Как нарисовать Мону Лизу без кистей и красок?
Рисуем Мону Лизу используя глубокое обучение с подкреплением
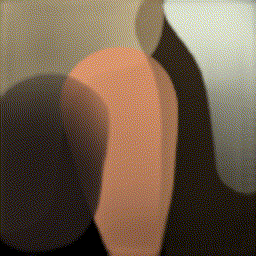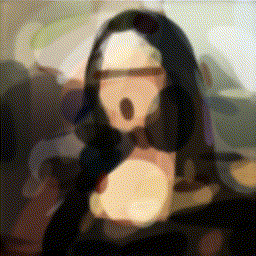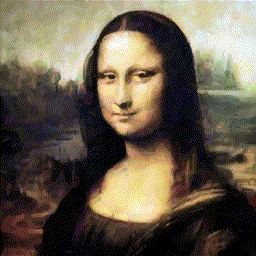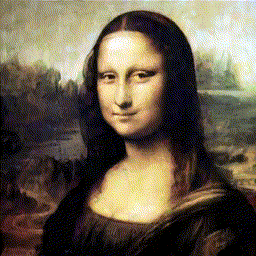
Пост написан специально для всех любителей искусства (и, возможно, машинного обучения).
На самом деле, специально для лучшего курса по ML.
В этом посте я хочу рассказать о том, как же научить машины рисовать так, как рисуют люди-художники, которые, используя небольшое количество мазков, создают фантастические картины.
Живопись является важной формой искусства, символизирует человеческую мудрость и творчество. Но людям трудно овладеть этим навыком, не потратив много времени на надлежащее обучение. Поэтому обучение машин рисованию является важной, но сложной задачей, которая помогает пролить свет на тайну живописи.
Сейчас мы с вами попробуем разобраться, как обучить искусственный интеллект последовательно наносить штрихи на холст, чтобы создать картину, похожую на заданное изображение. Будем называть машину, которая рисует, агентом. Кратко идею можно разделить на три пункта:
Научить агента раскладывать изображение на составляющие: агент должен проанализировать целевое изображение, понять текущее состояние холста и иметь дальновидные планы относительно будущих штрихов.
Создать пространство штрихов, которыми может пользоваться агент, учитывая различные параметры: расположение штриха, цвет, прозрачность и форма.
Создать рендер (средство визуализации), который может имитировать рисование сотен штрихов на холсте.
Давайте начнем.
Как научить агента раскладывать изображение на штрихи?
Как я уже писала, цель агента — разложение заданного целевого изображения на штрихи, которые могут воссоздать изображение на холсте (с помощью рендера). Чтобы имитировать процесс рисования, агент должен уметь прогнозировать следующий штрих на основе наблюдения за текущим состоянием холста и целевым изображением. Каждый штрих должен как можно более правильно соотноситься с предыдущим и следующим, чтобы уменьшить общее количество штрихов и быстрее нарисовать картину.
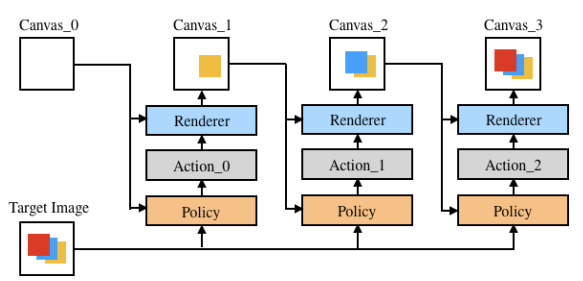 Общая архитектура: на каждом шаге агент получает текущий холст и итоговое изображение, анализирует его, и выдает набор параметров штриха, затем рендер визуализирует его и получается следующее состояние холста.
Общая архитектура: на каждом шаге агент получает текущий холст и итоговое изображение, анализирует его, и выдает набор параметров штриха, затем рендер визуализирует его и получается следующее состояние холста.
Сейчас нам как раз пригодится обучение с подкреплением. Для тех, кто никогда не сталкивался с ним — обучение с подкреплением можно сравнить с дрессировкой собаки. Чтобы научить своего мохнатого друга питомца выполнять определенную команду, нужно его подкармливать вкусняшками за каждое правильное действие. Так и в машинном обучении — есть окружающая среда, которая поощряет действия агента, которые приводят к правильному результату (картине).
Более математично:
На вход в нашей задаче подается пустой холст  и картина
и картина  (целевое изображение)которую мы хотим нарисовать. Агент стремится найти последовательность штрихов
(целевое изображение)которую мы хотим нарисовать. Агент стремится найти последовательность штрихов  такую, что рендеринг (рисование) штриха
такую, что рендеринг (рисование) штриха  на холсте
на холсте  выдает холст
выдает холст  . Итоговый холст
. Итоговый холст  должен быть визуально похож на целевое изображение
должен быть визуально похож на целевое изображение  .
.
Мы моделируем нашу задачу как Марковский процесс принятия решений с пространством состояний  , пространством действий
, пространством действий  , функцией перехода
, функцией перехода  и функцией вознаграждения
и функцией вознаграждения  . Пространство состояний
. Пространство состояний  строится на основе всей возможной информации, которую агент может наблюдать в окружающей среде. Мы разделим состояние на три части:
строится на основе всей возможной информации, которую агент может наблюдать в окружающей среде. Мы разделим состояние на три части:  , где
, где  состояние холста,
состояние холста,  целевое изображение и
целевое изображение и  номер шага.
номер шага.
Как это все будет работать?
Наша модель будет основана на DDPG, в которой есть две нейросетки — агент и критик.
Другими словами, агент выбирает ход для каждого состояния, а критик, основываясь на текущем холсте и целевом изображении, предсказывает ожидаемую награду за штрих. Оригинальная DDPG не очень хорошо подходит для нашей задачи, ведь для разных картин — есть разное окружение, т.е. где-то мы рисуем портрет с определенными тонами, где-то пейзаж, где-то натюрморт и тд. Есть специальные модели, например, Модель Мира, которые позволяют агенту эффективно понимать, какой мир его окружает.
Мы сделаем аналогичную вещь — рендер — с помощью которой агент сможет наблюдать смоделированную среду. Тогда он сможет изучить окружающий мир и эффективно улучшить свои действия. Модель с рендером называется Model-based DDPG. Разница между ними наглядно показана на рис. ниже.
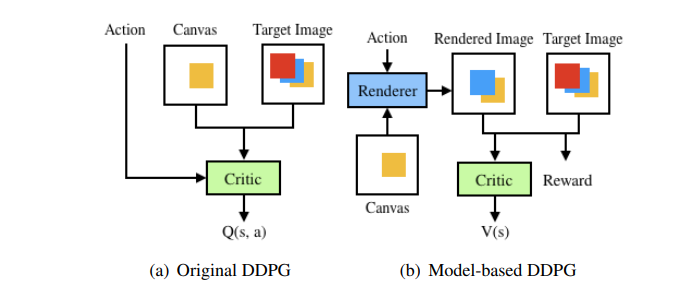
Немного меняется и Марковский процесс: теперь на шаге критик принимает состояние
критик принимает состояние  , а не состояние и действие вместе. Критик по-прежнему предсказывает ожидаемое вознаграждение для агента, но теперь по следующей формуле:
, а не состояние и действие вместе. Критик по-прежнему предсказывает ожидаемое вознаграждение для агента, но теперь по следующей формуле: 
Полезный мув: предсказывать сразу последующих штрихов. Действительно, такой подходпозволяет смотреть на будущее изображение на каждом шаге более обширно. Средство визуализации может отображать
последующих штрихов. Действительно, такой подходпозволяет смотреть на будущее изображение на каждом шаге более обширно. Средство визуализации может отображать штрихов одновременно, что значительно ускоряет процесс рисования. Опытным путем установлено, что
штрихов одновременно, что значительно ускоряет процесс рисования. Опытным путем установлено, что  подходит лучше всего для нашей задачи.
подходит лучше всего для нашей задачи.
Пора уже сказать пару слов об архитектуре наших нейросеток
Будем использовать residual структуры, по типу ResNet-18, в качестве средства извлечения признаков для агента и критика.
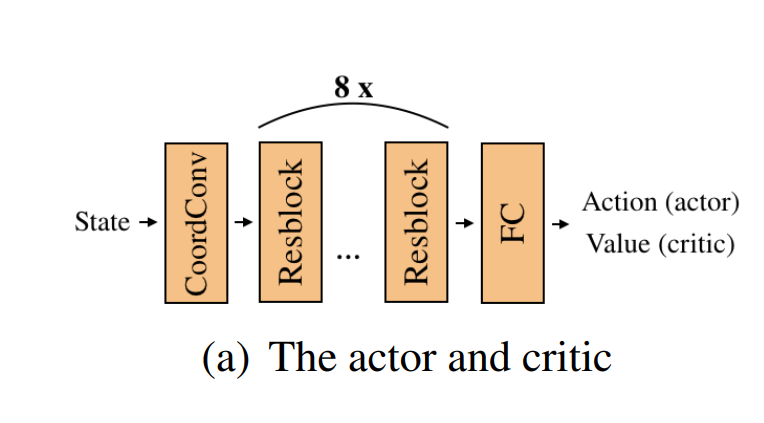 архитектура агента и критика. на вход — состояние, на выход — действие/значение
архитектура агента и критика. на вход — состояние, на выход — действие/значение
И так у нас есть 3 различных слоя:
1. CoordConv
2. Resblock x8
3. FC (Fully Connected Layer)
Разница для агента и критика только в последнем слое, где у них разные размерности выхода
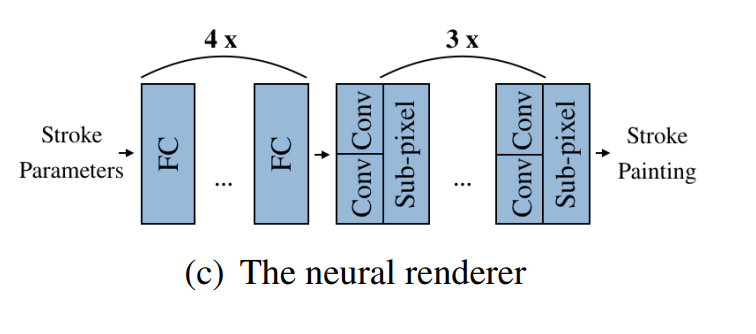 архитектура рендера. на вход — параметры штриха, на выход — визуализация такого штриха
архитектура рендера. на вход — параметры штриха, на выход — визуализация такого штриха
Нейронный рендер
FC (полносвязный слой)
Conv (свертка)
Sub-pixel — специальная штука, чтобы сделать изображение более четким
Использование нейронной сети для генерации штрихов хорошо тем, что она гибка для генерации штрихов любых стилей. А какими могут быть штрихи? И какие у них параметры? Давайте разбираться.
Насчет формы — в нашем случае штрих будет представлять собой квадратичную кривую Безье (с толщиной ~ как кисть). Форма этой кривой определяется координатами контрольных точек, а цвет, толщина и прозрачность несколькими числами. Формально:  ,
,
где первые 6 чисел — координаты контрольных точек,  — контролируют толщину и прозрачность двух конечных точек кривой, RGB — цвет.
— контролируют толщину и прозрачность двух конечных точек кривой, RGB — цвет.
Формула кривой Безье: 
А как же сравнить текущее состояние холста и целевое изображение? Какая метрика?
Для этого мы используем Wasserstein GAN, улучшенная версия оригинальной GAN, в которой расстояние — Wasserstein-l. Оно так же называется Earth_mover dist.
 метрика между текущим изображением и целевой картинкой
метрика между текущим изображением и целевой картинкой
Распределение  — распределение текущего холста,
— распределение текущего холста,  — целевого изображения. Функция
— целевого изображения. Функция  дискриминатор, липшицева с константой 1. Ее мы тоже отдельно обучаем.
дискриминатор, липшицева с константой 1. Ее мы тоже отдельно обучаем.
Вместо этого можно использовать  расстояние, но как покажут эксперименты, с ним результат будет хуже.
расстояние, но как покажут эксперименты, с ним результат будет хуже.
О математике достаточно поговорили, пришло время посмотреть на картинки и результаты экспериментов.
Рассмотрим 4 датасета — MNIST (рукописные цифры), SVHN (номера домов), CelebA (лица знаменитостей) и ImageNet (просто разные картинки).
Все картинки сводятся к размеру 128×128 пикселей. На каждой итерации обучения мы по очереди обновляем критика и актера. Все модели обучаются с нуля.
Изображения MNIST и SVHN — простые структуры изображений и обычное содержимое. Так что мы обучаем одного агента, который рисует 5 штрихов для изображений MNIST, и другого, который рисует 40 штрихов, для изображений SVHN.
Изображения знаменитостей имеют более сложную структуру и разнообразное содержимое, так что нам понадобится агент с 200 штрихами (как видно на рисунке ниже, в принципе, изображение похоже, но четкость пропала).
Для последнего датасета понадобится целых 400 штрихов из-за чрезвычайно сложных структур и разнообразного содержимого. Несмотря на потерю некоторых текстур, агент по-прежнему демонстрирует хорошие результаты в разложении изображения на штрихи.
Картинка ⬇

Пара слов про скорость:
На процессоре Intel Core i7 с тактовой частотой 2,2 ГГц. и видеокарте NVIDIA можно нарисовать изображение из 200 штрихов (предсказывая по 5) примерно за 2 секунды. Достаточно быстро, не так ли?
Наша модель хорошо работает и на других типах штрихов — прямые линии, треугольники и круги. Картины похожи на целевое изображение, но кривые Безье и прямые штрихи, на мой взгляд, больше всего похожи на настоящую картину.

Чуть не забыла. Хочется еще сравнить нашу нейронную сеть и какую-нибудь другую.
Для примера
рисунок а) — нейросеть SPIRAL с 20 штрихами (слева) + оригинал
рисунок б) — наша архитектура с 20 штрихами (оригинал g)
Первая выглядит как очень сильно размытое изображение, а вторая — уже больше похожа на картину какого-нибудь художника.

Рисунки (b), © и (g) — это наша нейросетка с 20, 200 и 1000 штрихами соответственно. А вот (d), например, использует в качестве метрики  . Получается, конечно, тоже похоже на оригинал, но более размыто.
. Получается, конечно, тоже похоже на оригинал, но более размыто.
На последок хочу показать примеры рисования некоторых картин, очень залипательно!
Вот, например, рассвет:
 sunrise
sunrise
А вот подсолнухи:
 sunflower
sunflower
И даже звездная ночь Ван Гога!
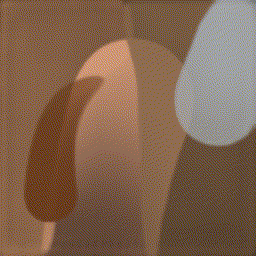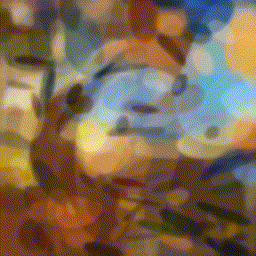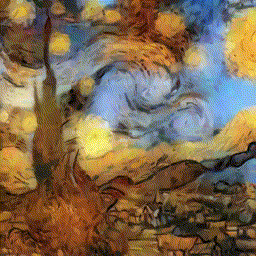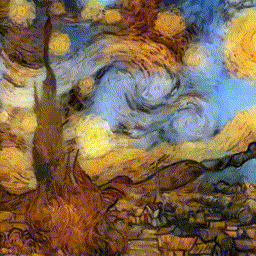 deepdream night
deepdream night
