Как построить надёжную шину данных на Apache Kafka
Всем привет! Я Павел Агалецкий, ведущий инженер в Авито. Мы в компании используем микросервисную архитектуру с синхронным и асинхронным обменом событиями. В какой-то момент нам стало нужно обеспечивать более надёжную передачу сообщений. Стандартной Apache Kafka нам для этого было мало. Так мы пришли к идее, что пора строить собственную шину данных.

Зачем нужна шина данных
Микросервисы можно подключить к Apache Kafka напрямую. Это быстро и просто: нужно развернуть кластер, дать продюсерам (отправителям) и консьюмерам (получателям) адрес подключения и разрешить обмениваться событиями.

Прямое подключение микросервисов к Kafka
У такого подхода есть весомые минусы:
Сложно менять топологию системы. Если вы захотите отказаться от Kafka или разделить её на несколько кластеров, придётся обновить клиенты для всех пользователей, поменять адреса и настройки.
Под каждый язык разработки нужен свой клиент. В Авито мы пишем на Go, PHP, Python и других, получается зоопарк из разных систем только для обмена событиями.
С ростом системы прочитать сообщения из Kafka становится сложнее из-за растущей нагрузки.
Поэтому мы решили пойти другим путём и поставили между Kafka и микросервисами data bus, или шину данных. Она изолирует Kafka от сервисов и берет не себя получение и отправку сообщений получателям и реализует взаимодействие с Apache Kafka.

Шина отделяет микросервисы друг от друга и от Kafka
Микросервисы подключаются к шине данных через протокол websocket. Они публикуют события через один метод и подписываются на интересующие их события по названию топиков через другой. Протокол простой, поддерживается всеми языками разработки, которые мы используем в Авито.

Микросервисы подключаются к шине по протоколу websocket, а сама шина работает с Kafka напрямую
Шина напрямую взаимодействует с Kafka и скрывает все особенности работы с ней. Разработчикам микросервисов не нужно знать ничего об офсетах, хранении событий. Команда поддержки разработала три клиента для разных языков программирования, чтобы инженерам Авито не приходилось разбираться в Kafka.
Кроме того, шина предоставляет разработчикам универсальные метрики. Например, скорость записи и чтения, количество публикуемых событий, время обработки событий, размер бэклога. Все эти данные пользователи получают из нашего сервиса сразу после подключения, без специальных действий. Это помогает разработчикам в отладке микросервисов.
Сейчас шина данных — центральная система Авито. Средняя нагрузка на неё составляет порядка 3 миллионов запросов на запись и около 10 миллионов запросов на чтение в минуту. Её постоянно используют больше 500 сервисов компании, поэтому наша главная цель — обеспечить физическую надёжность и доступность системы.
Помимо физической доступности, нам важна логическая надёжность шины данных. Все данные в ней должны быть консистентными, чтобы любой сервис-консьюмер смог прочитать сообщения. При этом нельзя, чтобы сервисы-продюсеры случайно или целенаправленно записывали невалидные события, которые могут вызвать поломку системы или просто останутся непрочитанными.
Архитектура шины данных на основе Apache Kafka
Сначала у нас был один большой кластер Kafka, распределенный между несколькими дата-центрами Авито. На тот момент мы полагались на возможность самой Kafka восстанавливаться после отказа части серверов, которые входят в её кластер.

Одна большая Kafka была растянута между всеми дата-центрами Авито
Этот подход оказался для нас не очень удачным. Когда все серверы и дата-центры доступны, шина работала хорошо. Но при отключении дата-центра появлялась заметная просадка Latency.

Момент отключения одного дата-центра. Время записи в нашу систему достигает 30 секунд
Это происходило, потому что на момент отключения в Kafka было довольно много топиков, которые имели больше 15 тысяч партиций. При отключении дата-центра и потери связи с частью брокеров выполнялся ребаланс, выбирался новый мастер и в это время топики становились недоступны для записи. Это сильно влияло на работу всех наших пользователей.
Запись данных в шину для Авито важнее, чем чтение. Если микросервисы не могут записать данные в систему, получают ошибку или большой тайм-аут, то ломаются многие процессы. В итоге это становится заметно даже конечным пользователям Авито — на сайте или в приложении. Поэтому нам очень важно, чтобы запись всегда была быстрой.
Кроме того, мы хотели, чтобы работа с Kafka всегда была локальной. Для любого сервиса, который взаимодействует с шиной данных, все операции должны происходить внутри одного кластера. Поэтому мы переработали архитектуру и создали Kafka Federation.
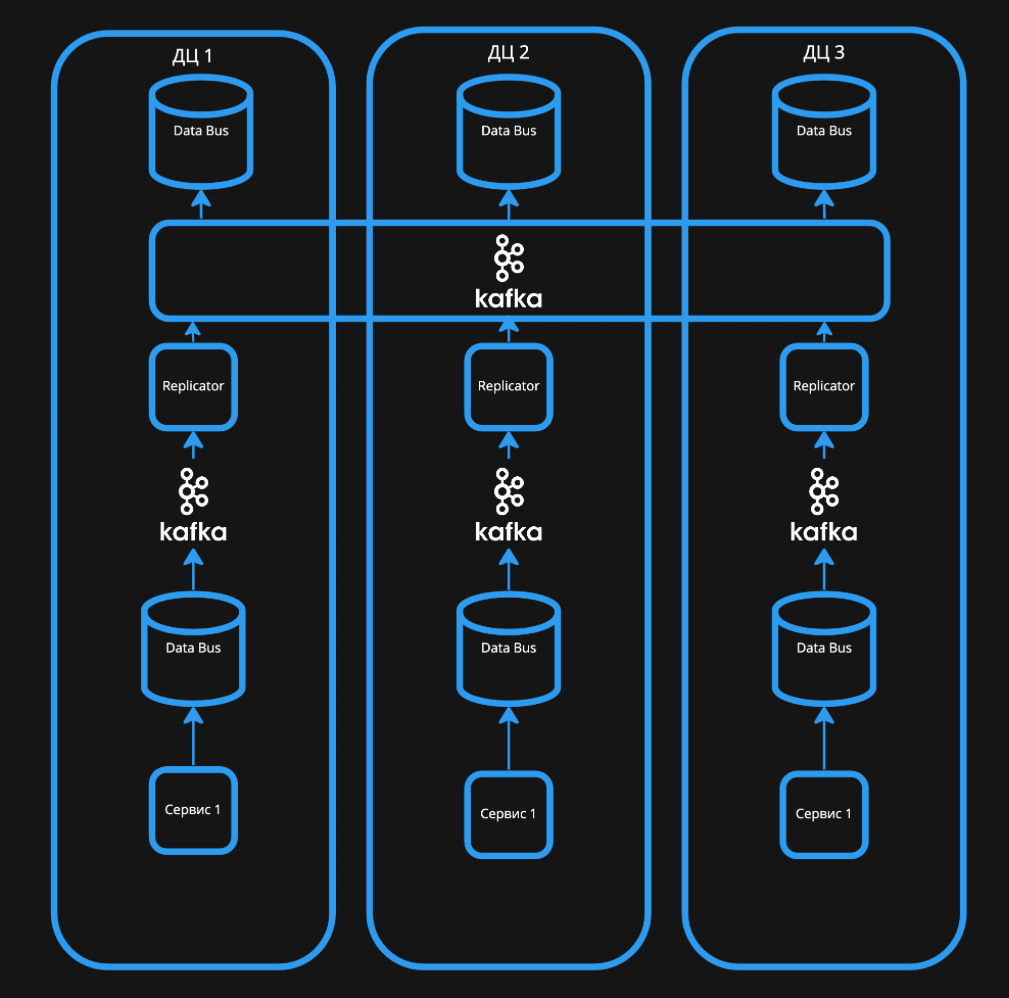
Общая схема архитектуры Kafka Federation
Мы отказались от одного большого кластера и заменили его несколькими маленькими. В каждом дата-центре разместили свою Kafka и экземпляр шины данных, а также экземпляры микросервисов, которые тоже должны быть устойчивыми к отказу.
Микросервисы-продюсеры записывают данные в шину, которая находится в одном с ними кластере. Затем шина передает событие во Write Kafka, доступную только для записи.
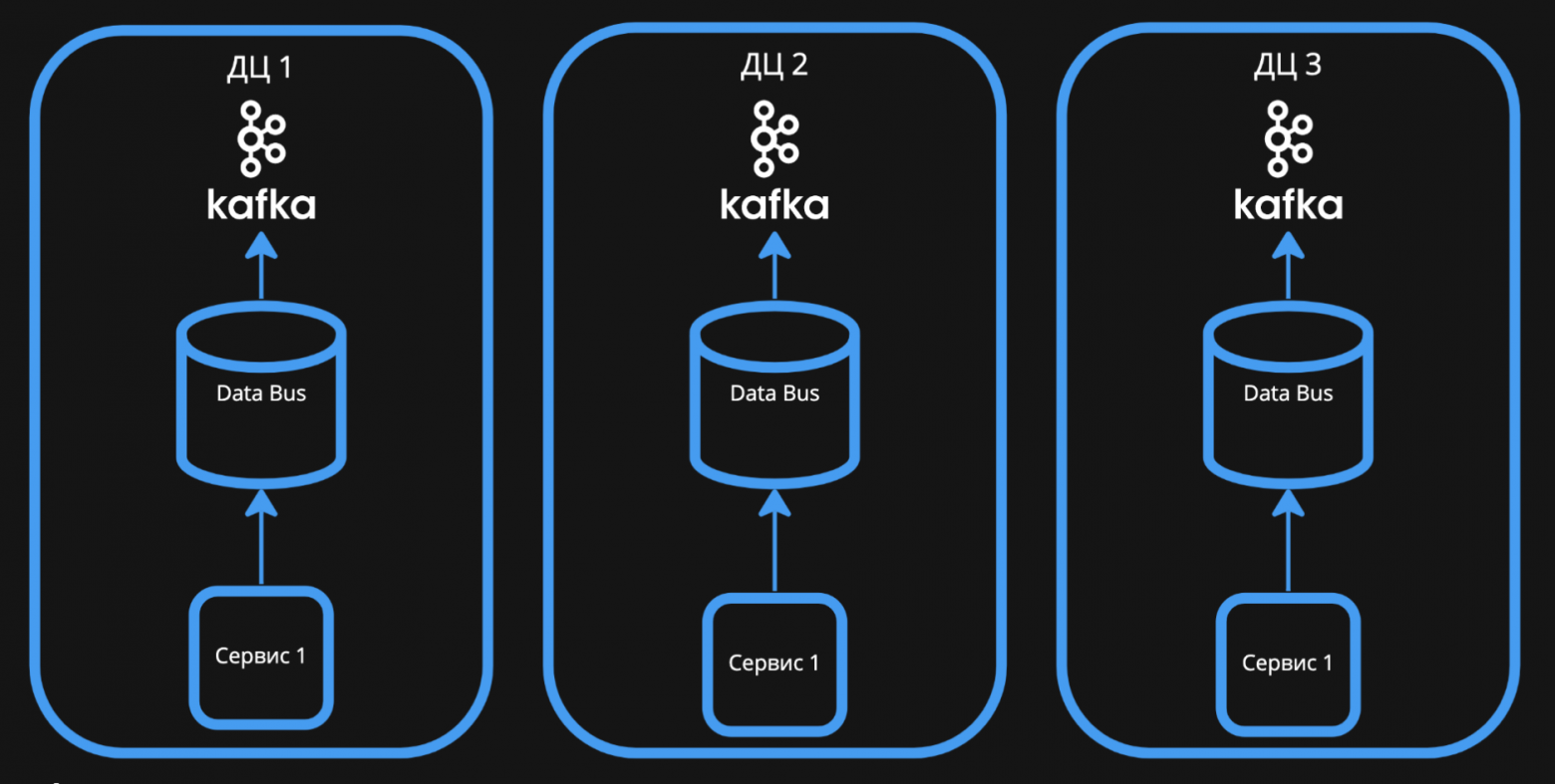
Первый шаг: микросервисы могут только записывать данные локально
Затем события из Write Kafka с помощью репликатора записываются в общую центральную Kafka. Её мы реализовали по старой схеме — распределили один кластер между всеми дата-центрами.

Второй шаг: репликатор копирует событие из локальных Kafka в центральную
Центральная Kafka доступна для записи и чтения. Она подвержена тем же проблемам: медленная запись, высокий Latency. Но для пользователей это становится незаметным, потому что для них запись выполняется сначала в локальную Write Kafka.
Задержку замечает только репликатор: при возникновении проблем с дата-центром, он какое-то время не может переложить данные в большую Kafka. Но это не влияет на качество работы всех систем Авито.
Чтение с центральной Kafka тоже осуществляется репликами шины данных, расположенными в каждом из дата-центров. А уже к ним, в свою очередь, подключаются микросервисы-консьюмеры.

Третий шаг: шина данных считывает сообщение из центральной Kafka и передает его консьюмерам
Так у нас получилась система, которая всегда доступна на запись вне зависимости от отказа того или иного дата-центра. Даже если один из них недоступен, микросервисы в остальных дата-центрах продолжают работу.
Как мы обеспечили логическую надежность шины данных
Микросервисы Авито постоянно эволюционируют: у них меняются данные и наборы событий, которые они публикуют и читают. Система должна уметь проверять сообщения и сохранять консистентность данных, чтобы ничего не сломалось из-за изменений. При этом все пользователи шины должны быть уверены, что они при любых условиях смогут прочитать события и получить валидные данные. Поэтому с точки зрения логической надёжности нам нужно было реализовать схемы сообщений и их валидацию.
Схема сообщения, или контракт — это описание того, что продюсер записывает, а консьюмер читает: какие у его события есть поля, типы данных. Разработчики прямо в коде микросервиса в специальной директории указывают события, которые они публикуют или читают.
Внутри Авито мы используем для описания синхронных и асинхронных схем обменов Brief — текстовый формат строгой типизации. Он недоступен вне компании, но по структуре описания похож на gRPC.
Схема события в формате Brief:
schema "service.update.commited” ServiceUpdateCommited ‘Коммит библиотеки для сервиса’
message ServiceUpdateCommited {
serviceName string ‘Название сервиса’
repository string ‘Адрес репозитория’
repositoryClone string ‘Адрес репозитория для клонирования’
owner string ‘Владелец сервиса’
update LibUpdateVersion ‘Библиотека для обновления’
commitData CommitData ‘Данные о коммите в репозиторий’
jiraTaskId *string ‘Уникальный идентификатор апдейта — название Jira тикета eg: ARCH-123’
}
message LibUpdateVersion {
libName string ‘Название библиотеки’
language string ‘Язык программирования’
desired string ‘Желаемое обновление’
}
message CommitData {
branchName string ‘Имя ветки, в которую был произведён коммит’
comment string ‘Комментарий к pr’
}
Для удобства разработчиков мы реализовали кодогенерацию на основе описания событий. В автоматически сгенерированном коде прописаны модели данных и клиенты, программисту достаточно указать схему события. В итоге получается работающий клиент, который можно сразу использовать для публикации или чтения сообщений.
Проверку валидности схемы выполняет шина данных. Когда один из сервисов пытается выкатиться в продакшен, система сравнивает его схемы событий со схемами его продюсеров и консьюмеров.

Схема валидации данных при развертывании микросервера
Шина проверяет ряд критериев: наличие обязательных полей, совпадение полей и типов данных для продюсера и консьюмера.
Также шина запрещает микросервисам выполнять не валидные действия. Например, мы не даем возможность продюсеру удалить событие, у которого есть консьюмер. То есть сначала нужно убрать ожидание этого сообщения во всех сервисах-получателях, а затем — в сервисе-продюсере. Другой пример — нельзя поменять тип поля со строки на число или обратно.
Итоги
Шина данных способна пережить отказ отдельных серверов или даже дата-центра. В продакшене система работает уже больше трех лет. За последние полтора года не было ни одного серьезного инцидента, связанного с недоступностью или отказом.
Шина гарантирует соблюдение контрактов между продюсерами и консьюмерами. В конечном итоге это обеспечивает надежность системы в длительной перспективе: пользователи уверены, что их сервисы всегда смогут прочитать события, которые публикуют другие сервисы.
Шина данных скрывает от пользователей все нюансы работы с Kafka. Нам это помогло незаметно заменить схему с одним экземпляром системы на Kafka Federation.
Сейчас мы думаем о дальнейших улучшения топологии. Одна из главных задач — уйти от единой точки отказа в виде общей для всех Apache Kafka. Если мы решим поменять топологию или даже заменить Apache Kafka на какое-то другое решение, то сможем сделать это незаметно для пользователей. Для них переход будет прозрачным, так как мы сохраняем наш API и не меняем точки входа, как бы ни менялась топология шины данных внутри.
Если решим поменять инструмент, нам не придется беспокоить пользователей — для них переход снова будет незаметным.
Предыдущая статья: Ультимативный гайд по HTTP. Часть 1. Структура запроса и ответа
