Как настроить инфраструктуру веб-аналитики за $100 в месяц
Рано или поздно почти любая компания сталкивается с проблемой развития веб-аналитики. Это не значит, что нужно только поставить код Google Analytics на сайт — нужно найти пользу в полученных данных. В этом посте я расскажу, как это сделать максимально эффективно, затратив незначительные (по меркам профильных сервисов) деньги.

Меня зовут Андрей Колесниченко, я — руководитель отдела веб-аналитики в финтех-компании ID Finance. В компании мы постоянно следим за многими показателями, в первую очередь для нас важны конверсии на разных шагах. В начале вся отчетность была только по Google Analytics. Для того чтобы посчитать конверсию, мы сегментировали пользователей и находили долю каждого сегмента.
Затем мы перешли к отчетам в Google Docs. Об этом мы писали ранее на Хабре.
Сейчас мы находимся на следующем этапе — все отчеты строятся на сырых данных.
Для любого аналитика важны именно они: работая с агрегированными отчетами Google Analytics, не удается глубоко понять поведение пользователя, что сильно влияет на качество аналитики.
Чтобы получить такие данные можно оплатить Google Analytics Premium, стоимость которого составляет несколько миллионов рублей в год. В таком случае мы получим сырые данные в BigQuery. Также есть различные сервисы, которые дублируют данные Google Analytics и складывают их в BigQuery. Но можно это сделать самим и менее затратным способом. Начнем.
Подготовка Front-End
У вас уже есть сайт и настроенный Google Analytics. Теперь нам нужно сделать небольшие изменения, чтобы начать собирать сырые данные. Основная идея состоит в отправке Google Client ID и последующей выгрузке данных в этих разрезах.
Сначала мы должны создать три новых custom dimension в интерфейсе Google Analytics.
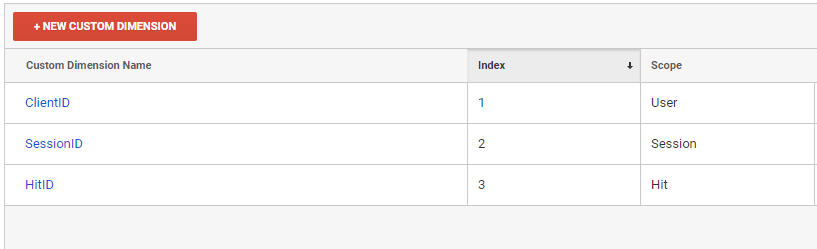
Именно в разрезе этих custom dimensions мы и будем скачивать отчеты из Google Analytics
- ClientID — идентификатор юзера
- SessionID — индентификатор сессии
- HitID — идентификатор хита
Потом мы должны добавить эти переменные во все хиты, отправляемые в Google Analytics.
ga(function (tracker) {
var clientId = tracker.get('clientId');
var timestamp = new Date().getTime();
ga('set', 'dimension1', clientId);
ga('set', 'dimension2', clientId + '_' + timestamp);
ga('set', 'dimension3', clientId + '_' + timestamp);
});
При отправке каждого хита dimension2 и dimension3 должны генериться заново. Dimension3 — идентификатор хита, поэтому он должен быть уникальным. Если вы используете GTM, то принцип добавления custom dimension такой же.
ClientID у нас настроен на уровне User, поэтому по нему мы сможем однозначно определять человека. SessionID настроен на уровне Session, по нему мы сможем определять сессию пользователя. Вы можете заметить, что мы отправляем каждый раз разные SessionID, но Гугл сохранит у себя только одно, последнее значение. Это значение и будут определять сессию.
Инфраструктура
После настройки фронт-энда нам нужно настроить выгрузку сырых данных.
- Выгружать данные мы будем в Google BigQuery. Для этого нам нужно будет создать проект в Google Cloud Platform. Даже если вы не собираетесь использовать BigQuery, проект все равно создать нужно для скачивания данных по API. Тех, кто будет пользоваться сервисами Google Cloud, ждет приятный бонус в 300$ при привязке карты. Для нужд аналитики небольшого проекта хватит минимум на полгода бесплатного использования.
- На странице console.cloud.google.com/iam-admin/serviceaccounts необходимо создать сервисный ключ, с помощью которого будем пользоваться API Google Analytics и Google BigQuery.
- Затем необходимо предоставить доступ этой почте к чтению Google Analytics.
- Переходим на страницу console.cloud.google.com/apis/library/analytics.googleapis.com и включаем API Google Analytics
- Так как данные мы будем скачивать каждый день, то нам нужен сервер для выполнения наших задач. Для этого мы будем использовать Google Compute Engine
Поток данных выглядит так:
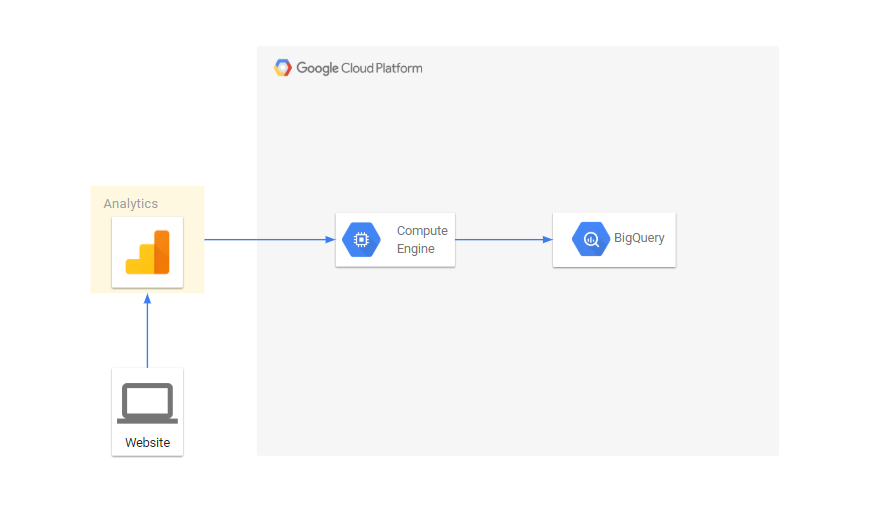
Экспорт данных через API Google Analytics
У Google Analytics есть API, который позволяет скачивать отчеты. Мы будем скачивать отчеты в разрезе наших параметров. Все скрипты написаны на питоне, расскажу про основные вещи:
from apiclient.discovery import build
import os
import unicodecsv as csv
from googleapiclient.errors import HttpError
import time
SCOPES = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = 'my_key_file.p12'
SERVICE_ACCOUNT_EMAIL = 'service_account_email@my-google-cloud-project.iam.gserviceaccount.com'
class ApiGA():
def __init__(self, scopes=SCOPES,
key_file_location=KEY_FILE_LOCATION,
service_account_email=SERVICE_ACCOUNT_EMAIL,
version='v4'):
credentials = ServiceAccountCredentials.from_p12_keyfile(
service_account_email, key_file_location, scopes=scopes)
self.handler = build('analytics', version, credentials=credentials)
def downloadReport(self, view_id, dim_list, metrics_list, date, page, end_date=None, filters=None):
if not end_date:
end_date = date
body = {
'reportRequests': [
{
'viewId': view_id,
'dateRanges': [{'startDate': date, 'endDate': end_date}],
'dimensions': dim_list,
'metrics': metrics_list,
'includeEmptyRows': True,
'pageSize': 10000,
'samplingLevel': 'LARGE'
}]}
if page:
body['reportRequests'][0]['pageToken'] = page
if filters:
body['reportRequests'][0]['filtersExpression'] = filters
while True:
try:
return self.handler.reports().batchGet(body=body).execute()
except HttpError:
time.sleep(0.5)
def getData(self, view_id, dimensions, metrics, date, filename='raw_data.csv', end_date=None, write_mode='wb', filters=None):
dim_list = map(lambda x: {'name': 'ga:'+x}, dimensions)
metrics_list = map(lambda x: {'expression': 'ga:'+x}, metrics)
file_data = open(filename, write_mode)
writer = csv.writer(file_data)
page = None
while True:
response = self.downloadReport(view_id, dim_list, metrics_list, date, page, end_date=end_date, filters=filters)
report = response['reports'][0]
rows = report.get('data', {}).get('rows', [])
for row in rows:
dimensions = row['dimensions']
metrics = row['metrics'][0]['values']
writer.writerow(dimensions+metrics)
if 'nextPageToken' in report:
page = report['nextPageToken']
else:
break
file_data.close()
Скрипт скачивает данные по API и пишет в файл filename для даты date. View_id — номер представления в google analytics:
filename = 'raw_data.csv'
date = '2019-01-01'
view_id = '123123123'
ga = ApiGA()
dims = ['dimension1', 'dimension2', 'source', 'medium', 'campaign', 'keyword', 'adContent', 'userType']
metrics = ['hits', 'pageviews', 'totalEvents', 'transactions', 'screenviews']
ga.getData(view_id, dims, metrics, date, filename)
from google.cloud import bigquery
client = bigquery.Client()
schema = [
bigquery.SchemaField('clientId', 'STRING'),
bigquery.SchemaField('sessionId', 'STRING'),
bigquery.SchemaField('source', 'STRING'),
bigquery.SchemaField('medium', 'STRING'),
bigquery.SchemaField('campaign', 'STRING'),
bigquery.SchemaField('keyword', 'STRING'),
bigquery.SchemaField('adContent', 'STRING'),
bigquery.SchemaField('userType', 'STRING'),
bigquery.SchemaField('hits', 'INTEGER'),
bigquery.SchemaField('pageviews', 'INTEGER'),
bigquery.SchemaField('totalEvents', 'INTEGER'),
bigquery.SchemaField('transactions', 'INTEGER'),
bigquery.SchemaField('screenviews', 'INTEGER')
]
table_id = ‘raw.sessions’
table = bigquery.Table(table_id, schema=schema)
table = client.create_table(table)
dataset_ref = client.dataset(dataset_id)
table_ref = dataset_ref.table(table_id)
job_config = bigquery.LoadJobConfig()
job_config.source_format = bigquery.SourceFormat.CSV
job_config.skip_leading_rows = 0
job_config.autodetect = True
with open(filename, "rb") as source_file:
job = client.load_table_from_file(source_file, table_ref, job_config=job_config)
job.result()
Для того чтобы получить все хиты скачиваем данные в разрезе dimension2, dimension3:
dims = ['dimension2', 'dimension13', 'pagePath', 'hostname', 'dateHourMinute']
metrics = ['hits', 'entrances', 'exits']
….
dims = ['dimension3', 'eventCategory', 'eventAction', 'eventLabel']
metrics = ['eventValue']
….
В конце объединяем все данные между собой sql-запросом. Получается что-то похожее на:
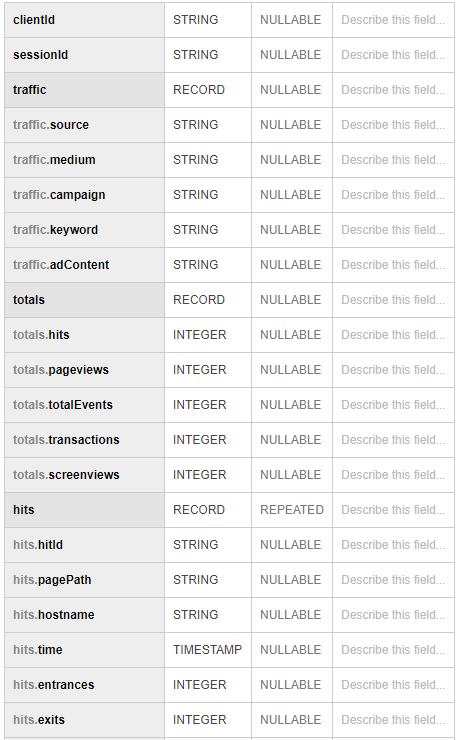
Использование
Мы настроили сбор сырых данных в BigQuery, нам осталось только подготовить отчеты для наших конверсий. Они делаются несложными sql-запросами. Для отчетности мы используем Tableau и Google Data Studio.
К тому же у нас появилась возможность обогащать данные из google analytics данными из внутренней БД, содержащей информацию о заявках, выдачах, просрочках, платежах и т. д.
Ко всему прочему, Google Cloud позволяет просто настроить realtime стриминг данных, если это необходимо.
Полная схема потока для аналитической отчетности сейчас выглядит так:
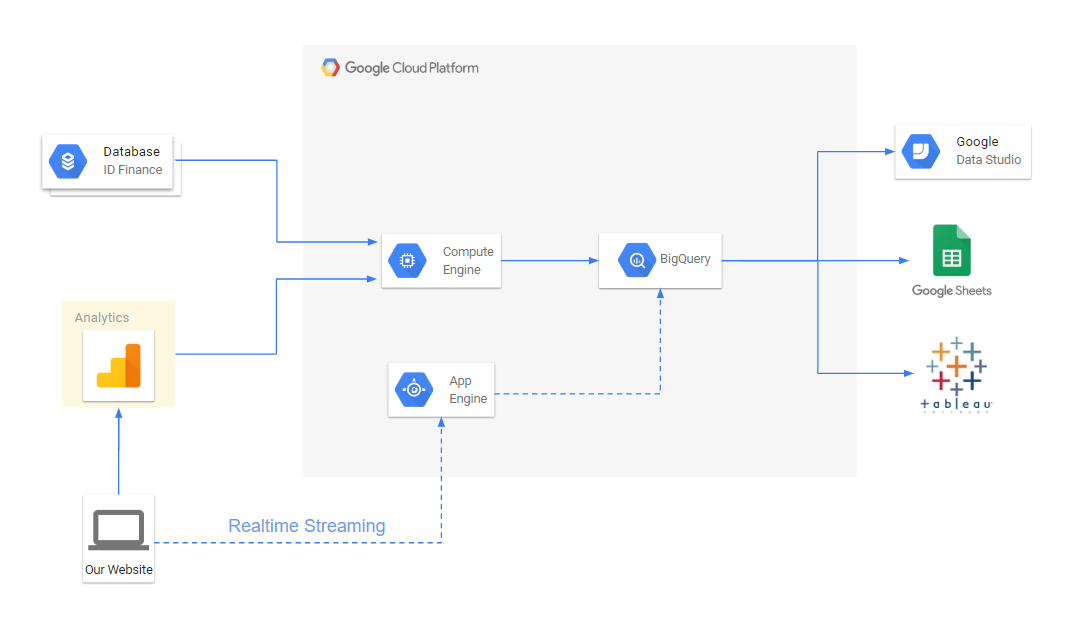
В результате нам удалось:
- Сделать отчетность более гибкой и удобной
- Сократить время на решение проблем с конверсией
- Построить мультиканальную атрибуцию для маркетинга. Это позволяет нам распределить ценность заявки не только по последнему источнику, но и по всем остальным источникам, приведшим пользователя на сайт.
- Объединить данные о пользователях в одном месте
