Как мы строили параллельные вселенные для нашего (и вашего) CI/CD пайплайна в Octopod

Привет, Хабр! Меня зовут Денис и я вам расскажу как нас надоумило сделать техническое решение для оптимизации процесса разработки и QA у себя в Typeable. Началось с общего ощущения, что вроде делаем все правильно, но все равно можно было бы двигаться быстрее и эффективнее — принимать новые задачки, тестировать, меньше синхронизироваться. Это все нас привело к дискуссиям и экспериментам, результатом которых стало наше open-source решение, которое я опишу ниже и которое теперь доступно и вам.
Давайте, впрочем, не будем бежать впереди паровоза, а начнем с самого начала и разберемся предметно в том, о чем я говорю. Представим достаточно стандартную ситуацию — проект с трехуровневой архитектурой (хранилище, бэкенд, фронтенд). Есть процесс разработки и процесс проверки качества, в котором присутствует несколько окружений (их часто называют контурами) для тестирования:
- Production — основное рабочее окружение, куда попадают пользователи системы.
- Pre-Production — окружение для тестирования релиз-кандидатов (версий, которые будут использованы в production, если пройдут все этапы тестирования; их также называют RC), максимально схожее с production, где используются production доступы для интеграции с внешними сервисами. Цель тестирования на Pre-production — получить достаточную уверенность в том, что на Production проблем не будет.
- Staging — окружение для черновой проверки, как правило тестирование последних изменений, по возможности использует тестовые интеграции со сторонними системами, может отличаться от Production, используется для проверки правильности реализации новых функциональностей.
Что и как нам хотелось улучшить
C Pre-production все достаточно понятно: туда последовательно попадают релиз-кандидаты, история релизов такая же, как на Production. Со Staging же есть нюансы:
- ОРГАНИЗАЦИОННЫЕ. Тестирование критических частей может потребовать задержки публикации новых изменений; изменения могут взаимодействовать непредсказуемым образом; отслеживание ошибок становится трудным из-за большого количества активности на сервере; иногда возникает путаница, что в какой версии реализовано; бывает непонятно, какое из накопившихся изменений вызвало проблему.
- СЛОЖНОСТЬ УПРАВЛЕНИЯ ОКРУЖЕНИЯМИ. Нужны разные окружения для тестирования разных изменений: для одной внешней системы может потребоваться production доступ, а работать с другой нужно в тестовой среде вместо «боевой». А если staging один, то эти настройки распространяются на все реализованные фичи до следующего деплоймента. Приходится всё время об этом помнить и предостерегать сотрудников. Ситуация в целом похожа на работу многопоточного приложения с единым разделяемым ресурсом: он блокируется одними потребителями, остальные ждут. Например, один QA инженер ждет возможности проверки платежного шлюза с production интеграцией, пока другой проверяет все на интеграции тестовой.
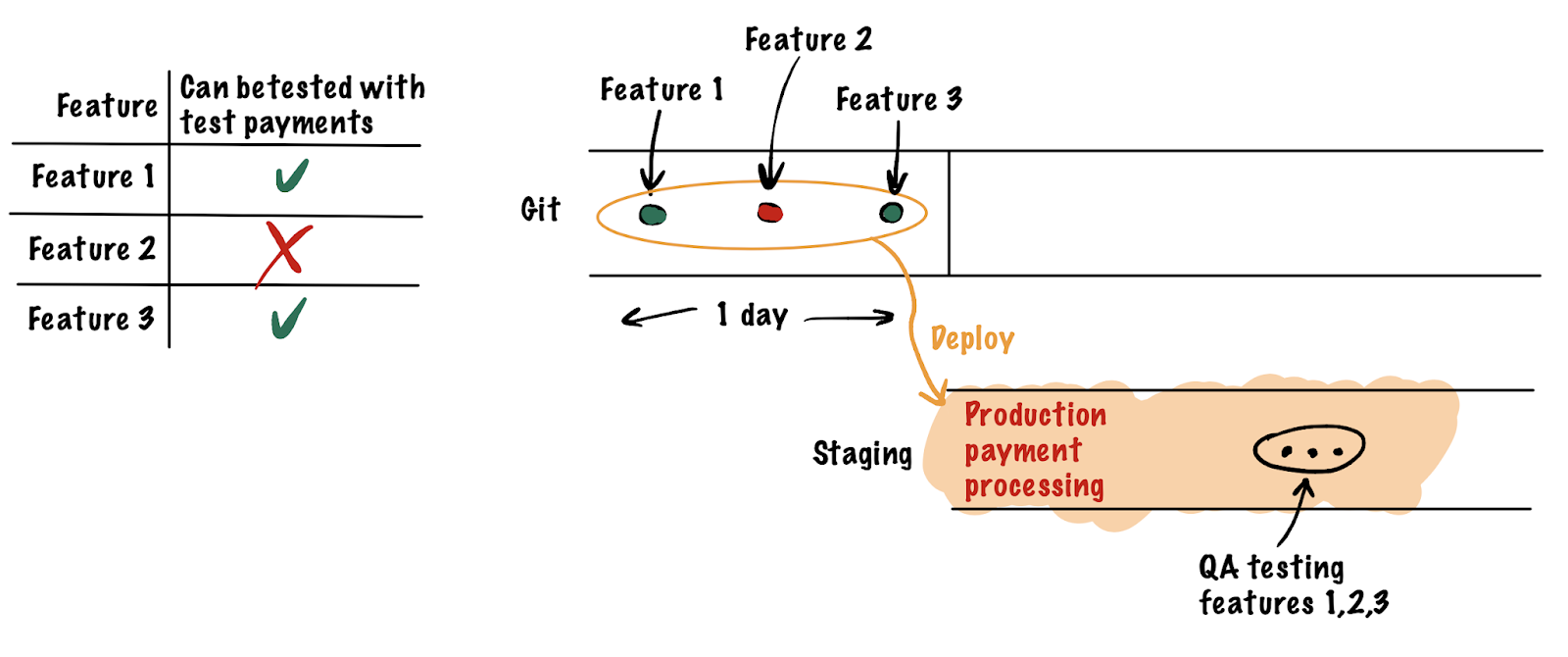
- ДЕФЕКТЫ. Критичный дефект может заблокировать тестирование всех новых изменений разом
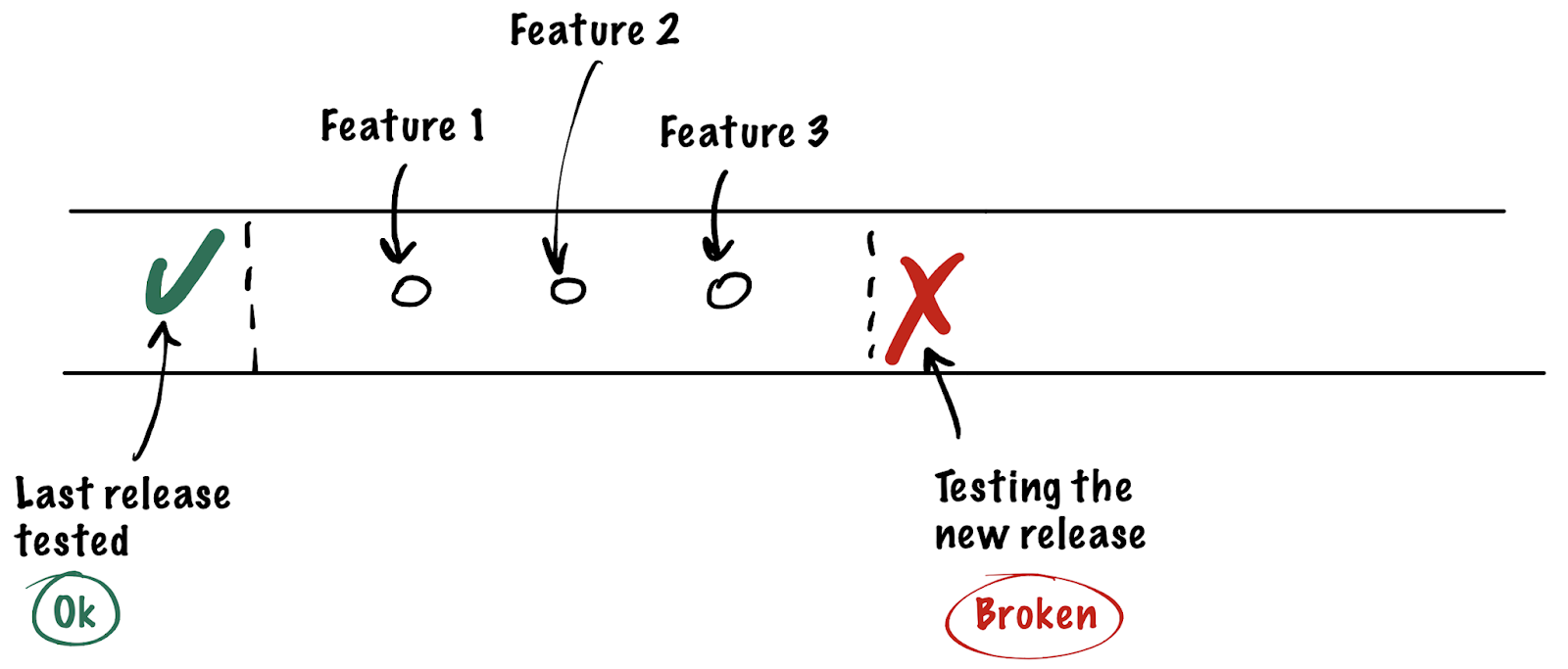
- ИЗМЕНЕНИЯ СХЕМЫ БД. Тяжело управлять изменениями схемы баз данных на одном стенде в периоды её активной разработки. Откати туда-сюда. Упс, тут не ревертится. А тут отревертили, но данные тестировщиков потеряли. Хочется для тестирования разных функциональностей иметь разные, изолированные друг от друга базы.
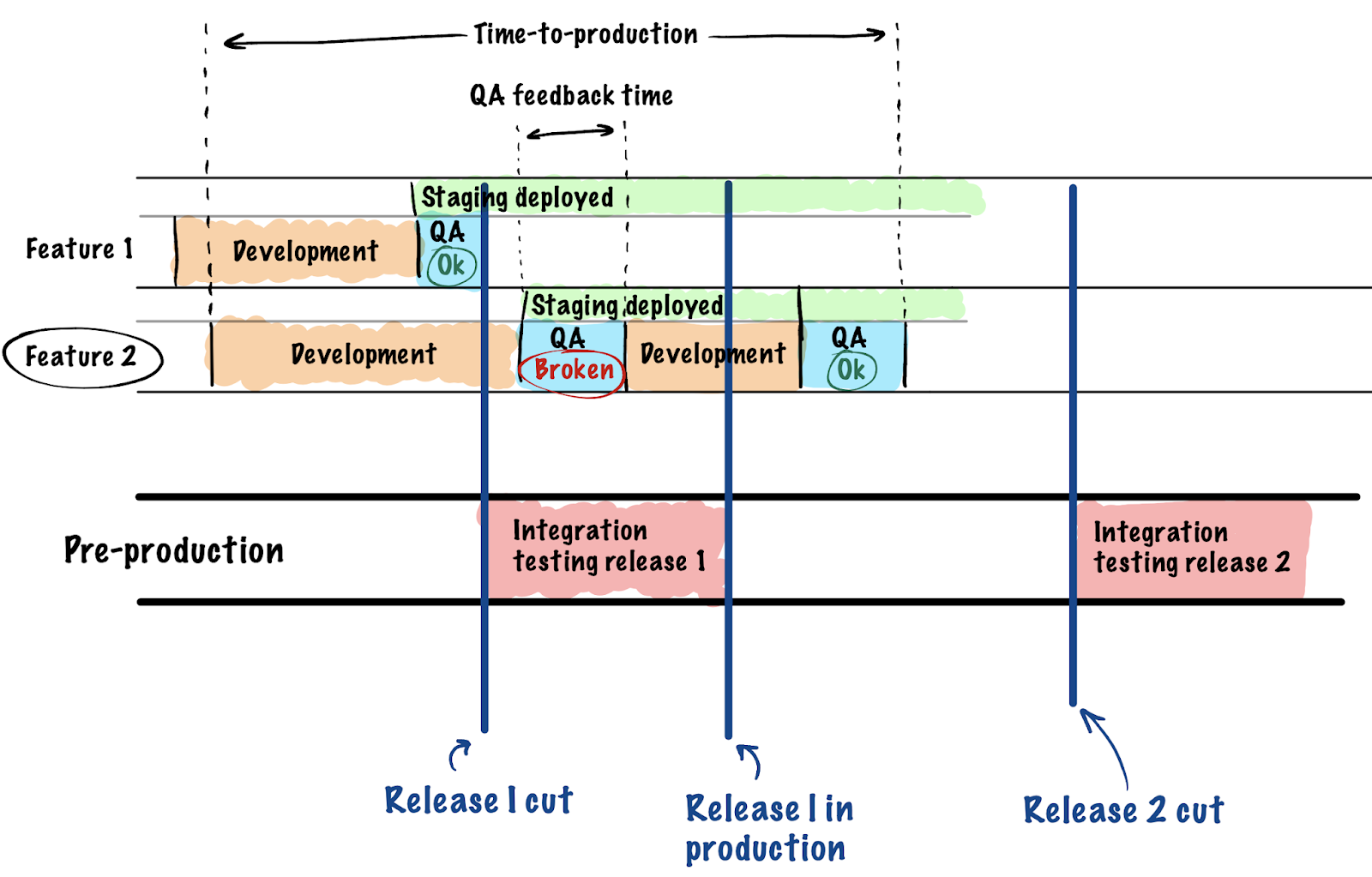
- УВЕЛИЧЕННОЕ ВРЕМЯ ПРИЁМКИ. Из-за того, что комбинация прошлых пунктов иногда приводит к ситуациям, когда часть фичей становится недоступна тестировщикам вовремя, или настройки окружения не позволяют приступить к тестированию сразу, происходят задержки на стороне разработки и тестирования. Допустим, в фиче обнаруживается дефект, и она возвращается на доработку разработчику, который уже вовсю занят другой задачей. Ему было бы удобнее получить её на доработку скорее, пока контекст задачи не потерян. Это приводит к увеличению отрезка времени от разработки до релиза в production для этих фич, что увеличивает так называемые time-to-production и time-to-market метрики.
Каждый из этих пунктов так или иначе решается, но все это привело к вопросу, а получится ли упростить себе жизнь, если мы уйдем от концепции одного staging-стенда к их динамическому количеству. Аналогично тому, как у нас есть проверки на CI для каждой ветки в git, мы можем получить и стенды для проверки QA для каждой ветки. Единственное, что нас останавливает от такого хода — недостаток инфраструктуры и инструментов. Грубо говоря, для принятия фичи создается отдельный staging с выделенным доменным именем, QA тестирует его, принимает или возвращает на доработку. Примерно вот так:

Проблематика различных окружений при таком подходе решается естественным способом:

Что характерно, после обсуждения мнения в коллективе делились на «давайте попробуем, хочется лучше, чем сейчас» и «вроде и так нормально, не вижу чудовищных проблем», но к этому мы еще вернемся.
Наш путь к решению
Первое, что мы попробовали — это прототип, собранный нашим DevOps: комбинация из docker-compose (оркестрация), rundeck (менеджмент) и portainer (интроспекция), которая позволила протестировать общее направление мысли и подход. С удобством были проблемы:
- Для любого изменения требовался доступ к коду и rundeck, которые были у разработчиков, но их не было, например, у QA инженеров.
- Поднято это было на одной большой машине, которой вскоре стало недостаточно, и для следующего шага уже был нужен Kubernetes или что-то аналогичное.
- Portainer давал информацию не о состоянии конкретного staging, а о наборе контейнеров.
- Приходилось постоянно мерджить файлик с описанием стейджингов, старые стенды надо было удалять.
Даже при всех своих минусах и при некотором неудобстве эксплуатации, подход зашел и начал экономить время и силы проектной команды. Гипотеза была проверена, и мы решили сделать все то же самое, но уже крепко сбитым образом. Преследуя цель оптимизации процесса разработки, мы собрали требования по новой и поняли, чего хотим:
- Использовать Kubernetes, чтобы масштабироваться на любое количество staging-окружений и иметь стандартный для современного DevOps набор инструментов.
- Решение, которое было бы просто интегрировать в инфраструктуру, уже использующую Kubernetes.
- Простой и удобный графический интерфейс для сотрудников на таких ролях как Руководители проектов, Product менеджеры и QA-инженеры. Они могут не работать с кодом напрямую, но инструменты для интроспекции и возможности задеплоить новый стейджинг у них должны быть. Результат — не дергаем разработчиков на каждый чих.
- Решение, которое удобно интегрируется со стандартными CI/CD пайплайнами, чтобы его можно было использовать в разных проектах. Мы начали с проекта, который использует Github Actions как CI.
- Оркестрацию, детали которой сможет гибко настраивать DevOps инженер.
- Возможность скрывать логи и внутренние детали кластера в графическом интерфейсе, если проектная команда не хочет, чтобы они были доступны всем и/или есть какие-то опасения на этот счет.
- Полная информация и список действий должны быть доступны суперпользователям в лице DevOps инженеров и тимлидов.
И мы приступили к разработке Octopod. Названием послужило смешение нескольких мыслей про K8S, который мы использовали для оркестрации всего на проекте: множество проектов в этой экосистеме отражает морскую эстетику и тематику, а нам представлялся эдакий осьминог, щупальцами оркестрирующий множество подводных контейнеров. К тому же Pod — один из основополагающих объектов в Kubernetes.
По техническому стеку Octopod представляет из себя Haskell, Rust, FRP, компиляцию в JS, Nix. Но вообще рассказ не об этом, поэтому я подробнее на этом останавливаться не буду.
Новая модель стала называться Multi-staging внутри нашей компании. Эксплуатация одновременно нескольких staging окружений сродни путешествиям по параллельным вселенным и измерениям в научной (и не очень) фантастике. В ней вселенные похожи друг на друга за исключением одной маленькой детали: где-то разные стороны победили в войне, где-то случилась культурная революция, где-то — технологический прорыв. Предпосылка может быть и небольшой, но к каким изменениям она может привести! В наших же процессах эта предпосылка — содержимое каждой отдельно взятой feature-ветки.
Внедрение у нас происходило в несколько этапов и начиналось с одного проекта. Оно включает в себя и подгонку оркестрации проекта со стороны DevOps и реорганизацию процесса тестирования и коммуникации со стороны руководителя проекта.
В результате ряда итераций некоторые фичи самого Octopod были удалены или изменены до неузнаваемости. Например, у нас в первой версии была страница с логом деплоя для каждого контура, но вот незадача — не в каждой команде приемлемо то, что credentials могут через эти логи протекать ко всем сотрудникам, задействованным в разработке. В итоге мы решили избавиться от этой функциональности, а потом вернули её в другом виде — теперь это настраиваемо (а поэтому опционально) и реализовано через интеграцию с kubernetes dashboard.
Есть еще и другие моменты: при новом подходе мы используем больше вычислительных ресурсов, дисков и доменных имен для поддержки инфраструктуры, что поднимает вопрос оптимизации стоимости. Если объединить это с DevOps-тонкостями, то материала наберется на отдельный пост, а то и два, поэтому тут продолжать об этом не буду.
Параллельно с решением возникающих проблем на одном проекте, мы начали интегрировать это решение в другой, когда увидели интерес от еще одной команды. Это позволило нам убедиться в том, что для нужд разных проектов наше решение получилось достаточно настраиваемым и гибким. На текущий момент Octopod применяется у нас уже достаточно широко в течение трех месяцев.
В результате
В итоге система и процессы внедрены в несколько проектов, есть интерес еще из одного. Что интересно, даже те коллеги, кто не видел проблем со старой схемой, теперь не хотели бы на неё обратно переходить. Получилось, что для некоторых мы решили проблемы, о которых они даже не знали!
Самым сложным, как водится, было первое внедрение — на нем выловили большую часть технических вопросов и проблем. Фидбек от пользователей позволил лучше понять, что требует доработки в первую очередь. В последних версиях интерфейс и работа с Octopod выглядит примерно так:
Для нас Octopod стал ответом на процессуальный вопрос, и я бы назвал текущее состояние однозначным успехом — гибкости и удобства явно прибавилось. Есть еще не до конца решенные вопросы: авторизацию самого Octopod в кластере перетаскиваем на Atlassian oauth для нескольких проектов, и этот процесс затягивается. Впрочем, это не более чем вопрос времени, технически проблему уже удалось решить в первом приближении.
Open-source
Надеемся, что Octopod будет полезен не только нам. Будем рады предложениям, пулл реквестам и информации о том, как вы оптимизируете схожие процессы. Если проект будет интересен аудитории, напишем об особенностях оркестрации и эксплуатации у нас.
Весь исходный код с примерами настройки и документацией доступен в репозитории на Github.
