Как быстро загрузить большую таблицу в Apache Ignite через Key-Value API

Некоторое время назад на горизонте возникла и начала набирать популярность платформа Apache Ignite. Вычисления in-memory — это скорость, а значит, скорость должна быть обеспечена на всех этапах работы, особенно при загрузке данных.
Под катом находится описание способа быстрой загрузки данных из реляционной таблицы в распределенный кластер Apache Ignite. Описана предобработка SQL query result set на клиентском узле кластера и распределение данных по кластеру с помощью задания map-reduce. Описаны кеши и соответствующие реляционные таблицы, показано, как создать пользовательский объект из строки таблицы и как применить ComputeTaskAdapter для быстрого размещения созданных объектов. Весь код полностью можно увидеть в репозитории FastDataLoad.
История вопроса
Этот текст — перевод на русский моего поста в In-Memory Computing Blog на сайте GridGain.
Итак, некая компания решает ускорить медленное приложение путем переноса вычислений в in-memory кластер. Исходные данные для вычислений находятся в MS SQL; результат вычислений нужно положить туда же. Кластер распределенный, поскольку данных много уже сейчас, производительность приложения на пределе и объем данных растет. Заданы жесткие ограничения по времени работы.
Прежде чем писать быстрый код для обработки данных, эти данные нужно быстро загрузить. Неистовый поиск в сети показывает явную нехватку примеров кода, которые можно масштабировать до таблиц размером десятки или сотни миллионов строк. Примеров, которые можно загрузить, скомпилировать и пройти по шагам в отладке. Это с одной стороны.
С другой стороны, документация Apache Ignite / GridGain, вебинары и митапы дают представление о внутреннем устройстве кластера. Методом проб и ошибок удается сделать загрузчик, учитывающий распределение данных по партициям. И когда в один прекрасный день начальство спрашивает «а сыграл ли твой козырный туз?», ответ — да, все получилось. Полученный код кажется некой самоделкой с привкусом внутренней архитектуры, но работает с достаточной скоростью.
Данные для загрузки (World Database)
Поскольку данных много, мы будем хранить записи в партиционированном виде и использовать data collocation, чтобы логически связанные значения хранились на одном и том же узле кластера. В качестве источника данных мы будем использовать файл world.sql из дистрибутива Apache Ignite.
Разделим его на три CSV файла в предположении, что каждый из них — это результат SQL запроса:
Рассмотрим загрузку записей countryCache из файла country.csv. Ключ countryCache — трехсимвольное поле code, тип ключа — String, значение — объект Country, созданный из остальных полей (name, continent, region).

Наивная загрузка
Поскольку опыта нет, то пляшем от печки — будем загружать так же, как в монолитное нераспределенное приложение. Будем создавать пользовательский объект Country для каждой строки таблицы и класть в кеш перед тем, как перейти к следующей строке. Для этого используем библиотеку org.h2.tools.Csv, которая умеет конвертировать файл CSV в java.sql.ResultSet. Эта библиотека уже присутствует на каждом узле Apache Ignite и загружать ее не надо, поскольку подсистема SQL построена на субд H2.
// define countryCache
IgniteCache cache = ignite.cache("countryCache");
try (ResultSet rs = new Csv().read(csvFileName, null, null)) {
while (rs.next()) {
String code = rs.getString("Code");
String name = rs.getString("Name");
String continent = rs.getString("Continent");
Country country = new Country(code,name,continent);
cache.put(code,country);
}
} Код замечательно работает для небольших таблиц на кластере из одного узла. Но, если подать таблицу в десять миллионов строк и добавить узлов в кластер, приложение начинает засыпать. Причем с ростом объема данных засыпает оно как-то по экспоненте.
Это все потому, что кеш распределен по узлам кластера и каждое изменение кеша должно быть синхронизировано между всеми узлами. Чтобы загружать быстро, надо учитывать внутреннее устройство кластера.
Попартиционная загрузка
Основа кластера Apache Ignite — распределенный кеш ключ-значение. Если объем хранимых данных велик, кеш создается в режиме PARTITIONED и каждая пара ключ-значение хранится в некоторой партиции (partition) на некотором узле кластера. Из соображений отказоустойчивости копия этой партиции может храниться еще и на другом узле; мы здесь для простоты будем считать, что копий нет. Чтобы определить расположение пары ключ-значение, кластер использует affinity function, которая определяет, в какой партиции будет находиться данная пара и на каком физическом узле кластера будет находиться эта партиция.
В нашем примере требуется обработать ResultSet на клиентском узле кластера и распределить данные по серверным узлам. Клиентский узел не хранит данные, поэтому распределение данных гарантированно будет происходить по сети. На рисунке показано взаимодействие клиентского узла с тремя серверными узлами.

Чтобы минимизировать сетевой трафик, мы предварительно сгруппируем загружаемые данные по партициям:
- для хранения предзагруженных данных создадим HashMap вида partition_number → key → Value
Map - для каждой строки данных создадим ключ и с помощью affinity function определим его partition_number. Вместо cache.put () для каждой строки положим пару ключ-значение в раздел HashMap с номером partition_number
try (ResultSet rs = new Csv().read(csvFileName, null, null)) { while (rs.next()) { String code = rs.getString("Code"); String name = rs.getString("Name"); String continent = rs.getString("Continent"); Country country = new Country(code,name,continent); result.computeIfAbsent(affinity.partition(key), k -> new HashMap<>()).put(code,country); } }
После группировки используем ComputeTaskAdapter в паре с ComputeJobAdapter. В нашем примере число заданий ComputeJobAdapter совпадает с числом партиций и равно 1024. Каждое задание содержит данные своей партиции и отправляется на тот узел кластера, где хранится партиция.
Результатом выполнения задания ComputeJobAdapter служит число добавленных в кеш записей. По завершении каждое задание возвращает результат на клиентский узел, который вычисляет общий итог.
Compute Task, вид изнутри
Согласно документации, «ComputeTaskAdapter initiates the simplified, in-memory, map-reduce process». Клиентский узел кластера сначала создает задания ComputeJobAdapter и выполняет map — определяет, на какой физический узел кластера отправится каждое задание. Затем результаты выполнения заданий возвращаются на клиентский узел и там выполняется reduce — вычисление общего числа добавленных записей.
Задание для узла данных (RenewLocalCacheJob)
В нашем примере партиция любого кеша наполняется данными на клиентском узле, заворачивается в объект RenewLocalCacheJob и отправляется по сети на нужный узел кластера. Там созданная партиция размещается в кеше целиком
targetCache.putAll(addend);После размещения RenewLocalCacheJob печатает partition_number и число добавленных записей.
Задание для клиентского узла (AbstractLoadTask)
Каждое задание загрузки (пакет loader) — наследник AbstractLoadTask. Задания отличаются именами извлекаемых полей и типами создаваемых пользовательских объектов. Загруженные данные могут предназначаться для кешей с ключами различных типов (примитивных либо пользовательских), поэтому AbstractLoadTask определен с параметром TargetCacheKeyType. Соответственно и предзагружаемый HashMap определен как
Map> result; В нашем примере только у countryCache ключ имеет примитивный тип String. Остальные кеши в качестве ключа используют пользовательские объекты. AbstractLoadTask определяет тип ключа параметром TargetCacheKeyType, а значение кеша и вовсе BinaryObject. Это все потому, что составной ключ — это пользовательский объект и работать с ним просто так на узлах данных не получается.
Почему BinaryObject вместо пользовательского объекта
Наша цель — положить в память узла кластера некоторое количество пользовательских объектов. Мы помним, что узел этот работает не только в другой JVM, но и на другом хосте где-то в сети. На этом узле class definition пользовательских объектов недоступен, он находится в JAR-файле на клиентском узле. Если мы определим кеш с типом Country
IgniteCache countryCache; и будем извлекать из него значение по ключу, то узел кластера попытается десериализовать объект, не найдет ничего на classpath и выдаст исключение ClassNotFound.
Есть два способа преодолеть эту трудность. Первый — обеспечить наличие классов на classpath, сам по себе достаточной элегантный:
- сделать JAR-файл с пользовательскими классами внутри;
- положить этот файл на classpath на каждом узле кластера;
- не забывать обновлять этот файл при каждом изменении любого из пользовательских классов;
- после обновления файла не забывать перезагружать узел.
Второй способ — использовать интерфейс BinaryObject для доступа к данным в их исходном (сериализованном) виде. В нашем примере это выглядит так:
- Кеш определяется в бинарном виде
IgniteCache - Сразу после создания пользовательский объект Country преобразуется в BinaryObject (см. код в LoadCountries.java)
Country country = new Country(code, name, .. ); BinaryObject binCountry = node.binary().toBinary(country); - Созданный бинарный объект помещается в предзагружаемый HashMap, который определяется с типом BinaryObject
Map
Предзагрузка целиком выполняется на клиентском узле, где есть определения всех пользовательских классов. На удаленные узлы данные отправляются в бинарном виде, определения классов не нужны, ClassNotFoundException не возникает.
Практическая часть. Запуск узлов данных.
Мы будем запускать кластер Apache Ignite в минимально достаточной конфигурации: два узла данных и один клиентский узел.
Узлы данных
Запускаются почти что из коробки с единственным изменением в файле default-config.xml — мы разрешаем передавать классы заданий по сети между узлами. Шаги для запуска узла данных:
- Установить GridGain CE по инструкции Installing Using ZIP Archive. На странице загрузки важно выбрать версию 8.7.10, поскольку код в репозитории FastDataLoad сделан имеенно для нее, а кластер из узлов разных версий собрать не получится;
- В папке {gridgain}\config открыть файл default-config.xml и добавить в него
строки - Открыть окно командной строки, перейти в папку {gridgain}\bin и запустить узел командой ignite.bat. В процессе тестирования оба узла кластера могут размещаться на одном хосте; для разработки и запуска на бою надо использовать разные машины;
- Открыть еще одно окно командной строки, повторить предыдущий шаг. Если в обоих окнах появилась строка наподобие вот этой, то все получилось
[08:40:04] Topology snapshot [ver=2, locNode=d52b1db3, servers=2, clients=0, state=ACTIVE, CPUs=8, offheap=3.2GB, heap=2.0GB]
Важно. Если все же нужно загрузить последнюю версию, например 8.7.25, придется указать номер версии в файле pom.xml
8.7.25 Иначе версии узлов данных и клиентского узла не совпадут и клиентский узел не сможет войти в кластер
class org.apache.ignite.spi.IgniteSpiException: Local node and remote node have different version numbers (node will not join, Ignite does not support rolling updates, so versions must be exactly the same) [locBuildVer=8.7.25, rmtBuildVer=8.7.10]Клиентский узел
Вся работа выполняется клиентским приложением, которое содержит определение кешей, пользовательские объекты и логику map-reduce. Приложение — это JAR-файл, который стартует клиентский узел кластера и запускает compute task для загрузки данных. Для демонстрации мы используем один хост Windows, для боевого запуска лучше использовать разные хосты Linux. Шаги для запуска клиентского узла:
Метод main () класса LoadApp создает пользовательский объект LoaderAgrument с названиями кеша и файла данных и преобразует его в бинарный формат. Далее бинарный объект используется как аргумент map-reduce задания LoadCountries.
LoadCountries создает для каждой партиции задание RenewLocalCacheJob и отправляет его по сети на соответствующий узел данных, где задание выполняется и выводит сообщение с номером обновленной партиции (номера партиций между узлами не пересекаются).
Узел данных #1

Узел данных #2

После этого клиентский узел суммирует возвращенные заданиями результаты и выводит общее число загруженных объектов
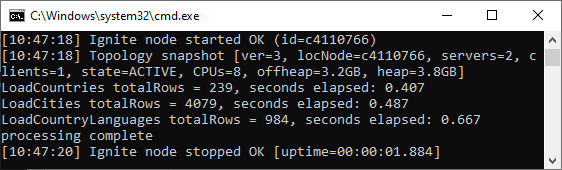
Файл country.csv загружен, ключи CountryCode и соответствующие значения собраны в партициях и каждая партиция размещена в памяти своего узла данных. Процесс повторяется для cityCache и countryLanguageCache; клиентское приложение выводит число объектов, время работы и завершается.
Заключение
Пару слов о скорости работы наивной и попартиционной загрузки.
Для больших таблиц наивный способ загрузки за разумное время не заканчивается вовсе. Попартиционный способ используется автором в реальной боевой эксплуатации и демонстрирует приемлемую скорость работы:
- свойства загружаемой таблицы (SQL Server Management Studio):
- число строк — 44 686 837;
- объем — 1.071 GB;
- время загрузки и предобработки данных на клиентском узле — 0H:1M:35S;
- время на создание заданий RenewLocalCacheJob и reduce результатов — 0H:0M:9S.
На распределение данных по кластеру времени тратится меньше, чем на выполнение SQL-запроса.
