Как мы сокращаем время простоя при установке обновлений схемы базы данных. Советы разработчикам
Привет! Я работаю в компании Bercut и мы более 20 лет занимаемся разработкой и поддержкой ПО для операторов сотовой и фиксированной связи. Я прошел путь от инженера в отделе сопровождения до менеджера продукта. В последние годы работаю ведущим специалистом в отделе администрирования (Senior DBA) и знаю все про работу высоконагруженных биллинговых базах данных, обслуживающих от сотен тысяч до десятков миллионов абонентов. Сегодня я хочу рассказать о наших подходах к сокращению времени простоя продуктивного комплекса при установке обновлений схемы данных (далее — патчей) на СУБД Oracle.
Обновление ПО выполняется в период минимальной нагрузки на комплекс, в то временное окно, когда будет оказано минимальное влияние на пользователей и бизнес. У временного окна есть определенные границы, например 3–4 часа, с 01 до 05 утра. В это окно нужно уложить все активности по включению режима ограниченного обслуживания, активации by‑pass режимов (для того чтобы абоненты могли звонить без участия биллинга) и остановке ряда модулей; произвести установку обновления на БД и обновить сами модули; выполнить тесты, активировать все сервисы и выполнить контрольные проверки бизнес функций. Описанные в статье методы и практики ориентированы на сокращение времени простоя/периода оказания сервиса с ограничениями в момент обновления комплекса.
Данная статья скорее обзор «лучших практик» по разработке, тестированию и запуску скриптов установки патчей, миграции данных и тд. В статье описаны различные подходы и варианты по минимизации времени простоя комплекса, методика выявления узких мест, а также средства контроля и мониторинга процесса установки. Более детальные сведения по конкретным решениям Вы сможите найти в документации.
Статья состоит из двух частей. В первой части рассматриваются решения по ускорению установки патчей, во второй части будут описаны действия по подготовке, мониторингу процесса установки и диагностики проблем.
Что есть патч?
Патч это набор скриптов, выполняемых с помощью утилиты для работы с БД — sqlplus.exe. В компании типовой патч состоит исполняемого сценария install.bat, главного файла последовательности установки install.sql, конфигурационого файла install_config.sql, файла с локализованными текстами localize.sql и директориями с файлами устанавливаемых объектов БД и скриптами с дополнительными файлами последовательности установки install.sql. Могут быть также дополнительные исполняемые сценарии апгрейда в несколько этапов.
На следующем скриншоте представлена типовая структура патча:
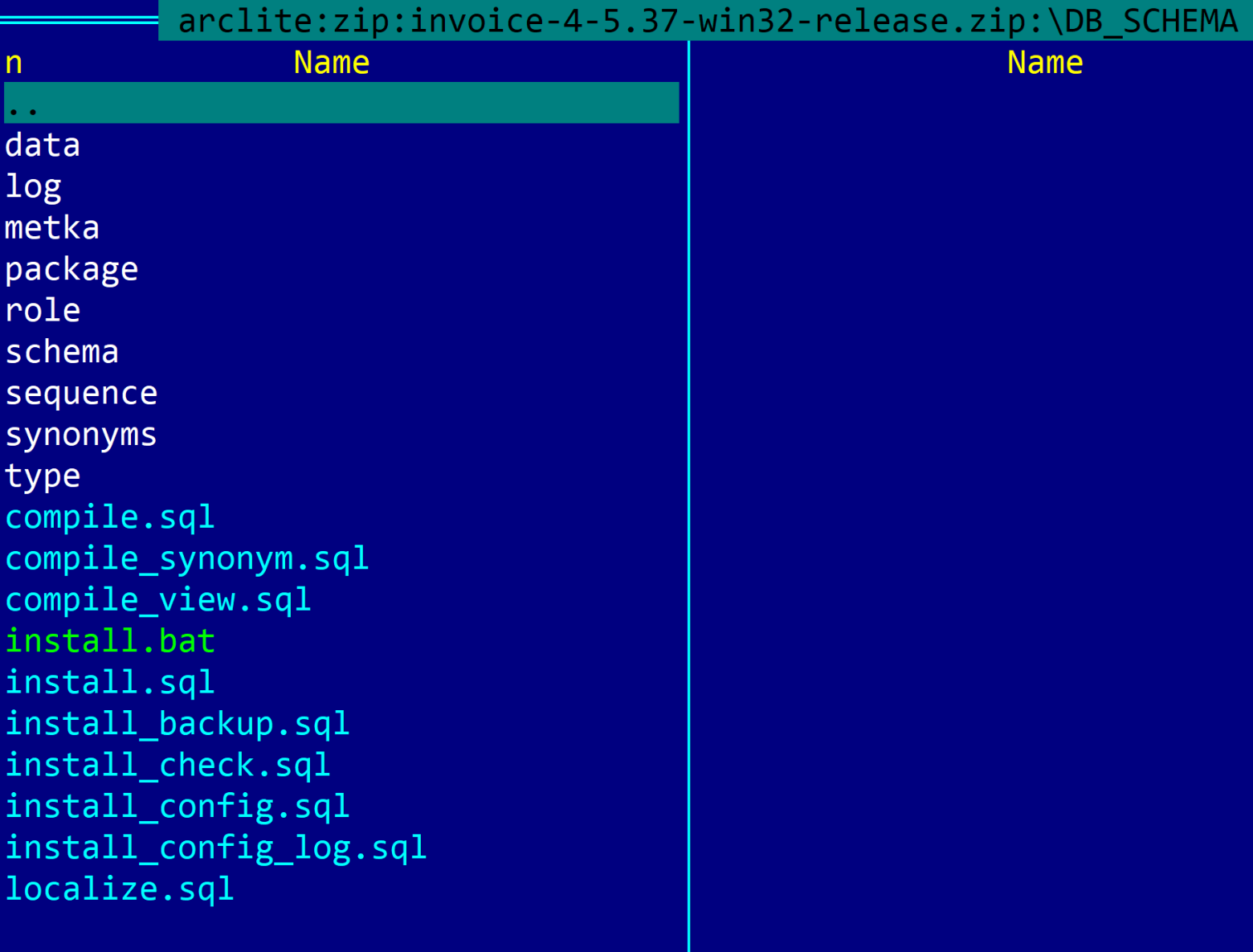
При разработке патча учитывается, что патч может быть установлен как на небольшую абонентскую БД, так и на БД с миллионами абонентов. При этом процесс установки патча должен укладываться в выделенное окно и чем оно меньше, тем меньше потери бизнеса от простоя комплекса. Для сокращения времени установки патча могут быть использованы различные методы распараллеливания, а степень параметризации настраивается в конфигурационном файле патча. Для разных этапов и шагов установки могут быть использованы отдельные параметры.
Примеры определения параметров для управления степенью распараллеливания и размером пакета:
-- к-во строк subs_serv_history, обрабатываемых за 1 транзакцию
def ssh_transaction='100000'
-- Степень параллелизма, которая будет использована при создании таблицы SUBS_SERV_HISTORY и индексов для нее
def ssh_parallel='10'Распараллеливание: какой метод и когда применять. Общие рекомендации.
Распараллеливание — выполнение какой то операции при установке патча на БД в нескольких потоках, с целью сокращения общего времени работы комплекса в условиях оказания сервисов с ограничениями.
Следует применять подходящие методы исходя из разумных соображений, чтобы уложиться в требуемое окно, например, не более 1 часа на установку патча на БД. При оценке необходимости использования тех или иных методов следует учитывать те БД и объемы данных в них, на которые патч будет устанавливаться. Если какая то операция быстро выполняется на маленькой БД, это вовсе не означает что она будет также отрабатывать за удовлетворительное время на большой БД. У разработчика должно быть как минимум понимание объемов данных, с которыми он работает, а лучше — должен быть доступ до тестовых БД с большими объемами, на которых он сможет выполнить оценку необходимости применения методов сокращения времени выполнения операции. В тоже время, если операция одинаково быстро выполняется и на маленьких и на больших объемах данных, это означает, что никакие методы применять не требуется; достаточно выполнения обычных манипуляций с данными или схемой данных. Таким образом, методы распараллеливания применяются исходя из целесообразности и необходимости. И в любом случае следует придерживаться метода KISS — Keep It Simple.
В следующей табличке сведены типовые задачи и типовые решения:
|
|---|
Далее все эти методы будут разобраны на примерах, но сначала о важной настройке самого экземпляра БД:
Настройка БД. Параметр parallel_max_servers
Биллинг является высоконагруженной OLTP системой, с тысячами или десятками тысяч транзакций в секунду. Много различных сессий разных приложений вставляют, изменяют, удаляют или читают строки. Большинство транзакций короткие, изменяющие 1 или несколько строк. Для такого режима работы параллельное выполнение операций не требуется и бывает даже вредным. Параллельное выполнение какого то тяжелого процесса, читающего или изменяющего большие объемы данных может создать существенную нагрузку на CPU и СХД и навредить другим сессиям с множеством коротких, но критичных ко времени отклика транзакциям. Поэтому обычно возможность параллельного выполнения искусственно ограничивается, для этого значение параметра экземпляра БД parallel_max_servers администраторами БД выставляется в околонулевое значение.
select name, value,description from v$parameter where name like 'parallel_max%'
/
NAME VALUE DESCRIPTION
-------------------- ---------- --------------------------------------------------
parallel_max_servers 4 maximum parallel query servers per instanceВ тоже время, во время ночных работ по обновлению БД или выполнения каких либо maintenance операций может потребоваться распараллеливание этих операций. Поэтому, если при установке патча или выполнении подобных работ требуется выполнение операций с распараллеливанием, следует перед началом работ увеличить значение параметра parallel_max_servers. Возможным значением может быть число, равное числу процессорных ядер в сервере БД. Если планируется запускать несколько сессий с параллельным выполнением, то может потребоваться и большее значение.
После окончания работ рекомендуется вернуться к старому значению параметра.
Распараллеливание DDL
DDL — Data Definition Language — группа операторов языка SQL для определения структуры данных. С помощью этих операторов можно создавать, изменять и удалять таблицы, индексы, процедуры и тд. Операторы CREATE, ALTER и DROP используются соответственно для создания, изменения и удаления объектов схемы. GRANT и REVOKE для выдачи и изъятия привилегий и ролей; имеется также ряд других операторов типа TRUNCATE, COMMENT, AUDIT и пр, впрочем которые уже не нуждаются в распараллеливании. DDL операторы, создающие или изменяющие большой объект в БД, могут выполняться долго и их время выполнения можно попытаться сократить за счет использования операнда PARALLEL.
Примеры:
create index BILL.IDXDATE on BILL.BILL (DATE_OF_BEGINNING, DATE_OF_END, DATE_OF_ISSUE) parallel 16
/
alter index CALL_DIS_02_2022" class="formula inline">CALL#DIS#S&index_degree
/
create table CALL_DIS_02_2022_new tablespace users parallel °ree as select * from CALL_DIS_02_2022
/В первом примере желаемая степень распараллеливания задана в коде (16), а во втором и третьем — параметризована.
В момент параллельного выполнения команды в списке сессий можно наблюдать Pxxx процессы, выполняющую запущенную задачу в несколько потоков.
Необходимость в использовании операнда PARALLEL определяет разработчик на основе знаний о том, большой или нет определяется объект. Количество параллельных процессов определяется инженером/администратором БД, устанавливающим патч, исходя из конфигурации оборудования, числа ядер и настроенных ограничений на параллельное выполнение на стороне БД.
Пример:
Задача: Создать две новые таблицы, одна из которых содержит список тарифных планов, а вторая — историю платежей абонентов. Создать индекс на уже существующую таблицу, в которой у разных заказчиков содержится от 3 до 300 млн записей.
Решение: Для обоих новых таблиц распараллеливание при создании таблиц не требуется, потому что они создаются впервые и объекты будут иметь нулевой размер. При создании индекса нужно использовать PARALLEL °ree, где значение параметра °ree будет задаваться в конфигурационном файле в зависимости от конфигурации оборудования в каждом конкретном случае инженером по внедрению непосредственно при установке.
В OLTP системе после создания или изменения объекта с PARALLEL я рекомендую обязательно изменить свойство объекта degree на 0.
Например,
ALTER INDEX index_name NOPARALEL;Это позволит исключить нежелательное срабатывание параллельного выполнения запросов с использованием объекта в дальнейшем.
Распараллеливание DML
DML — Data Manupulation Language — это группа операторов для манипуляции данными. С помощью этих операторов можно добавлять, изменять, удалять строки в БД. Операторы INSERT, UPDATE, DELETE, MERGE используются соответственно для вставки, изменения, удаления и вставки или замены строк.
Параллельное выполнение DML использует отличные от серийного выполнения DML механизмы блокирования, обработки транзакций и выделения места и по умолчанию параллельное выполнение DML выключено. Там, где явно требуется выполнить какой то DML параллельно, его необходимо явно включить.
В приведенном ниже примере наглядно видно, что указание подсказки оптимизатору PARALLEL для оператора DML update хоть и приводит к тому, что оптимизатор Oracle формирует план параллельного выполнения с характерными признаками, но снизу имеется приписка, что параллельное выполнение отключено.

Параллельное выполнение следует разрешить явно либо изменением текущей сессии:
ALTER SESSION ENABLE PARALLEL DML;либо, начиная с Oracle 12, путем указания дополнительной подсказки ENABLE_PARALLEL_DML:
update /*+ PARALLEL(8) ENABLE_PARALLEL_DML */ call_dis_02_2022 set d_part=null where rownum<=10000000;Проверить, включен ли режим параллельного выполнения, можно, обратившись к атрибутам текущей сессии PDML_STATUS:
select sid,username,program,machine,pddl_status,pdml_status from v" class="formula inline">session where sid=sys_context('USERENV','SID')
SID USERNAME PROGRAM MACHINE PDDL_STATUS PDML_STATUS
---- -------------------- -------------------- -------------------- ----------- -----------
70 BERCUT sqlplus.exe BERCUT\GOLIKOV-S ENABLED DISABLED
1 row selected.Вопросы мониторинга длительного серийного и параллельного выполнения будут рассмотрены во второй части.
Изменение структуры текущих крупных объектов, миграция с помощь DBMS_REDEFINITION
Штатный пакет Oracle DBMS_REDEFINITION предназначен для выполнения реорганизаций таблиц в БД с минимальным временем простоя. С помощью этого пакета можно, например, из несекционированной таблицы сделать секционированную. Основное достоинство этого пакета — операцию можно сделать в онлайн или с минимальной остановкой сервиса. Это не означает, что данный пакет использует какие то внутренние секретные инструкции, которые делают манипуляции в разы быстрее. Используется другой подход, суть которого заключается в том, что длительная по времени операция по реорганизации данных разделается на несколько этапов. Важно правильно запланировать выполнение этих этапов, иначе никакого выйгрыша в сокращении времени простоя не будет. Пакет хорошо документирован в официальной документации или, например, тут: Online Table Redefinition (DBMS_REDEFINITION) Enhancements in Oracle Database 10g Release 1
С помощью этого пакета реорганизация таблицы выполняется в несколько этапов:
create table — cоздается новая целевая таблица с другим именем.
EXEC DBMS_REDEFINITION.start_redef_table — инициируется процесс начала реорганизации таблицы. В этот момент создается MVIEW и MVIEW LOG для регистрации изменений в оригинальной таблице.
EXEC DBMS_REDEFINITION.copy_table_dependents — инициируется копирование зависимостей исходной таблицы на целевую.
EXEC DBMS_REDEFINITION.sync_interim_table — выполняется копирование данных оригинальной таблицы в целевую либо догрузка изменений, если запускать несколько раз.
EXEC DBMS_REDEFINITION.finish_redef_table — выполняется финальная синхронизация изменений в целевую таблицу и выполняется переключение указателя на сегменты данных оригинальной таблицы на целевую. В результате оригинальная таблица получает имя новой, а новая получает имя оригинальной. Созданные временные объекты для поддержки синхронизации удаляются.
Рассмотрим пример использования DBMS_REFEDINITION на примере:
Оригинальный скрипт:
--
-- чтение конфигурационных параметров
--
@.\install_config.sql
--
-- Открываем лог
--
spool .\log\alter_serv_order_rd.log
--
-- соединение под пользователем, под которым устанавливается патч
--
connect &usr/&pwd@&sid
--
ALTER SESSION FORCE PARALLEL DML PARALLEL 8;
ALTER SESSION FORCE PARALLEL QUERY PARALLEL 8;
prompt
prompt redefining table serv_order
prompt
create table serv_order_rd
( sord_id number,
subs_id number,
serv_id number,
sact_id number,
nserv_id number,
sord_stat_id number,
order_time date,
cre_user_id number,
cre_date date,
som_id number,
csc_id number(14,0),
charge_order number,
parent_sord_id number,
sordb_id number,
dis_int_dict_id number,
sordp_id number,
sord_group_id number )
tablespace &data_tbls
partition by range (order_time)
interval (interval '1' month)
(partition p0 values less than (to_date('1-1-2012','DD-MM-YYYY')) )
/
declare
error_count pls_integer := 0;
begin
dbms_redefinition.start_redef_table('smaster', 'serv_order', 'serv_order_rd');
dbms_redefinition.copy_table_dependents('smaster', 'serv_order', 'serv_order_rd',
1, true, true, true, false,
error_count);
dbms_output.put_line('errors := ' || to_char(error_count));
dbms_redefinition.finish_redef_table('smaster', 'serv_order', 'serv_order_rd');
end;
/
alter table serv_order enable constraint SERV_ORDERFK
/
drop table serv_order_rd cascade constraints
/
--
-- перекомпилляция объектов схемы
--
prompt reCompilling all ....
@.\compile.sql
--
@.\compile_view.sql
--
disconnect
exitЧто с этим скриптом не так? Вроде бы вся последовательность использования процедур пакета DBMS_REDEFINTION выполнена? Тем не менее, скрипт отрабатывал 8 часов.
Проведенный анализ показал, что операция переноса данных из оригинальной таблицы в целевую отработала быстро, в режиме распараллеливания DML, а затем последовало создание индексов, серийно, в один поток, и как раз это заняло все основное время:
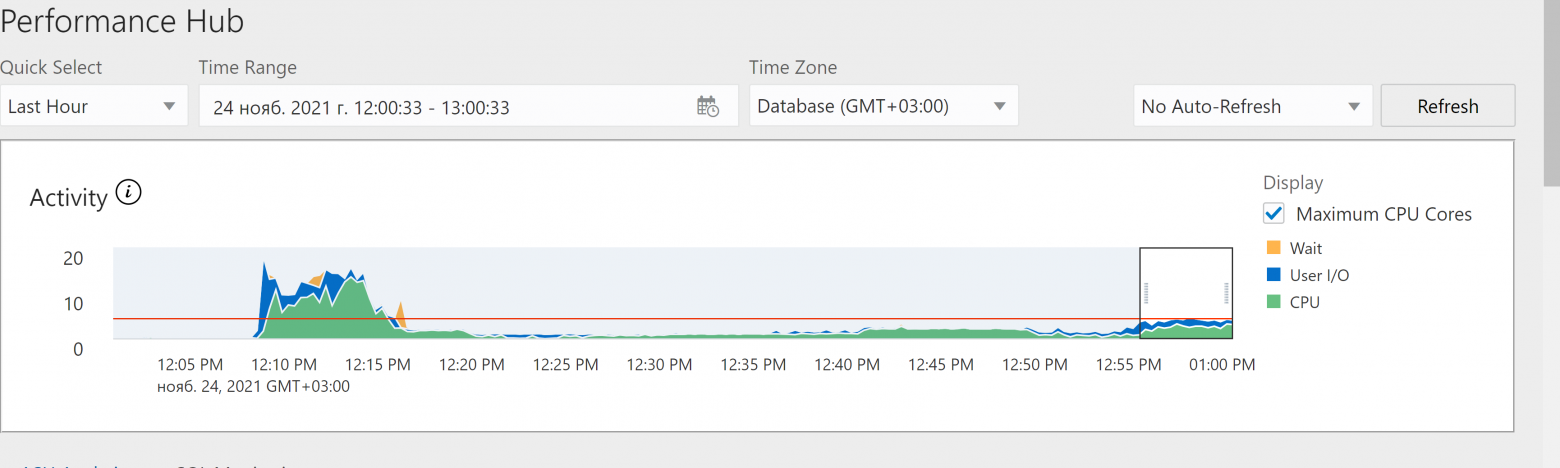
Добавление в скрипт команды включения параллельного DDL ускорило процесс, но общее время выполнения операции все равно было более 1ч.
Что было сделано не правильно и как можно ускорить процесс? Исходя из указанного выше кода видно, что основное преимущество DBMS_REDEFINITION по сравнению с обычными последовательными командами создания таблицы, копирования данных и создания индексов не было использовано. Следовало разбить данный скрипт на 2 этапа. Первый — создание таблицы, копирование основного объема данных и создания индексов; синхронизации изменений таблицы, которые накопились за время создания индексов. Второй — остановка сервисов, финальное применение дельты изменений и завершение реорганизации таблицы. В этом случае на время простоя оказало бы влияние только длительность применения дельты изменений в оригинальной таблицы и оно бы составляло несколько минут.
Таким образом, DBMS_REDEFINITION хорошо будет работать там, где длительную по времени задачу можно разбить на этапы подготовки и выполнения, согласно следующей схеме:
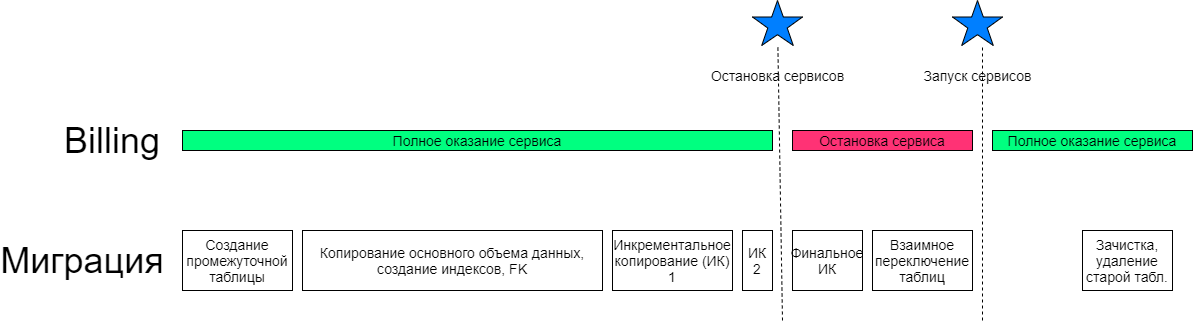
К недостаткам пакета можно отнести тот факт, что нет возможности влиять на те операции, которые выполняются внутри при вызове процедур пакета.
Изменение структуры текущих крупных объектов, миграция с помощь CTAS
CTAS — Create Table As Select. Данный метод является самым быстрым решением задачи удаления большого объема данных из большой таблицы. Прямая (direct) загрузка данных в таблицу, не обремененной какими либо индексами, ограничениями целостности и тд, с последующим созданием индексов и ограничений целостности может отрабатывать гораздо быстрее, чем просто удаление данных большого объема данных из таблицы. При этом таблица и индексы оптимизируется, блоки данных заполняются полностью и последующие операции SELECT и DML будут работать быстрее. В случае с удалением, такой же эфект после DELETE достигается лишь с последующим MOVE таблицы и перестройки индексов.
Рассмотрим пример с таблицей, в которой 148 млн записей, а задача — удалить половину.
SQL> select /+ PARALLEL(8)/ count(*) from call_dis_test
COUNT()
----------
148644292
1 row selected.Первый вариант решения — в лоб. Просто удаляем данные:
set timing on
delete /+ parallel(8) enable_parallel_dml */ call_dis_test where rownum<=74322146;
set timing off
rollback;
74322146 rows deleted.
Elapsed: 00:05:05.39
Rollback complete.Второй вариант решения — метод CTAS, создание новой таблицы с переливкой в нее данных, которые требуется сохранить:
set timing on
timing start
create table call_dis_new parallel 8 tablespace users as select * from call_dis_test where rownum<=74322146;
CREATE UNIQUE INDEX SMASTER.CALL_DISNCALL#DIS#S" class="formula inline">P ON SMASTER.CALL_DIS_NEW (CALL_ID, DIS_ID, START_TIME_INTERVAL, SH_REC_TYPE) parallel 8;
timing stop
Table created.
Elapsed: 00:02:51.64
Index created.
Elapsed: 00:00:42.09
Elapsed: 00:03:33.87Из сравнительного теста видно, что переливка ½ данных в новую таблицу с последующим созданием индекса оказалось на 1,5 минуты быстрее, чем удаление ½ данных из этой таблицы. При этом в первом случае размер таблицы и индекса не сократился, а во втором — стали в 2 раза меньше. Чтобы после DELETE сократить размер таблицы, потребуется дополнительно выполнить операторы ALTER TABLE. MOVE и ALTER INDEX… REBUILD, направленные на уплотнение хранения записей в таблице и уменьшение ее размера. Таким образом, общее время варианта с DELETE еще более увеличится.
В каждом конкретном случае с большими объектами стоит проводить тесты, но теперь вы знаете, что есть такой метод CTAS и он может быть быстрее чем DELETE. Не забудьте только переименовать новую таблицу)
Выполнение сложных миграций с помощью DBMS_PARALLEL_EXECUTE
Пакет Oracle DBMS_PARALLEL_EXECUTE предназначен для реализации параллельной обработки больших объемов данных. С помощью пакета целевой объект делится на логические части (chunk) заданного размера, и далее каждая порция подается отдается на вход обработчикам. Количество обработчиков настраивается. В качестве обработчика удобно использовать хранимую процедуру.
Документация.
О методе расскажу подробнее на реальном примере:
В процессе сборки кумулятивного патча миграции с S.Q до версии X.Y столкнулись с долгим временем скриптов миграции данных stage 1 и 2. Время работы скриптов 1 и 6 часов соответственно. Неприемлемо!
Исходный скрипт миграции содержал PL/SQL блок. Внутри SELECT, который выбирает данные, подлежащие миграции, открывается цикл FOR rec in (SELECT…) LOOP… и далее выполняются UPDATE, INSERT,…
Для применения решения потребовалось незначительное изменение исходного кода PL/SQL блока, а именно PL/SQL блок был оформлен в виде процедуры с двумя входными параметрами l_low_rid, i_high_rid с типом ROWID и добавления условия в WHERE rowid between start_id and end_id.
CREATE OR REPLACE PROCEDURE migr_stage_1 (i_low_rid IN ROWID, i_high_rid ROWID)
IS
--17.02.2014 SGolikov Использован PARALLEL EXECUTION для ускорения
--26.08.2013 Dmitriy Shubin Миграция данных client, client_history, customer
...
BEGIN
FOR rec
IN (SELECT ch2.clnt_id -- это для обратной миграции (заполнения customer_id соответствующих таблиц)
,
co.gndr_id,
co.date_of_birth,
ch2.cjt_id,
co.inn,
co.trrc,
ch2.lang_id,
ch2.lang_id doc_lang_id
FROM (SELECT ch.clnt_id,
ch.cjt_id,
LAG (ch.num_history, 1, -1) OVER (PARTITION BY ch.clnt_id ORDER BY ch.clnt_id, ch.num_history) nh,
ch.stat_id,
GREATEST (ch.stime, v_sysdate) stime -- sysdate или дата начала ближайшей истории
,
ch.lang_id,
ch.customer_id
FROM client_history ch
WHERE ch.etime > v_sysdate) ch2,
contract co
WHERE co.ROWID BETWEEN i_low_rid AND i_high_rid
AND ch2.nh = -1 -- выбираем только первую встретившуюся запись, начиная с sysdate (ее значения)
AND ch2.clnt_id = co.clnt_id
AND co.stime <= ch2.stime
AND ch2.stime < co.etime
AND ch2.customer_id IS NULL -- кроме уже обработанных
)
LOOP
...
-- получим ID нового клиента
SELECT customer_seq.NEXTVAL INTO customer_id_tb (v_idx) FROM DUAL;
trrc_tb (v_idx) := TRIM (rec.trrc);
lang_id_tb (v_idx) := rec.lang_id;
clnt_id_tb (v_idx) := rec.clnt_id;
...
-- Заполним таблицу customer
FORALL i IN 1 .. customer_id_tb.COUNT
INSERT INTO customer (customer_id,
cust_type_id,
...
-- Обновим данные в таблице client_history
FORALL i IN 1 .. customer_id_tb.COUNT
UPDATE client_history
SET customer_id = customer_id_tb (i), doc_lang_id = lang_id_tb (i)
WHERE clnt_id = clnt_id_tb (i);
...
END LOOP;
EXCEPTION
WHEN OTHERS
THEN
ROLLBACK;
raise_application_error (-20000, SQLERRM);
END;
/Выполняется подготовка среды выполнения, создание задачи для PE:
prompt Create a "place holder" for the task.
execute dbms_parallel_execute.create_task(task_name => 'migration_stage_1')Выполняется нарезка порций:
prompt create chunks...
prompt
prompt
begin
dbms_parallel_execute.create_chunks_by_rowid(
task_name => 'migration_stage_1',
table_owner => 'SMASTER',
table_name => 'CONTRACT',
by_row => false,
chunk_size => 10000
);
end;
/При вызове процедуры для нарезки порций указываться имя ранее созданной задачи (task_name), указывается имя владельца схемы и имя таблицы, данные в которой предполагается разбить равномерно. Значение параметра by_row => false определяет, что разбиение будет на основе числа блоков, а не строк в таблице. Целесообразнее делать именно поблочное разбиение, чтобы конкурентные сессии не конфликтовали между собой при обращении к одним и тем же блокам (в примере скрипте таблица CONTRACT также обновляется, поэтому это актуально. chunk_size — 10 000 блоков. В итоге получилось 206 частей.
Пакет предлагает и другие способы нарезки на порции, например, вызов CREATE_CHUNKS_BY_NUMBER_COL позволяет поделить таблицу на порции на основе диапазонов числовых идентификаторов. Удобно, если в таблице хранятся строки с монотонно‑возрастающим идентификатором, без пропусков. Еще один вариант — процедура create_chunks_by_sql. Она позволяет выполнить разделение на порции на основе пользовательского запроса, который должен вернуть диапазоны ROWID или ID, если by_rowid => false.
Результат «нарезки» можно посмотреть в представлении user_paralle_execute_chunks:
set pages 1000
select
chunk_id, status, start_rowid, end_rowid, job_name
from
user_parallel_execute_chunks
where
task_name = 'migration_stage_1'
order by
chunk_id;В результате — выполнена нарезка на порции, у каждой порции есть начальный и конечный адрес строки ROWID. Статус UNASSIGNED означает, что chunk‑и не взяты в работу.
CHUNK_ID STATUS START_ROWID END_ROWID JOB_NAME
---------- -------------------- ------------------ ------------------ ------------------------------
1 UNASSIGNED AAB5bmAALAAABGZAAA AAB5bmAALAAABGgCcP
2 UNASSIGNED AAB5bmAALAAABGhAAA AAB5bmAALAAABGoCcP
3 UNASSIGNED AAB5bmAALAAABHhAAA AAB5bmAALAAABHoCcP
4 UNASSIGNED AAB5bmAALAAAGD5AAA AAB5bmAALAAAGEACcP
...
208 UNASSIGNED AAB5bmAJrAAAJiJAAA AAB5bmAJrAAALiICcP
209 UNASSIGNED AAB5bmAJrAAALiJAAA AAB5bmAJrAAANiICcP
210 UNASSIGNED AAB5bmAJrAAANiJAAA AAB5bmAJrAAAPiICcP
210 rows selected.
Elapsed: 00:00:00.07Далее выполняется запуск. В коде указывается имя процедуры и параметры, определяющие обрабатываемую порцию за каждый вызов:
prompt start parallel execution... Jobs must be enabled!!!
declare
l_sql_stmt varchar2(2000);
begin
l_sql_stmt := 'begin
smaster.migr_stage_1(
i_low_rid=>:start_id,
i_high_rid=>:end_id);
end;';
dbms_parallel_execute.run_task(
task_name => 'migration_stage_1',
sql_stmt => l_sql_stmt,
language_flag => dbms_sql.native,
parallel_level => 16
);
end;
/
start parallel execution... Jobs must be enabled!!!
PL/SQL procedure successfully completed.
Elapsed: 00:15:01.57В момент вызова run_task сессия создает джобы, каждый из которых будет обрабатывать свою порцию. Запуск джобов должен быть разрешен в БД. Инициирующая сессия подвисает на время выполнения — ожидает завершения обработки всех порций. Для наблюдения за прогрессом целесообразно использовать запрос из предыдущего блока, а также смотреть v$active_session_history или Oracle Enterprise Manager Top Activity за прогрессом и потенциальными проблемами/ конкруренцией.
select status,count(*) from dba_parallel_execute_chunks where
task_name = 'migration_stage_1' group by status
/
STATUS COUNT()
-------------------- ----------
PROCESSED 210Итого время на все сократилось в 4 раза с 1 часа до 15 минут! А время выполнения второго скрипта сократилось в 7 раз с 6 часов до 50 минут.
Особенности
Каждая порция обрабатывается в отдельной сессии. И если pl/sql блок не делает промежуточных commit, то смигрирует либо весь chunk либо ничего. Таким образом, может получится, что отдельные порции могут не смигрировать. В такой ситуации у несмигрировавших порций будет статус PROCESSED_WITH_ERROR. Как быть?
Во‑первых, существует возможность повторно запустить обработку необработанных/ошибочных chunks. Для этого следует воспользоваться вызовом:
execute dbms_parallel_execute.resume_task(task_name => 'migration_stage_1')Во‑вторых, в dba_parallel_execute_chunks есть поля ERROR_CODE, ERROR_MESSAGE. Тут будет код и текст той ошибки, которую поймает и выдаст исходный pl/sql блок. Так что можно разобраться, исправить и также запустить повторно. Разумеется, скрипт миграции должен быть «умным» и должен браться только за те данные, что еще не были смигрированы.
И еще. Может оказаться так (вернее, оказалось именно так со вторым скриптом миграции), что запрос, выбирающий данные, подлежащие миграции, довольно тяжелый. И если при серийном выполнении pl/sql блока миграции он выполнялся долго 1 раз, то при новом подходе он будет выполняться число раз, равное числу порций. Решением может быть и стало вынос тяжелого подзапроса в отдельный скрипт, который создает временную таблицу и индекс. А дальше эти данные многократно используются конкурентными сессиями при обработке каждого chunk.
Конкуренция
Конкурентные сессии будут обрабатывать разные данные, но в одних и тех же сегментах. Если есть insert, то скорее всего будет конкуренция за ITL слоты enq: TX — allocate ITL entry. Тут же возможна и ORA-00 060 deadlock detected. Причина — при обновлении блоков разными сессиями недостаточное число слотов для идентификатора транзакции. Если блок занят на 100%, новым слотам помимо изначально выделенных (задается в параметре таблицы/индекса initrans) расти некуда и сессия ожидает с указанным enqueue. Если случается что сессия S1 ждет блок b2, который был обновлен сессией S2, а та в свою очередь захотела обновить блок b1, то возникает ORA-00 060. Решение очень простое — перед запуском скрипта миграции выполнить ALTER TABLE MOVE / ALTER INDEX REBUILD с указанием большего числа INITRANS. Лучше, если это будет большее простое число.
Кроме того, может и возникнет ожидание buffer busy waits на таблицах и индексах. Тут можно посоветовать удалить ДО и создать ПОСЛЕ индексы, за исключением может быть PRIMARY KEY, который может понадобиться при миграции, а также увеличение freelists если используется MANUAL SPACE SEGMENT MANAGEMENT.
Дополнительно почитать
1. DBMS_PARALLEL_EXECUTE
2. Oracle Scratchpad — Parallel Execution
Скрипт скоростного апдейта. Распараллеливание вручную.
Метод основан на разделении таблицы на диапазоны ID или диапазоны ROWID и генерации отдельных скриптов для обработки каждого диапазона. Обработка диапазонов или наборов диапазонов запускается параллельно в нескольких сеансах SQLPLUS.
Ниже приводится пример оператора, который генерирует текст DML запроса для обновления таблицы CLIENT_HISTORY, разбивая его на несколько (10) потоков (stream) путем формирования диапазовнов ROWID на основе параметров физического хранения таблицы, числу блоков и файлов данных
SELECT 'prompt stream #' || ppt || ' partition #' || ppn || CHR(13) || CHR(10) ||'UPDATE client_history c SET c.use_cascade_balance=(SELECT greatest(CASE WHEN t.owner_clnt_id IS NOT NULL OR (SELECT COUNT() FROM client c WHERE c.owner_clnt_id = t.clnt_id) > 0 THEN 1 ELSE 0 END ,CASE WHEN (SELECT COUNT() FROM client_balance cb WHERE cb.clnt_id = t.clnt_id) > 1 THEN 1 ELSE 0 END ,CASE WHEN (SELECT COUNT(*) FROM client_balance cb, quota q WHERE cb.clnt_id = t.clnt_id AND cb.clnt_bal_id = q.clnt_bal_id) > 0 THEN 1 ELSE 0 END) AS new_cascade_balance FROM client t WHERE t.clnt_id = c.clnt_id) '|| CHR(13) || CHR(10) ||
'WHERE c.ROWID BETWEEN ''' || min_rid || ''' AND ''' || max_rid || '''' || CHR(13) || CHR(10) || '/' || CHR(13) || CHR(10) || 'COMMIT' ||
CHR(13) || CHR(10) || '/' || CHR(13) || CHR(10) st
FROM (
SELECT MOD(grp, 10) ppt
,rank() over(PARTITION BY MOD(grp, 10) ORDER BY grp) ppn
,tt.
FROM (SELECT grp
,dbms_ROWID.ROWID_create(1, data_object_id, lo_fno, lo_block, 0) min_rid
,dbms_ROWID.ROWID_create(1, data_object_id, hi_fno, hi_block, 10000) max_rid
FROM (SELECT DISTINCT grp
,first_value(relative_fno) over(PARTITION BY grp ORDER BY relative_fno, block_id rows BETWEEN unbounded preceding AND unbounded following) lo_fno
,first_value(block_id) over(PARTITION BY grp ORDER BY relative_fno, block_id rows BETWEEN unbounded preceding AND unbounded following) lo_block
,last_value(relative_fno) over(PARTITION BY grp ORDER BY relative_fno, block_id rows BETWEEN unbounded preceding AND unbounded following) hi_fno
,last_value(block_id + blocks - 1) over(PARTITION BY grp ORDER BY relative_fno, block_id rows BETWEEN unbounded preceding AND unbounded following) hi_block
,SUM(blocks) over(PARTITION BY grp) sum_blocks
FROM (SELECT relative_fno
,block_id
,blocks
,trunc((SUM(blocks) over(ORDER BY relative_fno, block_id) - 0.01) /
(SUM(blocks) over() / 40)) grp
FROM dba_extents
WHERE segment_name = 'CLIENT_HISTORY'
AND owner = USER))
,(SELECT data_object_id FROM user_objects WHERE object_name = 'CLIENT_HISTORY')) tt)
ORDER BY ppt, ppnВ результате получается следующий код:
prompt stream #0 partition #1
UPDATE client_history c SET c.use_cascade_balance=(SELECT greatest(CASE WHEN t.owner_clnt_id IS NOT NULL OR (SELECT COUNT() FROM client c WHERE c.owner_clnt_id = t.clnt_id) > 0 THEN 1 ELSE 0 END ,CASE WHEN (SELECT COUNT() FROM client_balance cb WHERE cb.clnt_id = t.clnt_id) > 1 THEN 1 ELSE 0 END ,CASE WHEN (SELECT COUNT() FROM client_balance cb, quota q WHERE cb.clnt_id = t.clnt_id AND cb.clnt_bal_id = q.clnt_bal_id) > 0 THEN 1 ELSE 0 END) AS new_cascade_balance FROM client t WHERE t.clnt_id = c.clnt_id)
WHERE c.ROWID BETWEEN 'AAAsk5AAAAAEjbgAAA' AND 'AAAsk5AABAACpp/CcQ'
/
COMMIT
/
prompt stream #0 partition #2
UPDATE client_history c SET c.use_cascade_balance=(SELECT greatest(CASE WHEN t.owner_clnt_id IS NOT NULL OR (SELECT COUNT() FROM client c WHERE c.owner_clnt_id = t.clnt_id) > 0 THEN 1 ELSE 0 END ,CASE WHEN (SELECT COUNT() FROM client_balance cb WHERE cb.clnt_id = t.clnt_id) > 1 THEN 1 ELSE 0 END ,CASE WHEN (SELECT COUNT(*) FROM client_balance cb, quota q WHERE cb.clnt_id = t.clnt_id AND cb.clnt_bal_id = q.clnt_bal_id) > 0 THEN 1 ELSE 0 END) AS new_cascade_balance FROM client t WHERE t.clnt_id = c.clnt_id)
WHERE c.ROWID BETWEEN 'AAAsk5AABAACwmAAAA' AND 'AAAsk5AABAACw1/CcQ'
/
COMMIT
/
prompt stream #0 partition #3
UPDATE client_history c SET c.use_cascade_balance=(SELECT greatest(CASE WHEN t.owner_clnt_id IS NOT NULL OR (SELECT COUNT() FROM client c WHERE c.owner_clnt_id = t.clnt_id) > 0 THEN 1 ELSE 0 END ,CASE WHEN (SELECT COUNT() FROM client_balance cb WHERE cb.clnt_id = t.clnt_id) > 1 THEN 1 ELSE 0 END ,CASE WHEN (SELECT COUNT(*) FROM client_balance cb, quota q WHERE cb.clnt_id = t.clnt_id AND cb.clnt_bal_id = q.clnt_bal_id) > 0 THEN 1 ELSE 0 END) AS new_cascade_balance FROM client t WHERE t.clnt_id = c.clnt_id)
WHERE c.ROWID BETWEEN 'AAAsk5AABAADAgAAAA' AND 'AAAsk5AABAADAv/CcQ'
/
COMMIT
/
prompt stream #1 partition #1
UPDATE client_history c SET c.use_cascade_balance=(SELECT greatest(CASE WHEN t.owner_clnt_id IS NOT NULL OR (SELECT COUNT() FROM client c WHERE c.owner_clnt_id = t.clnt_id) > 0 THEN 1 ELSE 0 END ,CASE WHEN (SELECT COUNT() FROM client_balance cb WHERE cb.clnt_id = t.clnt_id) > 1 THEN 1 ELSE 0 END ,CASE WHEN (SELECT COUNT(*) FROM client_balance cb, quota q WHERE cb.clnt_id = t.clnt_id AND cb.clnt_bal_id = q.clnt_bal_id) > 0 THEN 1 ELSE 0 END) AS new_cascade_balance FROM client t WHERE t.clnt_id = c.clnt_id)
WHERE c.ROWID BETWEEN 'AAAsk5AABAACpqAAAA' AND 'AAAsk5AABAACqJ/CcQ'
/
COMMIT
/
....
prompt stream #9 partition #4
UPDATE client_history c SET c.use_cascade_balance=(SELECT greatest(CASE WHEN t.owner_clnt_id IS NOT NULL OR (SELECT COUNT() FROM client c WHERE c.owner_clnt_id = t.clnt_id) > 0 THEN 1 ELSE 0 END ,CASE WHEN (SELECT COUNT() FROM client_balance cb WHERE cb.clnt_id = t.clnt_id) > 1 THEN 1 ELSE 0 END ,CASE WHEN (SELECT COUNT(*) FROM client_balance cb, quota q WHERE cb.clnt_id = t.clnt_id AND cb.clnt_bal_id = q.clnt_bal_id) > 0 THEN 1 ELSE 0 END) AS new_cascade_balance FROM client t WHERE t.clnt_id = c.clnt_id)
WHERE c.ROWID BETWEEN 'AAAsk5AABAADGAAAAA' AND 'AAAsk5AABAADGP/CcQ'
/
COMMIT
/Операторы каждого из 10 потоков помещаются каждый в свой *.sql файл и запускаются одновременно, например, через sqlplus. 10 сессий, каждая отработает по 4 оператора и это будет значительно быстрее, если бы этот UPDATE работал в 1 поток.
Данный метод хорошо подходит для Oracle SE2, в котором нет поддержки Parallel DML. Используя этот метод, задачу можно распараллелить.
Удобство данного метода по сравнению с штатным пакетом DBMS_PARALLEL_EXECUTION еще и в том, что запуская задачу через sqlplus в несколько потоков, мы не зависим от джобов Oracle, которые обычно отключаются на время апгрейда.
Ускорение создания ограничений целостности
Создание ограничений целостности на большие таблицы может занимать длительное время, например создание внешнего ключа по SUBS_ID на таблице BIG_TABLE занимает 10 минут.
set timing on
ALTER TABLE SMASTER.BIG_TABLE
ADD CONSTRAINT BIG_TABLEFK
FOREIGN KEY (SUBS_ID)
REFERENCES SMASTER.SUBSCRIBER (SUBS_ID);
set timing off
Table altered.
Elapsed: 00:10:08.38Данную операцию можно ускорить:
set timing on
ALTER TABLE SMASTER.BIG_TABLE
ADD CONSTRAINT BIG_TABLEFK
FOREIGN KEY (SUBS_ID)
REFERENCES SMASTER.SUBSCRIBER (SUBS_ID) NOVALIDATE;
set timing off
Table altered.
Elapsed: 00:00:00.03Ограничение целостности создалось и уже работает для всех новых транзакций, однако текущие данные еще не проверены. Далее следует сделать операцию VALIDATE. Первый вариант — запуск VALIDATE в режиме параллельного DDL:
alter table SMASTER.BIG_TABLE parallel 8;
alter session enable parallel ddl;
set timing on
ALTER TABLE SMASTER.BIG_TABLE MODIFY CONSTRAINT BIG_TABLEFK ENABLE VALIDATE;
set timing off
alter table SMASTER.BIG_TABLE noparallel;
Table altered.
Session altered.
Table altered.
Elapsed: 00:01:10.91
Table altered.Ускорение почти в 10 раз, с 10 минут 8 секунд до 1 минуты 10 секунд!
Важно не забыть обнулить degree у таблицы, выполнив команду ALTER TABLE… NOPARALLEL; чтобы избежать нежелательных проблем в будущее.
Второй вариант — текущие скрипты оставить как есть, а операцию VALIDATE для ограничения целостности вынести в отдельный скрипт, post patch. Подобные отложенные операции запускать уже после того как основное обновление на БД запущено, во время выполнения проверок, тестов и даже запуска сервисов.
--post patch, phase 2
ALTER TABLE SMASTER.BIG_TABLE MODIFY CONSTRAINT BIG_TABLEFK ENABLE VALIDATE;
Table altered.
Elapsed: 00:09:36.13Операция будет выполняться примерно те же 10 минут, однако это время будет уже за пределами критического окна на выполнение работ по установке обновлений. Данный вариант очень хорошо подходит для Oracle Standard Edition 2, в котором параллельные операции DDL и DML не поддерживаются.
По методам распараллеливания у меня все, но есть еще несколько моментов, которые могут оказать влияние на время установки патчей.
DB_FILE_MULTIBLOCK_READ_COUNT
Параметр позволяет минимизировать число операций ввода-вывода во время сканирования таблиц. Он определяет максимальное количество блоков, считываемых за одну операцию ввода-вывода во время последовательного сканирования.
Для OLTP систем, с целью предпочтительного использования индексов, значение параметра может быть установлено в значения от 4 до 16 и поэтому, при выполнении массовых изменений данных или выполнения реорганизации объектов, стоит проверить установленное значение и выставить на уровне сессии в более подходящее. Максимальный размер операции ввода-вывода зависит от ограничений операционной системы и в случае указания большего значения будет действовать максимально возможное.
alter session set db_file_multiblock_read_count=128;Почитать дополнительно.
Nologging
Очень часто в патчах приходится сталкиваться с тем, что в DDL командах используются операнды NOLOGGING. Да, данный операнд в ряде случаев позволяет уменьшить размер информации, записываемой в журналы транзакций Oracle Redo Logs, однако у всех наших заказчиков используется решение по отказоустойчивости — Standby Database, изменение в которую реплицируются как раз с помощью журналов транзакций. С целью исключения возможности не передачи на резервную БД каких‑либо изменений в основной и появлению факта рассихронизации при создании Disaster Recovery (DR) конфигурации на уровне БД включается режим FORCELOGGING и с этого момента указание NOLOGGING на отдельных операциях не имеет никакого смысла.
В т
