Как не наступать на грабли в Go
Этот пост является версией моей же англоязычной статьи «How to avoid gotchas in Go», но слово gotcha не переводится на русский, поэтому я буду использовать это слово как без перевода, так и немного непрямой вариант — «наступать на грабли».
Gotcha — корректная конструкция системы, программы или языка программирования, которая работает, как описано, но, при этом, контринтуитивна и является причиной ошибок, поскольку её легко использовать неверно.
В языке Go есть несколько таких gotchas и есть немало хороших статей, которые их подробно описывают и разъясняют. Я считаю, что эти статьи очень важны, особенно для новичков в Go, поскольку регулярно вижу людей, попадающихся на те же грабли.
Но один вопрос меня мучал долгое время — почему я сам никогда не делал этих ошибок? Серьезно, самые популярные из них, вроде путаницы с nil-интерфейсом или непонятного результата при append ()-е слайса — в моей практике никогда не были проблемой. Каким-то образом мне повезло обойти эти подводные камни с первых дней своей работы с Go. Что же мне помогло?
И ответ оказался довольно прост. Я просто очень вовремя прочёл несколько хороших статей о внутреннем устройстве структур данных в Go и прочих деталях реализации. И этого, вполне поверхностного на самом деле, знания было достаточно, чтобы выработать некоторую интуицию и избегать этих подводных камней.
Давайте вернёмся к определению, «gotcha… это корректная конструкция… которая контринтуитивна…». В этом вся соль. У нас есть, на самом деле, два варианта:
- «починить» язык
- починить интуицию
Первый вариант, который будет по душе многим хабрачитателям, конечно же не вариант. В Go есть обещание обратной совместимости — язык уже меняться не будет, и это прекрасно — программы написанные в 2012-м компилируются сегодня последней версией Go без единого ворнинга. Кстати, в Go нет ворнингов :)
Второй же вариант будет правильнее назвать развить интуицию. Как только вы узнаете, как интерфейсы или слайсы работают изнутри, интуиция будет подсказывать правильнее и поможет избегать ошибок. Этот метод хорошо помог мне и, наверняка, поможет и другим. Поэтому я решил собрать эти базовые знания о внутренностях Go в один пост, чтобы помочь другим развить интуицию о том, как Go устроен изнутри.
Давайте начнем с базового понимания, как хранятся типы данных в памяти. Вот краткий перечень того, что мы изучим:
- Указатели
- Массивы
- Слайсы
- Добавление к слайсу (append)
- Интерфейсы
- Пустой интерфейс (interface{})
Указатели
Go, имея в генеалогическом дереве язык С, на самом деле довольно близок к железу. Если вы создаете переменную типа int64 (целочисленной значение 64-бита) вы точно можете быть уверены в том, сколько именно места она занимает в памяти, и всегда можете использовать unsafe.Sizeof (), чтобы узнать это для любого другого типа.
Я очень люблю использовать визуальное представление данных в памяти, чтобы «увидеть» размеры переменных, массивов или структур данных. Визуальный подход помогает быстрее понять масштабы, развить интуицию и наглядно оценивать даже такие вещи, как производительность.
Например, давайте начнём с простейших базовых типов в Go:
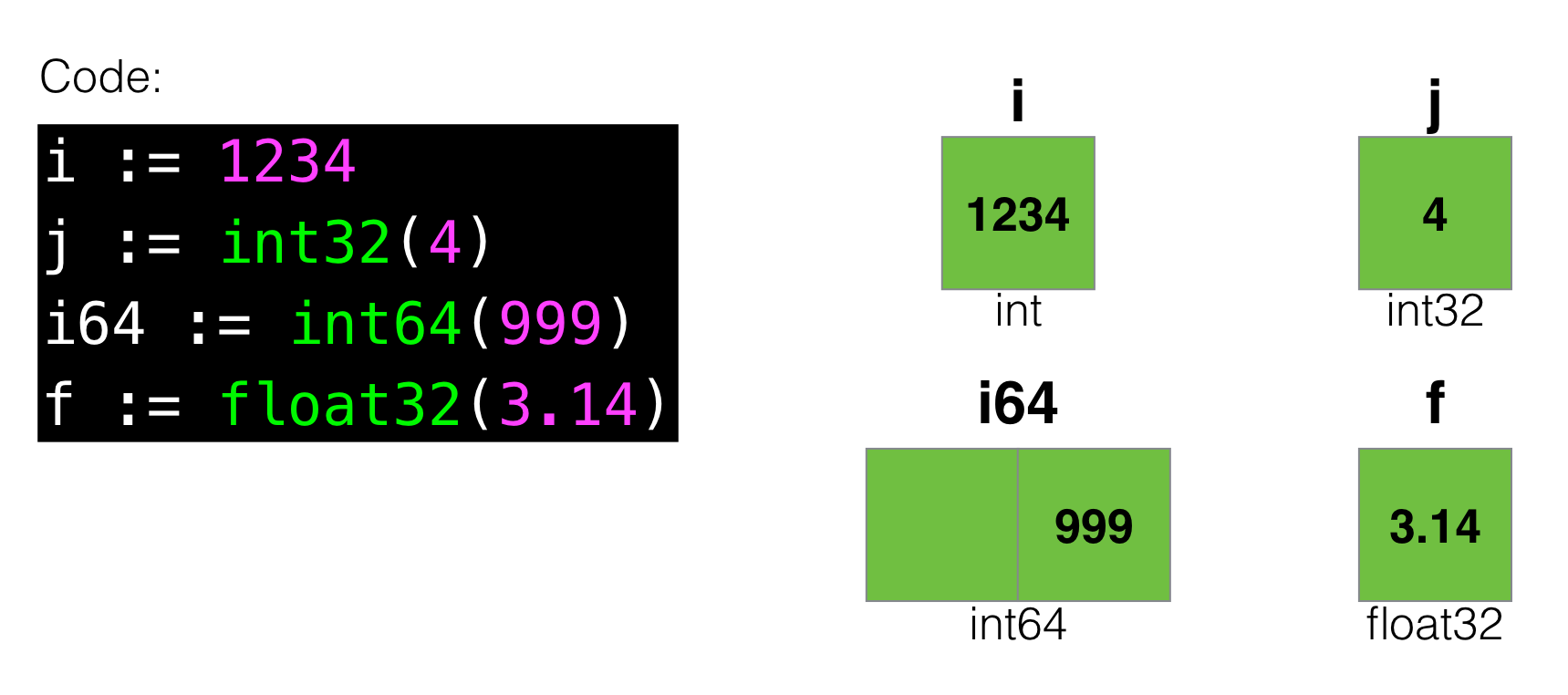
Скажем, в такой визуализации видно, что переменная типа int64 будет занимать в два раза больше «места», чем int32, а int занимает столько же, сколько int32 (подразумевая, что это 32-битная машина).
Указатели же выглядят чуть более сложно — по сути, это один блок памяти, который содержит адрес в памяти, указывающий на другой блок памяти, где лежат данные. Если вы слышите фразу «разыменовать указатель», то это означает «найти данные из блока памяти, на который указывает адрес в блоке памяти указателя». Можно представить это как-нибудь так:

Адрес в памяти обычно указывается в шестнадцатеричной форме, отсюда »0x…» на картинке. Но важный момент тут в том, что «блок памяти указателя» может быть в одном месте, а «данные, на которые указывает адрес» — совсем в другом. Нам это пригодится чуть дальше.
И тут мы подходим к одной из gotchas в Go, с которой сталкиваются люди, у которых не было опыта работы с указателями в других языках — это путаница в понимании что такое «передача по значению» параметров в функции. Как вы, наверняка знаете, в Go всё передаётся «по значению», тоесть буквально копируется. Давайте попробуем это визуализировать для функций, в которых параметр передаётся как есть и через указатель:

В первом случае мы копируем все эти блоки памяти — и, в реальности, их может быть запросто больше, чем 2, хоть 2 миллиона блоков, и они все будут копироваться, а это одна из самых дорогостоящих операций. Во втором же случае, мы копируем лишь один блок памяти — в котором хранится адрес в памяти — и это быстро и дешево. Впрочем, для небольших данных рекомендуется всё же передавать по значению, потому что у поинтеры создают дополнительную нагрузку на GC, и, в итоге оказываются более дорогими, но об этом как-нибудь в другой статье.
Но теперь, имея это наглядное представление, как передаются указатели в функцию, вы естественным образом можете «увидеть», что в первом случае изменяя переменную p в функции Foo(), вы будете работать с копией и не измените значение оригинальной переменной (p1), а втором — измените, поскольку указатель будет ссылаться на оригинальную переменную. Хотя и в том и другом случае, при передаче параметров происходит копирование данных.
Окей, разогрев окончен, давайте копнём глубже и посмотрим вещи чуть сложнее.
Массивы и слайсы
Слайсы поначалу принимают за обычный массив. Но это не так, и, на самом деле, это два разных типа в Go. Давайте сначала посмотрим на массивы.
Массивы
var arr [5]int
var arr [5]int{1,2,3,4,5}
var arr [...]int{1,2,3,4,5}Массив это просто последовательный набор блоков памяти и если мы посмотрим на исходники Go (src/runtime/malloc.go), то увидим, что создание массива это по сути просто выделение куска памяти нужного размера. Старый добрый malloc, только чуть умнее:
// newarray allocates an array of n elements of type typ.
func newarray(typ *_type, n int) unsafe.Pointer {
if n < 0 || uintptr(n) > maxSliceCap(typ.size) {
panic(plainError("runtime: allocation size out of range"))
}
return mallocgc(typ.size*uintptr(n), typ, true)
}Что это для нас означает? Это значит, что мы можем визуально представить массив просто как набор блоков памяти, расположенных один за другим:

Каждый элемент массива всегда инициализирован нулевым значением данного типа — 0 в данном случае массива из целых чисел длиной 5. Мы можем обращаться к ним по индексу и использовать встроенную функцию len(), чтобы узнать размер массива. Когда мы обращаемся к отдельному элементу массива по индексу и делаем что-то вроде этого:
var arr [5]int
arr[4] = 42То просто берем пятый (4+1) элемент и изменяем значение этого блока в памяти:

Окей, теперь разберёмся со слайсами.
Слайсы
На первый взгляд, они похожи на массивы. Ну вот прям очень похожи:
var foo []intНо если мы посмотрим на исходники Go (src/runtime/slice.go), то увидим, что слайс это, на самом деле, структура из трёх полей — указателя на массив, длины и вместимости (capacity):
type slice struct {
array unsafe.Pointer
len int
cap int
}Когда вы создаёте новый слайс, рантайм «под капотом» создаст новую переменную этого типа, с нулевым указателем (nil) и длиной и ёмкостью равными нулю. Это нулевое значение для спайса. Давайте попробуем визуализировать его:
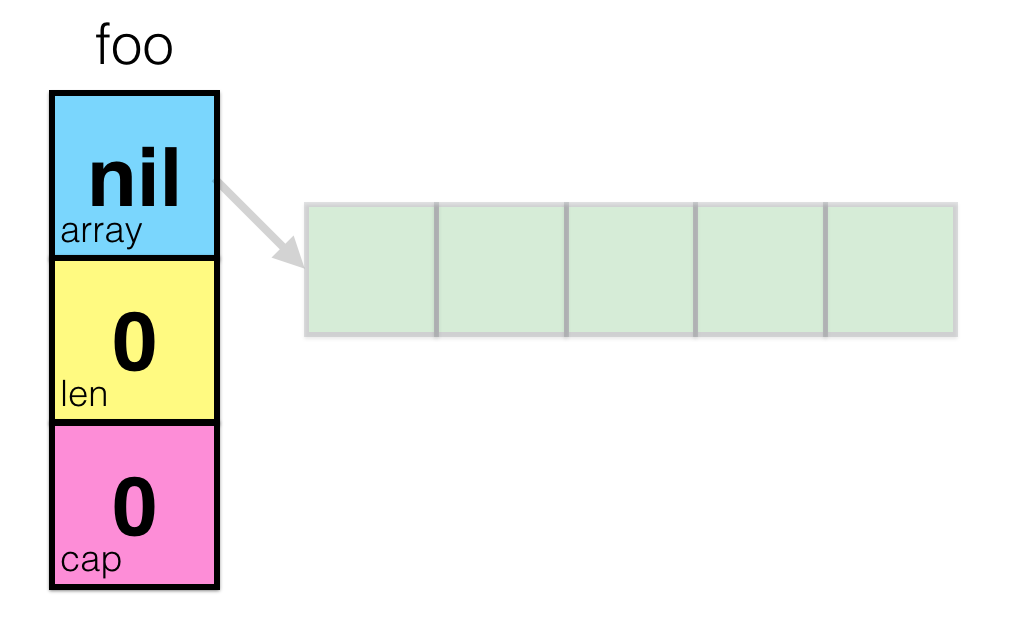
Это не очень интересно, поэтому давайте инициализируем слайс нужного нам размера с помощью встроенной команды make():
foo = make([]int, 5)Эта команда создаст сначала массив из 5 элементов (выделит память и заполнит их нулями), и установит значения len и cap в 5. Cap означает ёмкость и помогает зарезервировать место в памяти на будущее, чтобы избежать лишних операций выделения памяти при росте слайса. Можно использовать чуть более расширенную форму — make([]int, len, cap), чтобы указать ёмкость изначально. Чтобы уверенно работать со слайсами, важно понимать разницу между длиной и ёмкостью.
foo = make([]int, 3, 5)Давайте посмотрим на оба вызова:

Теперь, объединяя наши знания о том как устроены указатели, массивы и слайсы, давайте визуализируем, что происходит при вызове следующего кода:
foo = make([]int, 5)
foo[3] = 42
foo[4] = 100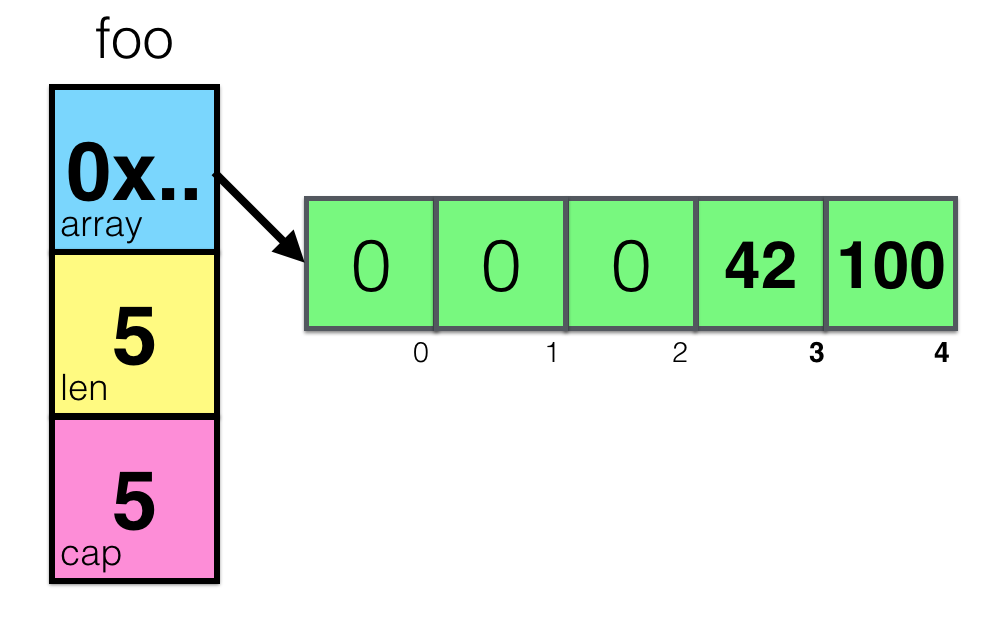
Это было легко. Но что будет, если мы создадим новый подслайс из foo и изменим какой-нибудь элемент? Давайте посмотрим:
foo = make([]int, 5)
foo[3] = 42
foo[4] = 100
bar := foo[1:4]
bar[1] = 99
Видно же? Модифицируя слайс bar, мы, на самом деле, изменяем массив, но это тот же самый массив, на который указывает и слайс foo. И это, на самом деле, реальная штука — вы можете написать код вроде этого:
var digitRegexp = regexp.MustCompile("[0-9]+")
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return digitRegexp.Find(b)
}И, скажем, считав 10МБ данных в слайс из файла, найти 3 байта, содержащих цифры, но возвращать вы будете слайс, который ссылается массив размером 10МБ!
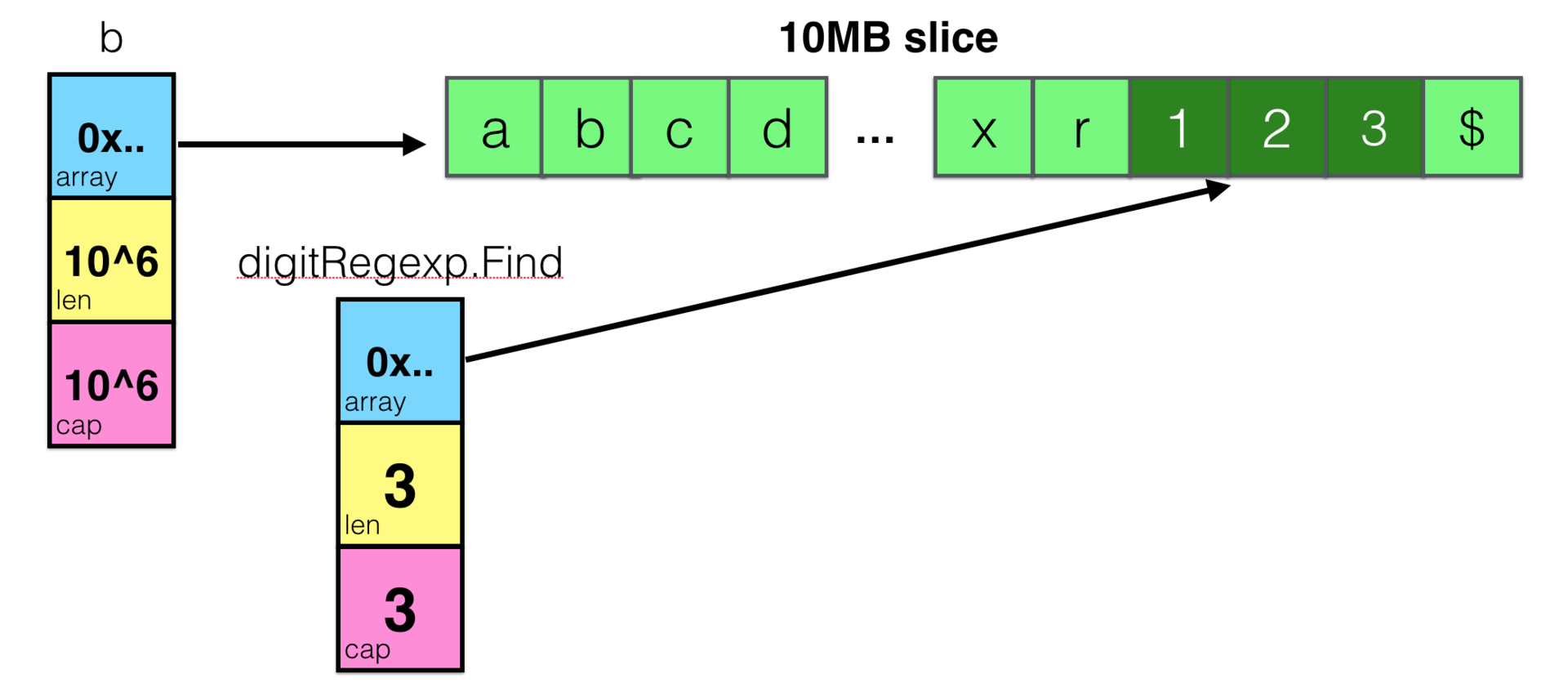
И это одна из самых часто упоминаемых gotchas в Go. Но теперь, наглядно понимая как это устроено, вам будет тяжело сделать такую ошибку.
Добавление к слайсу (append)
Следом за хитрой ошибкой со слайсами, идёт не очень очевидное поведение встроенной функции append(). Она, в принципе, делает одну простую операцию — добавляет к нему элементы. Но под капотом там делаются довольно сложные манипуляции, чтобы выделять память только при необходимости и делать это эффективно.
Взглянем на следующий код:
a := make([]int, 32)
a = append(a, 1)Он создаёт новый слайс из 32 целых чисел и добавляет к нему ещё один, 33-й элемент.
Помните про cap — ёмкость слайсов? Ёмкость означает количество выделенного места для массива. Функция append() проверяет, достаточно ли у слайса места, чтобы добавить туда ещё элемент, и если нет, то выделяет больше памяти. Выделение памяти это всегда дорогая операция, поэтому append() пытается оптимизировать это, и запрашивает в данном случае памяти не для одной переменной, а для ещё 32х — в два раза больше, чем начальный размер. Выделение памяти пачкой один раз дешевле, чем много раз по кусочкам.
Неочевидная штука тут в том, что по различным причинам, выделение памяти обычно означает выделение её по другому адресу и перемещение данных из старого места в новое. Это означает, что адрес массива, на который ссылается слайс также изменится! Давайте визуализируем это:
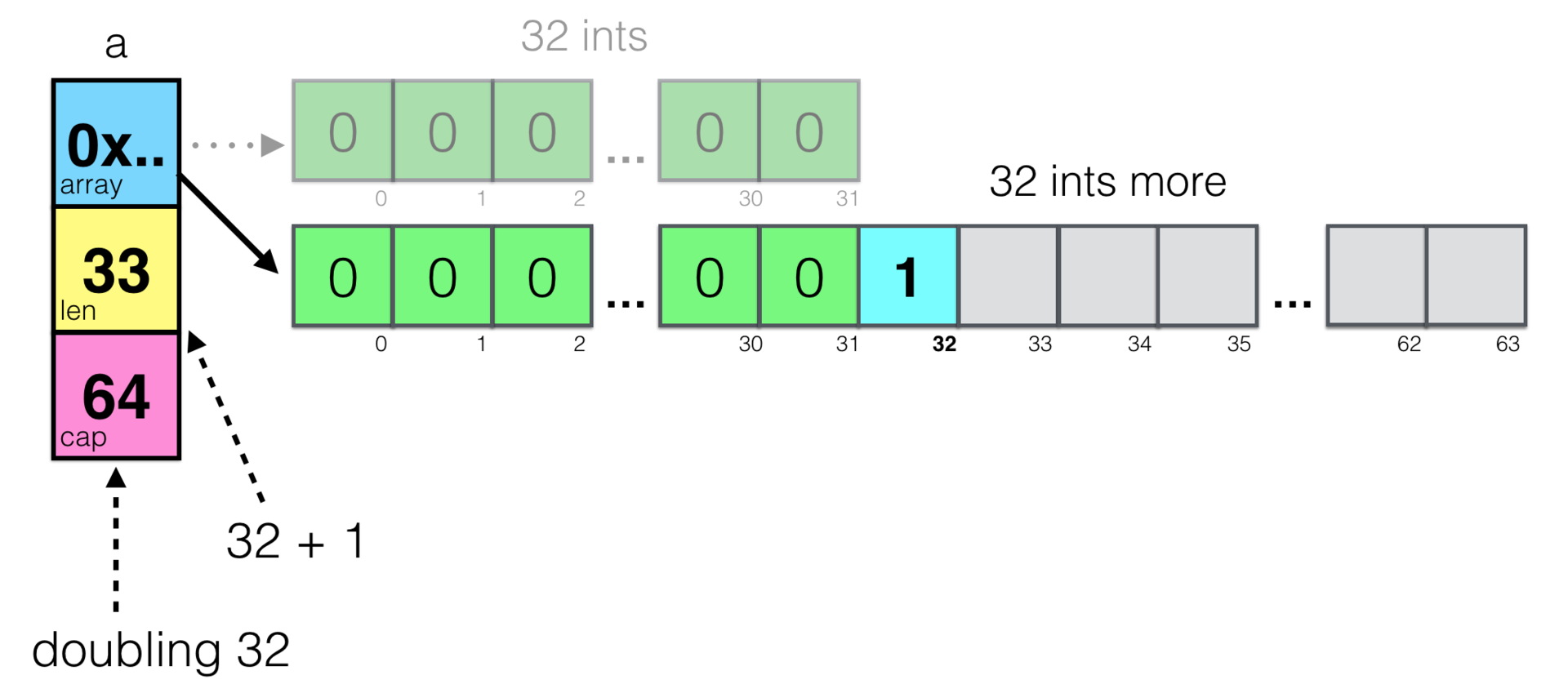
Легко увидеть два массива — старый и новый. Вроде бы ничего сложного, и сборщик мусора просто освободит место, занимаемое старым массивом при следующем проходе. Но это, на самом деле, одна из тех самых gotchas со слайсами. Что будет если, мы сделаем подслайс b, затем увеличим слайс a, подразумевая, что они используют один и тот же массив?
a := make([]int, 32)
b := a[1:16]
a = append(a, 1)
a[2] = 42Мы получим вот это:

Именно так, мы получим два различных массива, и два слайса будут указывать на совершенно разные участки памяти! И это, мягко говоря, довольно контринтуитивно, согласитесь. Поэтому, как правило, если вы вы работаете с append() и подслайсами — будьте осторожны и имейте ввиду эту особенность.
К слову, append() увеличивает слайс удвоением только до 1024 байт, а затем начинает использовать другой подход — так называемые «классы размеров памяти», которые гарантируют, что будет выделяться не более ~12.5%. Выделять 64 байта для массива на 32 байта это нормально, но если слайс размером 4ГБ, то выделять ещё 4ГБ даже если мы хотим добавить лишь один элемент — это чересчур дорого.
Интерфейсы
Окей, интерфейсы, наверное, самая непонятная штука в Go. Обычно проходит какое-то время, прежде чем понимание укладывается в голове, особенно после тяжелых последствий долгой работы с классами в других языках. И одна из самых популярных проблем это понимание nil интерфейса.
Как обычно, давайте обратимся к исходному коду Go. Что из себя представляет интерфейс? Это обычная структура из двух полей, вот её определение (src/runtime/runtime2.go):
type iface struct {
tab *itab
data unsafe.Pointer
}itab означает interface table и тоже является структурой, в которой хранится дополнительная информация об интерфейсе и базовом типе:
type itab struct {
inter *interfacetype
_type *_type
link *itab
bad int32
unused int32
fun [1]uintptr // variable sized
}Мы сейчас не будем углубляться в то, как работает приведение типа в интерфейсах, но что важно понимать, что по своей сути интерфейс это всего лишь набор данных о типах (интерфейса и типа переменной внутри него) и указатель на, собственно, саму переменную со статическим (конкретным) типом (поле data в iface). Давайте посмотрим, как это выглядит и определим переменную err интерфейсного типа error:
var err error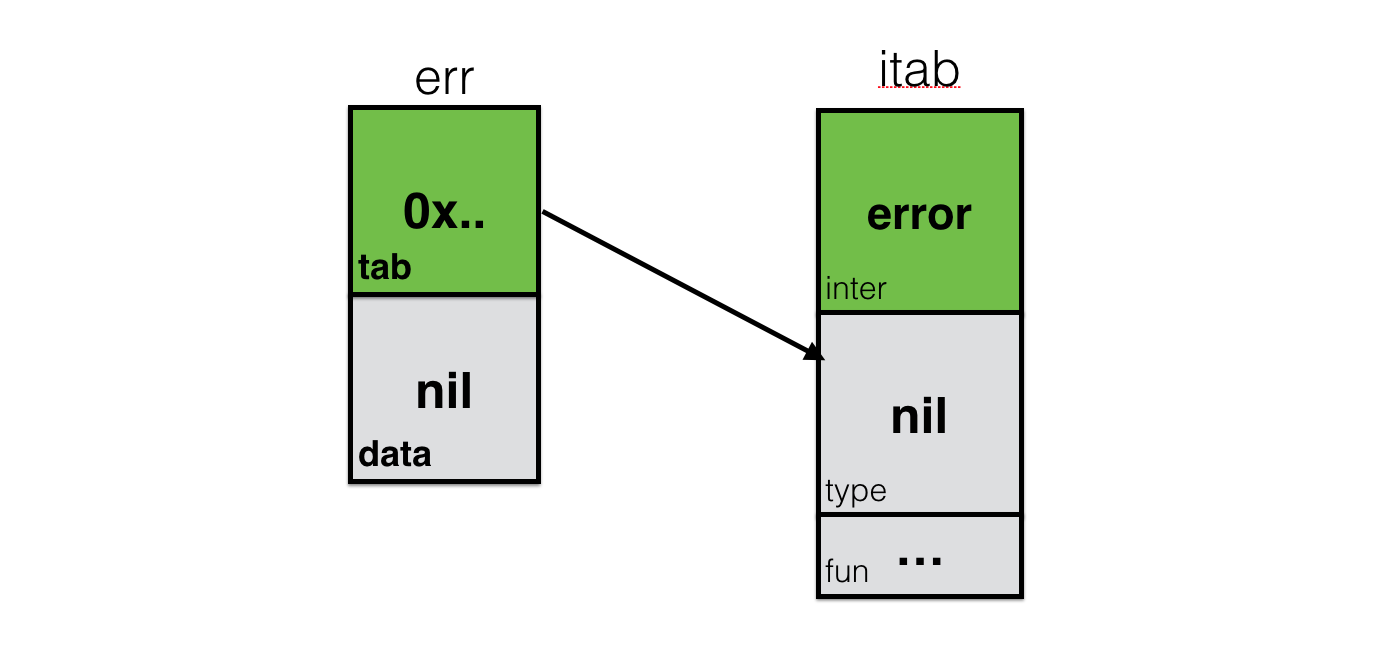
То, что мы видим на этой визуализации — это нулевой интерфейс (nil interface). Когда мы возвращаем nil в функции, возвращающей error, мы возвращаем именно вот этот объект. В нём хранится информация про сам интерфейс (itab.inter), но поля data и itab.type пустые — равны nil. Сравнение этого объекта с nil вернёт true в условии if err == nil {}.
func foo() error {
var err error // nil
return err
}
err := foo()
if err == nil {...} // trueТеперь, взгляните на вот этот случай, который также является известной gotcha в Go:
func foo() error {
var err *os.PathError // nil
return err
}
err := foo()
if err == nil {...} // falseЭти два куска кода очень похожи, если вы не знаете, что из себя представляет интерфейс. Но давайте посмотрим, как выглядит интерфейс error, в который «завернута» переменная типа *os.PathError:

Мы чётко видим тут саму переменную типа *os.PathError — это вот кусок памяти, в котором записано nil, потому что это нулевое значение для любого указателя. Но тот объект, что мы возвращаем из функции foo() — это уже более сложная структура, в которой хранится не только информация об интерфейсе, но и информация о типе переменной, и адрес в памяти на блок, в котором лежит nil указатель. Чувствуете разницу?
В обоих случаях мы как бы видим nil, но есть большая разница между «интерфейс с переменной внутри, чьё значение равно nil» и «интерфейс без переменной внутри». Теперь, понимая эту разницу, попробуйте спутать вот эти два примера:

Теперь вам должно быть сложно натолкнуться на такую проблему в вашем коде.
Пустой интерфейс (empty interface)
Несколько слов о так называемом пустом интерфейсе — interface{}. В исходниках Go он реализован отдельной структурой — eface (src/runtime/malloc.go):
type eface struct {
_type *_type
data unsafe.Pointer
}Легко заметить, что эта структура похожа на iface, но в ней нет таблицы интерфейса (itab). Что логично, потому что, по определению, любой статический тип удовлетворяет пустому интерфейсу. Поэтому, когда вы «заворачиваете» какую-либо переменную — явно или неявно (передавая, как аргумент или возвращая из функции, например) — в interface{}, вы на самом деле работаете с вот этой структурой.
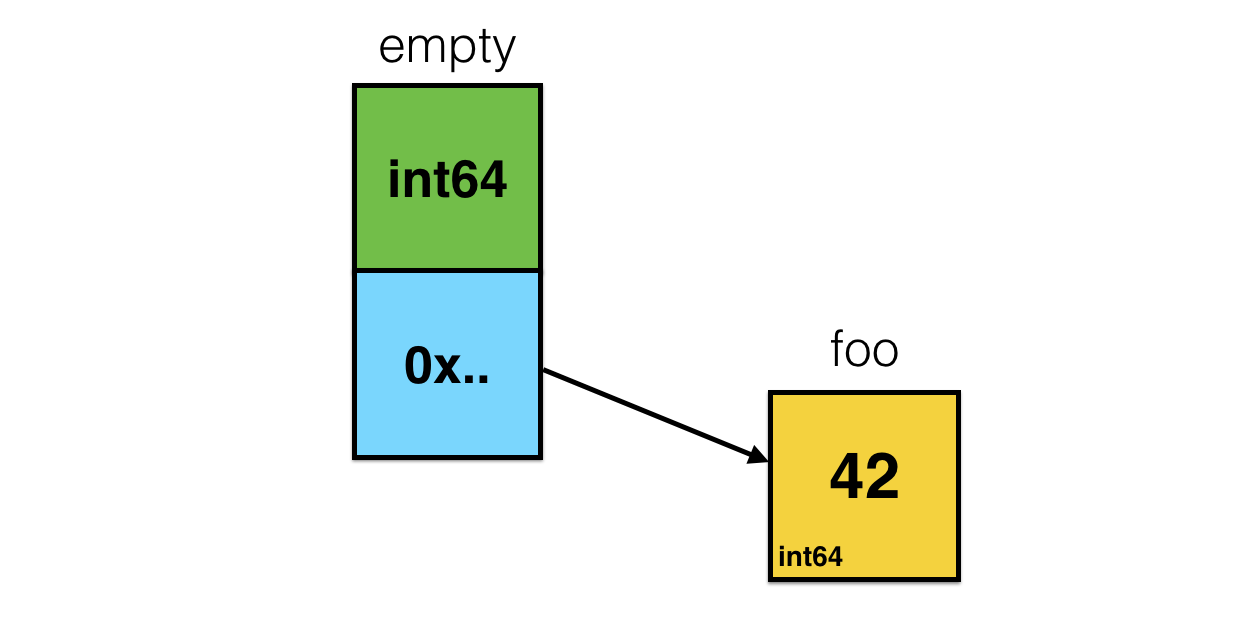
func foo() interface{} {
foo := int64(42)
return foo
}
Одна из известных непоняток с пустым интерфейсом заключается в том, что нельзя одним махом привести слайс конкретных типов к слайсу интерфейсов. Если вы напишете что-то вроде такого:
func foo() []interface{} {
return []int{1,2,3}
}Комплиятор вполне недвусмысленно ругнётся:
$ go build
cannot use []int literal (type []int) as type []interface {} in return argumentПоначалу это сбивает с толку. Мол, что за дела — я могу привести одну переменную любого типа в пустой интерфейс, почему же нельзя сделать тоже самое со слайсом? Но, когда вы знаете, что из себя представляет пустой интерфейс и как устроены слайсы, то вы должны интуитивно понять, что это «приведение слайса» на самом деле — довольно дорогая операция, которая будет подразумевать проход по всей длине слайса и выделение памяти прямо пропорционального количеству элементов. А, поскольку один из принципов в Go это — хотите сделать что-то дорогое — делайте это явно, то такая конвертация отдана на откуп программисту.
Давайте попробуем визуализировать, что собой представляет приведение []int в []interface{}:
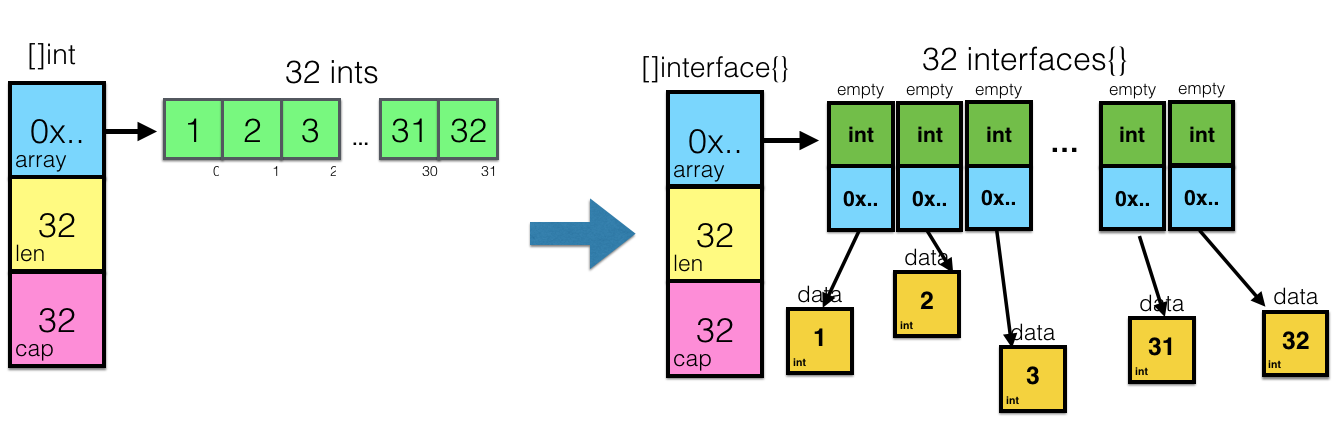
Надеюсь, теперь этот момент имеет смысл и для вас.
Заключение
Безусловно, не все gotchas и непонятки языка можно решить, углубившись во внутренности реализации. Некоторые из них являются просто разницей между старым и новым опытом, а он у нас всех различен. И всё же, наиболее популярные из них такой подход помогает обойти. Надеюсь этот пост поможет вам глубже разобраться в том, что происходит в ваших программах и как Go устроен под капотом. Go это ваш друг, и знать его чуть лучше всегда будет на пользу.
Если вам интересно почитать больше о внутренностях Go, вот небольшая подборка статей, которые помогли в своё время мне:
- Go Data Structures
- Go Data Structures: Interfaces
- Go Slices: usage and internals
- Gopher Puzzlers
Ну, и конечно, как же без этих ресурсов :)
- Исходники Go
- Effective Go
- Спецификация Go
Удачного кодинга!
