Как научить телефон видеть красоту

Недавно я читал книгу о математике и о красоте людей и задумался о том, что еще десятилетие назад представление о том, как понять, что такое красота человека были достаточно примитивными. Рассуждения о том, какое лицо считается красивым с точки зрения математики сводились к тому, что оно должно быть симметричным. Также со времен эпохи возрождения были попытки описать красивые лица при помощи соотношений между расстояниями в каких-то точках на лице и показать, например, что у красивых лиц какое-то отношение близко к золотому сечению. Подобные идеи о расположении точек сейчас используются как один из способов идентификации лиц (face landmarks search). Однако как показывает опыт, если не ограничивать набор признаков положением специфичных точек на лице, можно допиться лучших результатов в целом ряде задач, включая определение возраста, пола или даже сексуальной ориентации. Уже тут видно, что острым может стоять вопрос этики публикации результатов таких исследований.
Тема красоты людей и ее оценки тоже может быть этически неоднозначной. Многие из моих знакомых при разработке приложения отказывались от того, чтобы я использовал их фото для тестов, ну или просто не хотели знать результата (забавно, что отказывались узнать результаты в основном девушки). Также цель автоматизации оценки красоты может поднять и интересные философские вопросы. В какой мере понятие красоты обусловлено культурой? насколько верно, что «Красота в глазах смотрящего»? Возможно ли вообще выделить объективные признаки красоты?
Чтобы ответить на эти вопросы нужно хорошо изучить статистические данные об оценках одних людей другими. Я попытался сконструировать и обучить нейросетевую модель, которая бы оценивала красоту, а также запустить ее на телефоне под управлением android.
Часть 0. Pipeline
Для того, чтобы понимать как дальнейшие шаги связаны друг с другом, я нарисовал схему проекта:
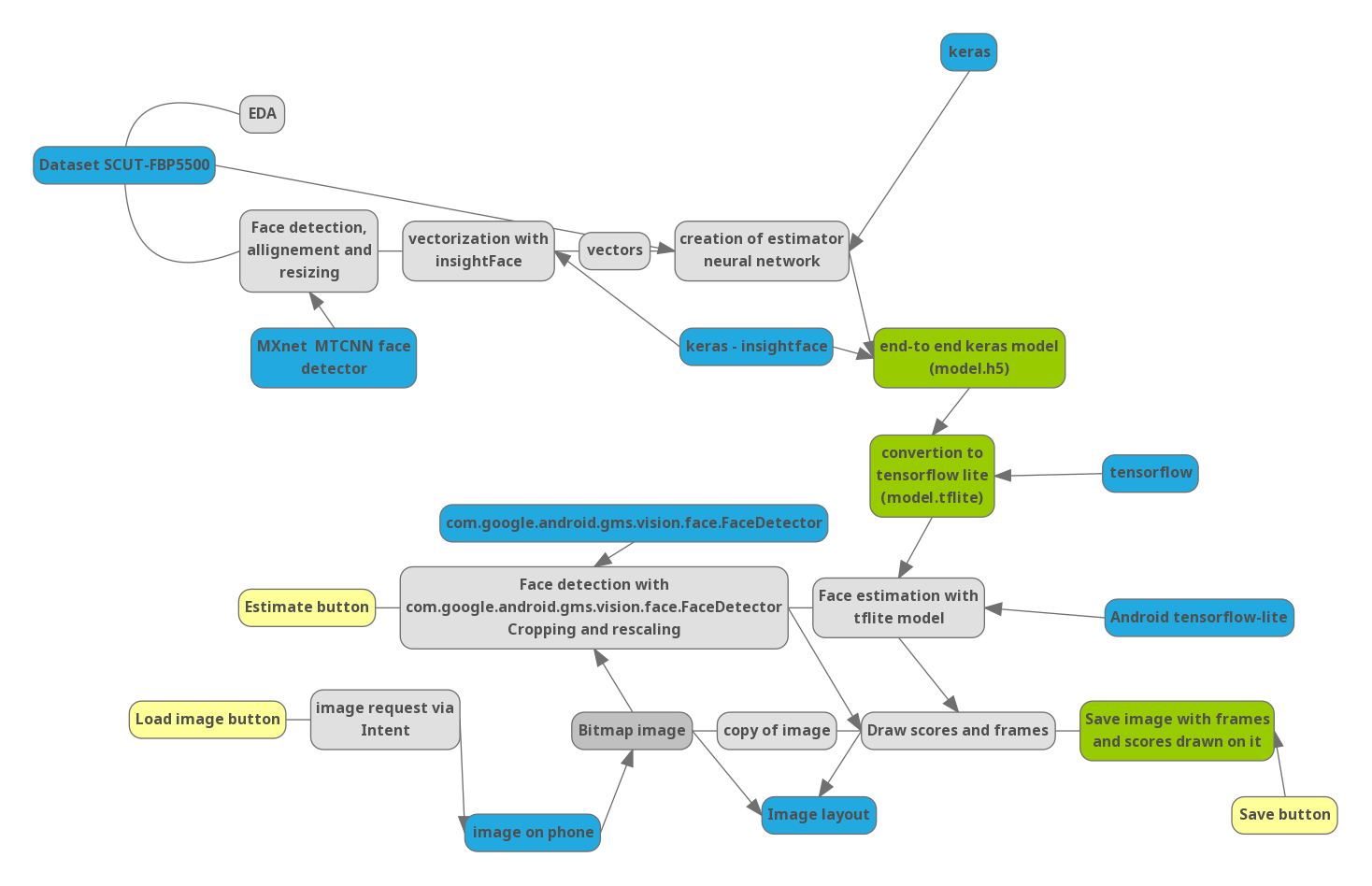
Синий — важные библиотеки и внешние данные. Желтый — элементы управления в приложении.
Часть 1. Python
Так как оценка красоты достаточно деликатная тема, в публичном доступе не очень много датасетов, содержащих фотографии с оценкой (уверен, что сервисы онлайн знакомств типа тиндера обладают гораздо большими наборами статистических данных). Мной была найдена база данных, собранная в одном из университетов Китая, содержащей 5500 фотографий, оцененных каждая 7 оценщиками из числа китайских студентов. Из 5500 фотографий 2000 — Азиатские мужчины (AM), 2000- Азиатские женщины (AF) и по 750 европиоидных мужчин (CM) и женщин (CF).
Прочтем данные с помощью модуля Python pandas и одним глазком взглянем на данные. Распределение по оценкам для различных полов и рас:
import pandas as pd
import matplotlib.pyplot as plt
ratingDS=pd.read_excel('../input/faces-scut/scut-fbp5500_v2/SCUT-FBP5500_v2/All_Ratings.xlsx')
Answer=ratingDS.groupby('Filename').mean()['Rating']
ratingDS['race']=ratingDS['Filename'].apply(lambda x:x[:2])
fig, ax = plt.subplots(2, 2, sharex='col')
for i, race in enumerate(['CF','CM','AF','AM']):
sbp=ax[i%2,i//2]
ratingDS[ratingDS['race']==race].groupby('Filename')['Rating'].mean().hist(alpha=0.5, bins=20,label=race,grid=False,rwidth=0.9,ax=sbp)
sbp.set_title(race)
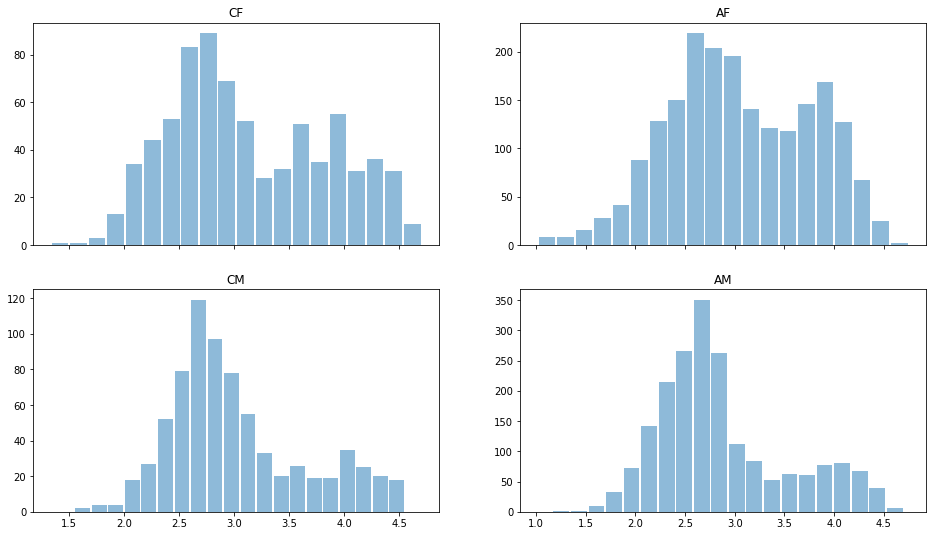
Видно, что в целом мужчин считают менее красивыми, чем женщин, распределения бимодальны — есть те. кого считают красивыми и «средние». Низких оценок почти нет, поэтому данные можно было бы и перенормировать. Но оставим их пока как есть.
Посмотрим на среднеквадратичное отклонение в оценках:
ratingDS.groupby('Filename')['Rating'].std().mean()
Оно составляет 0,64, что означает отличие в оценках разных оценщиков менее 1 балла из 5, что говорит о единодушии в оценках красоты. Можно обосновано сказать, что «красота НЕ в глазах смотрящего». При усреднении можно надежно использовать данные для обучения модели и не переживать о принципиальной невозможности программной оценки.
Однако несмотря на малое значение среднеквадратичного отклонения оценки, мнение некоторых оценщиков может сильно отличаться от «обычного». Давайте построим распределение отличия оценки от медианной:
R2=ratingDS.join(ratingDS.groupby('Filename')['Rating'].median(), on='Filename', how='inner',rsuffix =' median')
R2['ratingdiff']=(R2['Rating median']-R2['Rating']).astype(int)
print(set(R2['ratingdiff']))
R2['ratingdiff'].hist(label='difference of raings',bins=[-3.5,-2.5,-1.5,-0.5,0.5,1.5,2.5,3.5,4.5],grid=False,rwidth=0.5)
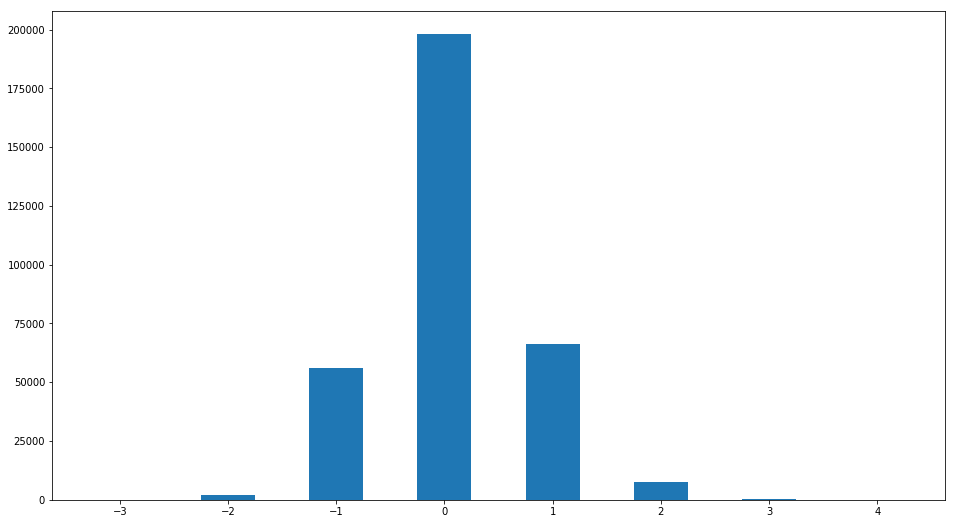
Обнаруживается интересная закономерность. Людей, оценка которых отличается от медианной более, чем на 1 балл
len(R2[R2['ratingdiff'].abs()>1])/len(R2)
0.029433333333333332
Менее 3%. То есть опять подтверждается поразительное единодушие в вопросах оценки красоты.
Создадим таблицу с необходимыми средними оценками
Answer=ratingDS.groupby('Filename').mean()['Rating']
Наша база данных невелика; кроме того на всех фотографиях присутствуют в основном изображения анфас, а мне хотелось бы надежного результата для любого положения лица. Для решения задач с небольшим количеством данных часто используется методика transfer learning — использование предобученных для схожих задач моделей и их модификация. Близкой к моей задаче является задача распознавания лиц. Она обычно решается трехэтапным образом.
1. Происходит детекция лица на изображении и его масштабирование.
2. При помощи сверточной нейросети происходит перевод изображения лица в вектор признаков, причем свойства такого преобразование таковы, что преобразование инвариантно относительно поворота лица, изменения прически. проявления эмоций и любых временных изображений. Обучение такой сети сама по себе интересная задача, которой можно писать долго. Кроме того постоянно появляются новые разработки по улучшению этого преобразования для улучшения алгоритмов массовой слежки и идентификации. Оптимизируют как архитектуру сети, так и способ обучения (пример triplet loss -cosface-arcface loss).
3. Сравнение вектора признаков с теми, что хранятся в базе данных.
Для нашей задачи я использовал готовые решения 1–2 пунктов. Задача детекции лиц решена в целом многими способами, более того почти на любом мобильном устройстве есть детекторы лиц (на Android входят в стандартный пакет GooglePlay services), которые используются для фокусировки на лицах при фотографировании. Что касается перевода лиц в векторную форму, то тут есть один неочевидный тонкий момент. Дело в том, что признаки. извлеченные для решения задачи распознавания — характерны для человека, но они могут вовсе не коррелировать с красотой. более того. эти признаки из-за особенностей сверточных нейросетей в основном локальны, и в целом это может вызывать множество проблем (Single pixel attack). Тем не менее, я обнаружил что результаты сильно зависят от размерности вектора и если 128 признаков не хватает для определения красоты, 512 бывает достаточно. Исходя из этого, была выбрана предобученная сеть insightFace на основе Resnet. В качестве фреймворка для машинного обучения также будем использовать keras.
Подробный код для загрузки предобученных моделей можно посмотреть тут
model=LResNet100E_IR()
В качестве детектора лиц для препроцессинга использовался детектор лиц mtcnn
detector = MtcnnDetector(model_folder=mtcnn_path, ctx=ctx, num_worker=1, accurate_landmark = True, threshold=det_threshold)
Выравниваем, обрезаем и векторизуем изображения из датасета:
imgpath='../input/faces-scut/scut-fbp5500_v2/SCUT-FBP5500_v2/Images/'
# Создадим список векторов
facevecs=[]
for name in tqdm.tqdm(Answer.index):
# откроем изображение
img1 = cv2.imread(imgpath+name)
# найдем, выровняем и обрежем лицо
pre1 = np.moveaxis(get_input(detector,img1),0,-1)
#получим вектор
vec = model.predict(np.stack([pre1]))
#добавим к списку
facevecs.append(vec)
Подготовим данные -разобьём на тренировочные (их 90%, на них будем учиться) и валидационные (на них будем проверять работу модели) вектора. Данные нормируем на диапазон 0–1.
X=np.stack(facevecs)[:,0,:]
Y=(Answer[:])/5
Indicies=np.arange(len(Answer))
X,Y,Indicies=sklearn.utils.shuffle(X,Y,Indicies)
Xtrain=X[:int(len(facevecs)*0.9)]
Ytrain=Y[:int(len(facevecs)*0.9)]
Indtrain=Indicies[:int(len(facevecs)*0.9)]
Xval=X[int(len(facevecs)*0.9):]
Yval=Y[int(len(facevecs)*0.9):]
Indval=Indicies[int(len(facevecs)*0.9):]
Теперь перейдем к модели. описывающей красоту.
def Createheadmodel():
inp=keras.layers.Input((512,))
x=keras.layers.Dense(32,activation='elu')(inp)
x=keras.layers.Dropout(0.1)(x)
out=keras.layers.Dense(1,activation='hard_sigmoid',use_bias=False,kernel_initializer=keras.initializers.Ones())(x)
model=keras.models.Model(input=inp,output=out)
model.layers[-1].trainable=False
model.compile(optimizer=keras.optimizers.Adam(lr=0.0001), loss='mse')
return model
modelhead=Createheadmodel()
Эта модель — однослойная полносвязная нейросеть с 32 нейронами и 512 входными узлами — одна из простейших архитектур, которая, тем не менее, неплохо обучается:
hist=modelhead.fit(Xtrain,Ytrain,
epochs=4000,
batch_size=5000,
validation_data=(Xval,Yval)
)
4950/4950 [==============================] — 0s 3us/step — loss: 0.0069 — val_loss: 0.0071
Построим кривые обучения
plt.plot(hist.history['loss'][100:], label='loss')
plt.plot(hist.history['val_loss'][100:],label='validation_loss')
plt.legend(bbox_to_anchor=(0.95, 0.95), loc='upper right', borderaxespad=0.)
Видим, что loss (средний квадрат отклонения) составляет 0,0071 на валидационных данных, следовательно СКО=0,084 или 0,42 балла по пятибальной шкале, что меньше разброса в оценках, даваемого людьми (0,6 баллов). Наша модель работает.
Для визуализации того, насколько модель работает можно использовать диаграмму рассеяния — для каждого фото из валидационных данных построим точку, где одна из координат соответствует среднему рейтингу лица, а вторая — среднему предсказанному рейтингу:
Answer2=Answer.to_frame()[:5500]
Answer2['ans']=0
Answer2['race']=Answer2.index
Answer2['race']=Answer2['race'].apply(lambda x: x[:2])
Answer2['ans']=modelhead.predict(np.stack(facevecs)[:,0,:])*5
xy=np.array(Answer2.iloc[Indval][['ans','Rating']])
plt.scatter(xy[:,1],xy[:,0])

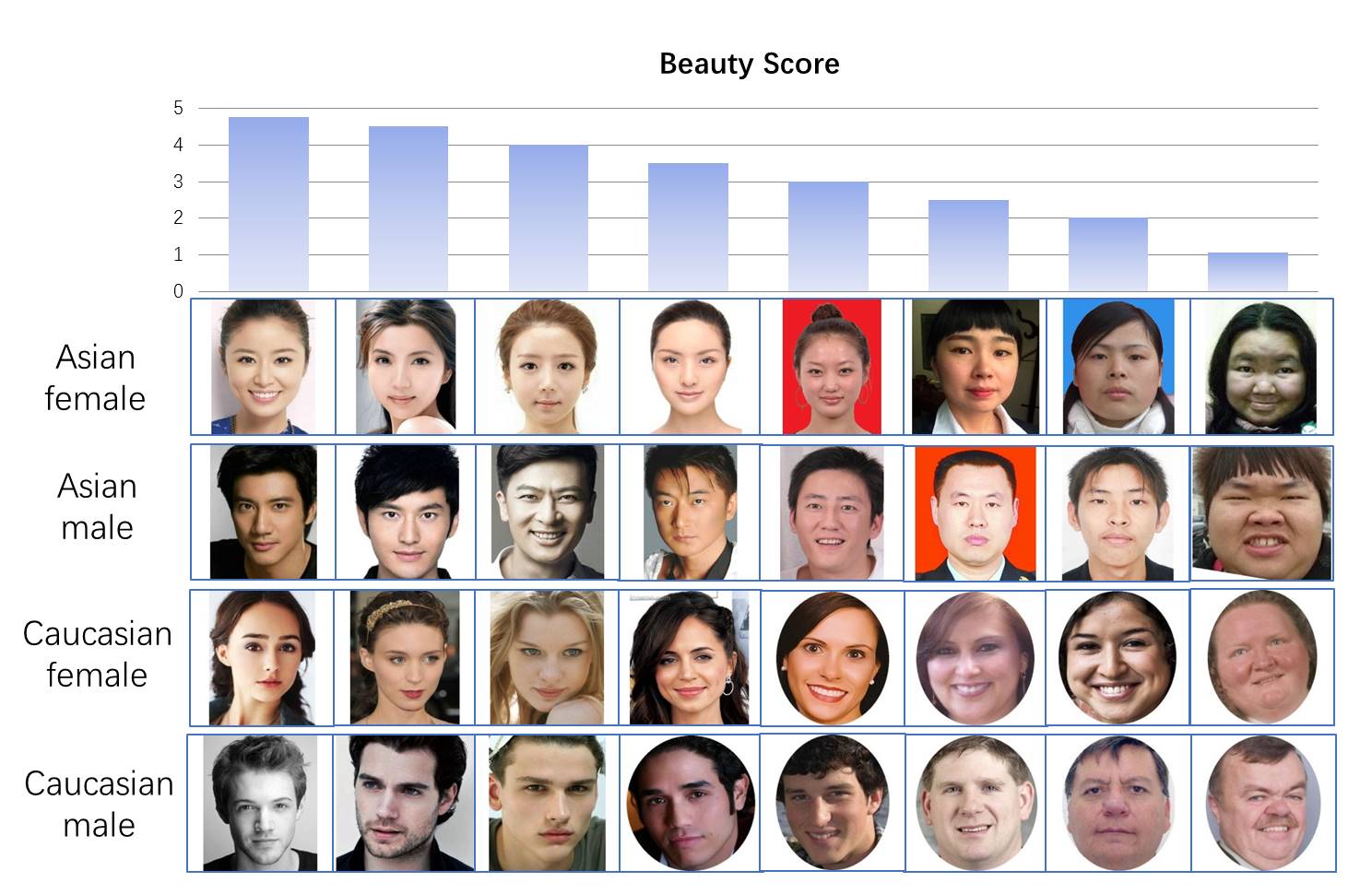
Ось Y- предсказанные моделью значения, ось X — средние значения оценок людьми. Видим высокую корреляцию (диаграмма вытянута вдоль диагонали). Можно также проверить наши результаты визуально — возьмем лица каждой из категорий с предсказанными оценками от 1 до 5
import matplotlib.image as mpimg
f, axarr = plt.subplots(4,5,figsize=(10, 10))
for i, race in enumerate(['AF','CF', "AM", 'CM']):
for rating in range(1,6):
#axarr[i,rating-1].axis('off')
axarr[i,rating-1].tick_params(# changes apply to the x-axis
which='both', # both major and minor ticks are affected
bottom=False, # ticks along the bottom edge are off
top=False, # ticks along the top edge are off
right=False,
left=False,
labelbottom=False,
labelleft=False
)
picname=(Answer2[Answer2['race']==race]['ans']-rating).abs().argmin()
axarr[i,rating-1].set_xlabel(Answer2.loc[picname]['ans'])
axarr[i,rating-1].imshow(mpimg.imread(imgpath+picname))

Видим, что результат с сортировкой по красоте выглядит разумным.
Теперь создадим полную модель, в которой на вход подаем лицо, на выходе получаем оценку от 0 до 1 и конвертируем ее в формат tflite, подходящий для телефона
import tensorflow as tf
finmodel=Model(input=model.input, output=modelhead(model.output))
finmodel.save('finmodel.h5')
converter = tf.lite.TFLiteConverter.from_keras_model_file('finmodel.h5')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
open ("modelquant.tflite" , "wb").write(tflite_quant_model)
from IPython.display import FileLink
FileLink(r'modelquant.tflite')
Данная модель на вход принимает изображение лица размером 112×112*3, а на выходе дает одно число от 0 до 1, означающее красоту лица (хотя надо помнить, что в датасете оценки варьировались не от 0 до 5, а от 1 до 5).
Часть 2. JAVA
Попробуем написать простое приложение для телефона под управлением Android. Язык Java для меня новый, и я никогда не занимался разработкой под android, поэтому в проекте не применены оптимизации работы, не используется управление потоками и прочие трудозатратные для новичка вещи. Так как код на java достаточно громоздкий, здесь приведу лишь самые важные и для работы программы куски. Полный код приложения доступен по ссылке. Приложение открывает фото, детектирует и оценивает лицо с помощью сохраненной ранее сети и выдает результат:

С точки зрения разработки в нем важны следующие функции
1. Функция загрузки нейросети из файла model.tflite в папке assets в объект interpreter
import org.tensorflow.lite.Interpreter;
Interpreter interpreter;
try {
interpreter=new Interpreter(loadModelFile(MainActivity.this));
Log.e("TIME", "Interpreter_started ");
} catch (IOException e) {
e.printStackTrace();
Log.e("TIME", "Interpreter NOT started ");
}
private MappedByteBuffer loadModelFile(Activity activity) throws IOException {
AssetFileDescriptor fileDescriptor = activity.getAssets().openFd("model.tflite");
FileInputStream inputStream = new FileInputStream(fileDescriptor.getFileDescriptor());
FileChannel fileChannel = inputStream.getChannel();
long startOffset = fileDescriptor.getStartOffset();
long declaredLength = fileDescriptor.getDeclaredLength();
return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength);
}
2. Детектирование лиц с использованием модуля FaceDetector, входящего в стандартный пакет библиотек от google, использование нейросети и вывод результатов.
import com.google.android.gms.vision.face.Face;
import com.google.android.gms.vision.face.FaceDetector;
private void detectFace(){
//Create a Paint object for drawing with
Paint myRectPaint = new Paint();
myRectPaint.setStrokeWidth(5);
myRectPaint.setColor(Color.GREEN);
myRectPaint.setStyle(Paint.Style.STROKE);
Paint fontPaint = new Paint();
fontPaint.setStrokeWidth(3);
fontPaint.setTextSize(70);
fontPaint.setColor(Color.BLUE);
fontPaint.setStyle(Paint.Style.FILL_AND_STROKE);
//Create a Canvas object for drawing on
tempBitmap = Bitmap.createBitmap(myBitmap.getWidth(), myBitmap.getHeight(), Bitmap.Config.RGB_565);
Canvas tempCanvas = new Canvas(tempBitmap);
tempCanvas.drawBitmap(myBitmap, 0, 0, null);
//Detect the Faces
FaceDetector faceDetector = new FaceDetector.Builder(getApplicationContext()).build();
Frame frame = new Frame.Builder().setBitmap(myBitmap).build();
SparseArray faces = faceDetector.detect(frame);
Face face;
float[][] labelProbArray = new float[1][1];
imgData.order(ByteOrder.nativeOrder());
//Draw Rectangles on the Faces
if (faces.size()>0){
for (int i = 0; i < faces.size(); i++) {
face = faces.valueAt(i);
isFaceFound=true;
float x1 = Math.max(face.getPosition().x,0);
float y1 = Math.max(face.getPosition().y,0);
float x2 = Math.min(x1 + face.getWidth(),frame.getBitmap().getWidth());
float y2 = Math.min(y1 + face.getHeight(),frame.getBitmap().getHeight());
Bitmap tempbitmap2 = Bitmap.createBitmap(tempBitmap, (int)x1, (int)y1, (int) (x2-x1), (int) (y2-y1));
tempbitmap2 = Bitmap.createScaledBitmap(tempbitmap2, 112, 112, true);
convertBitmapToByteBuffer(tempbitmap2);
interpreter.run(imgData, labelProbArray);
String textToShow = String.format("%.1f", (Answer[0][0]*5-1)/4 * 10);
textToShow = textToShow + "/10";
int width= tempCanvas.getWidth();
//int height=tempCanvas.getHeight();
int fontsize=Math.max(width/20,imgView.getWidth()/20);
fontPaint.setTextSize(fontsize);
tempCanvas.drawText(textToShow, x1, y1-10, fontPaint);
tempCanvas.drawRoundRect(new RectF(x1, y1, x2, y2), 2, 2, myRectPaint) }
imgView.setImageDrawable(new BitmapDrawable(getResources(),tempBitmap));
}
}
Если хочется поиграть с оцениванием на телефоне — можно скачать приложение с GooglePlay market.
