Как наконец найти время, чтобы учить слова
Что делать, если расширять словарный запас английского хочется, а время на занятия в приложениях типа Anki, Memrise найти не получается?
У меня он раньше рос от потребления контента, но так как это как правило техническая документация, книги по программированию или видео на эту же тему, то со временем новые слова стали попадаться реже, и этого уже не хватает, чтобы словарный запас увеличивался сам собой.
Попытался решить эту проблему с помощью аудио флэш-карточек с интервальным повторением.

Почему флэш-карточки
Флэш-карточики — формат распространённый, хоть и не единственный, но его проще всего портировать в аудио. Это для меня было главным, чтобы не выделять отдельно время, а учить слова на ходу, пока идешь до метро, или занимаешься в зале.
По сути флэш-карточка это карточка, у которой вопрос написан на передней стороне, а ответ на задней. Смотришь на переднюю сторону, и пытаешься вспомнить ответ. В варианте с аудио это получается: слово на английском, пауза чтобы вспомнить, и перевод. Можно добавить ещё пример использование, в идеале из контекста, откуда это слово взяли. Записывать аудио не самому, а генерировать через какой-нибудь классный Text-to-Speech сервис.
Интервальное повторение
Каждый раз переслушивать все аудиокарточки, показалось не эффективной идеей. Хотелось тратить на это времени не больше, чем нужно. В том же Anki эта проблема решается интервальным повторением. Плюс вы оцениваете, насколько хорошо помните карточку. Если помните хорошо, интервал повторения увеличивается, если плохо, то уменьшается.
Была мысль прикрутить к этому алгоритм SuperMemo 2, как в Anki, но потом, вдохновившись аудиокурсами Glossika и Пимслера, решил для первой итерации остановиться на варианте без обратной связи, но проще.
Берем набор слов, скажем 100, формируем из него mp3 файлы-уроков. В каждом 5 новых слов. На 1, 2, 3, 5, 7, 10, 13 день после того, как слово попалось в первый раз, добавляем повторение. Итого, на 100 слов получаем 33 mp3 файла на 33 дня, в каждом из которых 5 новых слов. Каждое слово встречаем 8 раз на протяжении 2 недель.
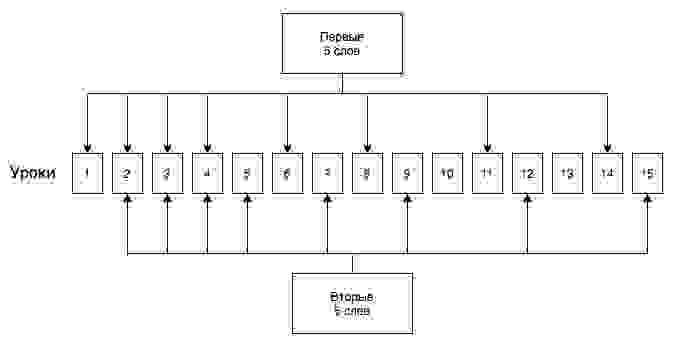
Конкретные параметры привел для примера, подобрал, чтобы получились короткие файлы по 3–5 минут, которые можно будет слушать на повторе. И чтобы учить слово в течение 2 недель.
Ну, а чтобы было интереснее, решил завернуть это всё в Telegram бота, а исходники выложить на GitHub.
Подготовка аудиофайлов с уроками
Мой основной язык C#, но последний год писал на Node.js, к тому же уже были заготовки по работе с аудио. Поэтому эту часть написал на нём.
1. Структура курса
До сих пор сомневаюсь в нейминге, но набор слов назвал курсом. Курс это просто JSON с описанием и массивом карточек.
Условно:
{
"id": "13800754-f9d3-43cf-808e-a51cb4d16125",
"name": "For beginners",
"cards": [
{
"text": "listen",
"translation": "cлушать",
"usage": "Listen, everybody!"
},
...
]
}2. Озвучивание карточек
Остановился на Amazon Polly, качество английской речи понравилось (голос Matthew), а русской просто удовлетворило (голос Tatyana). На Free Tier доступно 5 миллионов символов в месяц на год.
Генерировать будем через npm пакет aws-sdk. Перед этим нужно получить ключи. Полученные ключи через AWS CLI можно установить командой aws configure. Она сложит их в специальный файл, откуда их будет считывать npm пакет, на macOS это ~/.aws/credentials.
Озвучивание текста сводится просто к вызову метода в SDK, который нам возвращает Buffer с аудио.
const AWS = require('aws-sdk')
const polly = new AWS.Polly({
signatureVersion: 'v4',
region: 'us-east-1'
});
const buffer = await polly.synthesizeSpeech({
'Text': 'listen Проходимся по всем карточкам в курсе и вызываем polly.synthesizeSpeech для всех их частей: слово, перевод, пример использования. Полученные данные складываем локально по алгоритму:
Озвучиваемый текст очищаем от недопустимых в имени файла символов через filenamify и берём первые 60 символов.
Вычисляем хеш озвучиваемого текста.
Получаем имя файла
${filenamify(text, {replacement: '_', maxLength: 60})}_${hash}.mp3Записываем в файл директорию
${language}/${voiceId}/${speed}
Так мы сможем позже находить аудиофайл для заданного текста.
 Структура директорий после озвучивания курса
Структура директорий после озвучивания курса
3. Генерация уроков
Тут прозаично, из JSON’а с курсом генерируем JSON с массивом, уроков, в каждом уроке по 5 новых карточек, и карточки на повторение по заданной схеме.
Примерная структура:
{
"courseId": "13800754-f9d3-43cf-808e-a51cb4d16125",
"lessons": [
{
"cards": [
{
"text": "listen",
"translation": "cлушать",
"usage": "Listen, everybody!"
},
...
]
},
...
]
}4. Генерация аудио для уроков
Пройдемся по массиву уроков из предыдущего пункта. Для карточек из поля cards возьмем аудиофайлы из пункта 2 и склеим их в один. Для начала ставим FFmpeg, а потом при помощи пакета audioconcat конкатенируем.
const audioconcat = require('audioconcat');
function concatFiles(filePathes, outputFilePath) {
return new Promise((resolve, reject) => {
audioconcat(filePathes)
.concat(outputFilePath)
.on('error', err => reject(err))
.on('end', () => resolve()));
});
}5. Загружаем файлы в Telegram
Этот пункт опциональный, у нас уже есть аудиофайлы уроков, и ими можно пользоваться. Это мы делаем уже для бота.
Нужен токен бота, который можно получить у BotFather, и ID чата, куда будем загружать файлы. Telegram позволяет ботам загружать файлы один раз и потом использовать в сообщениях разным пользователям, указывая только ID файла. Можно создать либо отдельную группу и добавить бота туда, либо слать сообщения себе в личку.
Пакетов для Telegram в npm есть несколько, если делать полноценного бота, то имеет смысл выбирать, но для загрузки файлов непринципиально, я остановился на node-telegram-bot-api.
Для начала выясним ID чата. Для этого добавляем бота в чат, или пишем ему напрямую. Отправляем сообщение, предварительно запустив код:
const TelegramBot = require('node-telegram-bot-api');
const bot = new TelegramBot('YOUR_TELEGRAM_BOT_TOKEN');
bot.on('message', (msg) => {
console.log(msg.chat.id);
});Потом загружаем в этот чат аудиофайлы.
const TelegramBot = require('node-telegram-bot-api');
const bot = new TelegramBot('YOUR_TELEGRAM_BOT_TOKEN');
const chatId = 12345;
let {audio: {file_id}} = await bot.sendAudio(chatId, 'path/to/audio.mp3');Полученный file_id записываем в JSON соответствующему уроку. На выходе получится JSON с массивом уроков, в каждом из которых прописан file_id аудиофайла в Телеграме. В будущем, чтобы отправить урок через бота, нужно будет просто указать этот ID.
Заворачиваем в бота
Как способ доставки аудио флэш-карточкек сразу пришел на ум бот, который по нажатию кнопки отправляет голосовое сообщение со следующим уроком. Оказалось правда удобнее отправлять как звуковой файл, а не голосовым, тогда во встроенном плеере Телеграма их можно слушать на повторе.
Бота написал на C#/.NET 5 + MongoDb. У меня уже был бот на C#, было проще взять за основу старый, чем писать с нуля.
Подробное описание того, как написать Telegram бота на C# вышло бы за рамки статьи, да и на Хабре хватает руководств. С исходным кодом можно ознакомиться по ссылке в конце. Для тех, кто не знаком с .NET, отмечу, что .NET 5 кроссплатформенный и для того, чтобы дорабатывать/запускать бота не нужен Windows. Также бот использует long polling, то есть сам обращается к Телеграму, чтобы получить сообщения — настраивать веб-хуки не нужно.
Курсы
Чтобы ботом можно было пользоваться, не разбираясь в исходниках и не запуская самому, добавил несколько готовых курсов. Тематические (для начинающих, путешествия, IT, еда), фразовые и неправильные глаголы, и топ 3000 частотных слов.
Топ 3000 составил на основе бесплатных семплов с wordfrequency, а они, в свою очередь, на основе корпуса современного американского английского языка (COCA). При распространении просят просто ставить ссылку на них.
Большинство примеров употребления слов взято из Tatoeba — открытая база предложений c переводами переводов.
Ссылки
Исходный код и краткая инструкции по запуску и добавлению своих курсов
Потестить бота
