Как мы создавали галерею нейросетевого искусства и почему не даём копировать картины
Мы сегодня запустили виртуальную галерею, где все картины созданы нейронной сетью. Её особенность в том, что каждую картину в полном размере может забрать себе только один человек. Почти как в настоящей галерее.
В этом посте я расскажу о том, как родилась эта идея и как мы реализовали её с помощью двух нейросетей, одна из которых используется в поиске Яндекса.

Идея
Мы довольно много экспериментируем с GAN«ам и пытались нащупать идею красивого и понятного проекта, в котором могли бы показать наши достижения.
У меня уже был проект ganarts, который я запустил для себя и друзей. Это была просто страница, на которой бесконечно генерировались картины в виде принта на футболку. Их генерировала нейросеть StyleGAN, обученная на вручную подобранных стилях искусств с wikiart.
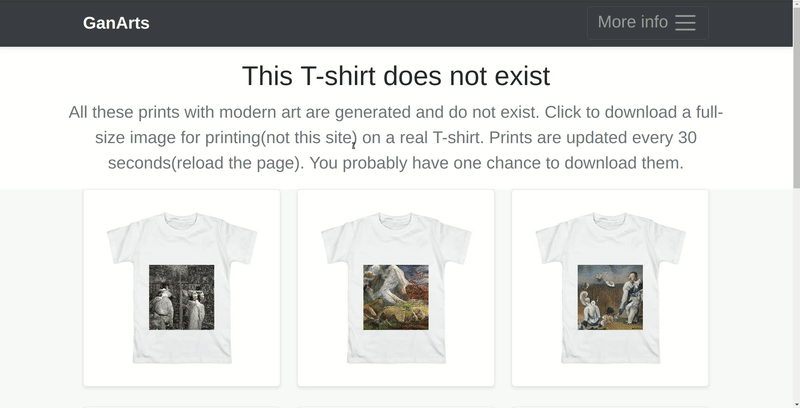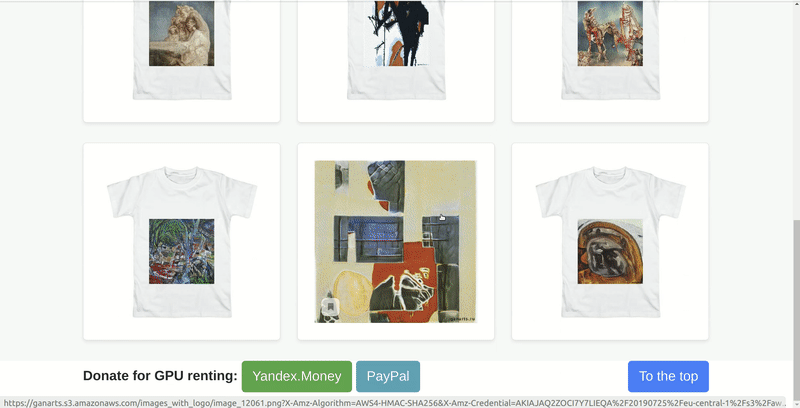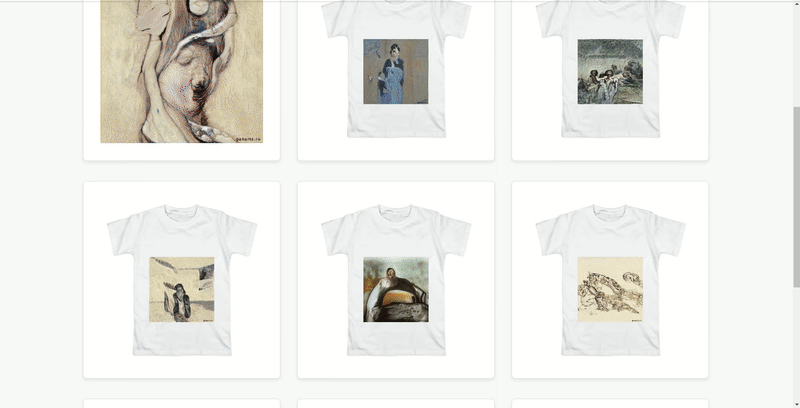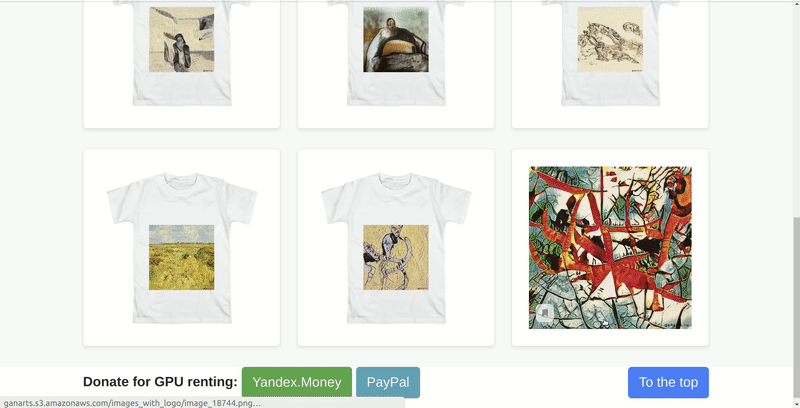
Эту идею мы взяли за основу. Но не хотелось делать просто очередной сайт-генератор картин. И в процессе обсуждений появилась концепция картинной галереи с несколькими тематическими залами, где у каждой картины должно быть не более одного владельца. Согласно нашей задумке, это должно связать виртуальную галерею с более привычными галереями, в которых у каждой картины есть конкретный владелец. При этом, имея возможность сгенерировать миллионы изображений, мы специально ограничили их количество, чтобы каждый пользователь, который успел забрать себе картину, чувствовал ее уникальность. А ещё мы добавили ограничение — взять можно не более одной картины — так гораздо интереснее выбирать.
Реализация
С тех пор как компания Nvidia выложила код для обучения нейросети StyleGAN, удивить кого-то сгенерированными изображениями достаточно сложно. Её авторам удалось сделать достаточно универсальную архитектуру, которая показывает хорошие результаты на разных данных. Прорыв был ещё и в том, что модель могла обучаться на достаточно большом разрешении (1024×1024) за приемлемое время и с лучшим, чем у конкурентов, качеством.
Энтузиасты «скармливали» ей всё, что попадает под руку. Если вам интересно взглянуть на подобные проекты, то вот список наиболее ярких.
— Люди: thispersondoesnotexist.com
— Аниме: www.thiswaifudoesnotexist.net
— Коты: thesecatsdonotexist.com
— Персонажи «Игры престолов»: nanonets.com/blog/stylegan-got
— Автомобили: twitter.com/SyntopiaDK/status/1094337819659644928
— Логотипы: twitter.com/matthewjarvisw/status/1110548997729452035
— Детские рисунки: twitter.com/roberttwomey/status/1239050186120282113
— Жуки: twitter.com/karim_douieb/status/1229903297378766854
— Комиксы про Гарфилда: twitter.com/willynguen/status/1220382062554898433
— Шрифты: twitter.com/cyrildiagne/status/1095603397179396098
— Снимки с микроскопа: twitter.com/MichaelFriese10/status/1229453681516412928
— Покемоны: twitter.com/MichaelFriese10/status/1210305621121064960
Но прогресс не стоит на месте, и в конце 2019 года Nvidia выпустила вторую версию StyleGAN. Подробный обзор всех изменений можно прочитать на Хабре. Главное видимое улучшение — это избавление от характерных droplet-like артефактов за счёт изменения метода нормализации активаций внутри сети. Попробовав новую архитектуру на нашем первоначальном датасете, мы также заметили увеличение разнообразия генерируемых картин, что не могло не радовать. Наша гипотеза: это произошло из-за увеличения количества параметров во второй версии архитектуры, что позволило выучить больше «мод» в распределении данных.
Еще одним приятным бонусом второй версии StyleGAN стало «более гладкое» латентное пространство. Проще говоря, это позволяет делать плавные перетекания между разными картинам:
Для создания картин мы применили архитектуру StyleGAN2. Мы обучили нейросеть на произведениях, принадлежащих к разным направлениям живописи: от фовизма и кубизма до минимализма и стрит-арта. Всего в обучающей выборке порядка 40 тысяч картин, на основе которых генерируются совершенно новые изображения.
В нашей галерее четыре тематических зала: «Люди», «Природа», «Город» и «Настроение». Для того чтобы разделить картины по залам, мы воспользовались нейросетью, которая применяется в Яндекс.Картинках. Она обучается на кликах пользователей из выдачи картинок по текстовому запросу. Наш внутренний датасет для обучения достаточно большой, чтобы эта нейронная сеть смогла разобраться даже со сгенерированными картинами. Она помогла автоматически выбрать изображения по нашим текстовым запросам из огромного количества случайных картин. Например, для зала под названием «Люди» картины выбирались по запросам «красавица», «хоровод», «свидание», «господин» и так далее. Это создало ощущение тематических залов, а исходные запросы послужили названиями для картин.
Результат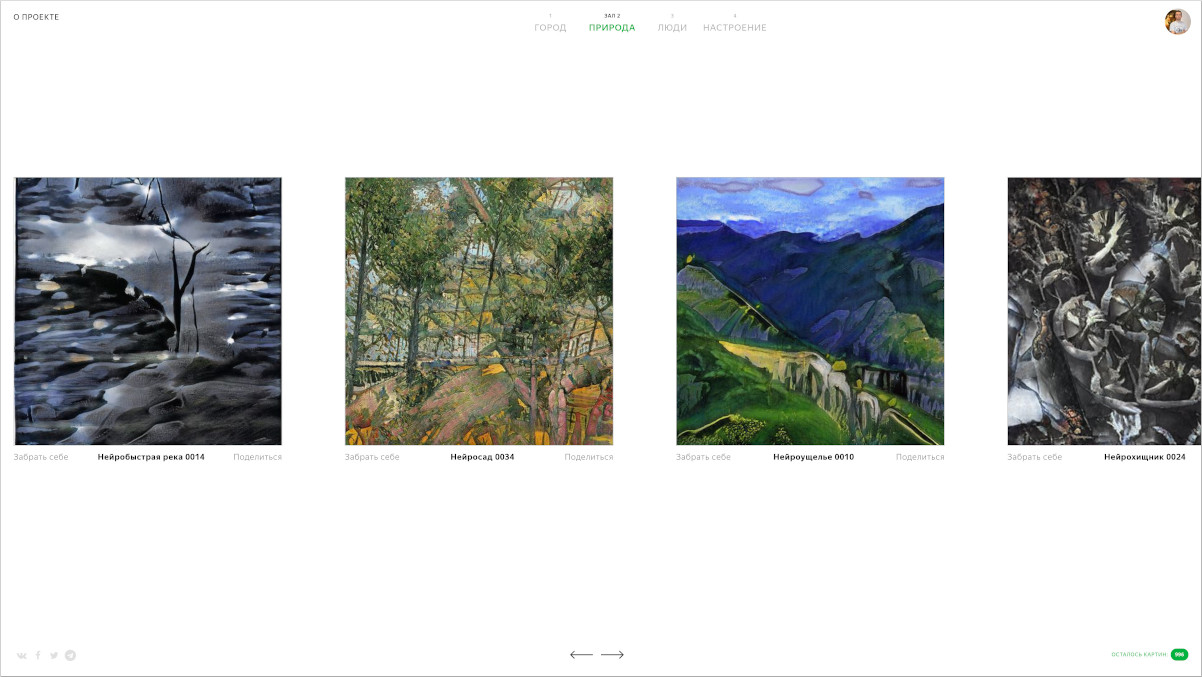
Мы сделали галерею из четырёх тысяч картин, каждая из которых может найти своего владельца. Такой виртуальной галереей мы хотим ещё немного уменьшить дистанцию между нейросетевым творчеством и более осязаемым искусством.
Считаю, что процесс выбора картины пользователем тоже можно назвать проявлением творчества. И надеюсь, что в будущем возможностей творческого выбора будет гораздо больше.
