влияют на предсказуемость продаж. Почему-то у длинных и узких предметов — зонтов или удочек, например — график значительно более волатилен. Мы пока не знаем, как это объяснить.
- Номер дня в году — он показывает, скоро ли Новый год, 8 марта, старт сезонного повышения продаж и т.д.
Сбор выборки
Обучающая выборка — это боль. Мы собирали ее около 4 недель, две из которых просто ходили к разным хранителям данных и просили дать посмотреть то, что у них есть. Так бывает каждый раз, когда нужны данные за длительный период. Даже в идеальной системе сбора данных за долгое время произойдет что-то в духе «раньше мы считали эту штуку вот так, но потом начали считать иначе и писать данные в тот же столбец». Или год или два назад сервер упал, но никто не записал, когда именно — и нули уже не означают, что продаж не было.
В итоге нашем распоряжении были данные о том, что делали люди на сайте, что и в каких количествах добавляли в избранное и корзину, покупали. Мы собрали выборку примерно из 15 млн семплов по 170 фичей в каждом, таргетом являлось количество продаж за будущую неделю.
Мы написали 2 тысячи строк кода на Spark. Работал он медленно, но позволял пережевывать огромные объемы данных. Это только кажется, что посчитать угловой коэффициент прямой просто. А сделать это 10кк раз, когда продажи тянутся из нескольких баз — задача не для слабонервных.
Еще неделю мы занимались очисткой данных, чтобы модель не отвлекалась на выбросы и локальные особенности выборки, а извлекла только истинные зависимости, свойственные продажам в Ozon. Здесь пойдут и 3 сигма и более хитрые методы поиска аномалий. Самый сложный кейс — восстановить продажи в периоды отсутствия товара на складе. Самое простое решение — выбрасывать недели, когда товар отсутствовал в течение «таргетной» недели.
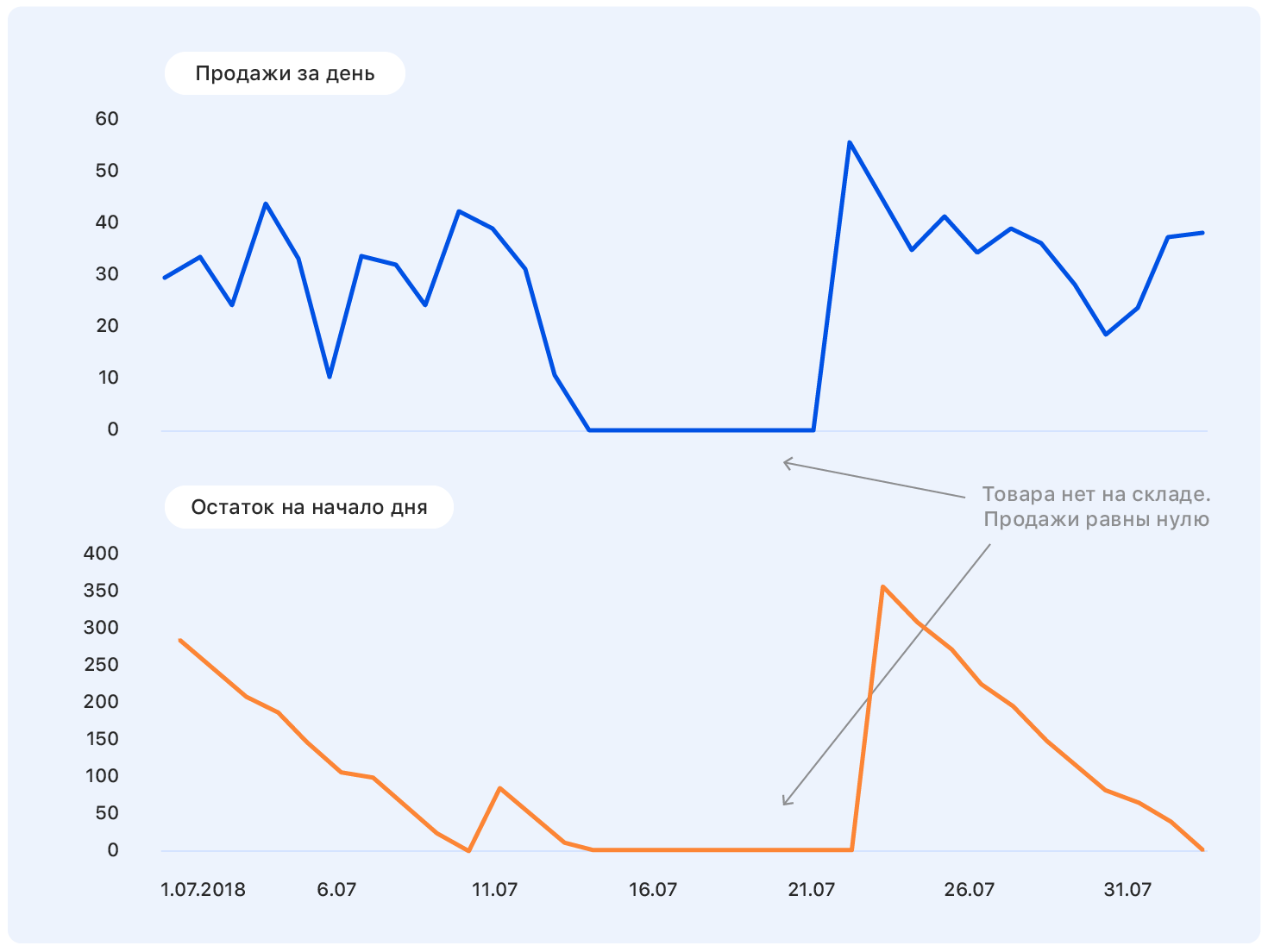
В результате из 15 млн семплов осталось 10 млн. Здесь важно не увлечься и не потерять полноту выборки (в самом деле, отсутствие товара на складе — косвенная характеристика его важности для компании; убрать из выборки такие товары не то же самое, что выкинуть случайные семплы).
Время ML
На чистой выборке и начали обучать модели. Естественно, начали с линейной регрессии и получили MAE = 1,15. Кажется, что это совсем небольшой прирост, но когда у тебя выборка 10 млн в которой средние значения 5–10, даже небольшое изменение значения метрики дает несоизмеримый прирост визуального качества прогноза. А поскольку вам в итоге придется презентовать решение бизнес-заказчикам, повышение уровня их радости — немаловажный фактор.
Дальше был sklearn.ensemble.RandomForestRegressor, который после непродолжительного подбора гиперпараметров показал MAE = 1,10. Следом попробовали XGBoost (куда без него) — все было бы хорошо и MAE = 1,03 — только очень долго. У нас, к сожалению, не было доступа к GPU для обучения XGBoost, а на процессорах одна модель обучалась очень долго. Мы попробовали найти что-то более быстрое, и остановились на LightGBM — он обучался в два раза быстрее и показал MAE даже чуть меньше — 1,01.
Мы разбили все товары на 13 категорий, как и в каталоге на сайте: столы, ноутбуки, бутылки, и для каждой из категорий обучили модели с разной глубиной прогноза — от 5 до 16 дней.
Обучение заняло примерно пять суток, и для этого мы подняли огромные вычислительные кластеры. Мы разработали такой пайплайн: долго работает random search, отдает 10 лучших наборов гиперпарметров, и дальше с ними работает дата сайентист уже вручную — строит дополнительные метрики качества (мы считали MAE для разных диапазонов таргетов), строит learning curves (например, мы выбрасывали часть обучающей выборки и обучали снова, проверяя, уменьшают ли новые данные loss на тестовой выборке) и другие графики.
Пример подробного анализа для одного из наборов гиперпараметров
|
Train set: |
Test set: |
| Для target =0, MAE=0.142222484602 | Для 0 MAE=0.141900737761 |
| Для target >0 MAPE=45.168530676 | Для>0 MAPE=45.5771812826 |
| Ошибок больше 0 — 67.931341691% | Ошибок больше 0 — 51.6405939896% |
| Ошибок больше 1 — 19.0346986379% | Ошибок больше 1 — 12.1977096603% |
| Ошибок больше 2 — 8.94313926245% | Ошибок больше 2 — 5.16977226441% |
| Ошибок больше 3 — 5.42406856507% | Ошибок больше 3 — 3.12760834969% |
| Ошибок больше 4 — 3.67938161595% |
Ошибок больше 4 — 2.10263125679% |
| Ошибок больше 5 — 2.67322988948% |
Ошибок больше 5 — 1.56473158807% |
| Ошибок больше 6 — 2.0618556701% |
Ошибок больше 6 — 1.19599209102% |
| Ошибок больше 7 — 1.65887701209% | Ошибок больше 7 — 0.949300173983% |
| Ошибок больше 8 — 1.36821095777% |
Ошибок больше 8 — 0.78310772461% |
| Ошибок больше 9 — 1.15368611519% | Ошибок больше 9 — 0.659205318158% |
| Ошибок больше 10 — 0.99199395014% | Ошибок больше 10 — 0.554593106723% |
| Ошибок больше 11 — 0.863969667827% | Ошибок больше 11 — 0.490045146476% |
| Ошибок больше 12 — 0.764347266082% |
Ошибок больше 12 — 0.428835873827% |
| Ошибок больше 13 — 0.68086818247% | Ошибок больше 13 — 0.386545830907% |
| Ошибок больше 14 — 0.613446089087% | Ошибок больше 14 — 0.343884822697% |
| Ошибок больше 15 — 0.556297016335% |
Ошибок больше 15 — 0.316433391328% |
| Для таргета = 0, MAE = 0.142222484602 |
Для таргета = 0, MAE = 0.141900737761 |
| Для таргета = 1, MAE = 0.63978556493 |
Для таргета = 1, MAE = 0.660823509405 |
| Для таргета = 2, MAE = 1.01528075312 | Для таргета = 2, MAE = 1.01098070566 |
| Для таргета = 3, MAE = 1.43762342295 | Для таргета = 3, MAE = 1.44836233499 |
| Для таргета = 4, MAE = 1.82790678437 |
Для таргета = 4, MAE = 1.86539223382 |
| Для таргета = 5, MAE = 2.15369976552 |
Для таргета = 5, MAE = 2.16017884573 |
| Для таргета = 6, MAE = 2.51629758129 |
Для таргета = 6, MAE = 2.51987403661 |
| Для таргета = 7, MAE = 2.80225497415 |
Для таргета = 7, MAE = 2.97580015564 |
| Для таргета = 8, MAE = 3.09405048248 |
Для таргета = 8, MAE = 3.21914648525 |
| Для таргета = 9, MAE = 3.39256765159 |
Для таргета = 9, MAE = 3.54572928241 |
| Для таргета = 10, MAE = 3.6640339953 | Для таргета = 10, MAE = 3.84409605282 |
| Для таргета = 11, MAE = 4.02797747118 |
Для таргета = 11, MAE = 4.21828735273 |
| Для таргета = 12, MAE = 4.17163467899 |
Для таргета = 12, MAE = 3.92536509115 |
| Для таргета = 14, MAE = 4.78590364522 |
Для таргета = 14, MAE = 5.11290428675 |
| Для таргета = 15, MAE = 4.89409916994 |
Для таргета = 15, MAE = 5.20892023117 |
Train loss = 0.535842111392
Test loss = 0.895529959873

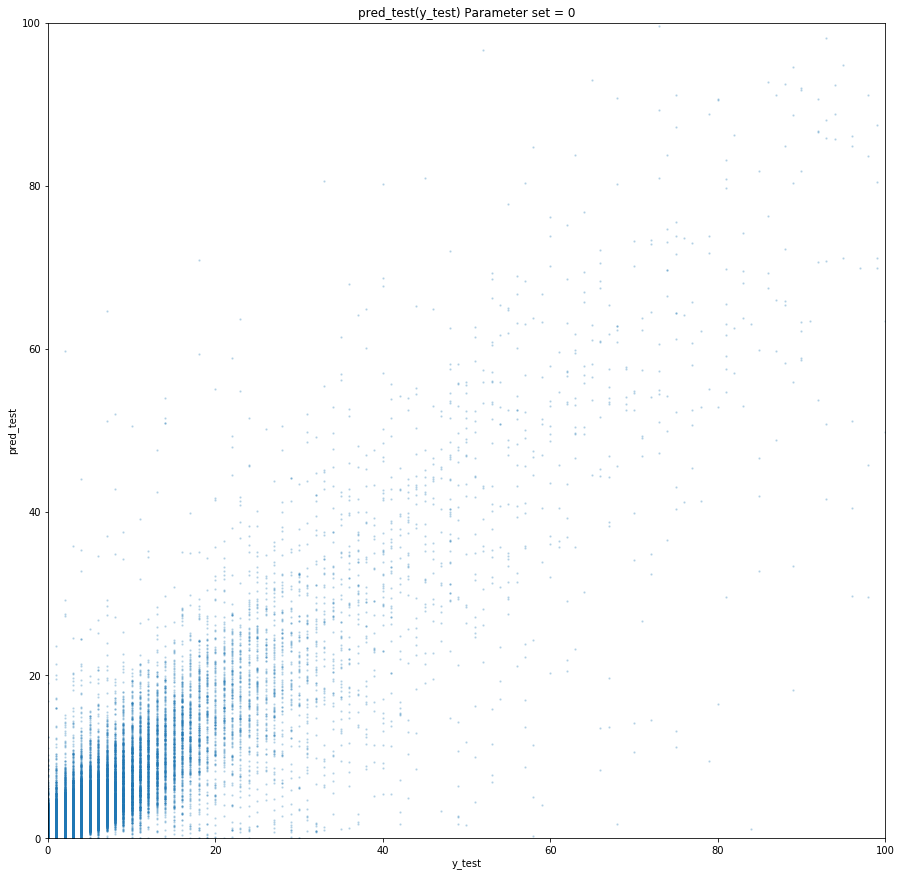
Если ни один не подходит — снова random search. Вот так мы впятером 4 или 5 дней промышленными темпами обучали модель. Мы дежурили, кто-то ночью, кто-то утром просыпался, 10 лучших параметров отсматривал, перезапускал или сохранял модель и ложился спать дальше. В таком режиме мы работали неделю и обучили 130 моделей — 13 типов товаров и 10 глубин прогноза, в каждой было 170 фичей. Среднее значение MAE на 5-fold time series cv у нас получилось равным 1.
Может показаться, что это не очень круто — и это так, если только у тебя в выборке единичек не большая часть. Как показывает анализ результатов, единицы предсказываются хуже всего — то, что товар купили один раз за неделю не говорит ничего о том, есть ли на него спрос. Один раз может продаться что угодно — найдется человек, который купит фарфоровую статуэтку в виде стоматолога, и это ничего не говорит ни о будущих продажах, ни о прошлых. В общем, мы не стали по этому поводу сильно расстраиваться.
Tips and tricks
Что шло не так и как можно этого избежать?
Первая проблема — подбор параметров. Мы начали пользоваться RandomizedSearchCV — это известный тул из sklearn для перебора гиперпараметров. Вот тут нас и ждал первый сюрприз.
from sklearn.model_selection import ParameterSampler
from sklearn.model_selection import RandomizedSearchCVestimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=72)
param_grid = {'boosting_type': boosting_type, 'num_leaves': num_leaves, 'max_depth': max_depth, 'learning_rate':learning_rate, 'n_estimators': n_estimators, 'subsample_for_bin': subsample_for_bin, 'min_child_samples': min_child_samples, 'colsample_bytree': colsample_bytree, 'reg_alpha': reg_alpha, 'max_bin': max_bin}
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=1, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
Расчет просто глохнет (что важно, он не падает, а продолжает работать, но на все меньшем количестве ядер и в какой-то момент просто останавливается).
estimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=1)rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=72, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
Но RandomizedSearchCV под каждый «job» загребает чуть ли не весь датасет. Соответственно, приходится сильно расширять объем оперативной памяти, возможно, жертвуя количеством ядер.
Кто бы нам тогда сказал о таких прекрасных вещах, как hyperopt! С тех пор, как узнали, пользуемся только им.
Еще один трюк, который пришел нам в голову ближе к концу проекта — выбирать модели, которые имели параметр callsemple_bytree (это параметр LightGBM, который говорит, какой процент фич отдать каждому лернеру) в районе 0,2–0,3, поскольку, когда машина работает в продакшене, каких-то таблиц может не быть, и отдельные фичи могут быть посчитаны неверно. Такая регуляризация позволяет сделать так, чтобы эти непросчитанные фичи зааффектили хотя бы не всех лернеров внутри модели.
Эмпирически мы пришли к тому, что нужно делать побольше эстиматоров и посильнее закручивать регуляризацию. Это не правило работы с LightGBM, но такая схема у нас сработала.
Ну и, конечно, Spark. Например, есть баг, который знает и сам Spark: если взять из таблицы несколько столбцов и сделать новую, а потом из этой же таблицы взять уже другие и делать новую, а потом поджойнить полученные таблицы — все сломается, хотя не должно. Спастись можно, только избавившись от всех ленивых вычислений. Мы даже функцию специальную написали — bumb_df, она превращает Data Frame в RDD обратно в Data Frame. То есть, сбрасывает все ленивые вычисления. Этим можно себя обезопасить от большинства проблем Spark.
def bump_df(df):
# to avoid problem: AnalysisException: resolved attribute(s)
df_rdd = df.rdd
if df_rdd.isEmpty():
df = df_rdd.toDF(schema=df.schema)
return df
else:
return df_rdd.toDF(schema=df.schema)
Прогноз готов: сколько закажем?
Прогноз продаж — задача сугубо математическая и, если нормальное распределение ошибки с нулевым средним для математика — победа, то для коммерсантов, у которых каждый рубль на счету — это недопустимо.
Если один лишний айфон или одно модное платье на складе — это не проблема, а, скорее, страховой запас, то отсутствие на складе того же айфона — это потери как минимум маржи, а как максимум — имиджа, и допускать этого нельзя.
Чтобы научить алгоритм закупать столько, сколько нужно, нам пришлось посчитать стоимость пере- и недозакупки каждого товара и обучить простенькую модель, чтобы минимизировать возможные потери в деньгах.
Модель получает на вход прогноз продаж, прибавляет к нему случайный, нормально распределенный шум (моделируем неидеальность поставщиков) и учится для каждого конкретного товара прибавить к прогнозу ровно столько, чтобы минимизировать потери в деньгах.
Таким образом, заказ — это прогноз + страховой запас, гарантирующий покрытие ошибки самого прогноза и неидеальности внешнего мира.
Как в проде
У Ozon есть свой достаточно большой вычислительный кластер, на котором каждую ночь запускается пайплайн (мы пользуемся airflow) из более чем 15 джоб. Выглядит это так:

Каждую ночь алгоритм запускается, затягивает в локальный hdfs около 20 Гб данных из самых разных источников, выбирает для каждого товара поставщика, собирает фичи для каждого товара, делает прогноз продаж и формирует заявки, исходя из расписания поставок. К 6–7 утра мы отдаем на стол людям, которые это отвечают за работу с поставщиками готовые таблицы, которые по нажатию одной кнопки улетают поставщикам.
Не прогнозом единым
Обученная модель знает о зависимости прогноза от любой фичи и, как следствие, если заморозить N-1 признаков и начать изменять один, можно наблюдать, как он влияет на прогноз. Конечно, самое интересное в этом — как продажи зависят от цены.
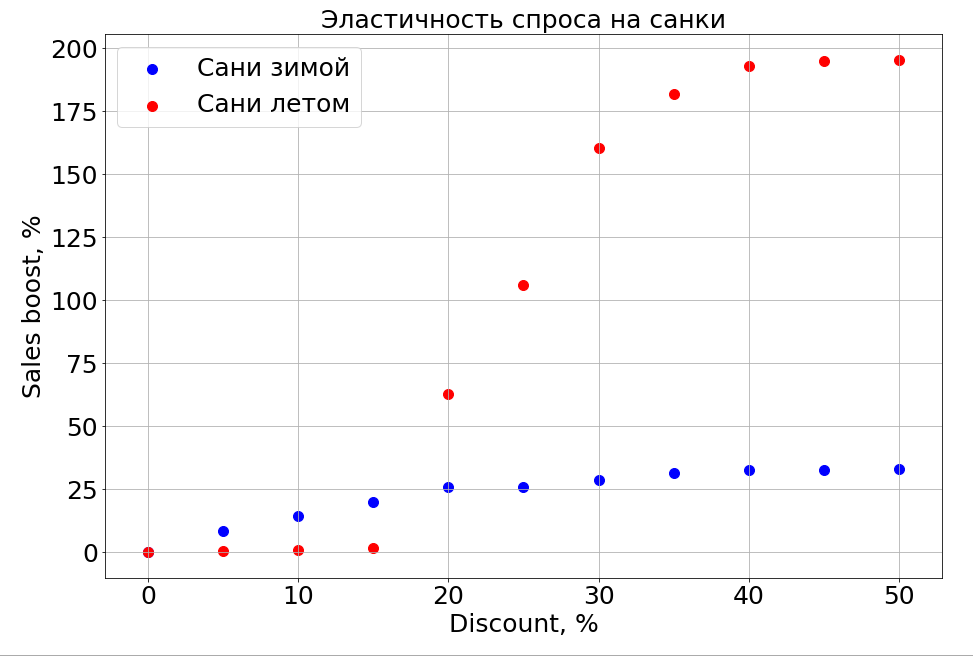
Важно заметить, что спрос зависит не только от цены. Например, если летом делать небольшие скидки на санки, это все равно не помогает им продаваться. Делаем скидку больше, и появляются люди, которые «готовят сани летом». Но до определенного уровня скидок мы все равно не сможем достучаться до той части мозга, которая отвечает за планирование. Зимой же это работает как для любого товара — делаешь скидку, и он продается быстрее.
Планы
Сейчас мы активно изучаем кластеризацию временных рядов, чтобы распределить товары по кластерам исходя из характера кривой, описывающей их продажи. Например, сезонные, традиционно популярные летом или, наоборот, зимой. Когда научимся хорошо отделять товары с длительной историей продаж, планируем выделить item-based фичи, которые подскажут, каким будет паттерн продаж нового, только что появившегося товара — пока это наша главная задача.
Дальше обязательно будут и нейронные сети, и параметрические модели временных рядов, и все это в ансамбле.
В том числе благодаря новой системе прогнозирования Ozon перешел от закупок товаров с запасом к цикличным поставкам, когда мы покупаем от одной поставки к другой и не храним на складе остатки.
Теперь нам предстоит решить, как научить алгоритм предсказывать продажи новых товаров и целых категорий. В следующем году компания планирует рост х10 продаж в категориях и х2,5 в площадях fulfillment. И нам нужно рассказать модели, что эти старые данные релевантны, но для другого, прошлого магазина. И пока мы пока думаем, как это сделать.
Вторая по природе своей иррациональная вещь, которую нам предстоит научиться прогнозировать — мода. Как можно было предсказать, что спиннер будет так продаваться? Как предсказать продажи новой книги Дэна Брауна, если одну его книгу раскупают, а другую нет? Пока мы над этим работаем.
Если вы знаете, как можно было сделать лучше, или у вас есть истории про использование machine learning в бою — го в комментарии, обсудим.
