Как отобразить динамическую выгрузку из БД на страницах Atlassian Confluence?
На рынке существует огромное количество wiki-движков корпоративных баз знаний. Если вы используете Atlassian Confluence, вам наверняка будет интересно узнать, как расширить стандартные wiki-возможности системы. И использовать Confluence, в том числе, в виде витрины для динамического отображения любой полезной информации, например:
- метрик вашего продукта,
- Agile-метрик по работе команд,
- графика роста численности вашей команды,
- списка ближайших дней рождений,
- и т. д.
Решаемая задача
Для наглядности, я буду рассматривать задачу учёта сотрудников вашей компании, на примере известных учёных прошлого. То есть, в СУБД есть таблица, каждая запись которой — отдельный сотрудник, каждое поле этой записи — характеристика сотрудника (Ф.И. О., дата рождения, телефон…). Для простоты, в качестве СУБД будет использоваться СУБД Atlassian JIRA, в которой хранится информация о проектах, задачах и т. д.
Способы отображения результатов
И вот, мы подошли к самому интересному — как динамическая информация будет выглядеть на страницах Confluence. Ниже вы сможете сравнить несколько способов отображения информации по сотрудникам.0. Фильтр JIRA
Перед тем как выводить информацию на страницу в Confluence, давайте посмотрим, как она будет выглядеть в JIRA.
Для этого необходимо написать несложный запрос, выбрать интересующие нас столбцы для отображения:
И, на будущее, сохраним запрос как фильтр:

Не секрет, что у продуктов Atlassian существует тесная интеграция между собой. Например, на странице Confluence за пару кликов можно отобразить список задач в определённом проекте, или по заданному фильтру.
Сначала нужно добавить макрос:
Затем написать запрос с проектом JIRA и отделами сотрудников:
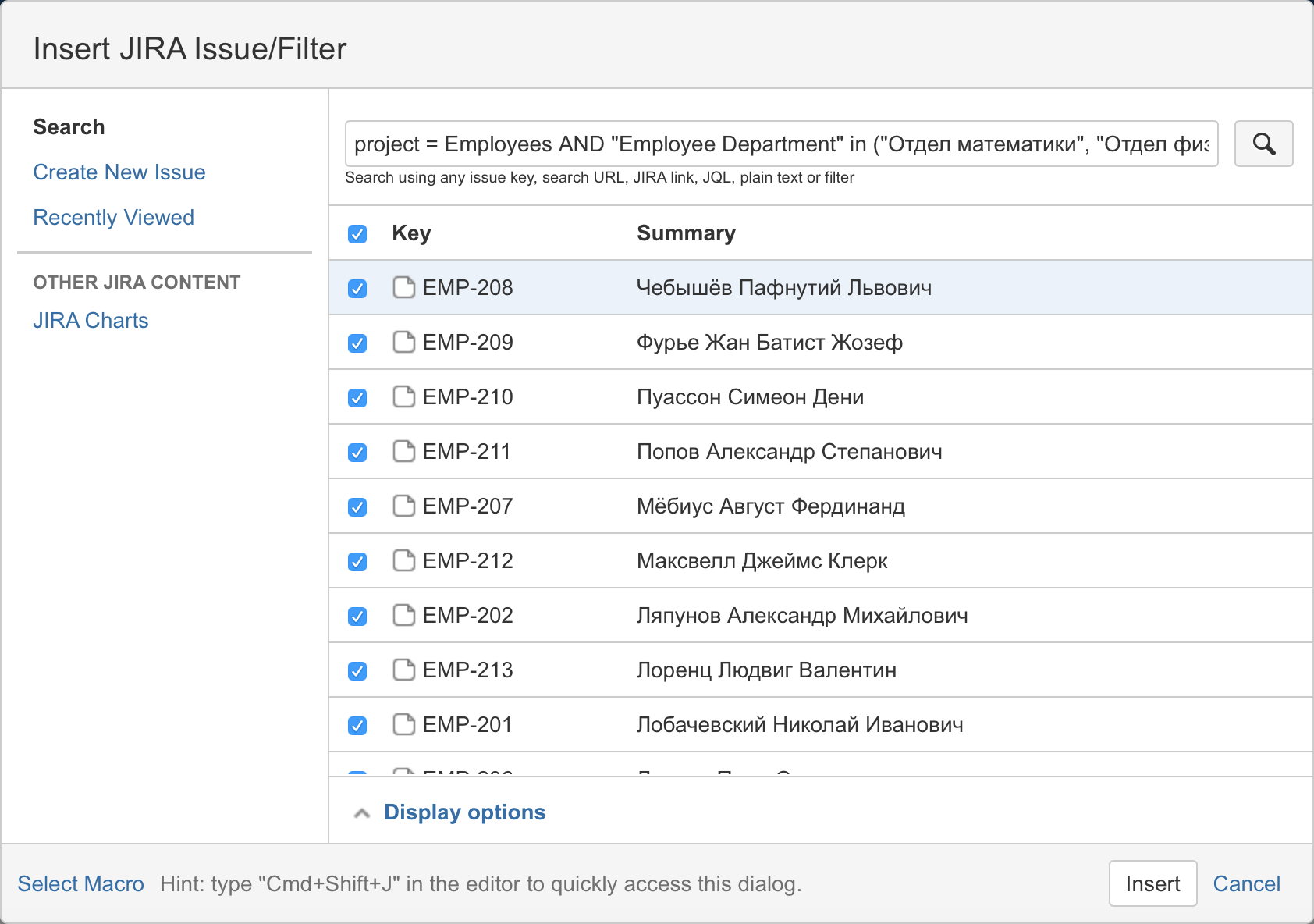
После чего выбрать столбцы для отображения в итоговой таблице:

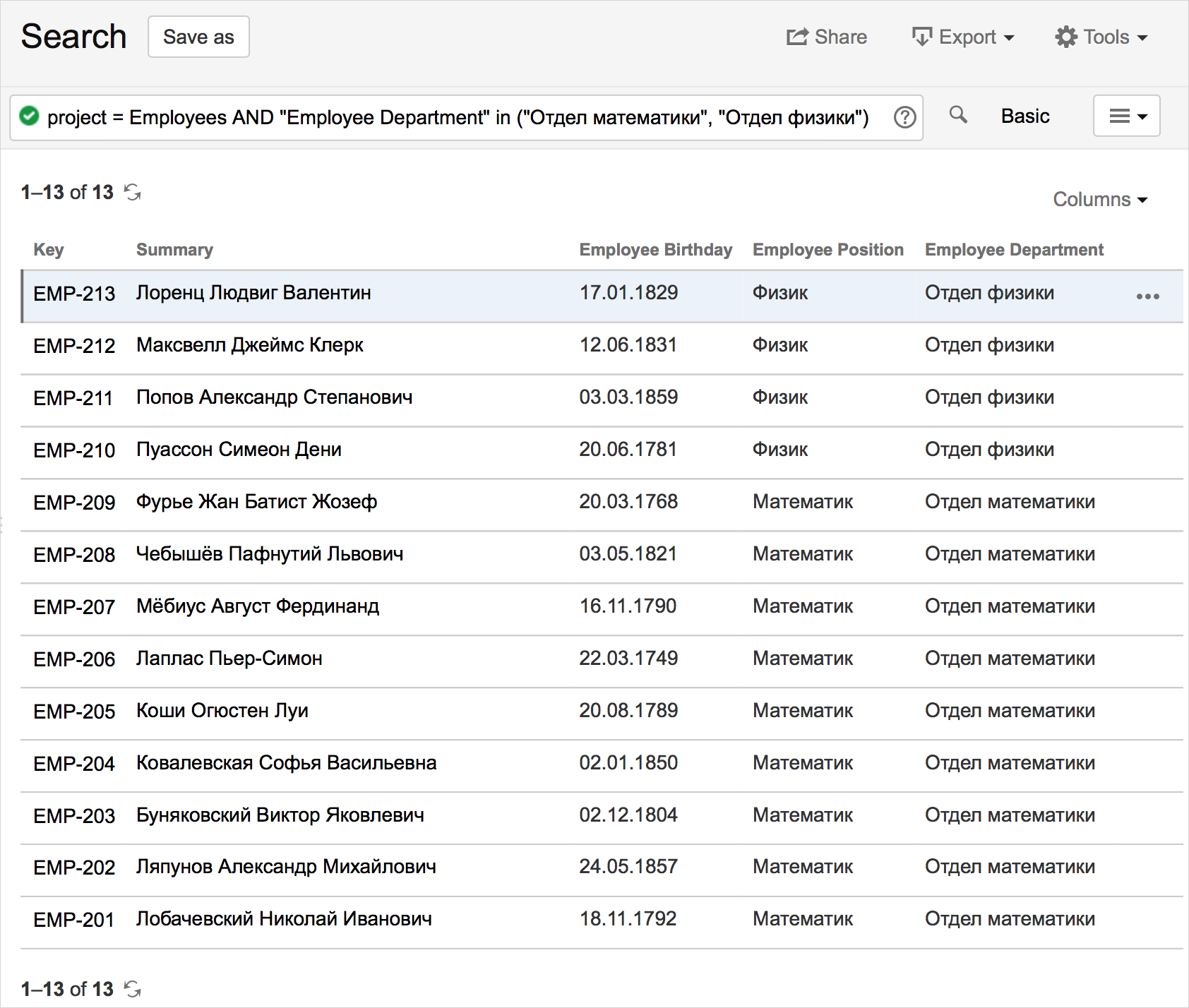
И получается вот такой результат:

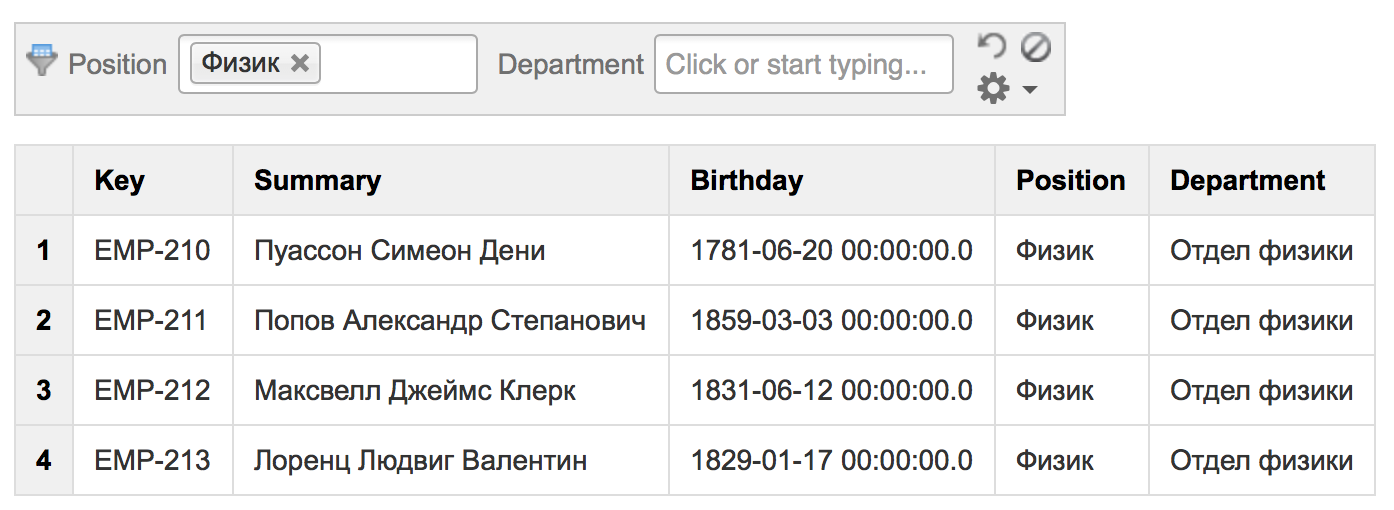
Получившаяся таблица динамически обновляется при перезагрузке страницы Confluence, или при нажатии на «Refresh».
Кроме того, таблицу можно сортировать при нажатии на названия столбцов. Названия столбцов совпадают с названиями полей, их переименовывать невозможно. Также доступен постраничный просмотр (paging), на случай, если записей слишком много (в нашем примере, размер страницы — 20 записей).
2. Гаджет JIRAМногие пользователи JIRA используют портлеты/гаджеты (gadgets) для отображения важной информации по проекту на рабочих столах (dashboards):

Вот так выглядит список сотрудников на гаджете JIRA:

Возможно, не все знают, что гаджеты JIRA можно отображать ещё на страницах Confluence. Отличие от предыдущего случая лишь в том, что HTML-код формируется на стороне JIRA и отображается в Confluence в неизменном виде.
3. Прямой SQL-запросПосле экспериментов с частными случаями механизмов отображения JIRA, перейдём к более общему случаю произвольной СУБД и запросов к ней.
Для наглядности сравнения, я написал SQL запрос к той же СУБД JIRA:

В отличие от предыдущих трёх случаев, запускаться он будет через обычный JDBC, без механизмов интеграции между Confluence и JIRA.
Вот результат выполнения запроса в среде разработки:

Для запуска этого запроса и просмотра результатов на странице Confluence, существует макрос SQL for Confluence от Bob Swift:
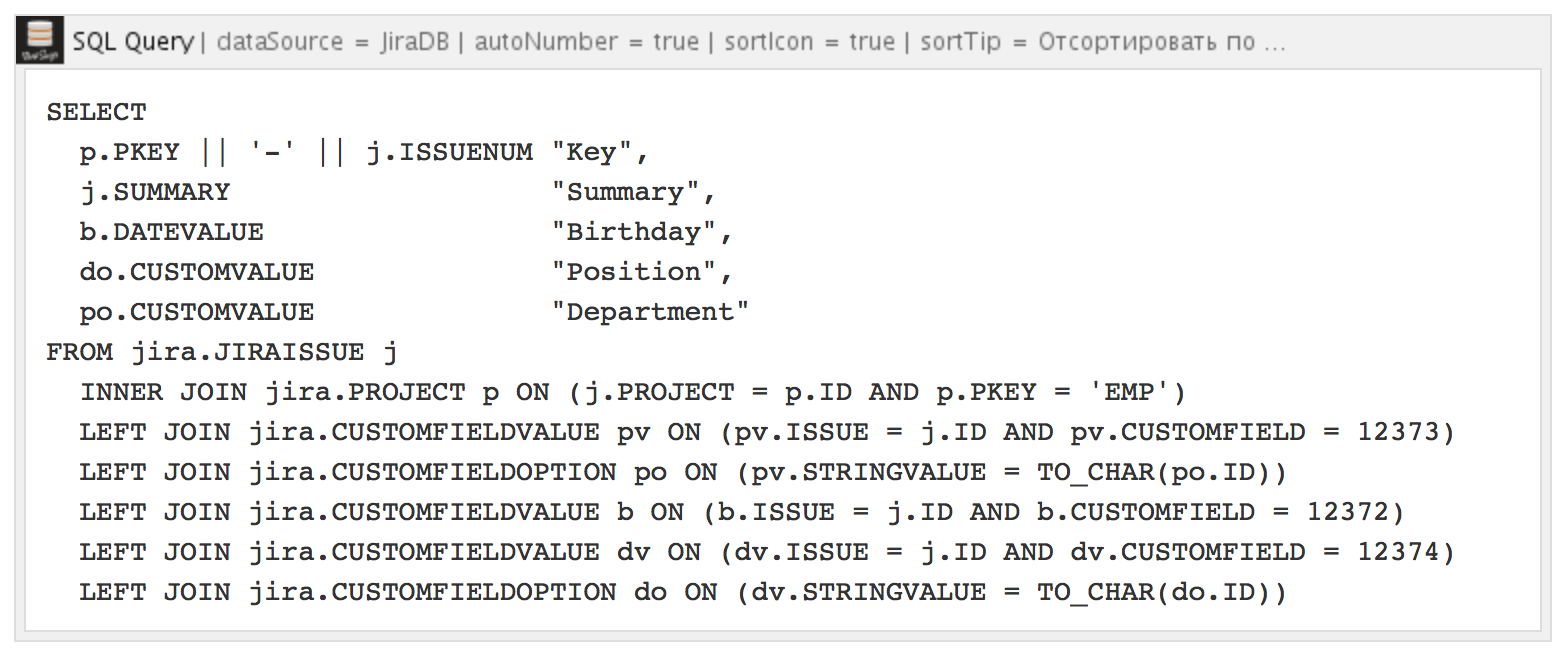
Вот как выглядит результат выполнения запроса:
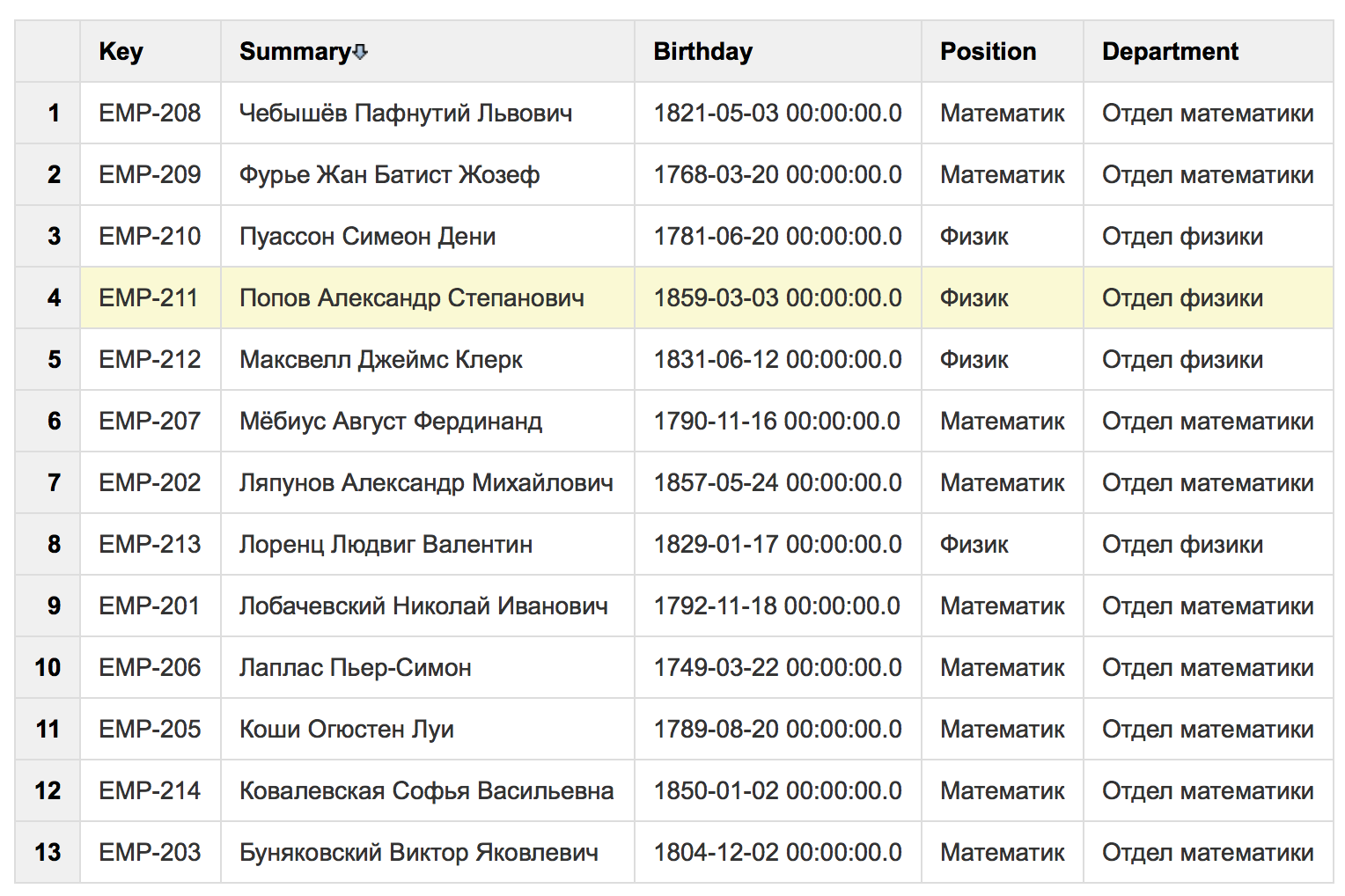
В отличие от предыдущих механизмов, в SQL for Confluence нет возможности постраничного вывода результатов. Зато в настройках макроса можно выключить режим автонумерации строк выполненного запроса. Кроме того, возможно высчитывать сумму, среднее, максимальное значение по столбцам (в нашем примере неактуально).
С точки зрения безопасности, макрос даёт выполнить произвольный SQL-запрос на СУБД. Чтобы предотвратить утечку или порчу данных, нужно, во-первых, настроить права технического пользователя, из-под которого запускаются SQL-запросы. Как минимум, запретить запись. Во-вторых, ограничить права в Confluence на редактирование страницы с запросом.
Для добавления возможности фильтровать результаты запросы, макрос SQL for Confluence хорошо работает в паре с другим макросом — Table Filter for Confluence от компании StiltSoft:
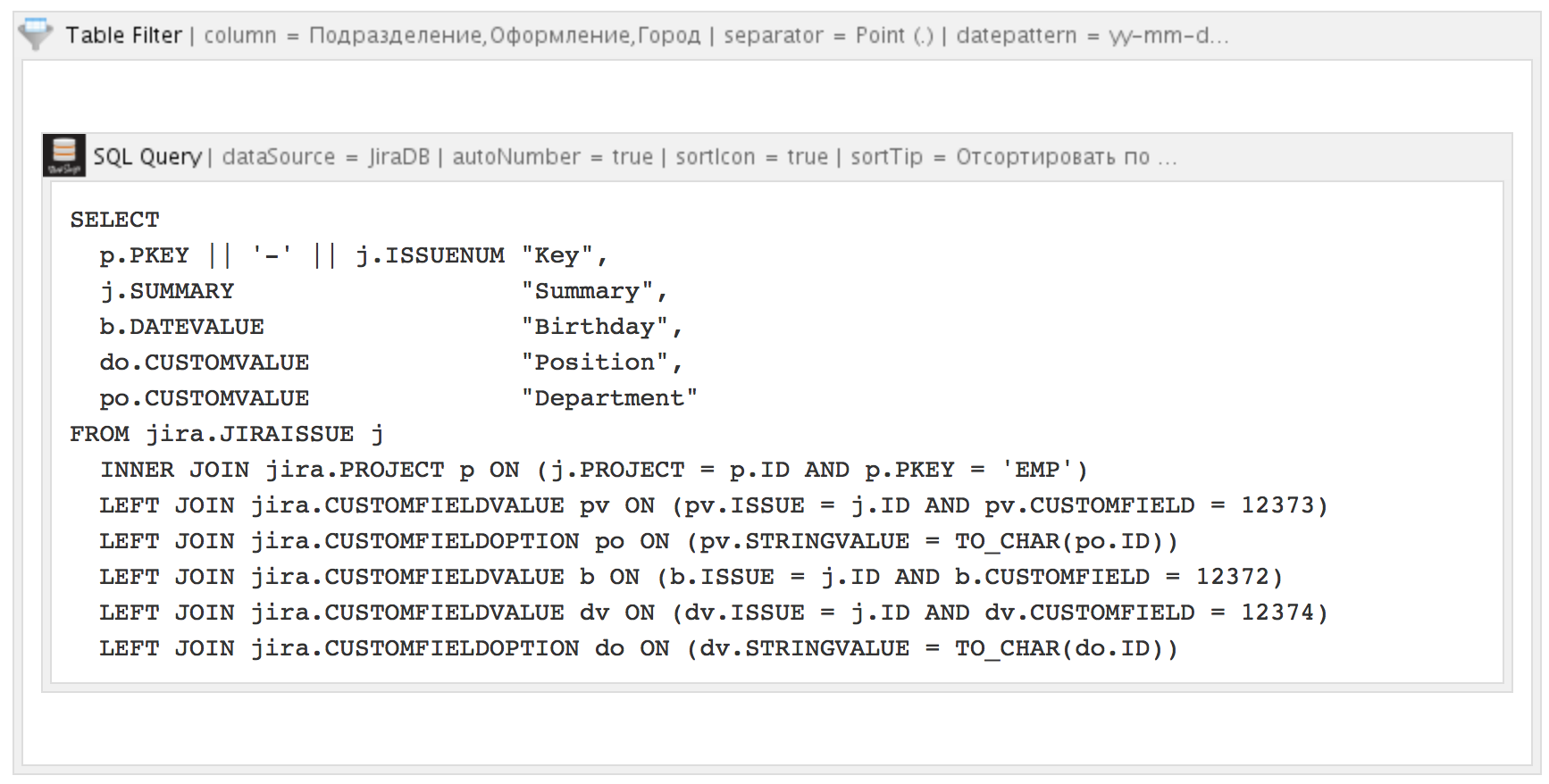
В итоге, к таблице сверху прикрепляется набор полей, изменяя значения которых, можно производить фильтрацию:
И заключительный, самый богатый и сложный макрос под названием eazyBI предлагает одноимённая компания. Этот продукт заточен под решение более сложных задач по направлению BI, заслуживает отдельной статьи. Но eazyBI вполне подойдёт для нашей задачи.
Для начала, необходимо настроить источник данных и указать SQL-запрос для выбора данных:
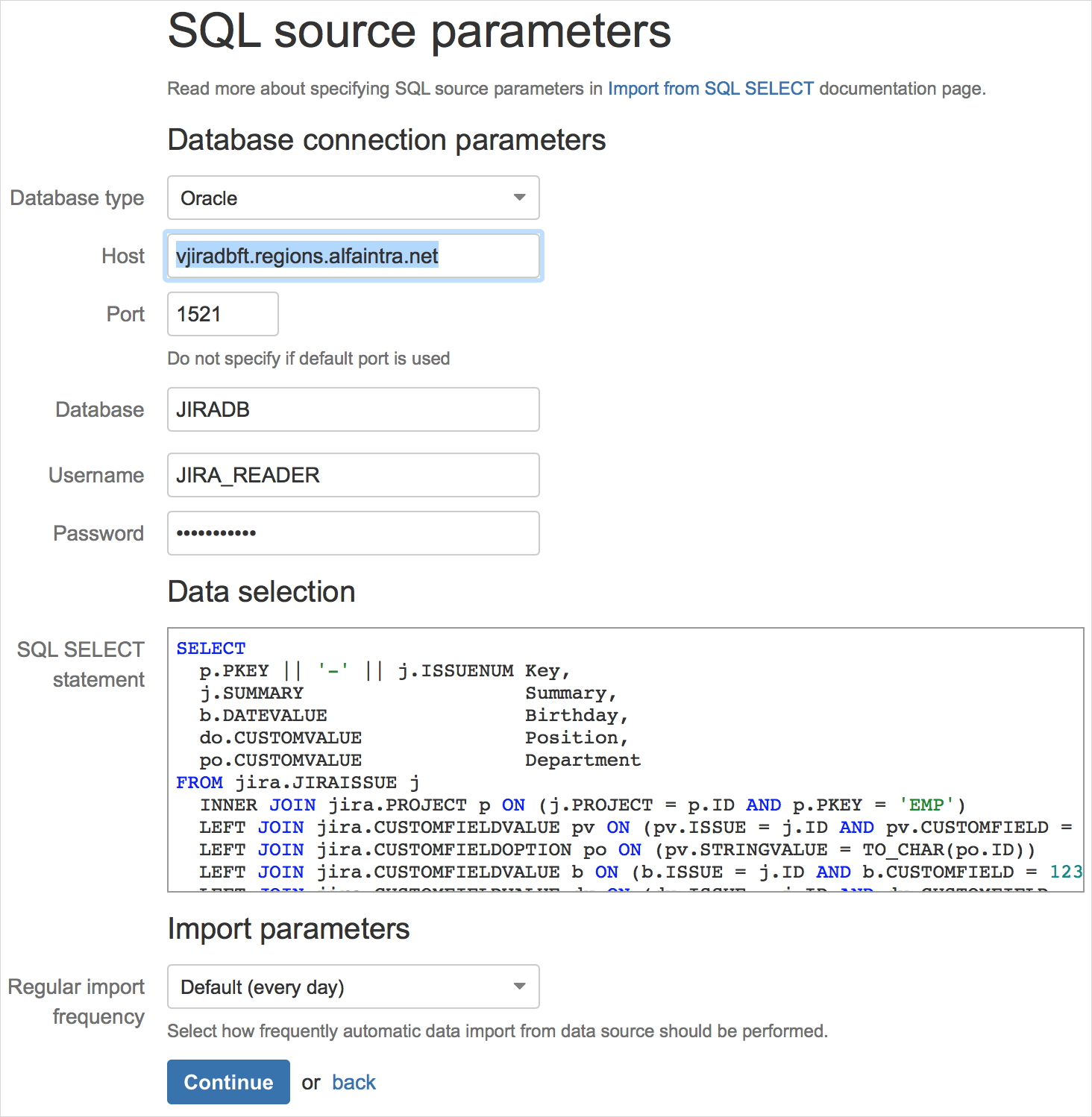
Движок eazyBI выполнит запрос, выгрузит названия столбцов и первые строки результата:
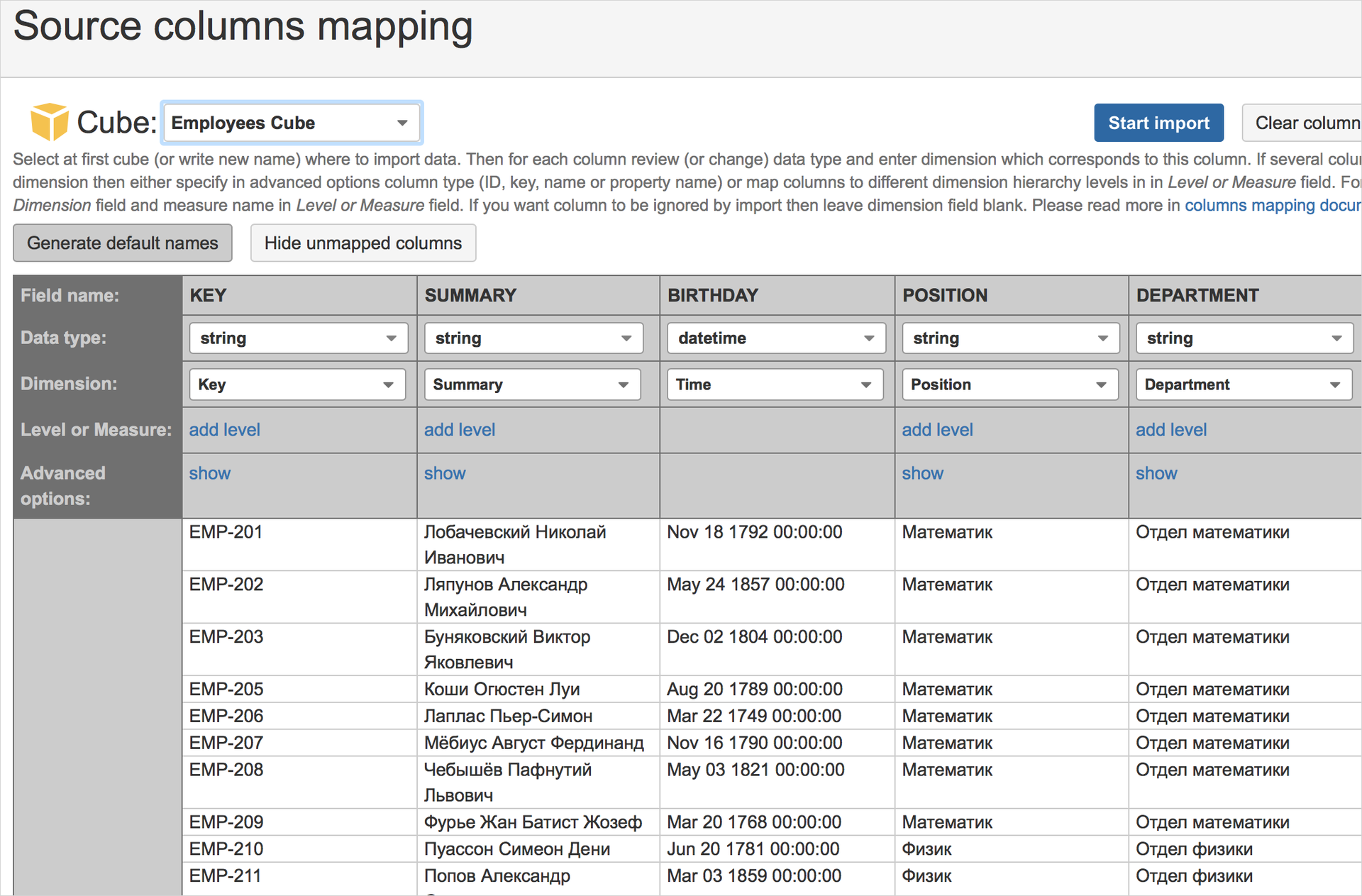
Затем запустит импорт данных, создаст из них куб. Комбинируя размерности куба в нужном порядке, получается вот такая выгрузка:
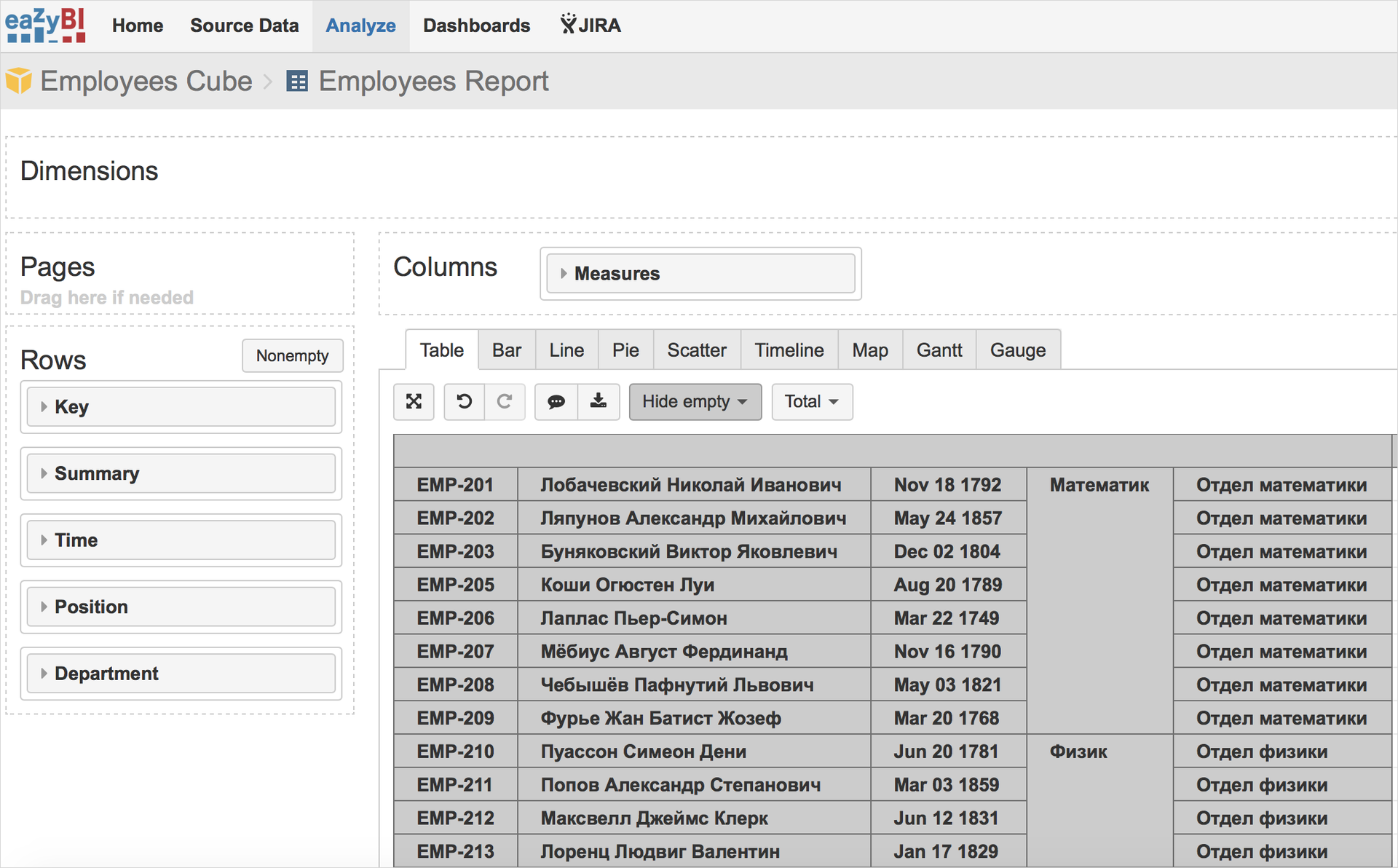
Которая через соответствующий макрос добавляется на страницу Confluence.
В eazyBI присутствуют все функции, как в описанных выше механизмах. Кроме того, есть автообновление, экспорт в Excel, удобная группировка по датам и многое, многое другое.
Из недостатков, хочу выделить особенность работы BI-движков — перед отображением, результат запроса выгружается в отдельную СУБД, уже из которой идёт отображение в Confluence. Запуск таких запросов производится не в реальном времени, а с периодичностью (от 5 минут до 1 дня). Поэтому, eazyBI лучше использовать на больших массивах данных, где критична скорость выполнения запроса (как следствие — нагрузка на СУБД), и не очень критична свежесть данных.
Итоги
Вот что получается в сухом остатке:
| viewing | sorting | paging | column renaming | filtering | numbering | real time execution | |
| 0. Фильтр JIRA | нет | да | да | нет | нет | нет | да |
| 1. Макрос JIRA | да | да | да | нет | нет | нет | да |
| 2. Гаджет JIRA | да | да | да | нет | нет | нет | да |
| 3. SQL-запрос | да | да | нет | да | да | да | да |
| 4. eazyBI | да | да | да | да | да | да | нет |
Таким образом, мне бы хотелось вам посоветовать — если данные хранятся в JIRA, пользуйтесь стандартными механизмами, пока они удовлетворяют вашим запросам. Если не удовлетворяю, или данные хранятся не в СУБД JIRA, то экспериментируйте с SQL + Table Filter. Если же данных очень много, достать их ресурсоёмко и актуальность не так важна, смело используйте eazyBI.
P.S. Вот прошлогодняя статья из песочницы, в которой более подробно описаны движки визуализации данных в Confluence. В том числе, упоминается Table Filter.
