Как мы помогли крупному бразильскому банку справиться с последствиями деноминации
 Новейшая история денежного обращения в Бразилии — это череда деноминаций, первая из которых была проведена в 1942 году, а последняя — в 1994 году. К 1994 году национальная валюта Бразилии — крузейро — была настолько слабой, что в магазинах цены назначались в условных единицах, рядом с цифрами писали слово «real» — «настоящая» цена. В 1994 от лишних нулей решили избавиться, а слово «real», к которому все привыкли, стало названием новой валюты — реал (впрочем, точно так же называлась денежная единица Бразилии до 1942 года).
Новейшая история денежного обращения в Бразилии — это череда деноминаций, первая из которых была проведена в 1942 году, а последняя — в 1994 году. К 1994 году национальная валюта Бразилии — крузейро — была настолько слабой, что в магазинах цены назначались в условных единицах, рядом с цифрами писали слово «real» — «настоящая» цена. В 1994 от лишних нулей решили избавиться, а слово «real», к которому все привыкли, стало названием новой валюты — реал (впрочем, точно так же называлась денежная единица Бразилии до 1942 года). Сегодня мы расскажем, как один из наших продуктов — ABBYY FineReader Engine помог крупнейшему частному бразильскому банку справиться с последствиями деноминации. Не представляете, как такое может быть? Добро пожаловать под кат.
Когда происходили деноминации конца 80-х годов, нули «исчезали» не только с денежных купюр — суммы на банковских счетах граждан также были скорректированы — разумеется, в пользу банков. На тот момент это были такие незначительные суммы, что никто не требовал у банков возмещения убытков. В 2007 году (то есть восемнадцать лет спустя) один предприимчивый бразильский гражданин посчитал, что с учётом процентов за полтора десятка лет «пропавшая» сумма стала не такой уж маленькой, и обратился в банк с требованием выплатить проценты, банк отказал и гражданин обратился с иском в суд. Суд признал требования законными и обязал банк возместить ущерб.
В этот момент стало понятно, что таких обращений будет очень много. Для обращения в суд была необходима информация о состоянии счёта (такой документ называется Bank Statement) на момент деноминации, и банки были обязаны предоставлять эту информацию держателям счетов.

В период, когда происходила деноминация, вся информация о состоянии счетов в банке была распечатана, сфотографирована и переведена на микрофиши (microfiche).
Плёнки хранились в архиве, и было понятно, что, если за этими данными придут тысячи людей, вся другая работа в банке встанет — рабочего времени сотрудников хватит только на то, чтобы ходить в архив, искать нужную плёнку и выдавать справки клиентам. В банке решили, что нужно перевести информацию с микрофишей в электронный вид — и здесь пригодились мы.
Нужно было в максимально сжатые сроки отсканировать все микрофиши на специальном сканере (использовали сканеры Wicks and Wilson и Kodak), извлечь данные — имя клиента, номер счёта и сумму — и поместить всё это в базу данных (Microsoft SQL Server). Сканы предстояло обрабатывать одному из наших продуктов — ABBYY FineReader Engine с использованием шаблонов, сделанных в ABBYY FormReader.
Схема работы в этом проекте была более-менее стандартная: сканирование — распознавание и извлечение данных — сохранение данных в базе — верификация:

Перед распознаванием изображения обрабатывались: убирались искажения, «шум».
Поскольку микрофиши хранились почти 20 лет в архиве, их состояние было средним, качество сканов, соответственно тоже, но сложность состояла не только в этом. Дело в том, что Bank Statement были напечатаны либо на матричных принтерах, либо на печатных машинках, а для распознавания таких документов применяется специальная технология и о ней есть смысл рассказать подробнее. Да простит нас читатель — в качестве примеров мы будем приводить не бразильские картинки, а изображения из нашей тестовой базы.
В наших продуктах есть несколько типов распознавания текста. Конечно, можно всё распознавать в стандартном режиме, но на текстах, напечатанных нестандартными шрифтами, качество может быть плохое. В этом случае можно выбрать один из специальных режимов: в нашем случае есть отдельные режимы и для матричного принтера, и для печатной машинки.
Как минимум, разные типы текста отличаются друг от друга разными эталонами — то есть для каждого типа текста характерно своё начертание символов. Начертания символов матричного принтера сильно отличаются от обычных, поэтому для них существуют специальные, отдельные эталоны. Мы старались собрать библиотеку шрифтов с разных принтеров. Для лучшего распознавания в базу «матричных» эталонов добавляем некоторое количество обычных — например, символы из моноширинного шрифта Courier New.


Помимо этого в коде различные типы данных обрабатываются по-разному. И матричный принтер, и печатная машинка используют моноширинные шрифты — в таких шрифтах ширина каждого знакоместа постоянна, в отличие от многих других шрифтов, и символы в соседних строках располагаются один над другим.

Как вы помните, один из этапов распознавания — это выделение строк. Когда мы выделяем строки на текстах, напечатанных моноширинными шрифтами, мы, прежде всего, пытаемся наложить на текст сетку — чтобы каждый символ оказался на своем месте.
Помимо этого, строчки выделяются с параметрами, которые отличаются от тех, что применяются при выделении строк на обычных шрифтах, — например, в обычном матричном принтере буквы с диакритикой (и прописные, и строчные) в любом случае попадают целиком в знакоместо.

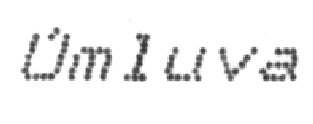
Получается, что обрабатывать диакритику отдельно и приклеивать к общим строкам не надо.
Ещё одна задача — правильно определить, какие пробелы считать интервалами между словами, а какие — расстоянием между буквами. В моноширинных шрифтах между символами i и l остаётся много места, и наши алгоритмы могут принимать их за пробелы.


Выделение пробелов у нас, в основном, происходит так: мы смотрим гистограмму, считаем все белые просветы. Обычно получается, что большие просветы — это расстояние между словами, маленькие — между буквами, а в описываемом примере расстояния получаются средними и программа может ошибиться, разбив слово на два там, где этого не нужно делать. Но если мы отметим тип текста «Матричный принтер», на текст наложится сетка, и будет видно, что этот просвет среднего размера попадает в промежуток между соседними ячейками — так мы понимаем, что это не пробел между словами (пробел — это целая пустая ячейка). Бывают случаи, когда матричный принтер плохо печатает, буквы накладываются друг на друга, и сетку невозможно построить. Или если лента в печатной машинке протягивается, и строки печатаются со сдвигом.


В таких вариантах сетку наложить трудно и мы используем обычные алгоритмы распознавания.
Следующая сложность связана с тем, как напечатан сам символ.
Матричные принтеры бывают разные. Вот это вполне хороший матричный принтер, такой текст можно даже попробовать распознать в обычном режиме.

А вот этот текст напечатан на старом принтере — в буквах видны отдельные точки и расстояния между ними.


Если мы указали тип текста «Матричный принтер», программа может выбрать сама один из двух режимов. Один — когда мы пробуем использовать те эталоны, что у нас есть. Второй — так называемый «драфт-режим» — когда внутри символа расстояние между точками заливается. Это очень помогает при работе с символами, в которых расстояние между точками большое — если его не залить, наши алгоритмы могут решить, что букв не одна, а две; начнёт проверять и искать соответствия для двух отдельных частей.


По нескольким параметрам программа решает, нужно ли попробовать применить «драфт-режим». Для начала на нескольких фрагментах, строчках, мы убеждаемся, что лучшая гипотеза — «драфт», если это так — начинаем заливать все остальные символы. Если лучшая гипотеза — не «драфт», то запускать этот режим мы, в принципе, можем, но только на отдельных символах, когда какой-то из них очень плохо распознался.
Кроме плохого качества пропечатки символов есть другая сложность — во времена, когда пользовались матричными принтерами, часто экономили бумагу и печатали в condense-режиме (узкий шрифт, маленькое расстояние между буквами).

В печатной машинке сложности те же — за небольшим исключением. Тексты, напечатанные на машинке, характеризуются очень большими дефектами букв. Лента выцветает, на буквы налипает краска, мусор и т.п.


Также много «мусора» между строками и между буквами, это усложняет распознавание.

Ещё одна тонкость в работе с такими текстами — верхние и нижние индексы. В печатных машиниках, чтобы напечатать индекс, сдвигают каретку на полстроки вверх или вниз. Размер шрифта при этом остается такой же, а у нас при обычном распознавании считается, что шрифт индексов должен быть меньше, — это предусмотрена в режиме «Печатная машинка».

Ещё в текстах, напечатанных на машинке, могут быть неровные расстояния между строчками.

Ну вот, собственно, и все отличия.
В заключение — традиционная статистика проекта. Всего за 3 месяца было обработано около 2,4 миллиона документов — и банк успешно справился с наплывом обращений граждан.
Текст написан в соавторстве с Джао Ротта (Joao Rotta), менеджером по развитию бизнеса ABBYY в Бразилии
Комментарии (1)
 EndUser
EndUser
6 июля 2016 в 00:22
0↑
↓
Рассказ впечатляет.
Поздравляю с подвигом! Желаю и дальше уверенным шагом доказывать конкурентам, что вы круче. :-)
