Как понять, что происходит на сервере

Александр Крижановский (NatSys Lab.)
По Сети уже давно бегает эта картинка, по крайней мере, я ее часто видел на Фейсбуке, и появилась идея рассказать про нее:

Я набрал в Google, оказалось, что человек, который ее создал, занимается оптимизацией производительности Linux«а, и у него есть замечательный блог. Там не только презентация, где эта картинка присутствует, там порядка трех презентаций, есть какая-то еще документация. Призываю сходить на этот блог, там хорошо рассказывается про все утилиты, которые перечислены на этой картинке. Мне не хотелось заниматься пересказом, поэтому я даю ссылку на презентацию — http://www.brendangregg.com/linuxperf.html.
С другой стороны, у него в презентации очень сжатый поток, там часовая презентация, о каждой из этих утилит понемногу — просто, что она делает, по сути, то же самое, что вы можете найти в man«е, либо просто набрав название каждой из этих утилит в Google. Мне захотелось сделать пару примеров о том, как можно найти узкое место и понять, что происходит.
Gregg дает методологии, начиная с рассмотрения того, как найти узкое место, пять вопросов «зачем» и т.д. Я ни разу не использовал какие-то методологии, просто смотрю, что-то делаю и хочу показать, что можно делать.

К сожалению, когда я готовил презентацию, у меня под рукой не было стенда с установленным софтом, бенчмарками, т.е. я не мог повторить весь сценарий. Я пытался собрать какие-то логи, которые у меня были, чаты, плюс воспроизводил какие-то сценарии у себя на ноутбуке, на виртуалках, поэтому если какие-то циферки вам покажутся подозрительными, они действительно подозрительные, и давайте смотреть на них немного сквозь пальцы. Нам будет больше важна идея о порядке цифр и о том, как их посмотреть, как их узнать.
Первый и основной пример — это то, что у нас было кастомное приложение, был модуль nginx, очень тяжелый модуль, но прикладную логику мы не будем рассматривать. Там была проблема в том, что людям хотелось очень много коннектов, но много коннектов не получалось, там остановилось все. Входной трафик был порядка 250 Мб в секунду, очень много параллельных соединений на таком достаточно скромном трафике. У нас полностью выжирались ресурсы, и ничего не происходило, т.е. новые коннекты, новые запросы просто отбрасывались.
Посмотрели. Первое, что мы делаем — это смотрим в netstat, делаем grep, делаем еще один grep. В netstat«е больше 20 тыс. соединений, и у нас там вот эти потоки. Понятно, что когда происходят проблемы с производительностью, система чувствует себя очень плохо. И когда мы запускаем netstat, он висит очень долго с grep«ом, поэтому, если есть возможность, лучше работать с proc«ом, она на самом деле всегда есть, и написать awk скрипт, который будет не пайпами работать, а сразу прочитает одну строку из proc, разберет ее и выдаст вам результат, как посчитает. Будет немного быстрее, комфортнее работать.
Второе, что делаем для понимания, что происходит — это просто посчитать входящие пакеты. Здесь я не пользовался какими-то сложными вещами, я просто беру счетчики пакетов, счетчики байтов. Собственно, как получены эти цифры — делаю sleep на 10 секунд, чтобы нивелировать какие-то флуктуации, и потом вычитаю одного из другого и делю на 10.

Далее запускаем Top обычный. В Top«е какая-то картинка, в целом, в ней ничего криминального нет, т.е. nginx не 100% процессора ест, average тоже в принципе нормальный. Подозрительно то, что системное время 33% и софтинтерраптное (si — software Interrupts) — 52%. Т.е. фактически у нас nginx мало что делает, но у нас много что делает ядро ОС. Также мы видим, что у нас есть две нитки ksoftirqd — это я воспроизводил у себя внутри виртуальной машины, и там всего два ядра было, т.е. два сетевых потока обработчика поднялись в Top.

Есть полезная кнопка в Top«е — это нужно нажать »1». Она вам покажет не суммарную статистику по процессорам, а для каждого процессора индивидуально. Здесь мы видим хорошую картинку, в целом, процессоры работают равномерно. Если один процессор выкручивается на 100%, а другие лежат, у нас явно проблема с распределением нагрузки. Если пакеты идут, в основном, на одно ядро, на одно прерывание, то остальные отдыхают. Здесь у нас распределение неплохое было.

Я люблю этим пользоваться. Это нехорошо, это крестьянский метод, но в целом GDB дает очень мощный интерфейс. Вы в цикле можете задать скрипт для GDB по всем вашим процессам nginx«а и посмотреть, что с ними делается. Здесь мы смотрим просто верхушку стека — первую и вторую функции, но, в принципе, вы можете сделать более интересные вещи, вы можете не только бэктрейсы собирать, вы можете какие-то переменные распечатывать и т.д. Это достаточно мощный механизм для того, чтобы в реал тайме заглянуть внутрь сервера, посмотреть, что с ним делается, его состояние, но при этом сильно не останавливать его. Этот скрипт, как бы, тормозит, понятное дело, что nginx«у становится еще хуже, но, в целом, оно работает, можно это делать в реал тайме.
Если запустить этот скрипт несколько раз, то, в целом, даже просто по нескольким процессам, нескольким потокам можно видеть, что какие-то потоки в большинстве своем проводят время в одной-двух функциях — этот как раз наш bottle-neck будет. Если у вас будет всего один поток или процесс, который вас интересует, просто несколько раз запустите и сможете понять, что это вот такое простое сэмплирование.
Еще не сказал, что в данном случае мы видим здесь просто epoll. Epoll — это не очень интересно, гораздо интересней, если бы мы увидели user space код. В том случае, с которого мы начинали, был user space код, там были регулярные выражения, которые мы обрабатывали, там был bottle-neck.
Следующее, что мы делаем, поскольку мы видим, что проблема не в nginx, а проблема в системе, мы идем в систему. Смотрим, как чувствует себя ОС.Т. е. на данный момент мы уже отсекли, поделили зону поиска и уже ищем в ОС.

Есть удобная утилита perf top — это трейсер ядра, он может показать все ваши процессы в системе, конкретный процессор, конкретный процесс, его call_trace. Вот, здесь мы видим, что основное время у нас тратится в nf_conntrack. В целом, не очень понятно, т.е. видно, что последние две строчки — это nginx. Мы понимаем, что там какой-то прикладной код, он для нас не интересен, потому что мы знаем, что nginx уже не наш bottle-neck. То, что мы ищем, мы ищем внутри ОС, и нас интересуют первые три вызова.
Первый. Для того чтобы найти что такое nf_ct_tuple_equal опять же удобно иметь исходники ядра под рукой. Я не говорю о том, что всем нужно разбираться внутри него, но просто сделав grep внутри ядра — то, что я сделал — вы можете достаточно легко понять, либо можете просто набрав в Google вызов, который вы видите в perf«e. Он может быть сначала непонятным, но достаточно быстро можно найти, что это за подсистемы. Не нужно знать точно, что делает этот системный вызов, эта функция ядра, просто понимать, что это за подсистема, в какой подсистеме у нас тормозит ядро.
Просто делаем grep. Я сделал общий рекурсивный grep внутри директорий, нашел Kconfig, где он лежит, и там есть человеческое описание — то, что вам выводится в конфигурации ядра, что делает эта подсистема. Дальше мы идем в Google, смотрим, что такое conntrack«и видим достаточно много сообщений о том, что conntrack«и тормозят систему, на входной трафик они не имеют смысла, в частности, для htp-сервера, мы их можем отключить.
Для того чтобы убедиться в том, что все сошлось, все наши данные, мы распечатываем количество соединений, которое сейчас пасут conntrack«и, и видим там примерно то же самое число, что и число установленных соединений. Сonntrack«и в Linux«е — это подсистема firewall«а, который отслеживает наши соединения, т.е. яркий пример FTP, когда у нас идет одно соединение, по нему отдается порт и firewall должен пасти и первое, и второе соединение, связать их. И у этой подсистемы есть достаточно медленная функция, которая начинает матчить все соединения, она просто работает вхолостую, она ничего не делает, поэтому мы ее можем отключить.
С первым bottle-neck«ом разобрались, давайте посмотрим на следующий.

Intel_idle. Честно говоря, в первый раз я подумал, что это от Intel«овской карты. Опять же делаем grep внутри ядра. Уже в Kconfig«e ничего нет, потому что это все всегда включено, но зато разработчики Intel позаботились, чтобы сделать хороший комментарий внутри исходника, и мы видим, что время, которое наш процессор тратит впустую, он тратит его внутри этого потока. Этот поток хороший, это значит, что у нас простаивает процессор какое-то время, и мы с ним ничего не делаем.
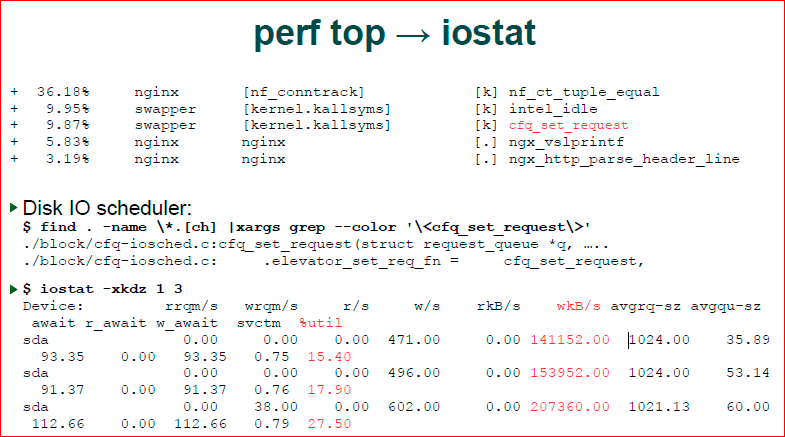
Следующая точка. Вновь делаем grep, мы видим, что у нас ./block/cfq-io планировщик, и мы понимаем, что мы имеем дело с планировщиком ввода-вывода. Значит, наверное, nginx что-то вводит-выводит. При этом block IO — это значит, что у нас файловая система, а не сетевая часть, т.е. сетевая часть находится в net.
Если так происходит, мы хотим посмотреть статистику ввода-вывода, iostat помогает нам это сделать. Мы видим, что у нас идет массивная запись, и что диск как-то там используется на 15–20%. Не очень много, но там тратится время.
Дальше, когда мы посмотрели perf top, мы на самом деле видели, что это ОС проводит в вводе-выводе. Это не значит, что nginx это делает, это может быть kswapd что-то выводит, это может быть какой-то демон Updatedb поднялся у нас по cron«у, который запускает какое-то обновление баз данных, может быть у нас там package менеджер обновляется и т.д. По-хорошему, когда мы видим, что у нас в системе происходит нагрузка на ввод-вывод, нам все-таки хорошо бы посмотреть, кто этим занимается.
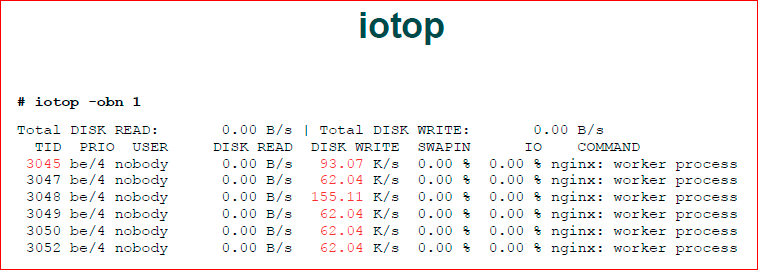
И у нас есть iotop — аналог обычного top«a, но для ввода-вывода. Он нам, как раз, показывает, кто нам генерирует такой ввод-вывод. Видим, что nginx.
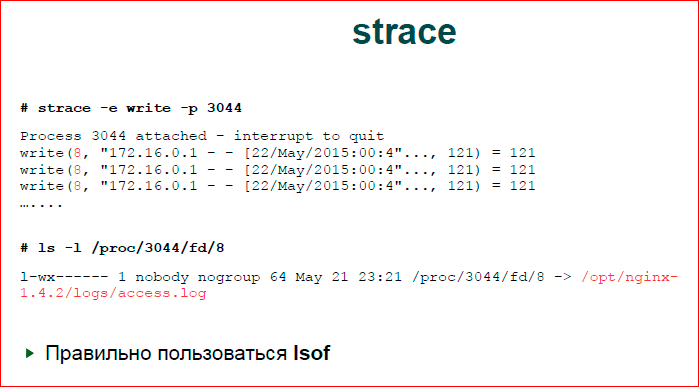
Следующее, что мы делаем — смотрим, что же nginx делает с вводом-выводом. Есть прикладная утилита strace, которая находится на стыке между ОС и прикладным процессом. Она выводит хуки на все системные вызовы. Я догадался, что у нас будет write и поставил write. Я до этого специально ничего не делал, просто получилось. На самом деле, у нас системных вызовов не так много, т.е. здесь правильно было — »-e write, write w» и, наверное, все. Т.е. если мы знаем, что файл ввод-вывод тормозит, то нас будет интересовать достаточно небольшое количество системных вызовов.
Второй вариант. Здесь мне подфартило, у меня чистый вывод. У меня действительно было там очень много таких write«ов. В реальности у вас может быть очень плохая ситуация, когда вы увидите просто мешанину системных вызовов, там будет epoll, обязательно там будет какой-то read из сокета, там будет write иногда, и, в целом, тяжело понять, что это такое.
Можно так же запустить strace. Мы strace откладываем в файл, потом этот файл обрабатываем скриптом, который нам строит статистику по системным вызовам. Понимаем, какой системный вызов у нас в Top«е, и, соответственно, в Top«е системных вызовов ищем системный вызов записей, и это будет write. По write мы видим, что у нас первым аргументом write идет файловый дескриптор 8.
Правильно пользоваться Isof, но я им так и не научился пользоваться, я пользуюсь docfs. Я иду в директорию fd, смотрю, что находится в 8-ом дескрипторе. Это access.log — не удивительно.

Последний сценарий — это, что делать, если у нас Top молчит, если он нам показывает хорошие цифры, что у нас, в целом, в системе все хорошо, но мы знаем, что у нас нехорошо.
Такой пример. Я просто взял свой бенчмарк — это бенчмарк, который нагружает очередь синхронизации в мьютексах, и посмотрел, что говорит Top. Top говорит, что у нас очень большой idle, и если мы не выводим per-CPU статистику, то у нас будет порядка 130% использования процессора при том, что у нас должно быть 400. Т.е. видим, что статистика вся хороша, но бенчмарк по своей идеологии должен полностью утилизировать все ресурсы, он этого не делает.
Давайте посмотрим, что происходит.

Здесь мы делаем снова strace, но мы зовем уже с -p и –с; -с позволяет нам собрать статистику по системным вызовам.
Почему мы этого не сделали для nginx, почему я сказал, что нужно брать какой-то скрипт и парсить вывод из strace? Дело в том, что strace генерирует эту статистику по завершении программы, которую он пасет, которую он трассирует, и если у вас работает nginx, а вы не хотите его прерывать, то вы не получите этой статистики, статистику надо собирать самому.
Здесь strace нам показывает трассу, какие системные вызовы у нас чаще зовутся, время внутри этих системных вызовов, и мы видим, что у нас futex. Если мы наберем man futex, то увидим, что это механизм ОC, который используется для синхронизации user space, а это мьютаксы наши. И pathRead lock«и, условные переменные используют как раз единый этот вызов futex — это значит, что у нас проблема с pathRead синхронизацией.
Вообще говоря, если вы видите такую картину, что у вас ввод-вывод хороший, процессоры хорошие, у вас, вообще, все хорошо, и с памятью хорошо, но количества RPS«ов вы не достигаете, как правило, это значит lock contention, что и, как раз, эта цифра 130% — она не случайна. Т.е. во время lock contention, когда у вас четыре процессора дерутся за одну блокировку, у вас в каждый момент времени только один процессор может что-то делать. Т.е., по сути, вы из четырех процессоров получаете один. И мы получаем еще дополнительные 30% только за счет дополнительных расходов на планировщик и еще на что-то, что дает нам чуть больше 100%, но эта такая природа у contention.
Контакты
» ak@natsys-lab.com
» Блог компании NatSys Lab.
Этот доклад — расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем HighLoad++ Junior.Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля «Российские интернет-технологии», в который входит восемь конференций, включая HighLoad++ Junior. Александра обязательно вновь позовём в докладчики
