Как мы учили Почту события в календарь добавлять. Часть 2
Привет, Хабр! С вами Дима из команды Машинного обучения Почты Mail.ru. Сегодня я продолжу рассказывать о том, как мы автоматизировали добавление событий из важных писем в календарь.
В первой части статьи я рассказал, как происходили проработка и анализ идей по этой фиче, исследования пользователей, и вкратце о том, как выглядит первый собранный прототип для проверки гипотез. Во второй части вас ждет продолжение этой истории, а именно то, как дорабатывали прототип, масштабировали его, как готовили данные, какие ML-модели использовали, и какие технические и продуктовые результаты получили.
Масштабирование MVP
После подтверждения полезности MVP мы начали думать о том, как распространить эту функциональность на большее количество пользователей. Дело в том, что лишь небольшая доля отправителей присылает файлы ICS в своих письмах (что такое ICS тоже можно посмотреть в первой статье). Соответственно, в идеале хочется для всего потока писем с событиями уметь выделять нужные поля. То есть от прототипа пора двигаться к решению на ML-основе.
Рассмотрим пока что ML-сервис как чёрный ящик, в который мы можем закинуть письмо, и который вернет нам JSON со следующей информацией:
Тип события. Например, «вебинар», «авиаперелет», «кино», «доставка заказа» и т.п. Каждый сценарий имеет свои конфигурируемые настройки уведомлений: когда и сколько раз нужно напомнить о событии. Например, о начале вебинара достаточно напомнить один раз за час до него, а о дожидающейся вас посылке на почте можно напомнить и 2–3 раза: за неделю до конца срока хранения и за пару дней, если вы ещё не успели её забрать. Интервалы получения уведомлений были получены из опросов: по каждому из массовых сценариев людей спрашивали, за какое время до начала события они хотели бы получить пуш с напоминанием.
Статус события «put/delete», который показывает, хотим мы поставить событие в календарь или удалить его.
Уникальный идентификатор, который потребуется для изменения/удаления события
Основная информация о событии: дата, длительность, название, дополнительные поля (например, адрес пункта выдачи или номер телефона отеля).
Доработаем наш MVP под новые реалии. То есть в пайплайне обработки появляются 2 ветки:
если письмо с событием содержит ics, то берём информацию из него
если ics-файла нет, то отправляем письма в ML-сервис, который выделит нужную информацию.
Общая схема обработки теперь выглядит так:

Упрощённая схема обработки писем для автоматической постановки событий
Разберем подробнее ветку обработки письма ML-сервисом на примере брони отеля.
Пользователь забронировал отель, отправитель прислал письмо с подтверждением брони.
Письмо пролетело через почтовые сервера, и ML-классификатор в онлайне определил, что это письмо относится к категории «путешествия». Этот классификатор является частью нашей системы категоризации потока писем (подробнее о категориях можно почитать тут и тут)
Письмо легло на хранилище-сторадж, который отправил сообщение в сервис-обработчик Handler. В Handler«е есть несколько правил, одно из них «это письмо с категорией «путешествия»
Handler по правилу «есть категория «путешествия» направляет письмо в очередь Queue2 для обработки
Очередь Queue2 разбирает разгребальщик dates-extractor, который берёт письмо и отправляет его в ML-сервис. Если ML-сервис по какой-то причине не вернул ответ, то обращаемся к нему снова (делаем повторные походы).
ML-сервис обрабатывает письмо, формирует JSON-ответ с информацией по событию (в том числе типом события «booking» и статусом «put») и возвращает его в dates-extractor.
Dates-extractor через API Календаря по уникальному идентификатору ставит событие в календарь пользователя с определёнными настройками уведомлений, соответствующими типу «booking».
Получив ответ от Календаря об успешной постановке события, dates-extractor записывает уникальный идентификатор события в метаданные письма. Таким образом сохраняется связь между письмом в почте и событием, благодаря чему можно из Календаря сразу перейти в письмо, которое послужило источником события.
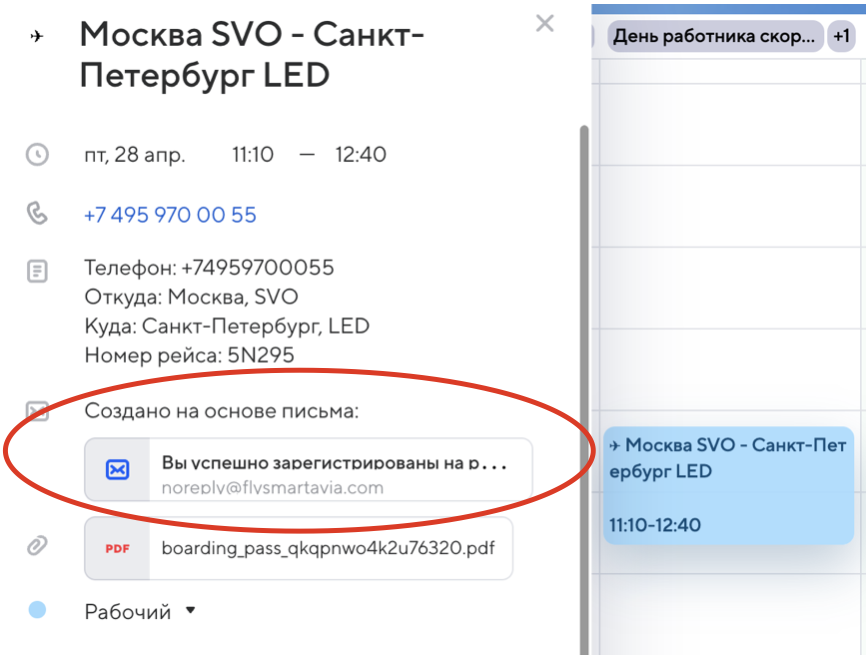
Переход из календаря в письмо, на основе которого создано событие
Теперь, когда у нас есть понимание того, как происходит обработка писем, погрузимся в детали. И начнем со специфики данных и их анонимизации.
Анонимизация данных
Если письма с рассылаемыми промо-предложениями меняются по контенту чуть ли не каждый день, то письма от отправителей событий/путешествий имеют вполне конкретную структуру.
Например, есть агрегатор, у которого купили билеты Вася и Аня. Аня идет на спектакль, а Вася — на концерт классической музыки.
Письмо Ани с приглашением выглядит так:
(тут шапка письма) \\n Дата и время события: 22 мая в 20:00 \\n Событие: Спектакль "Дядя Ваня" \\n Адрес: Театр "Рандомикон", пр-т. Театральный, д.12, корп.2 \\n (тут футер письма)
Письмо Васи выглядит похоже:
(тут шапка письма) \\n Дата и время события: 14 апреля в 19:00 \\n Событие: Концерт классической музыки \\n Адрес: Концертный зал "Москва", ул. Рандомная, д.3 \\n (тут футер письма)
Видно, что в обоих письмах есть фиксированная часть, связанная со структурой письма, и переменная часть, которая относится к конкретному событию — даты, названия событий, адреса, телефоны и т.п.
Процесс анонимизации состоит из следующих шагов:
возьмем все письма от одного отправителя с одним паттерном, под паттерном подразумеваются письма со схожими темами и структурой
заменим в тексте все числа на спецтокен
NUMагрегируем
все нечастотные слова маскируем спецтокеном
MASKсклеим все идущие подряд до разделителя строки токены MASK в один. То есть строка
текст1 MASK MASK MASK \\n MASK MASK текст2превратится втекст1 MASK \\n MASK текст2дополнительно для подстраховки заменим все слова, начинающиеся с большой буквы и не стоящие в начале предложения, токеном
MASKи получим на выходе только шаблон письма.
В нашем случае он будет выглядеть так:
(тут шапка письма) \\n Дата и время события: NUM MASK в NUM:NUM \\n Событие: MASK \\n Адрес: MASK \\n (тут футер письма)
Разработчик имеет доступ только к таким анонимизированным шаблонам исходных писем, из которых полностью удалена вся специфичная для данного конкретного события информация.
Делаем велосипед
Глядя на анонимизированные шаблоны писем, разработчик по контексту понимает, где позиционно находится каждая сущность — дата события, время, название, адрес и т.п. Например, что "в NUM:NUM" — это время.
Шаблоны писем в рамках отправителя меняются не так уж часто, возникает мысль быстро написать правила для массовых отправителей. И сделать таким образом велосипед — в смысле следующий шажок от самоката (прототип на ICS) к автомобилю (финальная система).
Так мы и сделали — взяли шаблоны массовых отправителей и написали правила на основе регулярных выражений.
Вот как выглядят правила разметки для примера выше:
[
"Дата и время события: (?P
"Событие: (?P
"Адрес: (?P[^\\n]+)\\n"
]
Получилась понятная и интерпретируемая логика, которая пишется очень быстро.
Для некоторых сущностей дополнительно применяется правило валидации. Например, даты и номера телефонов валидировать достаточно легко, так как они подпадают под определённый шаблон, и даже существуют готовые библиотеки для этого (например, dateparser для дат или phonenumbers для номеров телефона). Корректность выделения адресов тоже можно валидировать, например, через geo-API.
Хоть логика на правилах понятна и проста, она весьма неустойчива к смене отправителем шаблона рассылаемых писем. Но такого быстрого прототипа хватило, чтобы ещё раз проверить на большем количестве пользователей гипотезу о ценности разрабатываемого функционала.
Впрочем, в прототипе на правилах есть еще пара плюсов:
Во-первых, их можно использовать для «подстраховки» и валидации ML-модели на потоке
Во-вторых, с помощью правил можно получать первую разметку для обучения моделей
Модель
Если говорить про постановку задачи машинного обучения, то в данном случае мы решаем задачу извлечения именованных сущностей или NER (named-entity recognition). Фактически, она сводится к задаче многоклассовой классификации: мы хотим каждому токену (токен — слово или часть слова) текста присвоить метку класса. Класс в данном случае может обозначать как наличие какой-либо из интересующих нас сущностей (например, даты, адреса и т.п.), так и ее отсутствие (просто слово).
На первой итерации в качестве ML-модели мы попробовали обучить bidirectional LSTM, так как в команде уже был положительный опыт внедрения и инференса LSTM на CPU в аналогичном сервисе отложенной обработки. Но так как пальму первенства в обработке естественного языка уже давно захватили трансформеры, мы решили обучить трансформерную модель и сравнить качество с LSTM. Так как изначально не планировали занимать ресурсы кластера с GPU под эту задачу, то решили сразу целиться в инференс модели на CPU.
Эксперименты показали, что трансформер показывает лучшие метрики качества по сравнению с LSTM, и мы приступили к внедрению модели в сервис.
Ниже кратко основные результаты:
Модель: RoBERTa, 6 слоёв, 6 голов multi-head attention в каждом слое, hidden size 384
Сделали квантование слоёв
Сериализовали через torch.jit.trace
Средний тайминг на письмо — порядка 300 мс, что при текущей нагрузке в 7–10k rpm нас вполне устроило.
Сервис
Сервис написан на Python c использованием связки Gunicorn + Falcon и крутится в кластере k8s. Модели и конфигурационные файлы представляют собой отдельные от кода артефакты, которые версионируются и доставляются прямо в поды сервиса. Если сервис «видит», что артефакт обновился, то переподгружает его на лету. Через веб-интерфейс можно удобно обновить или откатить любой артефакт, выбирая нужную версию.
Обработка письма представляет собой последовательность модулей: парсинг, препроцессинг, инференс модели, применение правил, формирование итогового ответа и т.п.
Так как нам важно уметь обновлять модели и отслеживать влияние этих обновлений на метрики, сервис должен предоставлять возможность проведения A/B теста. Впрочем, меняться может не только модель, но и правила, и вообще сам пайплайн обработки. В этом случае в отдельной группе указывается нужный набор модулей или артефактов, которые нужно протестировать на потоке.
Например, хотим протестировать новую модель выделения сущностей на 10% пользователей. Пример конфигурационного файла для такого А/В теста приведён ниже (для удобства сократим повторяющиеся модули в обоих пайплайнах):
split_config:
groups:
group_A:
users_fraction: 90
logic:
- module: HtmlParser
...
- module: BertPredictor
filename: "roberta_NER_2.0.pt"
...
group_B:
users_fraction: 10
logic:
- module: HtmlParser
...
- module: BertPredictor
filename: "roberta_NER_2.1.pt"
...
Мониторинг
Метрики, за которыми мы следим, можно разделить на технические и продуктовые.
Технические включают в себя время обработки письма, количество пустых и непустых ответов в разрезе по каждому отправителю, количество ответов с определённым статусом (200/500/…) и т.п.
Также по отправителю мы мониторим каждую выделяемую сущность. Если отправитель изменил шаблон письма, и логика перестала выделять какую-то сущность, то по метрикам мы это заметим. После этого мы актуализируем правила, чтобы починить поведение на потоке, вольем новые шаблоны в модель для дообучения, и обновим модель в А/В тесте.
Продуктовые метрики включают в себя:
Количество поставленных и удалённых событий по каждому отправителю
Количество жалоб на некорректно поставленные события и жалобы на уведомления
Общее количество push-уведомлений — на текущий момент более миллиона пушей в день
CTR открытия пушей — 20–30+% в зависимости от отправителя
Процент пользователей, считающих уведомления полезными — согласно опросам, это более 70% от всех, получавших пуши
Отдельно стоит отметить, что эта функция напрямую повлияла на аудиторные метрики Календаря. С помощью автоматического добавления событий в Календарь мы увеличили его MAU за 2022 год более чем в 3 раза.
«Давай по новой, Миша», или почему не получается с самого начала всё продумать идеально
В этой секции хочется отметить некоторые неочевидные моменты, которые появлялись в течение работы над сервисами по мере погружения в специфику данных.

«Кажется, нам нужна итерация доработок»
Идентификатор события
Как мы помним, каждому событию нужен уникальный идентификатор, который связывает письмо и слот в календаре. По этому идентификатору событие изменяется или удаляется из календаря. Первоначально идентификатор формировался как хеш от строки, включающей отправителя и timestamp события. Однако скоро оказалось, что единственного идентификатора не всегда достаточно.
Самый простой пример с доставкой заказа:
»Заберите заказ №{NUM} до {NUM} мая {NUM}:{NUM}» — нужно поставить событие в календарь. Дата события есть, идентификатор однозначно формируется.
»Спасибо за ваш заказ №{NUM}. Оцените, как все прошло» — нужно удалить событие из календаря, так как пользователь уже забрал свой заказ и напоминать о нём больше не требуется. Однако в этом письме уже нету даты доставки, и понять, что оба письма про один и тот же заказ можно только по номеру заказа.
Поэтому пришлось вместо одного идентификатора события делать пару: generated ID (тот самый хеш от отправителя + timestamp) и extracted ID — это может быть номер заказа, хеш от номера рейса или названия вебинара и т.п.
Теперь, если прилетает запрос на удаление события, то сначала ищем его по extracted ID: если нашли — удаляем, если нет — ищем по generated ID.
Сразу на этапе проектирования предусмотреть, что нам понадобится два идентификатора, было сложно. В результате пришлось по ходу разработки немного менять схему ответа и допиливать логику на стороне бэкенда.
Часовые пояса
Интересные нюансы возникли также при определении точного времени события. К примеру, пользователь приобрёл билет по маршруту Москва-Новосибирск. Слот в календаре, соответствующий перелёту, должен корректно отображаться и когда пользователь находится в Москве, и когда уже прилетел в Новосибирск. Конкретную точку на оси времени удобно хранить при помощи машинного формата unix timestamp, то есть привычное время из письма нужно каким-то образом трансформировать в координаты этой точки. Соответственно, необходимо как-то определять часовой пояс (или таймзону), в котором будет происходить событие.
Иногда таймзону можно выделить непосредственно из письма. К примеру, часто в письмах с авиабилетами есть трёхбуквенный IATA-код аэропорта, который однозначно сопоставляется с часовым поясом (вот библиотечка для этого).
Если таймзону из письма выделить не удаётся, но можно выделить в письме адрес или город, то часовой пояс определяется по ним. То есть в случае, если в письме с билетами нет IATA-кода аэропорта прилёта, то сервис бэкенда идет с запросом «Новосибирск» в API внутреннего геосервиса и уже оттуда получает часовой пояс пункта прибытия.
Если таймзона или геоданные из письма не выделились (или их там вообще нет), то предполагается, что событие происходит в часовом поясе, в котором в данный момент находится устройство пользователя.
Таблицы
Письмо содержит разнообразную HTML-разметку, и часто билеты свёрстаны в виде HTML-таблиц. Нужно как-то развернуть таблицу в plain text, который уже будет подаваться на вход модели. Самый простой вариант — проклеивать текст в колонках, проходясь по строкам сверху вниз.
К примеру, такая таблица:
Город вылета | Город прилёта | Багаж | Места | Мили |
|---|---|---|---|---|
Москва | Новосибирск | Без багажа | Информация недоступна | {NUM} миль |
склеится в такую строку:
"\\nГород вылета\\nГород прилёта\\nБагаж\\nМеста\\nМили\\nМосква\\nНовосибирск\\nбез багажа\\nИнформация недоступна\\n{NUM}миль"
Видно, что здесь название города «Москва» далеко отстоит от фразы «Город вылета», что усложняет модели жизнь из-за разрыва контекста. Поэтому хотелось в данном случае этот контекст сохранить.
Мы решили ввести в пайплайн обработки отдельный модуль, который для каждой таблицы будет определять, нужно ли её повернуть для того, чтобы сохранить контекст. Например, вышеприведённую таблицу можно повернуть так:
Город вылета | Москва |
Город прилёта | Новосибирск |
Багаж | Без багажа |
Места | Информация недоступна |
Мили | NUM миль |
и проклеить в такую строку:
"\\nГород вылета\\nМосква\\nГород прилёта\\nНовосибирск\\nБагаж\\nбез багажа\\nМеста\\nИнформация недоступна\\nМили\\nNUM миль"
Таким образом восстанавливается связность контекста для модели, и благодаря этому нам удалось повысить качество выделения сущностей в письмах с билетами.
Что дальше
Мы начали с ряда понятных сценариев, которые встречаются у пользователя (записи к врачу, концерты, кино, авиаперелёты и т.п.), подтвердили гипотезу о полезности уведомлений, и теперь постепенно расширяем покрытие по отправителям в рамках этих сценариев.
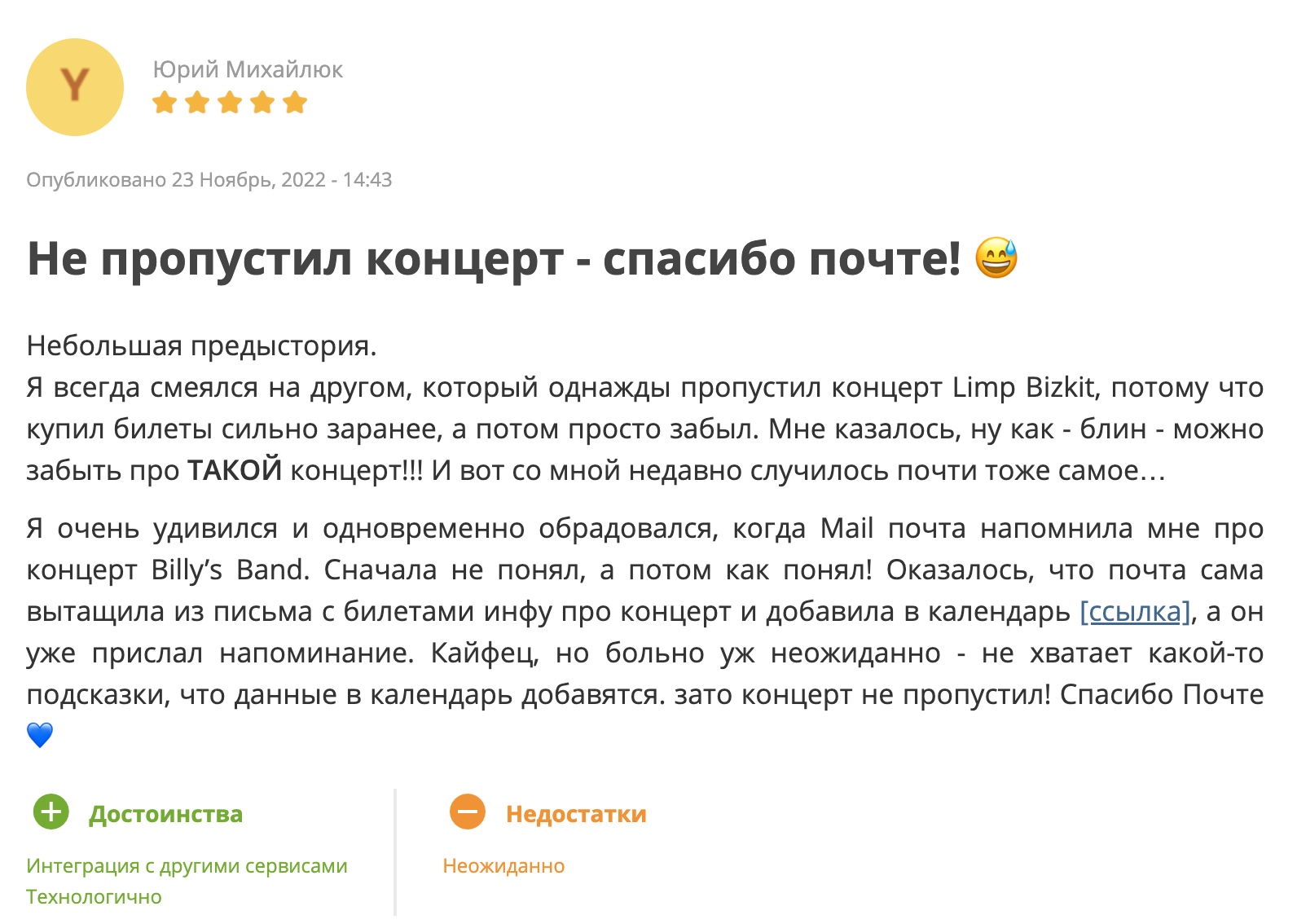
Также мы ищем и новые сценарии для автоматического добавления событий, которые будут полезны. Сейчас мы тестируем сценарий напоминаний о списаниях денег по подпискам на сервисы. Есть гипотеза, что это будет особенно актуально для тех пользователей, которые оформили пробную подписку и забыли её отменить. Календарь напомнит о том, что через пару дней со счёта будет списание.
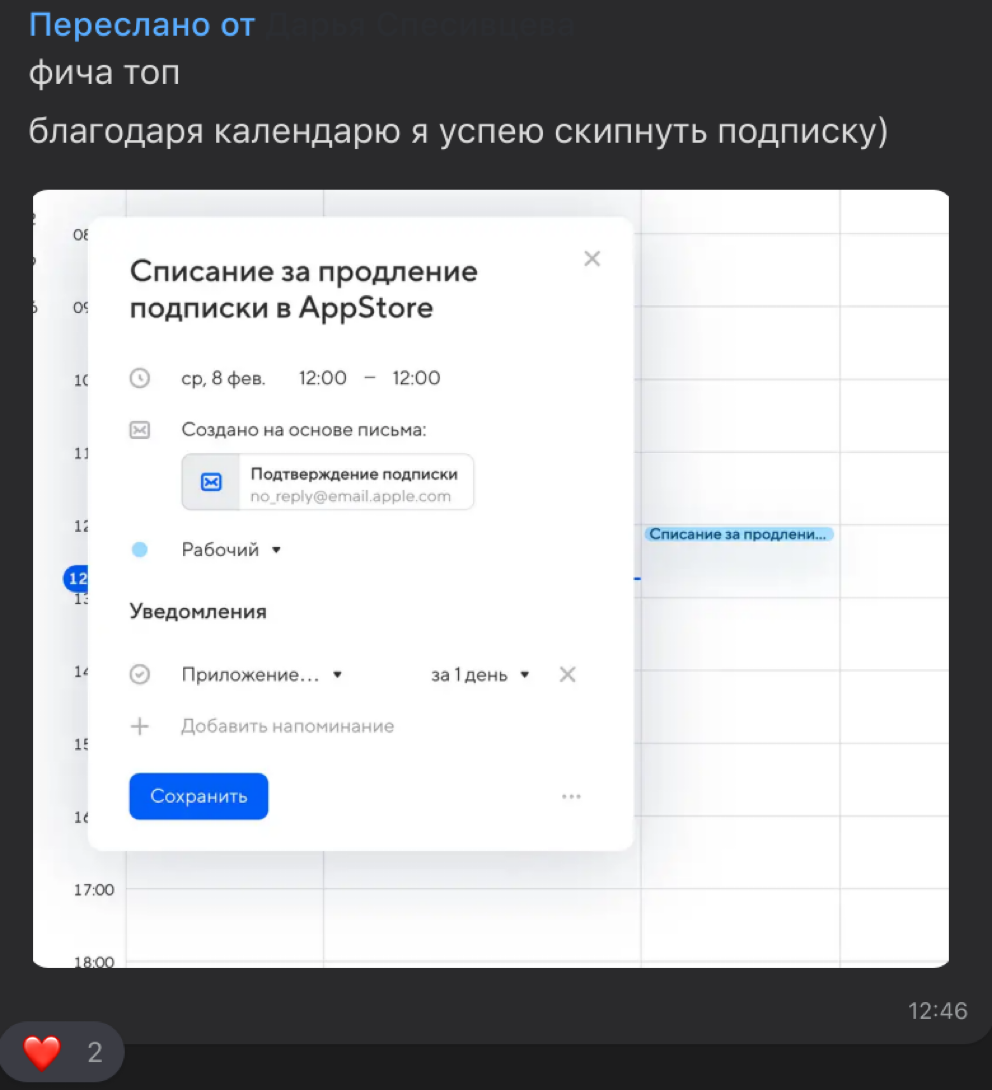
Отзывы от коллег по уведомлениям о списании денег
Ещё один аналогичный сценарий, который может помочь избежать ненужных трат — уведомлять об истечении даты бесплатной отмены бронирования на сервисах аренды жилья.
Более тесная интеграция почты и календаря — это еще один шаг к превращению электронной почты в персонального помощника, который помогает планировать день и держать под рукой всю важную информацию.
