Как не проспать проблемы в базах данных Postgres. Николай Самохвалов (Postgres.ai)

Чтобы поддерживать базы данных в здоровом состоянии, необходимо периодически заглядывать «под капот», «прощупывать» её на наличие ранних симптомов — другими словами, делать профилактическое исследование, оно же технический аудит БД, оно же healthcheck.
Сегодня будем говорить про здоровье баз данных.

Вкратце обо мне:
- С Postgres работаю активно и очень давно в разных ипостасях. Когда-то даже немножко хакером побыл.
- В последние годы я занимаюсь тем, что в долине, в большей части в США, консультирую, как лучше масштабироваться, как лучше избегать проблем заранее, а не тогда, когда они уже у нас уложили production.
- Участвую в разных конференциях в качестве участника программного комитета, включая эту конференцию.
И мы идем сейчас к тому, что мы делаем то, что не делает Cloud Vendors и другие. У них по-прежнему главная задача, как в мире микросервисов Kubernetes и т. д. сделать оркестрацию provisioning, бэкапы, реплики, failover, которые будут еще много лет улучшаться. Но у нас фокус дальше — другие задачи DBA, которые пока что слабо решаются. У нас задача их решать и автоматизировать.
И об одной из них сегодня пойдет речь. Это проверка здоровья.

Постановка проблемы.
Кто из вас работает с Postgres ежедневно? В правой части в два раза больше, чем в левой. А кто из вас хотя бы раз, разбираясь с какой-то проблемой, докапывался до решения с помощью чтения исходников Postgres? Теперь слева больше. Это правильно.
Open source силен тем, мы можем закопаться в исходники и разобраться, что на самом деле происходит. Тем более, что это не так сложно. Как правило, чтение исходников в Postgres сводится к чтению комментариев, а это plain English. И он хороший, там все понятно.
Допустим это я или вы. У нас есть любимая база данных на Postgres.

И у нее есть пара реплик для HA, чтобы мы могли мастер переключить и downtime снизить к минимальным минутам, а если autofailover, то к десяткам секунд.

Но у нас разработчики начали великий распил на микросервисы или у нас там появились новые проекты, и у нас еще появились мастера с их репликами.
И если раньше мы заботились о нашей базе как о pet, т. е. как о домашнем животном и знали все болячки, особенности, то теперь у нас есть cattle и нет роскоши относится к каждому из них как к любимому животному и выхаживать. Нам нужно управлять всем этим делом.
И, конечно, очень часто в компании кто-то один или несколько человек лучше знают область СУБД, но их сильно меньше, чем backend engineers. И если у вас только пара рук, которые знают, как работать с базами, то делать это становится проблематично. И с этим нужно что-то делать. Это проблема.
Можно немножко с другого конца подойти к этому вопросу. Если у вас есть какая-то система, то СУБД — это всегда сердце. Я выбрал эту профессию, потому что я с самого начала знал, что база данных есть в любой системе. Она никуда не денется. Реляционная модель будет еще долго жить.
И это сердце вашей системы. Это то, где лежат данные. Это то, что сложно масштабировать, потому что часто это многотерабайтная база, которую не так-то просто взять и развернуть еще где-то.
А проблемы в базе данных — это всегда очень больно. И лучше проблемы видеть заранее. Можно провести аналогию. Если у вас есть автомобиль, то вы должны делать диагностику регулярно. Или, если вы не следите за своим здоровьем, то в дальнейшем будете расплачиваться более глобально. Тоже самое и с базами данных.

Учитывая все выше сказанное, что мы хотим?
Мы хотим прийти, увидеть мастер, несколько реплик и очень быстро понять, что они из себя представляют. Нас обычно интересуют вполне конкретные вещи.
Я забыл упомянуть о том, что я за свою карьеру сделал больше 100 технических аудитов именно для Postgres. И выработал план, какие обычно штуки нам нужно проверять. Конечно, можно сильно углубиться. А можно сделать золотую середину, где мы покроем важные вопросы и сможем подсветить проблемные участки.
Итак, мы пришли и хотим очень быстро понять, с кем мы имеем дело. Или хотим заново понять, потому что мы приходили в последний раз полгода назад. Такое тоже бывает. Допустим, у нас несколько микросервисов и куча баз. И именно этот сервис мы проверяли последний раз полгода назад и уже забыли.

И обычно мы хотим узнать, что за ресурсы используются. В случае cloud хотим узнать, какие там instance, какой тип нагрузки. В случае self-management cloud мы хотим узнать версию системы, версию ядра, какая файловая система там используется. И также мы хотим быстро понять, есть ли различия между мастером и репликами, потому что это тоже важно. Если failover случится, то у нас реплика будет совершенно другим мастером, чем раньше.

И также мы хотим быстро понять, где главные потенциальные проблемы или где уже существуют проблемы, которые из-за недостатка внимания мы проспали.

Это очень частая ситуация, что какие-то проблемы живут долго, пока они совсем не обозначат себя. Иногда это только зарождающие проблемы. И это тоже самое, что в машине, что в здоровье человека. В любой сложной системе, включая такую сложную систему, как человеческое тело, есть такие паттерны, что мы можем что-то заранее выявить.
И это может быть что-то с performance. Мы можем понять, что эти части workload ведут себя хуже и уже видно, что они хуже.
И есть какие-то серьезные вещи. Этот чек-лист может включать в себя проверку каких-то вещей, которые покажут, что, допустим, fsync выключен. А это означает, что у нас есть большой риск потерять данные и получить не консистентное состояние в случае hard reset сервера. Такие вещи надо сразу подсвечивать.

И мы хотим в случае проблемы иметь возможность ее решить, знать, где копать и какими инструментами копать.

Это хороший вопрос. Я буду рассказывать про open source инструмент, который мы сейчас развиваем. Завтра будет версия 1.1, 3–4 недели назад была версия 1.0, т. е. мы его уже вовсю используем в production и на ряде клиентов обкатываем, автоматизируя собственные процессы. Он open source, на GitLab доступен. Вы можете его использовать, вы можете использовать какие-то принципы из него.
В мониторинге мы тоже можем увидеть проблему.

Но мониторинг часто недостаточно глубоко копает. Да, мы видим, что CPU высоко занят. Но чтобы докопаться до причины, надо идти вглубь.
Мы можем развивать свой мониторинг. Добавлять туда, например, анализ запросов. Но не все мониторинги на это способны. Если это Datadog, то там вообще этого нет. В Grafana только в последних версиях это можно как-то запилить на основе pg_stat_statements. Если у вас Okmeter, то вам повезло. Там уже достаточно интересные штуки покрыты.
Мониторинг постоянно теребит вашу базу проверками. Вы не можете более-менее тяжелые проверки делать. Например, я вижу, как некоторые пытаются запилить анализ bloat. И со временем у них запросы начинают 10–20 секунд отрабатывать. Для мониторинга это уже не очень хорошие запросы. Гонять такое каждые даже 5 минут — это не очень хорошо. Да и не надо. Достаточно эти проверки делать реже, но более полноценно.
Postgres-checkup — это такой инструмент, который нужен для глубокого анализа, но не так часто.
И отдельные наши консалтинговые случаи, когда вы приходите к кому-то и хотите помочь. И они даже готовы поменять мониторинг. Если это более-менее крупный заказчик, то это занимает в лучшем случае недели. А нам хочется прямо сейчас. И Postgres-checkup может прямо сейчас информацию дать.

Как я уже сказал, не все вещи покрываются мониторингом. В некоторых случаях нам хочется анализировать в совокупности мастер и реплики. А в мониторинге это нетривиально. Хорошо, если графики можем какие-то наложить, а нам хочется не графики, нам хочется таблицу нарисовать. Мониторинг имеет свои ограничения в том виде, в котором он сейчас существует.

У мониторинга задача другая. У него задача — быстро сообщить о проблемах, которые всплыли, превысили какой-то порог и нужно срочно отреагировать.
И, как правило, хранение логов, хранение мониторинг-информации тоже какое-то ограниченное. Вам повезло, если у вас есть информация, допустим, за прошлый или позапрошлый год. Обычно в мониторинге такой информации нет. И выяснить, как росли таблицы — это становится очень нетривиальным занятием. Нам даже приходится специальные статистические алгоритмы использовать, чтобы понять, как оно росло и как оно будет дальше расти, например, размеры таблиц, индексов и т. д.

Но мониторинг — это необходимая вещь. Я не говорю, что давайте выкинем мониторинг и заменим на Postgres-checkup. Мониторинг должен быто обязательно. И Postgres-checkup вам никак не заменит мониторинг. Это другая вещь.
Postgres-checkup’ом вы в лучшем случае будете что-то раз в неделю анализировать, но это не такой тактический инструмент, как мониторинг, который каждую минуту или 30 секунд опрашивает все и если что-то случается, то красную лампочку зажигает.
Это уже следующий вопрос. У нас есть уже какие-то toolset. В эту сторону мы и должны копать, чтобы решать проблему хорошей автоматизированной проверки здоровья. Это наш фундамент для того, чтобы строить автоматизацию проверки здоровья.
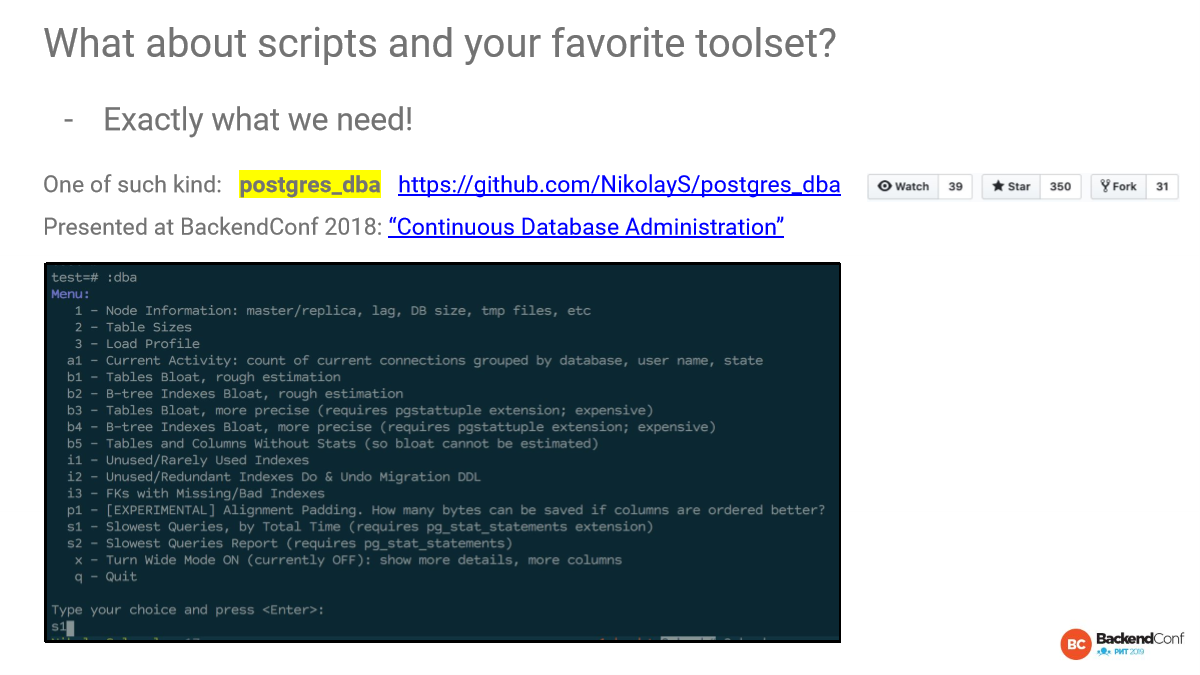
https://github.com/NikolayS/postgres_dba
https://www.youtube.com/watch? v=V-cwPLtDtSY
Год назад я рассказывал про инструмент Postgres_dba, который получил заметный отклик на GitHub. Это такая штука, когда PSQL заходишь и получаешь интерактивное меню. И говоришь: «Мне, пожалуйста, вот этот отчет». Этот инструмент я постоянно использую. Мы в мониторинге что-то нашли и дальше пошли копать.
Мы сидим на одной машине здесь. Это уже ограничение. И, конечно, PSQL-формат, который мы там видим, ограниченный. Это консоль. Я очень большой любитель консоли. Но не все такие большие любители.

pg-utils, pgsql-bloat-estimation, pgx_scripts, pgcluu, check_postgres.pl, pghero, sqlcheck, heroku-pg-extras
Есть другие инструменты. Некоторые из них здесь перечислены. Например, pghero, написан на Ruby. Он очень легкий и простой, но хорошо закрывает некоторые вопросы.
Есть такие древние, как check_postgres.pl, который написан на Perl и т. д.
Все это мы взяли и замешали, и продолжаем замешивать:
- Мы делаем больше автоматизации.
- Улучшаем форматы.
- И делаем multi-node analysis.
Вот что мы делаем в Postgres-checkup.

Из чего у нас состоит инструмент и как мы его применяем на практике?
https://gitlab.com/postgres-ai/postgres-checkup
Он выложен на GitLab. Прямой наследник Postgres_dba, который однонодовый и ручной.
Есть очень важное требование, которое не всегда легко придерживаться, но я его обязательно придерживаюсь. Мы ничего не должны ставить на сервер: никаких агентов, ничего вообще. Это принципиальное требование, потому что нам нужно с первой минуты получать результаты и смотреть, что там происходит.
Инструмент ограничивает себя в 30 секунд любой запрос, т. е. если у вас огромная база, то какие-то запросы могут занимать какое-то время. Например, bloat-запросы. Инструмент будет себя ограничивать и statement_timeout он выставляет автоматически. И минимальный эффект оказывает на сервере. Хотя, конечно, следы могут быть. Это не для того, чтобы никто не узнал, что мы его гоняем. Имеется в виду, что здесь аффект на производительность сведен к минимуму.
Наоборот, выставляется application-name checkup. Наоборот, видно в логах, что происходит.

И, как я говорил, multi-node analysis. Очень важно в совокупности смотреть на картину в целом.
И как результат, если раньше для крупных баз, которые развиваются несколько лет и там много терабайт, нам приходилось тратить на полную проверку порядка двух недель, то сейчас это сводится к 4 часам. Из которых сам сбор данных — это меньше 10 минут. 10 минут — это минимум, потому что там 2 снапшота надо. А дальше идет пара часов анализа экспертом, чтобы написать правильные выводы, рекомендации и т. д.
Как это работает?
У нас есть мастер, несколько реплик. Мы со своей машины идем по ssh-соединению.
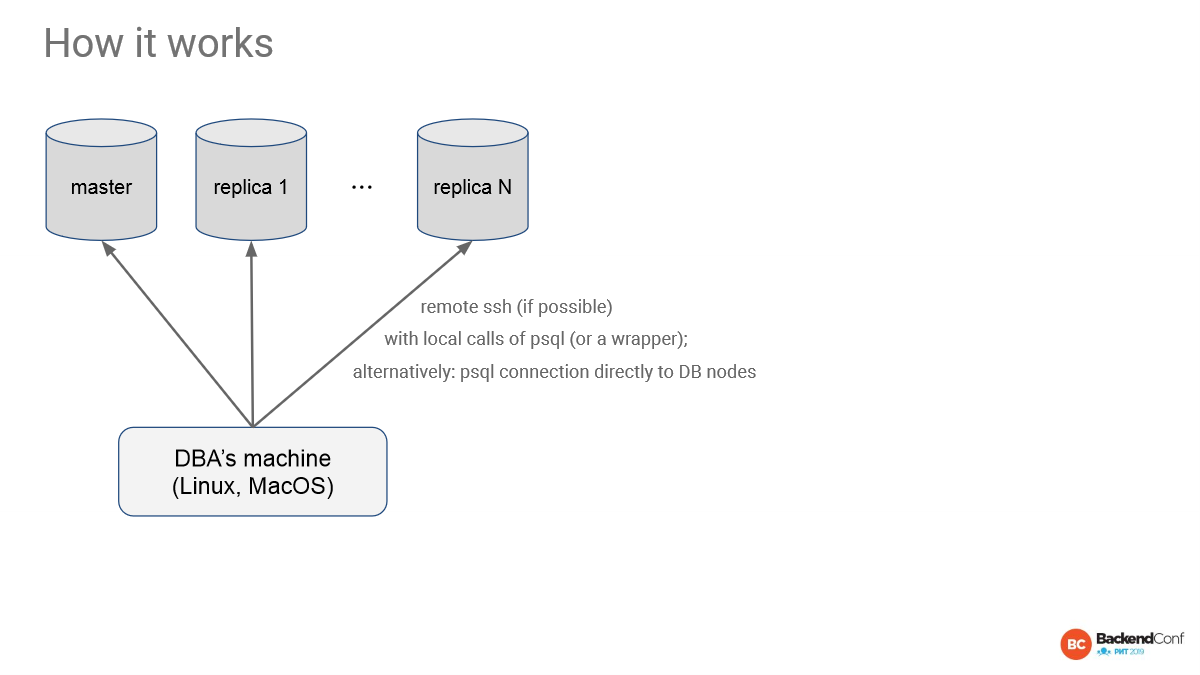
Нам нужны права. Как правило, у DBA есть права. Или у того, кто общается с DBA, есть права. И по remote-ssh запускается локально PSQL и все собирается. Ничего ставить не надо.
Второй вариант — это прямое соединение. В случае RDS или других облачных решений вы можете использовать прямое соединение к Postgres, но тогда вы потеряете ряд отчетов, которые смотрят файловую систему, операционную систему и т. д.
Поддержка RDS у нас тоже в планах есть, чтобы собирать информацию, что за instances, какие там характеристики и т. д.
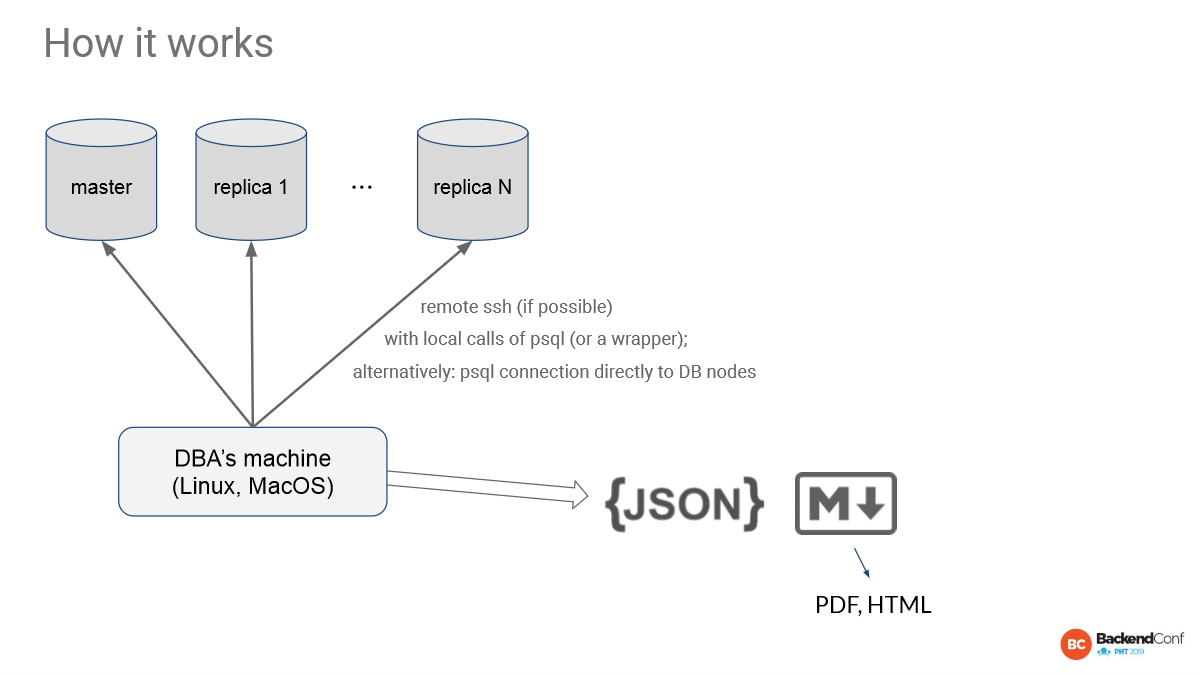
И дальше первое, что делает инструмент, он генерирует JSON-отчеты. Они складываются в файлы. Их можно сохранять в Postgres. С ними можно делать все, что угодно. Это максимальная гибкость. Т. к. это JSON, вы можете интегрировать свои какие-то другие решения. Мы специально так сделали, чтобы быть machine friendly.
А дальше генерируется markdown report. Markdown reports генерируются для того, чтобы им можно было легко вставлять, например, в GitHub issues или в GitLab issues. Мы так сделали, потому что нам так удобно. И, действительно, взять кусочек report и вставить его в GitHub issues, и сказать: «Смотрите, тут такая-то проблема, такой-то запрос тормозит», это просто. Кусочек markdown уже сгенерирован, там какая-то табличка и все это очень ускоряет работу.
Сейчас из markdown есть возможность автоматически попросить сгенерировать PDF или статичный html. В ближайшем будущем мы планируем также сделать красивый динамический html, который будет брать JSON и отрисовывать их так, чтобы можно было там сортировать и т. д. Но пока только вот такая картина, что уже неплохо. У нас есть machine friendly и есть human friendly. Пока что без картинок, пока что только таблицы, но это база, картинки тоже будут.

Есть еще один вариант. Вы можете ничего там не ставить на машину. Вы можете взять docker-контейнер, поднять на основе нашего образа, который выложен на GitLab. И оттуда можно плясать. И тоже самое делать из этого контейнера.
Этот контрибьютор сделал Иван Муратов. Спасибо ему за это. И есть пример, где это уже хорошо используется. Сейчас это обкатывается прямо в Gitlab.com. Они checkups, reports как раз у себя в CI/CD используют. Kubernetes поднимает runner, контейнер. Там несколько строчек, весь опрос происходит. Это очень удобно, красиво и современно.

Теперь отчеты.

У нас очень много всего. Есть больше 50 отчетов, которые мы запланировали. И где issues видны, это мы уже сделали. Мы сделали больше половины уже. И это будет постоянно пополняться, потому что поле для работы там огромное.
Вкратце расскажу. У нас разбивается на общие вопросы. Дальше идут вещи, которые сложно автоматизировать. Обычно об этом мы разговариваем с людьми, т. е. как бэкапы настроены, используют ли они что-то для autofailover и какая вообще политика. И про мониторинг тоже самое, т. е. какие метрики имеют и т. д.
А дальше пошла автоматизация. Это автовакуум, настройки bloat, анализ индексов, запросов, схем. И об этом мы как раз сейчас поговорим.

Начнем с первого.

Первый отчет — это просто мы знакомимся с системой. В данном случае это из runner GitLab«овского взято. Видно, сколько памяти, какой процессор. 1 VCP всего. И видно, что у нас версия ядра не такая уж старая. И это уже хорошо.


Conclusions, recommendations мы только начали автоматизировать, но мы все еще принимаем заявки на то, чтобы бесплатно их заполнить.
Еще один важный момент. Каждый отчем удобно строить, деля на 3 части:
- 1 часть — это наблюдение, т. е. то, что мы видим. И очень классно бывает сырой вывод прилагать, потому что это внушает доверие тем, кто будет потом с этим документом работать. Не всегда это возможно, но тем не менее.
- 2 часть — это conclusions, т. е. какие выводы мы из этого делаем. Обычно это нормальный plain English или Russian. Мы говорим: «Мы здесь наблюдаем, что у вас там такая-то вещь. И есть подозрение, что скоро будет проблема».
- 3 часть — это action item, т. е. рекомендации, что нужно сделать, чтобы этого избежать, либо, как исправить, если плохое уже случилось.
Вот такая простая структура каждого отчета позволяет ничего не упустить. И из этого понятно, что делать.
И пока conclusions, recommendations есть только в этой версии, которая в мастере есть. Там 5 отчетов, по-моему, заполняются. Остальные conclusions, recommendations будут пустые. И мы готовы их для вас заполнить. Присылайте на checkup@postgres.ai.
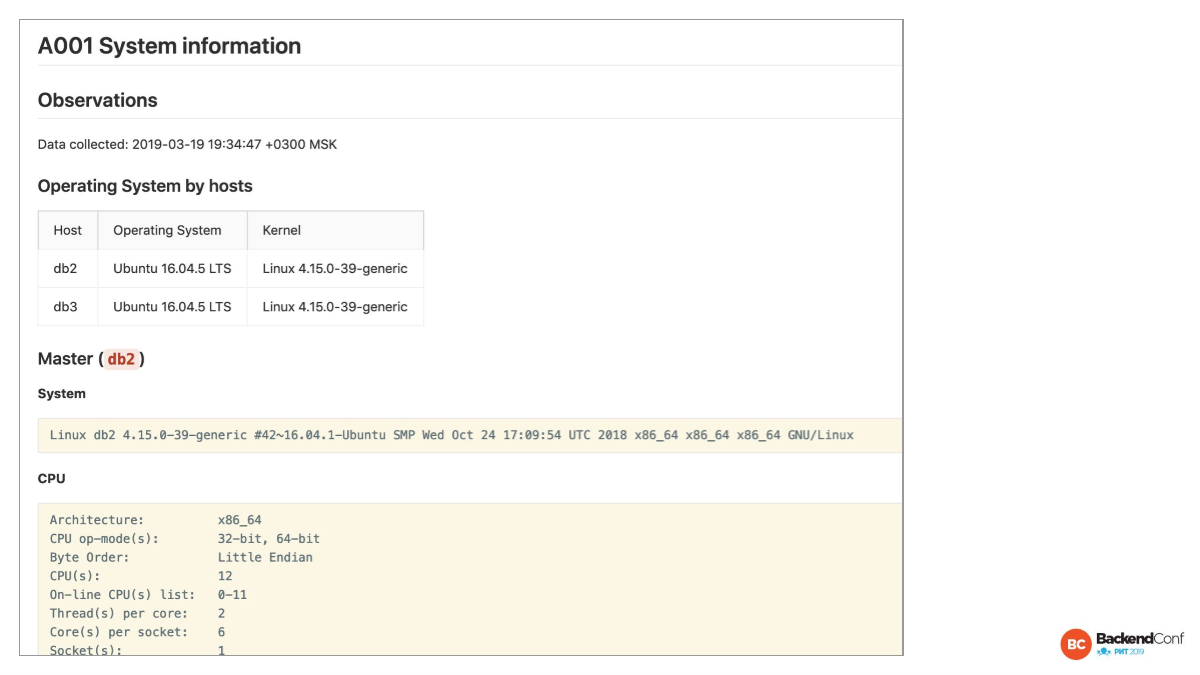
Вот эти отчеты для всех нод. И мы можем их быстренько посмотреть все ли там одинаковое, допустим.

Здесь мы видим, что для вот этих двух нод, где одна — это мастер, другая — реплика, все совпадает. Это здорово. Иногда не совпадает и это нехорошо.
Почему нехорошо? Если у нас случился switchover или failover, то мы оказываемся в других условиях. И очевидно, что это нехорошо.
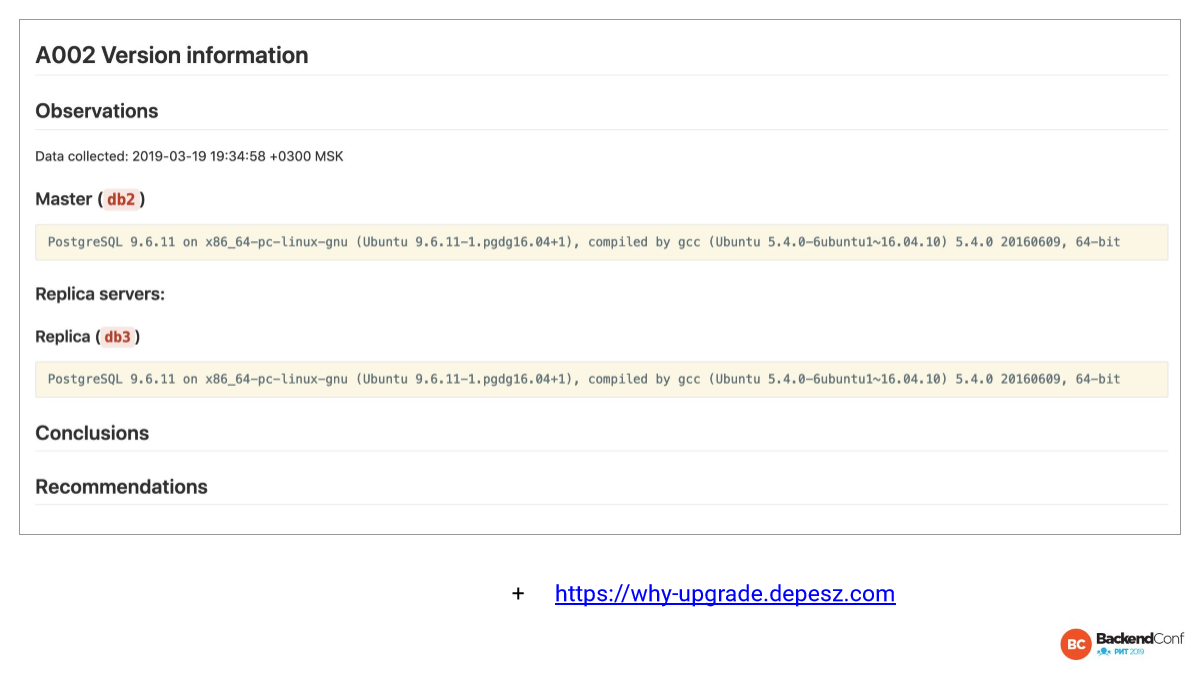
https://why-upgrade.depesz.com/
Дальше у нас в планах сделать очень крутую рекомендацию, которая будет говорить, что вы используете GNU индексы, а вот там они падали, срочно обновляйтесь. Пока такого нет, но уже в мастере говорится, какая у вас мажорная версия, поддерживается ли она в community и будет ли поддерживаться в ближайший год. Потому что, если не будет поддерживаться, то вам стоит обновиться, иначе вы можете оказаться в ситуации, когда обнаружили баг, но его уже никто не хочет исправлять, потому что эту версию больше не развивают.
А также будет говориться, какая у вас минорная версия, насколько вы отстаете от самой новой минорной версии. И вот этот сайт очень хороший: why-upgrade.depesz.com. Здесь вы можете быстро посмотреть список всех изменений, которые были между вашей версией и самой новой. Это помогает разобраться — стоит ли вам срочно обновляться или можно месяц-два еще подождать.
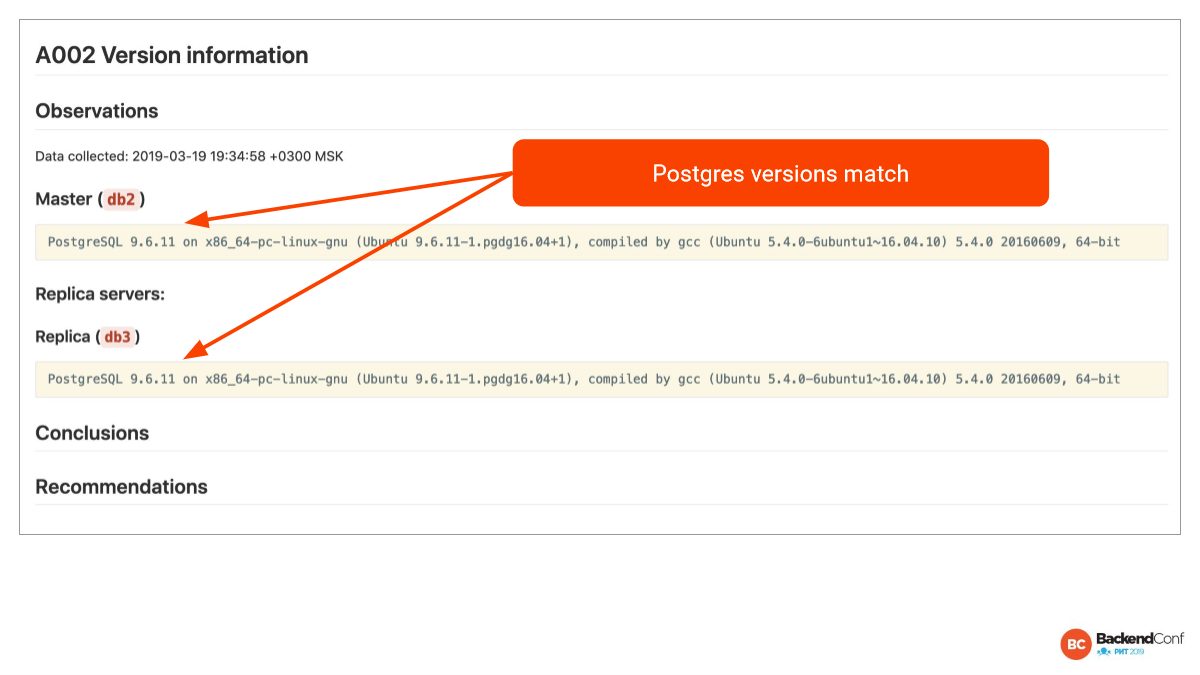
Здесь мы видим, во-первых, что версии одинаковые. И это уже хорошо. Потому что любые отклонения между мастером и репликой — это зло.

Во-вторых, здесь версия, конечно, не самая свежая, но еще не криминал, т. е. это не 9.5 или 9.6, у которых вообще серьезные проблемы были, которые в случае failover могли привести к тому, что вы там данные потеряли. И версия хотя бы больше 9.6 — это уже хорошо.
Но видно, что есть некоторые отставания. В частности, печально известная проблема с fsync. Потому что в Linux реализация fsync такая, что в некоторых ситуациях на самом деле данные не сохранены, а fsync отвечает, что все хорошо, там была ошибка. И теперь Postgres будет падать в ситуации, когда есть подозрения, что есть такая проблема.
И тут есть забавная ситуация. У меня есть заказчики, которые говорят: «А, может быть, нам лучше не обновляться, потому что, если там corruption пара страниц памяти, то это не так плохо, как если мы пролежим кучу минут и потеряем кучу денег? Может быть, фиг с ним, с corruption?». Конечно, хозяин — барин, но наша задача — показать, что мы упускаем.
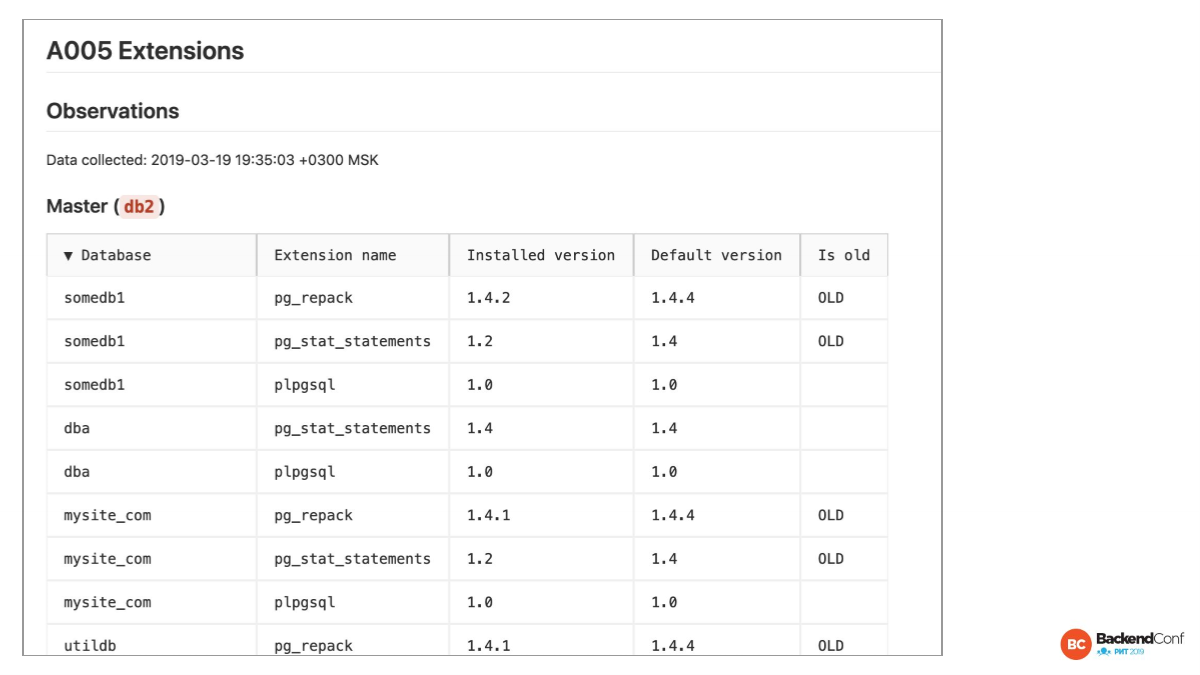
Вот то же самое с расширениями. Автоматически генерируется список, какие там версии. У нас есть понятие «текущая база». Базу, к которой мы коннектимся, мы прощупываем гораздо более подробно. Она называется current database. Мы ее исследуем специализированно. И в частности мы собираем все версии расширений, которые установлены и которые доступны.
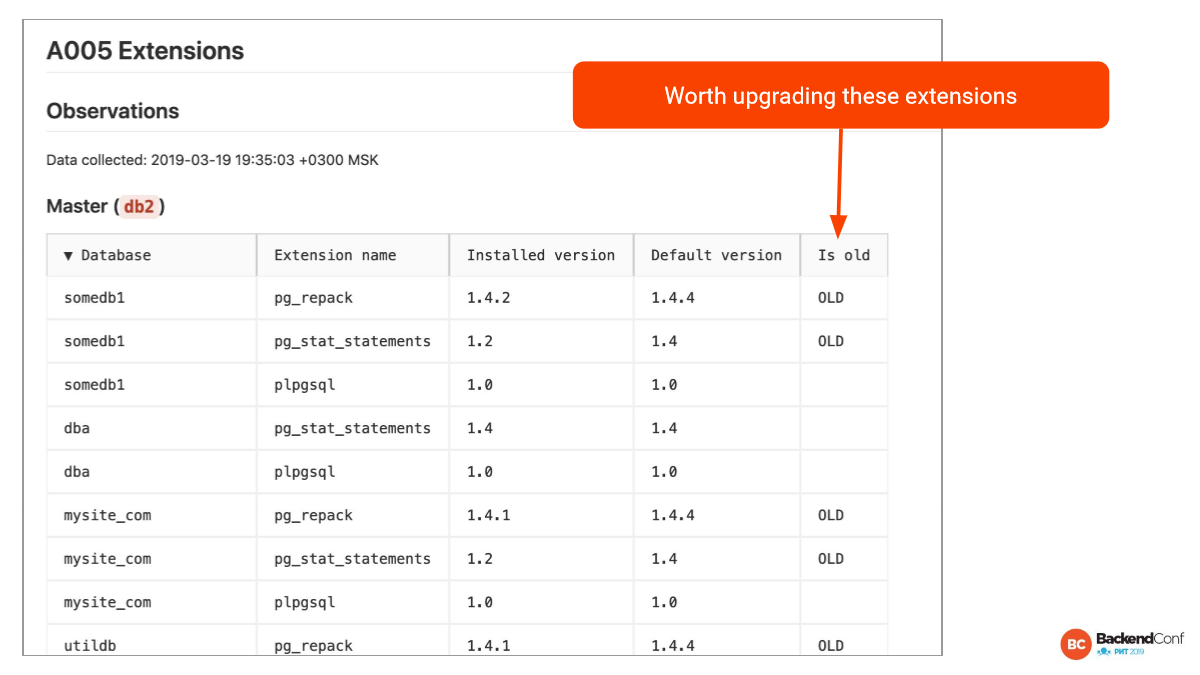
И здесь мы видим, что есть несколько расширений, которые отстают по версии. И это довольно легко исправить. Нужно просто ALTER EXTENSTION сделать или пересоздать расширение.
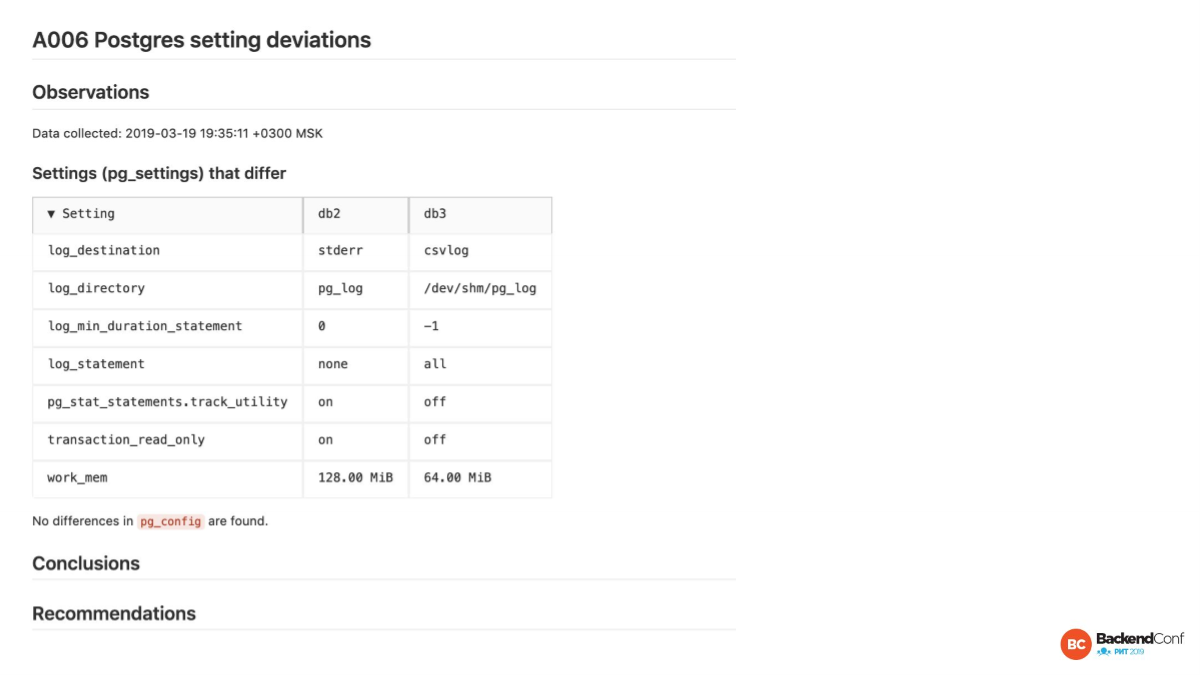
Это мой один из любимых отчетов. Это как раз про те самые разницы между мастером и репликой. Когда нет автоматизированных проверок, когда мы все делаем вручную, то процент случаев, когда есть отличия, приближается к 100. Руками такое каждый раз проверять замучаешься. Если вы просто сейчас пойдете на свой мастер, на свои реплики и сравните конфиги, то есть большая вероятность, что там будут отличия.
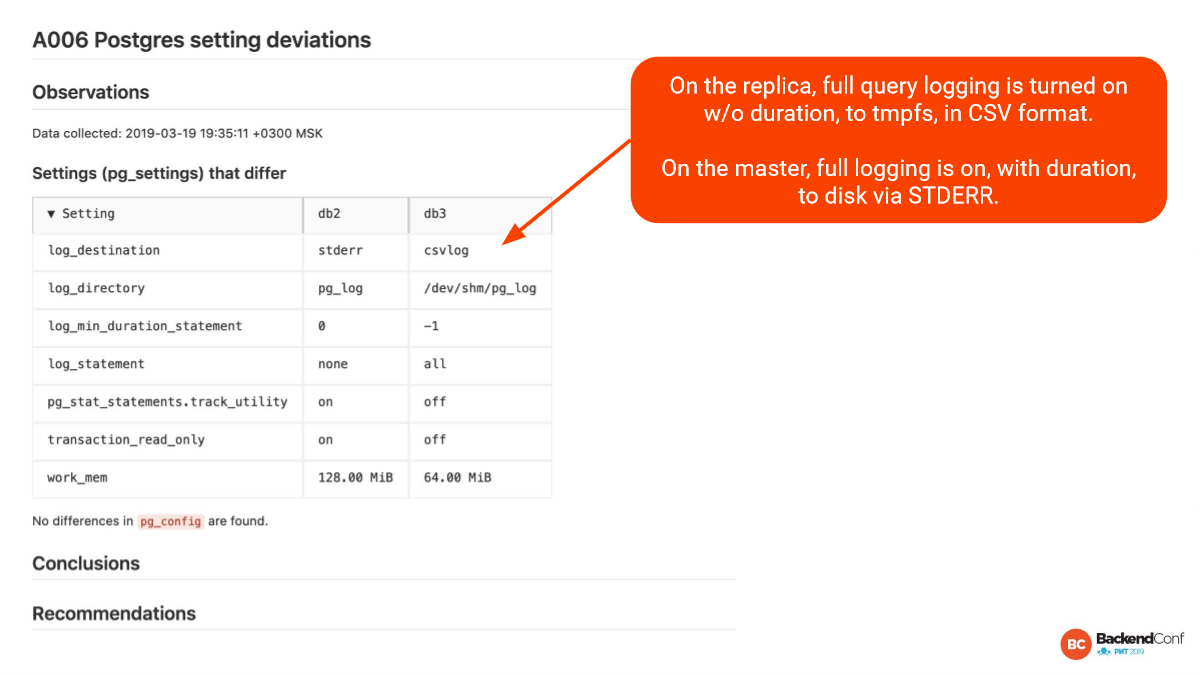
Здесь, конечно, клинический совсем случай. Здесь все различается в плане логирования. Во-первых, здесь разный log_distination, т. е. в одном случае мы пишем csv-файлы, в другом просто файлы.
Здесь вообще используются директория, а здесь в память пишем. Это совершенно разные подходы к логированию. На мастере одно, на реплике другое. И мастер частенько имеет большую загруженность, и в случае failover, возможно, что реплика не потянет. Такое здесь легко может быть.
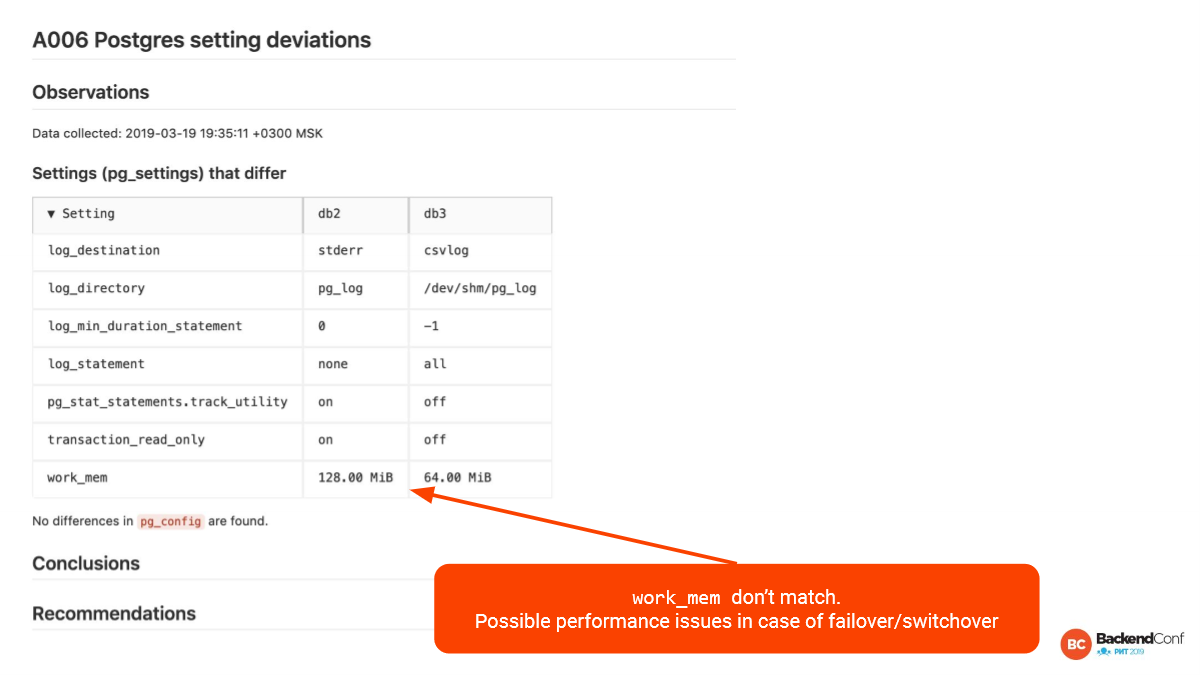
Work_mem отличаются. Это тоже важно поддерживать близко. Если у нас реплика HA, то она должна быть в любой момент готовой стать новым мастером. И нехорошо, если work_mem другой, особенно, если меньше. Да и больше — это тоже нехорошо. Это надо отслеживать.

Есть еще один отчет, который говорит — делали ли вы ALTER SYSTEM. Если вы делали ALTER SYSTEM, то вы здесь увидите postgresql.auto.conf. Это означает, что вы руками применили какое-то изменение с помощью ALTER SYSTEM. И, как правило, сделали это на одном сервере. Может быть, не на одном, но в любом случае это значит, что ваша переконфигурация прошла, скорее всего, руками, а не через ваш Ansible, Puppet или что вы там используете. Это тоже нехорошо.
Видно, что в данном случае 3 настройки были руками пропатчены. И хорошо бы, чтобы конфиг был в Git, и мы отслеживали, когда было сделано и что было сделано.
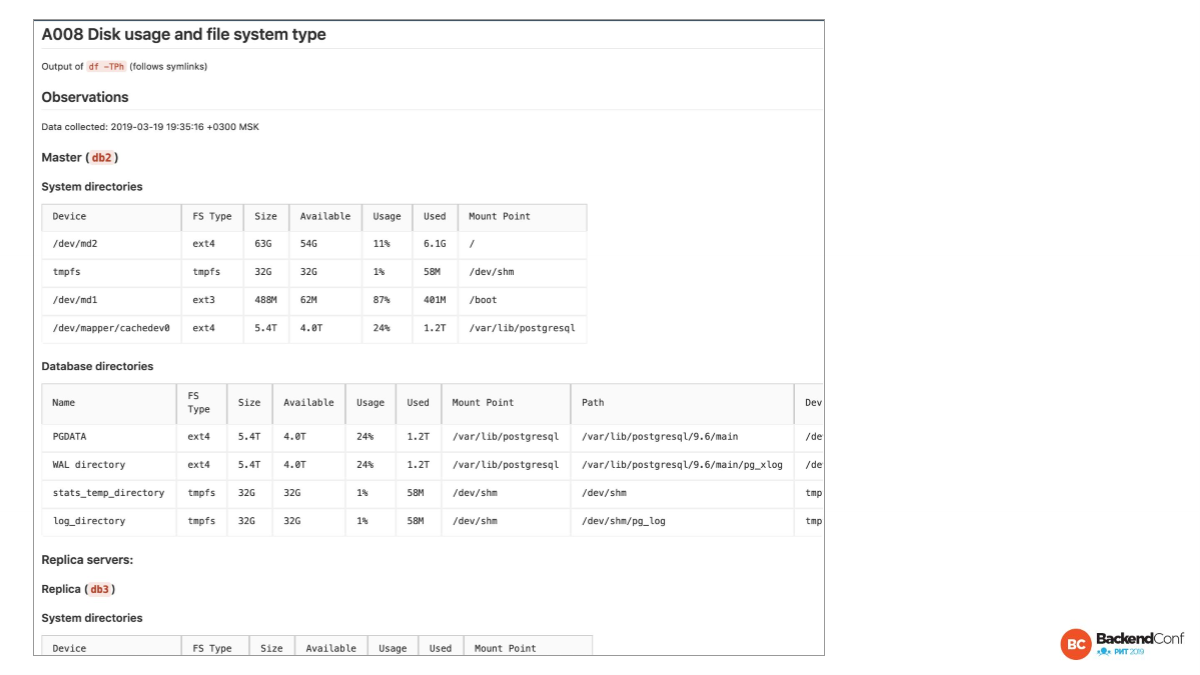
Следующий отчет — это Postgres-ориентированный взгляд на файловую систему. Особенно нас интересует PGDATA. Во второй табличке мы смотрим на PGDATA, смотрим на WAL directory, где у нас журнал транзакций — вынесено ли это, не вынесено ли это. Вот здесь не вынесено.
Видно, что mount point одинаковый. Это значит, что они на одном физическом диске. Сейчас нет строгой рекомендации выносить, как раньше это было rotation disc. Мы всегда говорили, что давайте лучше журнал транзакции писать на отдельный драйв.
Сейчас такой рекомендации уже нет. У нас SSD. Они хорошо поддерживают парализацию разных обращений.
И смотрим на stats_temp_directory. Лучше всего это в память выносить. Здесь это сделано.
И смотрим, где у нас логи. В данном случае логи тоже в памяти. И это экзотика. Это из другого доклада, но это интересное решение, чтобы собрать побольше логов, чтобы все запросы прологировать.

Следующая тема достойна отдельного доклада. У нас на HighLoad и на Backend Conf были такие доклады. Вы их можете посмотреть в YouTube. Эта тема неисчерпаемая, но есть некоторые признаки, что это в Postgres перестанет так сильно болеть когда-то. И это bloat, т. е. раздувание таблиц и индексов, особенно индексов.

Здесь мы начинаем с того, что мы смотрим какие у нас настройки. И пока что вы должны быть экспертом для того, чтобы быстро понять все. Здесь у нас настройки по умолчанию. Но мы сейчас движемся в сторону того, чтобы не экспертам давать более удобное представление, т. е. в observations будет расписано, что если autovacuum не настроен, то это признак того, что, скорее всего, проблема есть. Потому что дефолтные настройки в Postgres до 12-ой версии.
Кстати, в 12-ой версии кое-какие настройки сделали агрессивнее в 10 раз.
До 12-ой версии дефолтные настройки означают, что вам обязательно надо затюнить, если у вас более-менее существенная нагрузка. И если вы это не сделаете, то будет накапливаться bloat очень быстро.

После настроек первое, что мы смотрим, это есть ли угроза transaction id wraparound.
Относительно свежая история с mailchimp, когда они пролежали полутора суток. Была деградация. Один шард полностью лежал, потому что они уперлись в transaction id wraparound. И это проблема очень болезненная.
Вам нужно регулярно смотреть, что у вас к 50% точно ничего не приближается. Все capacity used у вас маленькие. Здесь у нас вообще по нулям. Но обычно мы здесь видим не больше 10%, потому что в Postgres, начиная с 10% уже агрессивно autovacuum начинает отрабатывать и убирать это.
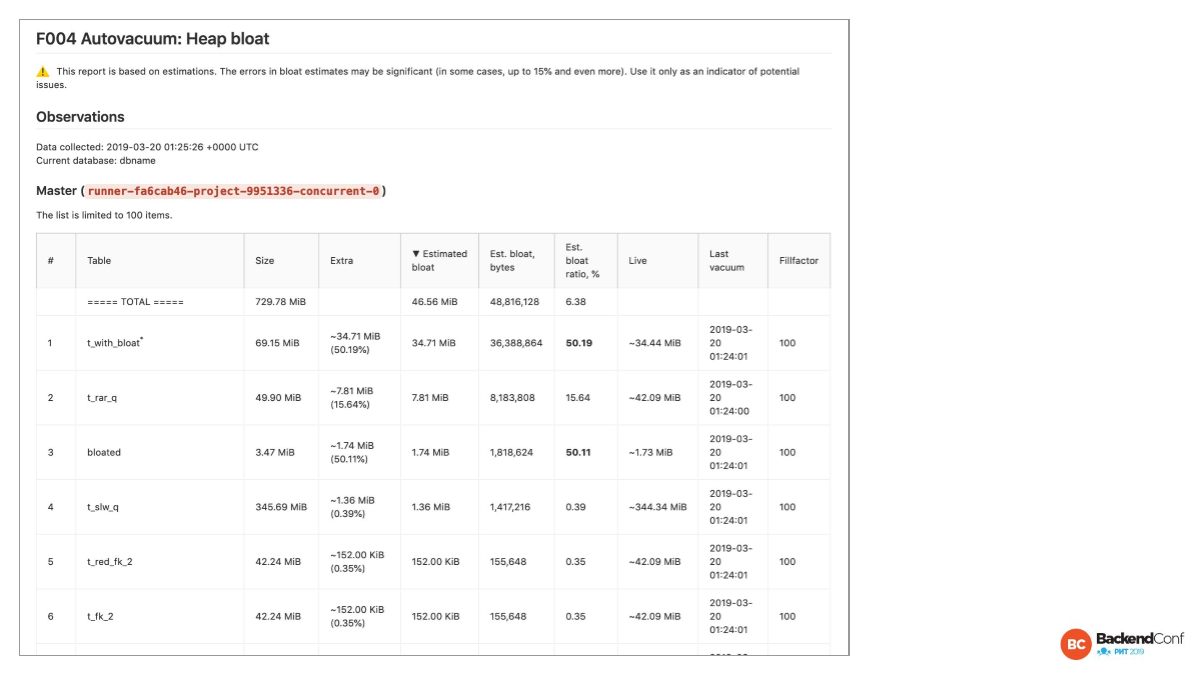
Heap bloat — тот же table bloat. Мы постарались сделать более human friendly вещи, т. е. мы показали проценты, гигабайты. Мы сделали жирным, когда проценты более высокие. Здесь видно жирным, когда более 50%. Мы показали, когда у нас в последний раз был вакуум. Это все упрощает работу с понимаем, где у нас bloat.
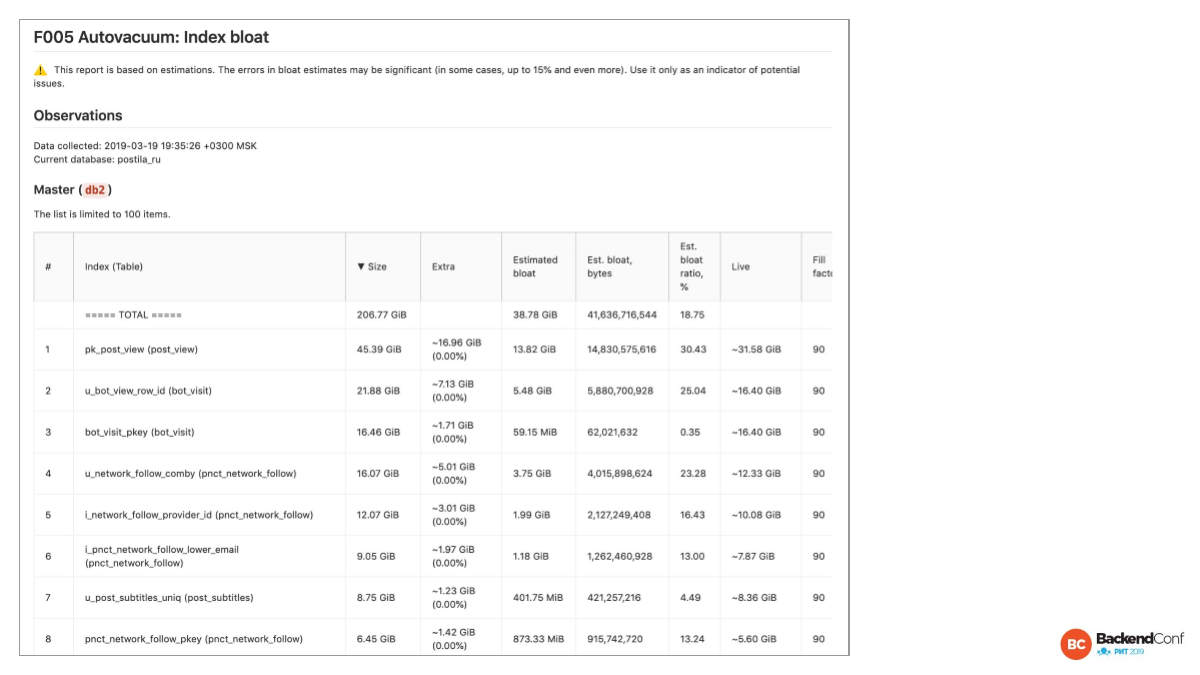
Конечно, index bloat — это более критичная вещь, потому что у вас, как правило, запросы используют index scan или index only scan. И раздувание индексов приводит к деградации производительности довольно серьезно.
И к тому же, index bloat — это более болезненная штука. Но в 12-ой версии индексы будут раздуваться меньше, чем до 12-ой версии. А как мы знаем, индексы рано или поздно все равно приходится перестраивать.
И за раздутием стоит следить. Если у вас там 40%, то это уже немножко напряг. 50% — это уже более существенный напряг. 90% — это означает, что в 10 раз индекс раздут. 90% — bloat, 10% — полезная нагрузка. Значит этот фактор умножается в 10 раз. Мы сейчас там добавили фактор, здесь его еще не видно.
Если между 90% и 99%, то там всего 9% разница, но это в 10 раз или в 100 раз у нас раздутие. В байтах это очень много. Байты мы тоже показываем.
Вы должны периодически индексы перестраивать. И bloat в таблице как раз хорошо покажет, что именно вам надо перестроить.

Важный момент: мы там пишем, что это estimated. Мы не делаем тяжелый анализ, мы делаем очень быстрый и легкий анализ. Он иногда ошибается.
И здесь есть пример, который я люблю показывать, потому что люди думают, что они знают свой bloat, а он может быть суперошибочным.
Вот здесь мы создаем табличку int4, потом int8, потом int2, потом int8. Те, кто знает internals, знают, что есть такая штука panting aliment. И между int4 и int8 4 байта будут ноликами забиты, т. е. из-за этих ноликов быстрый скрипт анализа bloat будет ошибаться очень сильно. С индексами та же картина.

Мы только что создали таблицу. Там 1 000 000 строчек. Там никакого bloat нет, там 0. Но быстрый скрипт анализа bloat будет говорить, что тут 23% bloat.

А для такого индекса он будет говорить, что вообще 31%. И вы можете броситься перестраивать индекс, хотя здесь его не стоит перестраивать.
Выход только один. Кроме checkup«ов наша фишка в том, что мы еще строим database lab в компаниях и позволяем упрощать стоимость экспериментов, исследований и т. д. И одна из простых вещей — это когда делаем клон, делаем vacuum full. Подождали. Иногда это сутки. И собрали размеры до и после. Это самый надежный способ узнать, какой у вас bloat.
Но в качестве быстрой оценки все равно, конечно, estimates нам нужны. Они как начальная стартовая точка для анализа.

Index analysis — это достаточно большая тема. Очень часто приходишь и видишь, что очень много лишних индексов понасоздавали. Иногда это бывает 20–30% от всей базы. И, конечно, в этих ситуациях хорошо бы сэкономить место и лишние индексы поубивать.
Базовых классов — 2: 1 — неиспользуемый, 2 — избыточный.
Простейший случай избыточного — это 2 одинаковых индекса. Нам нужно один оставить, другой прибить.
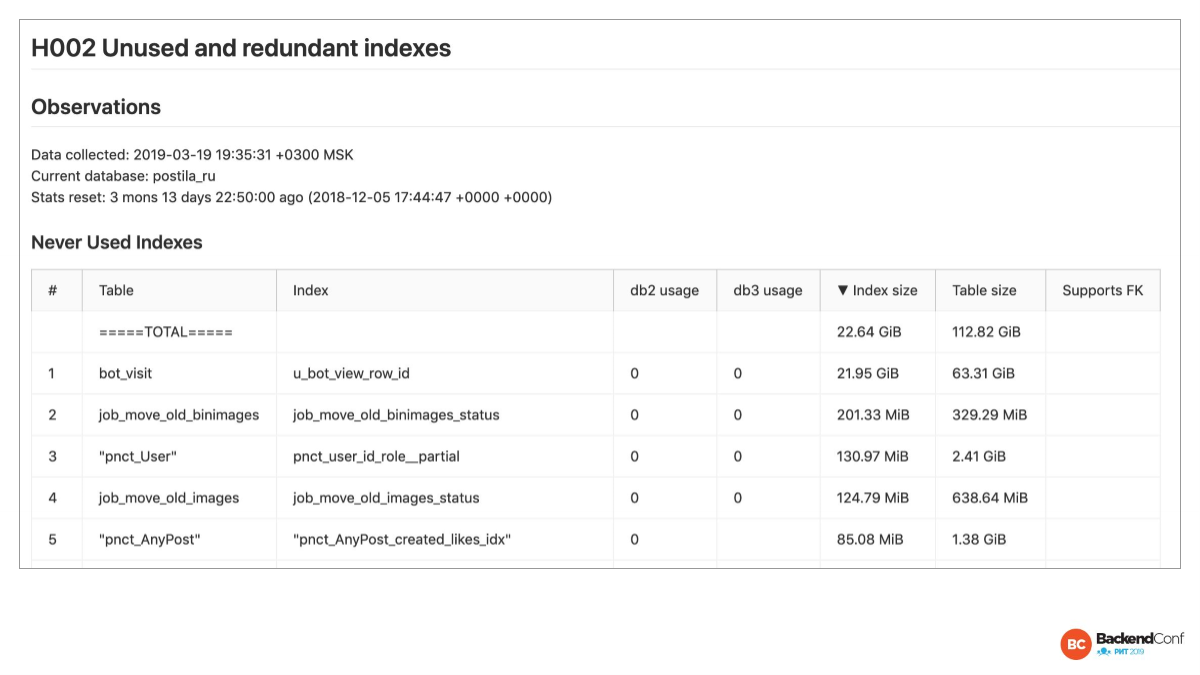
А в неиспользуемых индексах много скриптов, но нужно не забывать, что вы должны проверить все ноды. И Postgres-checkup утилита, конечно, не забывает это. Она по двум нодам проверила.
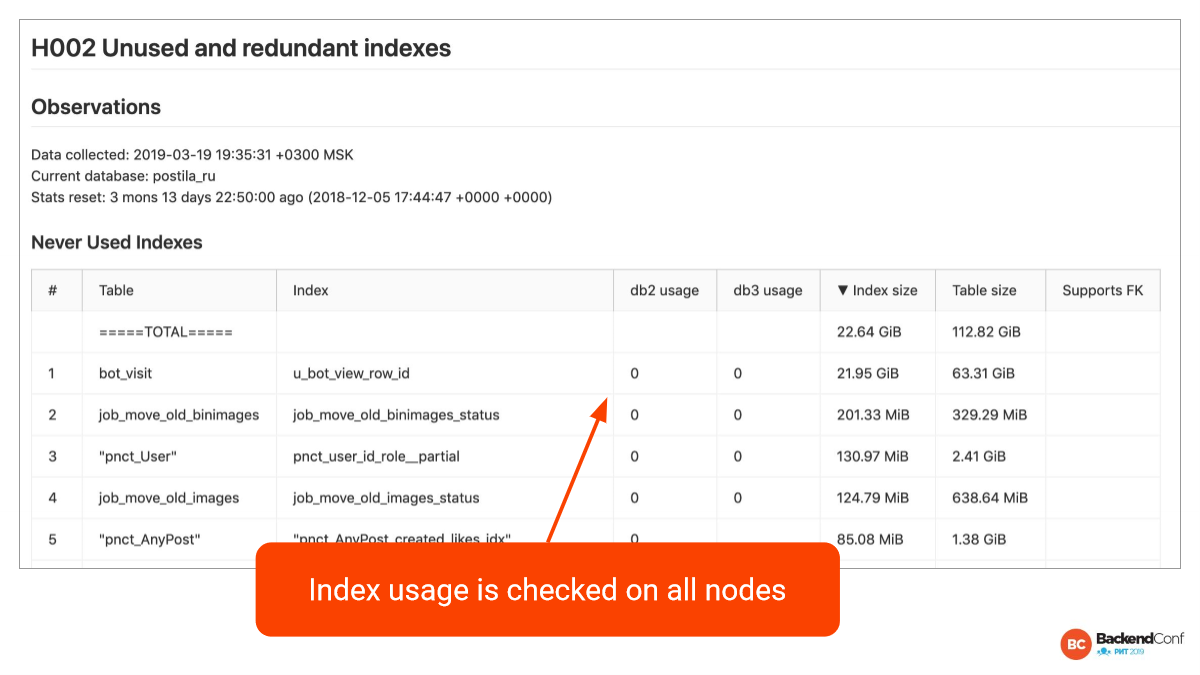
Мы специально здесь выводим нолики. Если не нолик, то значит, что статистики нет и ничего про этот индекс неизвестно. И когда мы видим нолики, то мы можем смело эти индексы замочить.
Единственное, нужно не забывать, что если статистика была сброшена час назад, то надо, наверное, подождать недельку, а то и месяц. Иногда бывает так, что индекс используется раз в месяц.
Еще бывает специальный случай, когда индекс нам особо не нужен, но он поддерживает внешний ключ. У нас для этого есть колонка. Здесь ни один индекс не поддерживает внешний ключ, т. е. со одного конца внешнего ключа индекс обязателен для Postgres, а с другого конца не обязателен. Reference table, т. е. откуда мы ссылаемся. И он обычно как бы не нужен, но если вы будете эту строчку удалять, то там вы получите Seq Scan в полной таблице, потому что он должен убедиться, что на него никто не ссылается.
В таких случаях, даже если мы индекс не используем, мы можем захотеть его оставить, потому что вдруг мы через пару дней решим удалить какую-нибудь строчку. И мы сознательно какие-то индексы оставляем, но это специализированные случаи.

Это почти последняя тема. Она очень важная. Это вершина всего анализа. И это неисчерпаемая тема, которая иногда даже выводится в отдельную активность. Это анализ запросов. СУБД должна выполнять запросы как можно быстрее.
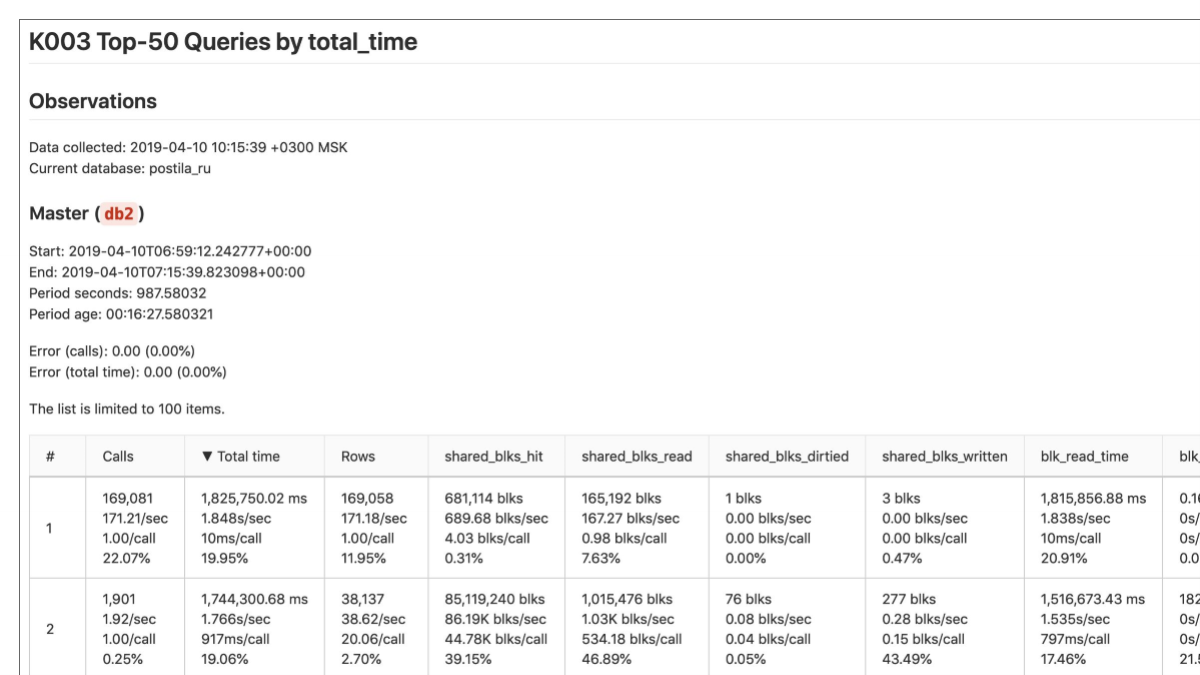
У нас свой взгляд на все это. Pg_stat_statements должен стоять у всех для анализа производительности запросов. Если вы его не ставите, то вы не знаете, что у вас с запросами происходит. Только pg_stat_statements даст вам нормальную и полную картину статистики со стороны базы. В нагруженном проекте, как правильно включать полное логирование — это отдельная большая тема.
У нас такой взгляд. Есть Pg_stat_statements. Что он делает? Postgres сам собирает тайминг. Собирает, сколько buffers было взято из buffer pool. Это называется хитами. Собирает, сколько было считано с кэша операционной системы. Это называется read, т. е. в buffer pool не оказалось, пришлось читать из кэша операционной системы. К сожалению, Postgres не знает, что, возможно, и в кэше операционной системы не было. Возможно, это даже с диска пришлось поднимать.
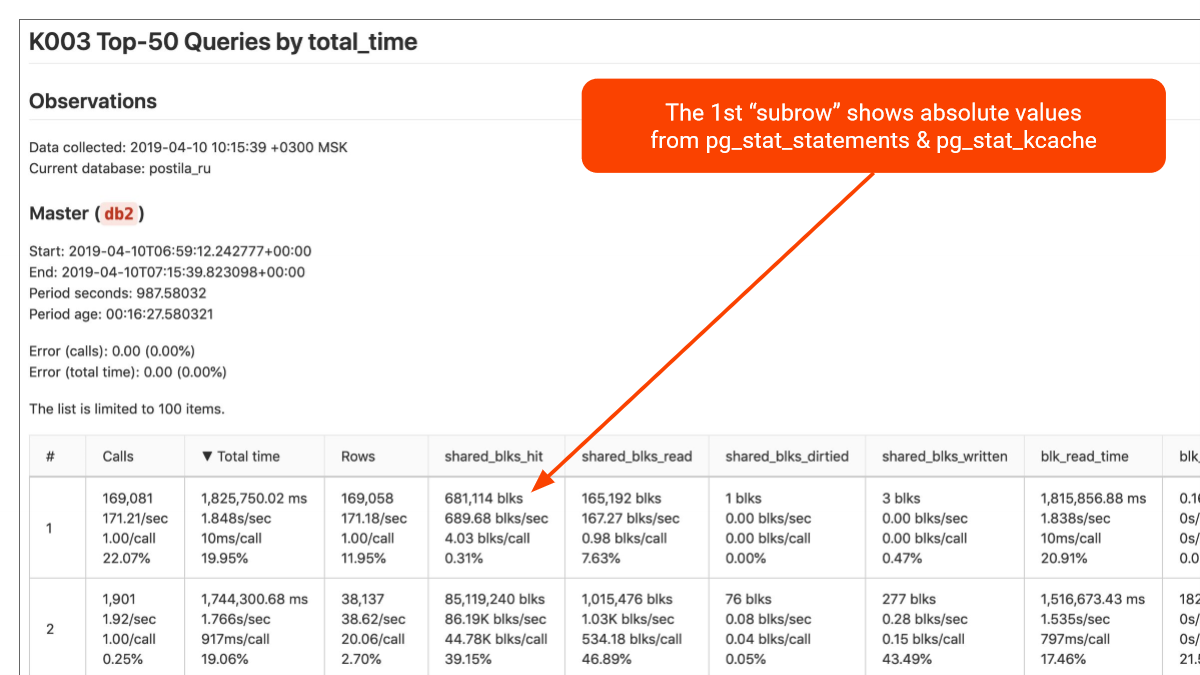
Чтобы эту проблему решить, есть еще pg_stat_kcache, дополняющий pg_stat_statements. И мы тогда можем увидеть, когда мы считываем с диска. Статистика накапливается, overhead небольшой — несколько процентов.
Все более-менее крупные проекты, которые я знаю, обязательно это используют.
И дальше мы имеем вот эти метрики. Мы их видим. Это у нас группа запросов. Здесь запрос сам не видно, но он где-то справа. Например, какой-то SELECT, INSERT.
Pg_stat_statements выкидывает параметры, т. е. SELECT * FROM TABLE WHERE id = 10, а будет написано id =$1 или знак вопроса, если более старая версия.
И дальше все это агрегируется. И мы знаем, что вот эта группа запросов насколько-то медленная.
И у нас есть главный параметр — это total time. Его в колонке видно и по нему сортировка.

И мы знаем, что за период наблюдения checkup нужно прогнать два раза, потому что нужны снапшоты, иначе у нас есть только абсолютные значения. Мы дельту высчитываем.
И после этого мы знаем, что за период наблюдения в 10&n
