Как мы собираем общие сведения о парке из Kubernetes-кластеров

Имея в обслуживании большой (более 150) парк Kubernetes-кластеров, всегда хотелось иметь удобное представление их общего состояния, в том числе и для того, чтобы поддерживать их гомогенными. В первую очередь нас интересовали следующие данные:
версия Kubernetes — чтобы все кластеры были on the edge;
версия Deckhouse (наша Kubernetes-платформа) — для лучшего планирования релизных циклов;
количество узлов с разбивкой по типам (управляющие, виртуальные и статические) — для отдела продаж;
количество ресурсов (CPU, memory) на управляющих узлах;
на какой инфраструктуре запущен кластер (виртуальные облачные ресурсы, bare metal или гибридная конфигурация);
какой облачный провайдер используется.
И вот каким был наш путь к тому, чтобы превратить эту потребность в наглядную реальность…
Истоки и проверка концепции
В какой-то момент времени мы стали использовать Terraform для раскатки инфраструктуры в облака и вопрос отслеживания соответствия желаемых конфигураций реальности встал еще острее. Мы храним Terraform state в самих кластерах и проверку соответствия их с реальностью проверяет отдельно написанный Prometheus exporter. Хотя ранее у нас уже была информация для реагирования на изменения (через соответствующие алерты в системе управления инцидентами), хотелось ещё иметь полное представление о ситуации в отдельной аналитической системе.
Итак, изначально в качестве PoC был несложный Bash-скрипт, которым мы вручную время от времени собирали интересующие данные с K8s-кластеров по SSH. Он выглядел примерно так:
((kubectl -n d8-system get deploy/deckhouse -o json | jq .spec.template.spec.containers[0].image -r | cut -d: -f2 | tr "\n" ";") &&
(kubectl get nodes -l node-role.kubernetes.io/master="" -o name | wc -l | tr "\n" ";") &&
(kubectl get nodes -l node-role.kubernetes.io/master="" -o json | jq "if .items | length > 0 then .items[].status.capacity.cpu else 0 end" -r | sort -n | head -n 1 | tr "\n" ";") &&
(kubectl get nodes -l node-role.kubernetes.io/master="" -o json | jq "if .items | length > 0 then .items[].status.capacity.memory else \"0Ki\" end | rtrimstr(\"Ki\") | tonumber/1000000 | floor" | sort -n | head -n 1 | tr "\n" ";") &&
(kubectl version -o json | jq .serverVersion.gitVersion -r | tr "\n" ";") &&
(kubectl get nodes -o wide | grep -v VERSION | awk "{print \$5}" | sort -n | head -n 1 | tr "\n" ";") &&
echo "") | tee res.csv
sed -i '1ideckhouse_version;mastersCount;masterMinCPU;masterMinRAM;controlPlaneVersion;minimalKubeletVersion' res.csv(Здесь приведен лишь фрагмент для демонстрации общей идеи.)
Однако количество клиентов и кластеров росло — стало ясно, что дальше так жить нельзя. Мы ведь инженеры, поэтому всё, что может быть автоматизировано, должно быть автоматизировано.
Так начался наш путь разработки волшебного агента для кластеров, который бы:
собирал желаемую информацию,
агрегировал ее,
отправлял в какое-то централизованное хранилище.
…, а заодно — соответствовал каноном высокой доступности и cloud native.
Этот путь дал начало истории модуля в Kubernetes-платформе Deckhouse, развёрнутой на всех наших кластерах, и сопутствующего ему хранилища.
Реализация
Хуки на shell-operator
В первой итерации источником данных в клиентских кластерах служили Kubernetes-ресурсы, параметры из ConfigMap/Deckhouse, версия образа Deckhouse и версия control-plane из вывода kubectl version. Для соответствующей реализации лучше всего подходил shell-operator.
Были написаны хуки (да, снова на Bash) с подписками на ресурсы и организована передача внутренних values. По результатам работы этих хуков мы получали список желаемых Prometheus-метрик (их экспорт поддерживается в shell-operator «из коробки»).
Вот пример хука, генерирующего метрики из переменных окружения, — он прост и понятен:
#!/bin/bash -e
for f in $(find /frameworks/shell/ -type f -iname "*.sh"); do
source $f
done
function __config__() {
cat << EOF
configVersion: v1
onStartup: 20
EOF
}
function __main__() {
echo '
{
"name": "metrics_prefix_cluster_info",
"set": '$(date +%s)',
"labels": {
"project": "'$PROJECT'",
"cluster": "'$CLUSTER'",
"release_channel": "'$RELEASE_CHANNEL'",
"cloud_provider": "'$CLOUD_PROVIDER'",
"control_plane_version": "'$CONTROL_PLANE_VERSION'",
"deckhouse_version": "'$DECKHOUSE_VERSION'"
}
}' | jq -rc >> $METRICS_PATH
}
hook::run "$@"Отдельно хочу обратить ваше внимание на значение метрики (параметр set). Изначально мы писали туда просто 1, но возник резонный вопрос: «Как потом получить через PromQL именно последние, свежие labels, включая те series, которые уже две недели не отправлялась?» Например, в том же MetricsQL от VictoriaMetrics для этого есть специальная функция last_over_time. Оказалось, достаточно в значение метрики отправлять текущий timestamp — число, которое постоянно инкрементируется во времени. Вуаля! Теперь стандартная функция агрегации max_over_time из Prometheus выдаст нам самые последние значения labels по всем series, которые приходили хоть раз в запрошенном периоде.
Чуть позже к источникам данных добавились метрики из Prometheus в кластерах. Для их получения был написан еще один хук, который через curl ходил в кластерный Prometheus, подготавливал полученные данные и экспортировал их в виде метрик.
Чтобы вписаться в парадигму cloud-native и обеспечить HA агента, мы запустили его в несколько реплик на управляющих узлах кластера.
Grafana Agent
Оставалось как-то донести полученные метрики до централизованного хранилища, а также обеспечить их кэширование на стороне кластера — на случай временной недоступности хранилища, связанной с его обслуживанием или модернизацией.
Выбор пал на разработку Grafana Labs, а именно — Grafana Agent. Он умеет делать scrape метрик с endpoint«ов, отправлять их по протоколу Prometheus remote write, а также (что немаловажно!) ведет свой WAL на случай недоступности принимающей стороны.
Задумано — сделано: и вот приложение из shell-operator и sidecar«ом с grafana-agent уже способно собирать необходимые данные и гарантировать их поступление в центральное хранилище.
Конфигурация агента делается довольно просто — благо, все параметры подробно описаны в документации. Вот пример нашего итогового конфига:
server:
log_level: info
http_listen_port: 8080
prometheus:
wal_directory: /data/agent/wal
global:
scrape_interval: 5m
configs:
- name: agent
host_filter: false
max_wal_time: 360h
scrape_configs:
- job_name: 'agent'
params:
module: [http_2xx]
static_configs:
- targets:
- 127.0.0.1:9115
metric_relabel_configs:
- source_labels: [__name__]
regex: 'metrics_prefix_.+' - source_labels: [job]
action: keep
target_label: cluster_uuid
replacement: {{ .Values.clusterUUID }}
- regex: hook|instance
action: labeldrop
remote_write:
- url: {{ .Values.promscale.url }}
basic_auth:
username: {{ .Values.promscale.basic_auth.username }}
password: {{ .Values.promscale.basic_auth.password }}Пояснения:
Директория
/data— это volumeMount для хранения WAL-файлов;Values.clusterUUID— уникальный идентификатор кластера, по которому мы его идентифицируем при формировании отчетов;Values.promscaleсодержит информацию об endpoint и параметрах авторизации для remote_write.
Хранилище
Разобравшись с отправкой метрик, необходимо было решить что-то с централизованным хранилищем.
Ранее у нас были попытки подружиться с Cortex, но, по всей видимости, на тот момент инженерная мысль его разработчиков не достигла кульминации: пугающая обвязка вокруг него в виде Cassandra и других компонентов не дала нам успеха. Поэтому мы данную затею отложили и, памятуя о прошлом опыте, использовать его не стали.
NB. Справедливости ради, хочется отметить, что на данный момент Cortex выглядит уже вполне жизнеспособным, «оформленным» как конечный продукт. Очень вероятно, что через какое-то время вернемся к нему и будем использовать. Уж очень сладко при мысли о generic S3 как хранилище для «БД»: никаких плясок с репликами, бэкапами и растущим количеством данных…
К тому времени у нас была достаточная экспертиза по PostgreSQL и мы выбрали Promscale как бэкенд. Он поддерживает получение данных по протоколу remote-write, а нам казалось, что получать данные используя pure SQL — это просто, быстро и незатратно: сделал VIEW«хи и обновляй их, да выгружай в CSV.
Разработчики Promscale предоставляют готовый Docker-образ, включающий в себя PostgreSQL со всеми необходимыми extensions. Promscale использует расширение TimescaleDB, которое, судя по отзывам, хорошо справляется как с большим количеством данных, так и позволяет скейлиться горизонтально. Воспользовались этим образом, задеплоили connector — данные полетели!
Далее был написан скрипт, создающий необходимые views, обновляющий их время от времени и выдающий на выход желаемый CSV-файл. На тестовом парке dev-кластеров всё работало отлично: мы обрадовались и выкатили отправку данных со всех кластеров.
Но с хранилищем всё не так просто
Первую неделю всё было отлично: данные идут, отчет генерируется. Сначала время работы скрипта составляло около 10 минут, однако с ростом количества данных это время увеличилось до получаса, а однажды и вовсе достигло 1 часа. Смекнув, что что-то тут не так, мы пошли разбираться.
Как оказалось, ходить в таблицы базы данных — мимо магических оберток, предоставляемых Promscale (в виде своих функций и views, опирающихся в свою очередь на функции TimescaleDB), — невероятно неэффективно.
Было решено перестать «ковыряться в потрохах» данных и положиться на мощь и наработки разработчиков Promscale. Ведь их connector может не только складывать данные в базу через remote-write, но и позволяет получать их привычным для Prometheus способом — через PromQL.
Одним Bash«ем уже было не обойтись — мы окунулись в мир аналитики данных с Python. К нашему счастью, в сообществе уже были готовы необходимые инструменты и для походов с PromQL! Речь про замечательный модуль prometheus-api-client, который поддерживает представление полученных данных в формате Pandas DataFrame.
В этот момент еще сильнее повеяло взрослыми инструментами из мира аналитики данных… Мотивированные «на пощупать» интересное и доселе неизведанное, мы двинулись в этом направлении и не прогадали. Лаконичность и простота «верчения» этой кучей данных через Pandas DataFrame доставила массу позитивных эмоций. И по сей день поддержка полученной кодовой базы, добавление новых параметров и всевозможные правки отображения финальных данных воспринимаются как праздник программиста и не требуют большого количества времени.
Изначально мы выбрали период скрейпинга данных grafana-agent«ом равным одной минуте, что отразилось на огромных аппетитах конечной БД в диске: ~800 мегабайт данных в день. Это, конечно, не так много в масштабах одного кластера (~5 мегабайт), но когда кластеров много — суммарный объём начинает пугать. Решение оказалось простым: увеличили период scrape«а в конфигах grafana-agent«ов до одного раза в 5 минут. Прогнозируемый суммарный объем хранимых данных с retention«ом в 5 лет уменьшился с 1,5 Тб до 300 Гб, что, согласитесь, уже выглядит не так ужасающе.
Некоторый профит от выбора PostgreSQL как конечного хранилища мы уже получили: для успешного переезда хранилища в финальный production-кластер достаточно было отреплицировать базу. Единственное текущий недостаток — пока не получилось самостоятельно собрать свой кастомный PostgreSQL с необходимыми расширениями. После пары неудачных попыток мы остались на готовом образе от разработчиков Promscale.
Получившаяся архитектура выглядит так:

Итоги и перспективы
Мы смотрим в будущее и планируем отказаться от отчётов в формате CSV в пользу красивого интерфейса собственной разработки. А по мере разработки собственной биллинговой системы начнём отгружать данные и туда — для нужд отдела продаж и развития бизнеса. Но даже те CSV, что мы получили сейчас, уже сильно упрощают рабочие процессы всего «Фланта».
А пока не дошли руки до фронтенда, мы сделали dashboard для Grafana (почему бы и нет, раз всё в стандартах Prometheus?…). Вот как это выглядит:
 Общая сводная таблица по кластерам с Terraform-состояниями
Общая сводная таблица по кластерам с Terraform-состояниями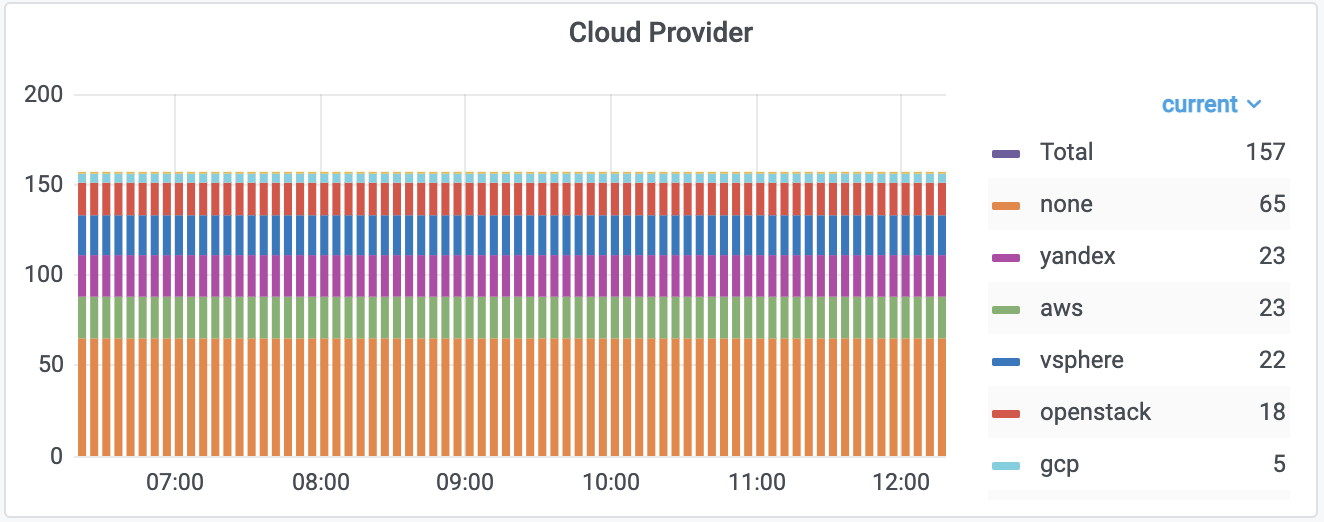 Распределение кластеров по облачным провайдерам
Распределение кластеров по облачным провайдерам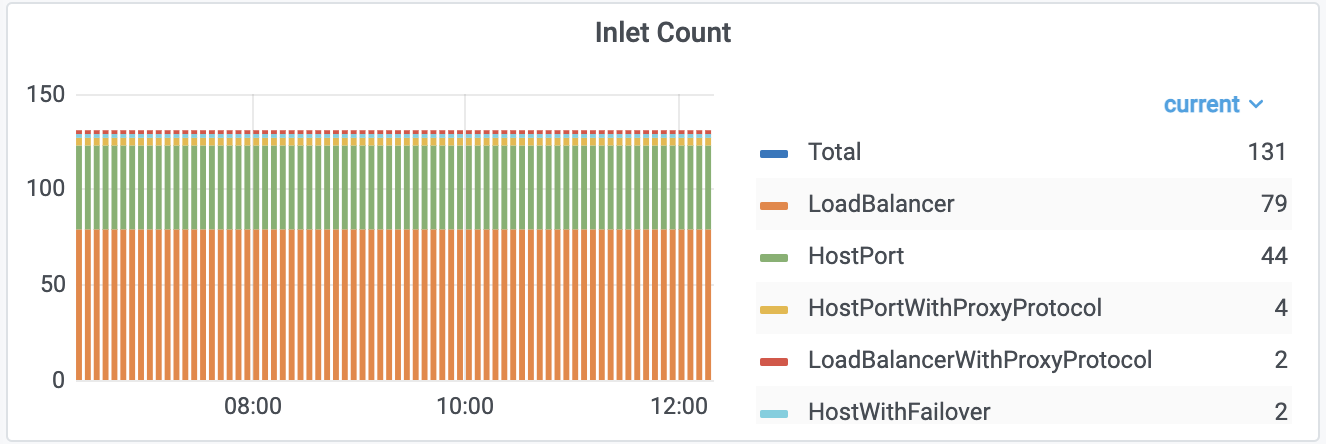 Разбивка по используемым Inlet в Nginx Ingress-контроллерах
Разбивка по используемым Inlet в Nginx Ingress-контроллерах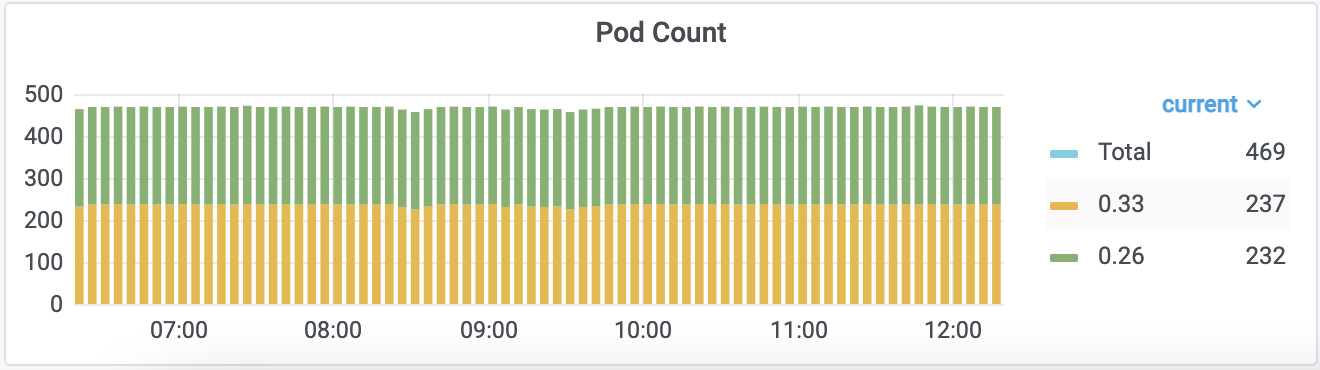 Количество pod«ов Nginx Ingress-контроллеров с разбивкой по версиям
Количество pod«ов Nginx Ingress-контроллеров с разбивкой по версиямВпереди нас ждет продолжение пути автоматизации всего и вся с уменьшением необходимости ручных действий. В числе первых горячо ожидаемых «плюшек» — переход к автоматическому применению изменений конфигураций Terraform, если таковые не подразумевают удаление каких-либо ресурсов (не являются деструктивными для кластера).
P.S.
Читайте также в нашем блоге:
