Как применение кодов избыточности в SDS помогает Яндексу дёшево и надёжно хранить данные
Яндекс, как и любая другая большая интернет-компания, хранит много, а точнее очень много данных. Это и пользовательские данные из разных сервисов, и намайненные сайты, и промежуточные данные для расчёта погоды, и резервные копии баз данных. Стоимость хранения ($/ГБ) — один из важных показателей системы. В этой статье я хочу рассказать вам про один из методов, который позволил нам серьезно удешевить хранилище.

В 2015 году, как вы все помните, сильно вырос курс доллара. Точнее, расти-то он начал в конце 2014-го, но новые партии железа мы заказывали уже в 2015-м. Яндекс зарабатывает в рублях, и поэтому вместе с курсом выросла и стоимость железа для нас. Это заставило нас в очередной раз подумать о том, как сделать, чтобы в текущий кластер можно было положить больше данных. Мы такое, конечно, делаем регулярно, но в этот раз мотивация была особенно сильной. Кстати, если после поста у вас останутся вопросы, которые бы вы хотели обсудить лично, приходите на нашу встречу.
Каждый сервер кластера предоставляет для нас следующие ресурсы: процессор, оперативную память, жёсткие диски и сеть. Сеть здесь — более сложное понятие, чем просто сетевая плата. Это ещё и вся инфраструктура внутри дата-центра, и связность между разными дата-центрами и точками обмена трафиком. В кластере для обеспечения надёжности применялась репликация, и суммарный объём кластера определялся исключительно через суммарную ёмкость жёстких дисков. Нужно было придумать, как обменять оставшиеся ресурсы на увеличение места.
Оперативную память обменять сложно. Мы используем дисковые полки, и разница в объёме оперативной памяти к ёмкости дисков — больше трёх порядков. Её можно использовать для ускорения доступа в рамках одной машины, но это история для отдельной статьи.
Процессор обменивается достаточно очевидно — через архивацию. Но нужно обратить внимание на несколько подводных камней. Во-первых, степень сжатия сильно зависит от комбинации архиватора и хранимых данных, то есть нужно взять репрезентативную выборку данных и на ней оценить, сколько получится сэкономить. Во-вторых, архиватор должен обеспечивать возможность читать данные практически с любого места, иначе придётся забыть про Range-заголовок в HTTP (а на это обидятся клиенты с не очень хорошим интернетом, которые больше не смогут скачивать большие файлы). В-третьих, немаловажна скорость сжатия и распаковки, а также сопутствующий расход CPU. Можно взять архиватор, который будет сжимать данные довольно эффективно, но количества процессоров в вашем кластере не хватит, чтобы обеспечить текущую скорость записи. При распаковке, в свою очередь, будет страдать latency запросов. Не так давно Facebook официально выпустил свой архиватор Zstd — мы рекомендуем его попробовать. Он очень быстрый и при этом неплохо сжимает данные.
Из всех ресурсов остаётся сеть, и с ней у нас большой простор для творчества. О том, как обменять сеть на ёмкость хранилища, как раз и пойдёт речь дальше.
У Яндекса достаточно жёсткие требования к системе хранения. Она должна оставаться работоспособной даже при потере одного дата-центра целиком. Такое условие накладывает довольно сильные ограничения на технологии, которые можно применять, но в обмен мы получаем более высокую надёжность, чем у самого дата-центра. Для нас как для разработчиков системы хранения это означает, что коэффициент избыточности должен быть больше единицы при выпадении любого ДЦ.
Вообще, правильнее говорить о зонах доступности. В нашем случае это именно дата-центр целиком, но это может быть и отдельная машина, стойка, машзал или даже континент. То есть если у нас есть четыре зоны доступности и мы равномерно распределили между ними данные, то степень избыточности не может быть меньше, чем 1.(3), по 0.(3) в каждой из зон. Итак, есть N зон доступности и нужно как-то разложить по ним данные.
Реплики
Очевидно, самый простой способ — сделать полные реплики. Чаще всего делают две или три реплики, и мы много лет жили именно по такой схеме. Недостатки очевидны: приходится использовать две (или, соответственно, три) гигабайта места на жёстких дисках для хранения одного гигабайта данных. Но есть и преимущества: в каждой реплике хранится полноценный файл, его легко прочитать, и при этом он целиком лежит на одной машине, на одном жёстком диске. Восстановить данные при потере диска тоже довольно просто — обычным копированием по сети.
За хранение контента пользователей, данных Яндекс.Музыки, разных аватарок и других подобных данных у нас отвечает сервис MDS — Media Storage. Он основан на Elliptics, Eblob и HTTP proxy. Elliptics предоставляет сетевую маршрутизацию, Eblob нужен для хранения данных на диске, прокси — для терминирования пользовательского трафика. Всем этим кластером управляет система под названием Mastermind. В нашем хранилище мы отошли от концепции больших DHT-колец, которые пробовали в Elliptics ранее, и разбили всё пространство на небольшие шарды по 916 гигабайт. Их мы называем «каплами» (от англ. couple). Цифра 916 выбрана из-за того, что нам нужно размещать кратное количество реплик каплов на одном жёстком диске (производители дисков, в свою очередь, любят маркетинг и считают объём в десятичных терабайтах). Mastermind следит за тем, чтобы реплики одного капла всегда располагались в разных ДЦ, запускает процедуру восстановления данных, дефрагментацию и вообще автоматизирует труд системных администраторов.

Для восстановления консистентности у нас есть специальная процедура, которая пробегает по всем ключам и дописывает недостающие ключи в те реплики, где их нет. Эта процедура не очень быстрая, но запускаем мы её только там, где между репликами есть расхождение в количестве живых ключей. Побочный плюс — создаётся нагрузка на жёсткий диск, даже если данные там холодные и пользователи за ними не приходят. В результате диск начинает умирать заранее, а не в тот момент, когда мы пытаемся восстановить данные, обнаружив, что другая реплика уже умерла. Мы его спокойно меняем, после чего автоматически запускается восстановление и данные пользователей остаются в целости и сохранности.
Коды избыточности
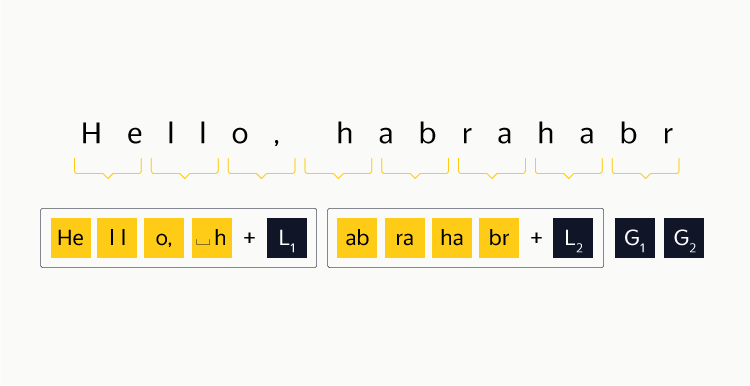
Если провести аналогию, подобный способ репликации данных — это RAID 1, простой, надёжный и не очень эффективный с точки зрения расходования места. Мы же хотим создать нечто аналогичное RAID 5 или RAID 6. Опять же, идём от простого к сложному: берём три зоны доступности, каким-либо образом разбиваем на блоки наши данные, в зону доступности 1 записываем чётные блоки, во вторую — нечётные, а в третью — результат побайтового XOR между блоками. Для обнаружения ошибок считаем по каждому блоку контрольную сумму, которая пренебрежимо мала в сравнении с размером блока. Восстановление данных элементарно: если a^b = c, то b = a^c. Коэффициент избыточности при таком подходе — 1,5. При потере любого блока потребуется прочитать два других, причём из разных зон доступности. Восстановление возможно при потере не более чем одного диска, что гораздо хуже, чем в случае трёх реплик, и сравнимо с двумя репликами. Вот как считается результат XOR для строки «Hello, habrahabr» (цифры снизу — десятичное представление байта):

Здесь стоит ввести понятие страйпа. Страйп — это N идущих подряд блоков, причём начало первого страйпа совпадает с началом потока данных, N зависит от выбранной схемы кодирования, и в случае с RAID 1 N=2. Для эффективного применения кодов избыточности нужно все файлы объединить в один непрерывный поток байтов, и уже его разбивать на страйпы. Рядом следует сохранить разметку, в каком стайпе и с какого байта начинается каждый файл, а также его размер. Если длина потока данных не кратна размеру страйпа, то надо оставшуюся часть заполнить нулями. Схематично это можно изобразить так:

При выборе размера страйпа можно воспользоваться следующими соображениями:
- чем больше размер блока, тем больше файлов поместится в один блок и тем меньше будет чтений сразу из двух зон доступности,
- чем больше размер блока, тем больше данных нужно перетащить по сети в случае временной недоступности блока или его потери.
Таким образом, нужно считать вероятности этих событий. У нас получилось, что оптимальный размер — две медианы размера файла. Кроме того, желательно так пересортировать файлы, чтобы границы блоков приходились на более крупные файлы, которые в один блок всё равно бы не поместились. Это тоже приведёт к снижению нагрузки на сеть. А чтобы упростить код, функция хранения блоков чётности закрепляется за одной из зон доступности.
Коды Рида-Соломона
Но что делать, если хочется большей надёжности? Правильно — использовать более мощные коды избыточности. Сейчас один из самых распространённых кодов — это код Рида-Соломона. Он используется при записи DVD-дисков, в цифровом ТВ (DVB-T), в QR-кодах, а также — в RAID 6. Мы здесь не станем рассказывать о математике полей Галуа — вас ждёт исключительно инженерный подход. Для всех вычислений мы задействуем библиотеку jerasure, у которой непростая судьба, но которая работает очень быстро и обладает всеми нужными нам функциями.
Первое, что стоит отметить: для эффективного результата нужно работать в полях 2^8, 2^16, 2^32, то есть в машинных словах. Далее мы для простоты будем использовать поле 2^8 и работать с байтами. Чтобы пример был более конкретным, попробуем достичь коэффициента репликации 1,5, но с двумя блоками чётности. Для этого потребуется разбить данные на страйпы по 4 блока каждый, и сгенерировать 2 блока чётности. Если взять из каждого блока данных первый байт, то можно составить вектор размерности 4 и, аналогично, вектор размерности 2 для блоков чётности. Чтобы из вектора размерности 4 получить вектор размерности 2, его нужно умножить на матрицу кодирования размером 2×4, причём умножать надо по правилам работы в полях Галуа, если смотреть с инженерной точки зрения. Матрица, которая нам нужна, называется матрицей Вандермонда. Для выбранного поля такая матрица гарантирует свойство, аналогичное отсутствию линейных комбинаций в обычной алгебре. При восстановлении данных оно тоже сыграет важную роль.
Возьмём один страйп данных «Hello, habrahabr». Он очень удачно разбивается на 4 блока по 4 байта в каждом, причём один байт соответствует одному слову кодирования.

Итак, получается следующая картинка:
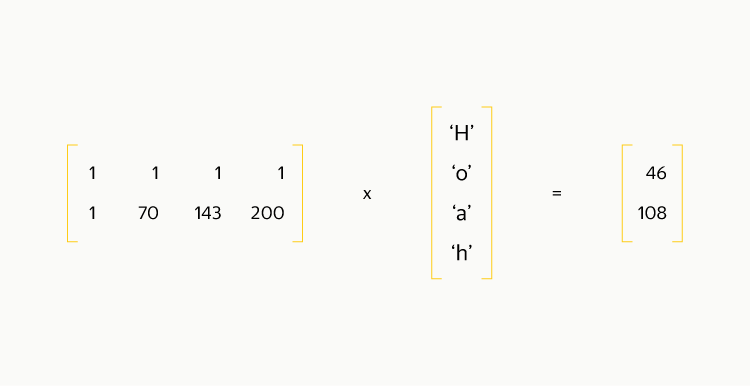
Посчитаем блоки чётности подобным образом, слово за словом (в нашем случае — байт за байтом).
Если немного изменить картинку и добавить единичную матрицу над матрицей кодирования, то в выходном векторе появятся исходные данные:

Предположим, что мы потеряли блок номер 2 и блок номер 4. Вычеркнем соответствующие строки из матрицы и из правого вектора:
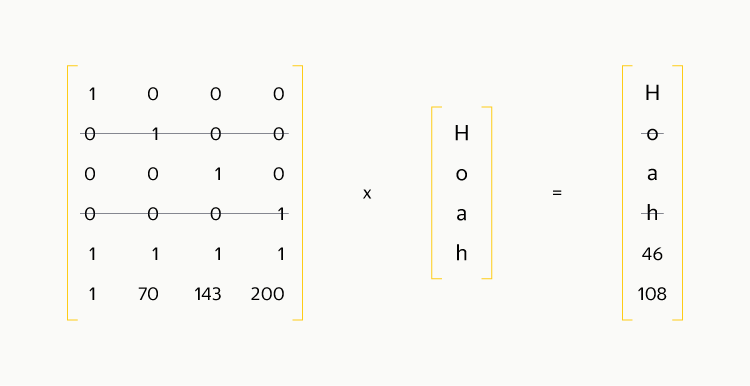
Затем обратим получившуюся квадратную матрицу и домножим на неё обе части равенства:
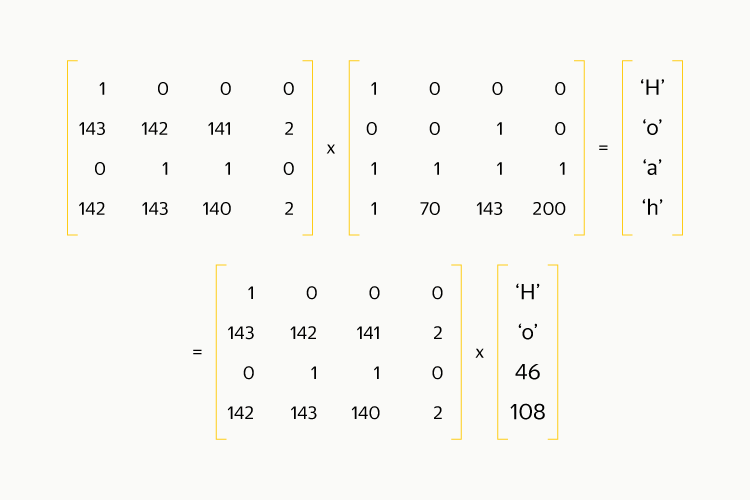
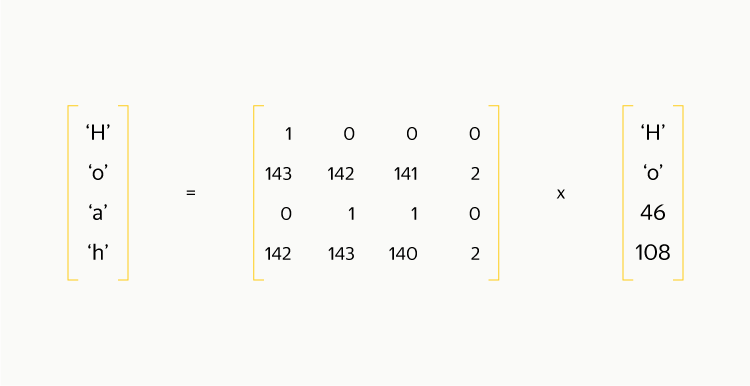
Получается, что для получения исходных данных нужно всего лишь провести такую же операцию умножения, как и при кодировании! Если потерялся всего один блок, то из матрицы кодирования, чтобы она стала квадратной, нужно вычеркнуть одну из строк, соответствующих блокам чётности. Обратите внимание, что первая строка состоит из единиц и обладает особой магией: подсчёт эквивалентен вычислению XOR между всеми элементами и выполняется в несколько раз быстрее, чем подсчёт любой другой строки. Поэтому выкидывать эту строку не стоит.
Local Recovery Codes
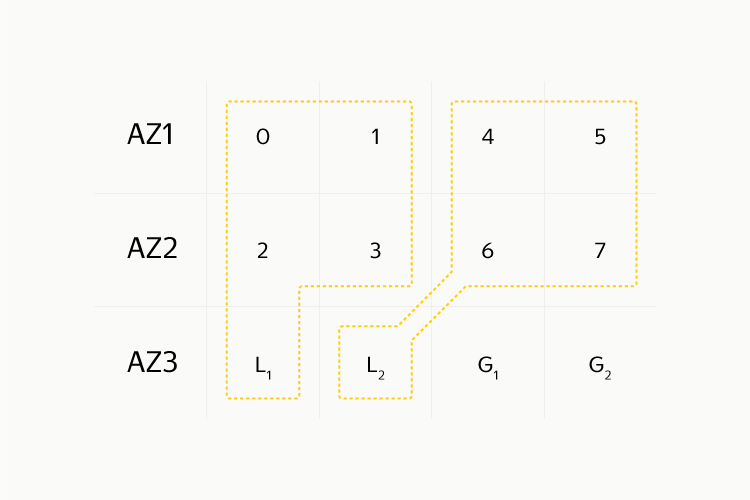
Получилось достаточно просто и, надеюсь, понятно. Но можно ли ещё что-нибудь улучшить? Да, говорят нам коллеги из Microsoft Azure в своей публикации. Этот метод называется Local Reconstruction Codes (LRC). Если разбить все блоки данных на несколько групп (например на две группы), то можно кодировать блоки чётности таким образом, чтобы локализовывать исправления ошибок внутри групп. Для прежнего коэффициента репликации 1,5 схема выглядит так: разбиваем страйп на две группы по четыре блока, для каждой группы будет свой локальный блок чётности плюс два глобальных блока чётности. Эта схема позволяет исправить любые три ошибки и около 96% ситуаций с четыремя ошибками. К оставшимся 4% относятся случаи, когда все четыре ошибки приходится на одну группу, куда входят 4 блока данных и локальный блок чётности.
Вновь применив подход «от простого к сложному», мы взяли и разделили строку единиц в матрице кодирования на две следующим образом:
| 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
| 1 | 55 | 39 | 73 | 84 | 181 | 225 | 217 |
| 1 | 172 | 70 | 235 | 143 | 34 | 200 | 101 |
for row in range(4):
for column in range(8):
k = 8
index = row * k + column
is_first_half = column < k / 2
if row == 0:
matrix[index] = 1 if is_first_half else 0
elif row == 1:
matrix[index] = 0 if is_first_half else 1
elif row == 2:
shift = 1 if is_first_half else 2 ** (k / 2)
relative_column = column if is_first_half else (column - k / 2)
matrix[index] = shift * (1 + relative_column)
else:
prev = array[index - k]
matrix[index] = libjerasure.galois_single_multiply(prev, prev, 8)С такой матрицей тест проходит успешно:
| 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
| 1 | 2 | 3 | 4 | 16 | 32 | 48 | 64 |
| 1 | 4 | 5 | 16 | 29 | 116 | 105 | 205 |
Здесь видно, что какую бы строку мы ни зачеркнули, в каждой группе локальности окажется не более трёх ошибок, а значит, данные можно будет прочитать. Если же сломается только один диск, на котором лежит один блок, то данные можно будет прочитать, запросив из другой зоны доступности всего лишь один дополнительный блок. Соображения по поводу размера блока — примерно такие же, как и в схеме с XOR, с одним исключением: если считать, что чтение окажется слишком дорогим только между зонами доступности, то размер блока можно сделать в четыре раза меньше, так как получится непрерывная последовательность в пределах одной зоны.
Практика
Теперь вы понимаете, что запрограммировать подсчёт кодов избыточности — достаточно простая задача, и можете применять эти знания в своих проектах. Варианты, которые мы рассмотрели в статье:
- Реплики — дают кратную избыточность, легко реализуемы (часто — дефолтный вариант), работают как на блочном, так и на файловом уровне.
- XOR, избыточность — 1,5, можно реализовать как на блочном, так и на файловом уровне, требует наличия трёх зон доступности.
- Коды Рида-Соломона — позволяют гибко выбирать степень избыточности, но для восстановления одного блока данных нужно прочитать столько же блоков, сколько содержит один страйп. Хорошо работают только на блочном уровне.
- LRС — похожи на коды Рида-Соломона, но при единичных сбоях позволяют читать меньше данных, хотя и обеспечивают восстановление данных в меньшем проценте случаев.
В MDS мы применили схему LRC-8–2–2 (8 блоков данных, 2 блока локальной чётности и 2 блока глобальной чётности). В итоге 1 капл, который имел 2 реплики и жил на 2 жёстких дисках, стал располагаться на 12 жёстких дисках. Это существенно усложнило процедуру чтения, да и восстановление после потери жёсткого диска тоже стало сложнее. Зато мы получили 25% экономии дискового пространства, что перевесило все минусы. Чтобы меньше нагружать сеть, запись данных совершается в обычные каплы с репликами. Конвертируем же мы их, только когда они полностью заполнятся и чтений станет поменьше — то есть когда данные «остынут».
О том, какие проблемы у нас возникли при реализации схемы, мы расскажем 15 октября на мероприятии в нашем московском офисе. Приходите, будет интересно!
