Как объяснять не-ИТ менеджерам принципы построения отказоустойчивой ИТ-инфраструктуры
Примерно год назад передо мной была поставлена достаточно серьезная задача: уложить в 2-часовую лекцию для менеджеров рассказ и об Agile и о DevOps.
Так началось мое возвращение из софтскиловой плоскости тренингов по Agile в сторону ИТ. И если верить организаторам, через эту лекцию прошло более 1000 менеджеров продуктов, из которых слово «балансер»(Load Balancer) слышали впервые на моем занятии примерно 48/50 человек.
У меня даже появилось шуточное божество «великий балансер, повелитель обновлений без даунтайма, дешевых в реализации A/B тестов без программирования, и в целом спокойного сна менеджера ночью».
Конечно, коллеги из IT могут посмеятся над этим упрощением, и даже возмутиться тем, что мир не сошелся на слове «балансер» и сколько можно уделять ему столько внимания.
Но когда у меня в зале 48 человек из 50 не слышали про явление балансировки нагрузок, это немного грустно. Да и разработчики бэкендов некоторых мобильных приложений, даже крупные банки могут грешить отсутствием подобных схем.
Мой любимый желтый банк, например, обновляет сервера бэкендов мобильного приложения в 5 утра по Москве примерно 2 раза в неделю. Почему я это знаю? Потому что в Новосибирске, куда я возвращалась на год пожить в 2016ом, в это время уже 9 утра, и мне выскакивала ошибка 000. Страшно представить, что для Дальнего Востока это уже обед.
Возможно, у нас есть шанс сделать этот мир немного лучше, если об отказоустойчивости будут задумываться менеджеры на момент бюджетирования серверных мощностей, и там будет не 1 сервер на все, а действительно соразмерная степени риска и нагруженности системы конфигурация.
Зачем?
Самый первый вопрос, который возникает при постановке любой задачи, конечно же: зачем?
Есть такой фреймворк:
Зачем оно нам? | Зачем оно им?
Зачем оно нам?
Если представить, что «мы» — это множество людей из ИТ, не только разработчиков и смежных специалистов, но и технологических консультантов, HR и Agile-коучей, на ежедневной основе контактирующих с менеджерами, не имеющими ИТ-бэкграунда.
Для себя на первый вопрос я ответила достаточно просто: повышение технической грамотности менеджеров сильно снижает вероятность возникновения неадекватных задач и повышает счастье разработчиков.
Зачем оно им?
Зачем знания об этом менеджерам, которые действительно далеки от ИТ?
Мы все люди, и все хотим спать спокойно. Менеджеры часто берут на себя ответственность за то, на что не в состоянии толком повлиять. Уровень стресса в таком случае сравним с пассажирами самолета, у которых наблюдается аэрофобия.
И это наверное единственная аргументация, которая не будет похожа на снобизм «ну как можно не знать таких очевидных вещей» или «любой человек должен ночью с завязанными глазами упрощать неопределенный интеграл». По моему опыту, если человек «по локоть в консоли», то даже неосознанно, но он часто может оперировать такими штампами.
Как можно объяснить сложное простыми картинками
Иллюстрации ниже не претендуют на абсолютную истину и не имеют самостоятельной ценности, тем более не стоит эти упрощения использовать как руководство к действию при построении отказоустойчивых архитектур, поскольку я намерено не стала там прорисовывать различные тонкие моменты, такие как кеширование. Это всего-лишь упрощенная модель.
В обучении взрослых людей, а усвоение новой информации является частью обучения, важно понимать, что любая информация должна быть повторена минимум трижды, чтобы повысить вероятность того, что она действительно усвоится.
Например, вот такая схема будет с большой вероятностью ассоциироваться с мемом «не пытайтесь покинуть Омск» и только утвердит человека в мысли, что «все сложно, а еще они хотят много серверов».
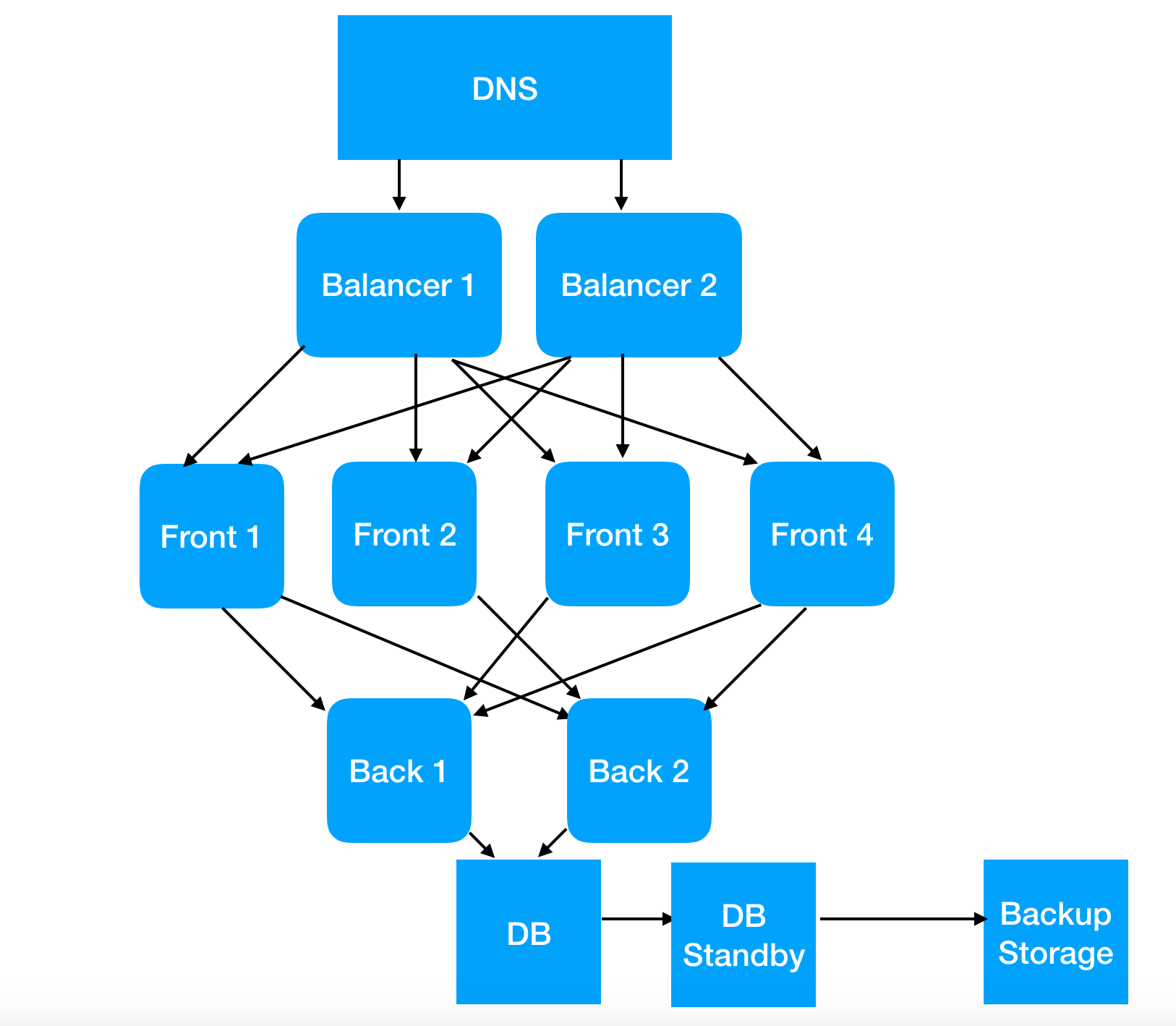
А вот эта схема, показанная сначала, может создать у человека ассоциацию слова «балансер» с явлением балансировки нагрузки на сервера. Без каких-либо гарантий правильности понимания этого процесса, но с уверенным знанием, что он существует, и зачем он нужен.
Давайте в этом месте спародируем немного пункты Agile-манифеста и скажем «то есть не умаляя ценности того, что справа, мы больше ценим то, что слева».
Например, потому что эта схема позволяет понять, как настроить систему A/B тестирования без написания тонн исходного кода, и как обновлять сервера, не выпивая для храбрости (менеджеру, не админу) перед этим.
Что дальше?
А само это понимание открывает менеджеру путь в прекрасный мир CI/CD, поскольку если мы уже знаем минимальные трудозатраты для того, чтобы сделать инфраструктуру частично отказоустойчивой, мы начинаем меньше бояться частых релизов. А это кардинально меняет подход к политикам обновления в целом.
Ну и не мне вам рассказывать, что более мелкие правки, выложенные на 1/10 мощностей (даже если это 1 сервер из 3, но ему отдается только 10% трафика), это сильное снижение накала страстей при обновлении. Даже если сервера полностью перестанут обрабатывать каждый 10ый запрос.
У нас однажды было 20% падение при RPS 600, и оно достаточно быстро было устранено, кажется даже без участия людей. Именно тогда я как технический PM, отвечавший за все бэкенды направления, практически начала с придыханием повторять слово «балансер» другим менеджерам.
Как показывает мой опыт, это знание крайне полезно именно для того, чтобы менеджеры могли понять, как сделать риски от релиза минимальными и заинтересовались CI/CD и различными технологическими экспериментами.
Когда-то года 4 назад примерно такой же историей в моей практике было рассказывать разработчикам про GitFlow-подобные системы «бранчевания» для стабилизации релизов и моратории на коммиты в релизную ветку, поддерживающиеся на уровне хуков, но последнее время это все-таки стало все меньше и меньше требоваться.
На мой взгляд, сейчас действительно важно повышать техническую грамотность нетехнических менеджеров. Совершенно не обязательно именно таким способом, конечно.
