Как мы поддерживаем стабильность приложения Lamoda
Всем привет!
Меня зовут Виталий Бендик. Я тимлид команды разработки Android приложения в компании Lamoda. В 2018 году я выступал на Mosdroid Aluminium c докладом, расшифровкой которого хочу поделиться.

Речь пойдет о том, как мы поддерживаем стабильность мобильного приложения. Для нас это очень важно, так как наша мобильная аудитория составляет миллионы пользователей. Кроме того, по доле в заказах наших клиентов приложения давно обогнали сайты, dekstop и mobile версии в сумме, а платформа iOS стала абсолютным лидером, опередив dekstop сайт.
В докладе я расскажу:
- что мы понимаем под стабильностью приложения;
- об архитектуре нашего мобильного приложения;
- о процессах, практиках и инструментах, которые мы используем.
Итак, что для нас стабильное приложение? Это приложение, которое не падает, не виснет и работает предсказуемо. Когда я говорю, что не падает, я подразумеваю, что оно не падает как минимум у 95%-99% пользователей.
Архитектура

Как вы уже могли догадаться, на данном изображении представлена чистая архитектура, которой мы и стараемся придерживаться. В качестве Presentation слоя у нас используется MVP с некоторыми дополнениями, о которых я расскажу ниже.
Наше мобильное приложение адаптировано как для телефонов, так и для планшетов. Поэтому верстка часто различается, но состоит из похожих или одинаковых блоков. В связи с этим у нас есть такая сущность как Widget. Она позволяет декомпозировать активити или фрагмент на более маленькие блоки, которые можно переиспользовать в других экранах. Это имеет смысл, так как с точки зрения кода, который находится во фрагменте или в активити, достаточно редко приходится различать, в контексте какого UI он выполняется. И эти фрагменты кода можно вынести в некоторые абстракции и переиспользовать. Этот подход чем-то напоминает библиотеку от SoundCloud — LightCycle.



Product page. Примеры элементов Widget
Что касается взаимодействия presenter с моделью, то здесь все стандартно: presenter через interactor взаимодействует с остальной частью приложения, будь то репозитории или менеджеры.
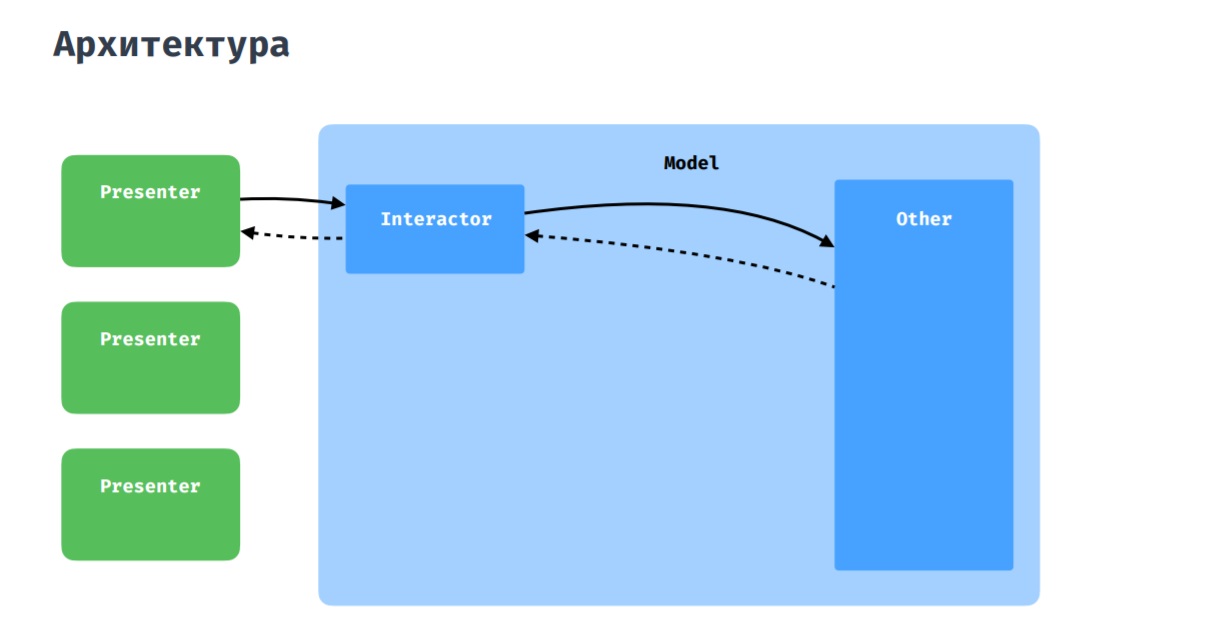
Бывает, что нескольким presenterам нужно коммуницировать между собой, обмениваться данными. Для этого у нас есть coordinator, который можно воспринимать как расшаренный interactor между несколькими presenterами.

Стек
— Весь новый код мы пишем на Kotlin, а в качестве реализации MVP используем Moxy.
— В качестве DI мы используем Dagger2.
— Для работы с сетью — Retrofit.
— Для работы с картинками — Glide.
— Крэши складываем в New Relic.
— Также мы применяем Lottie.
— На данный момент мы активно используем Kotlin Coroutines.
Процесс разработки
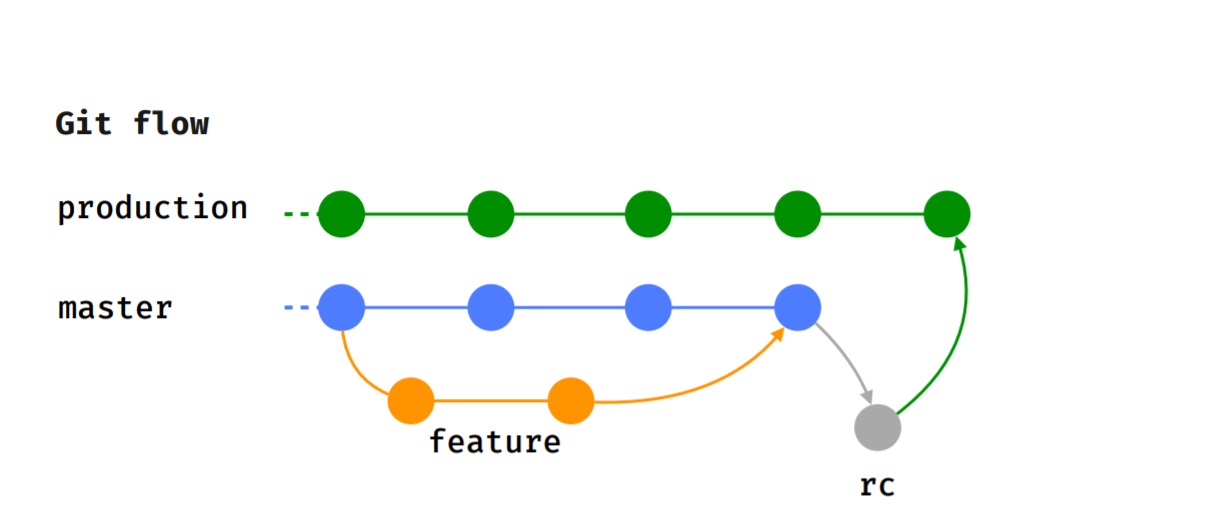
Мы придерживаемся Git flow, то есть каждая фича реализуется в отдельной feature-ветке, которая после код-ревью отдается на тестирование.
После того, как тестировщик успешно закончил тестирование, а мы определились с версией, в которую пойдет эта фича, она вливается в мастер.
Когда наступает время релиза (мы релизимся каждые 2 недели), отводится rc-ветка, на которой проводится smoke-тестирование, прогоняются тест-кейсы. После чего фича вливается в production-ветку и публикуется в Google Play Beta.
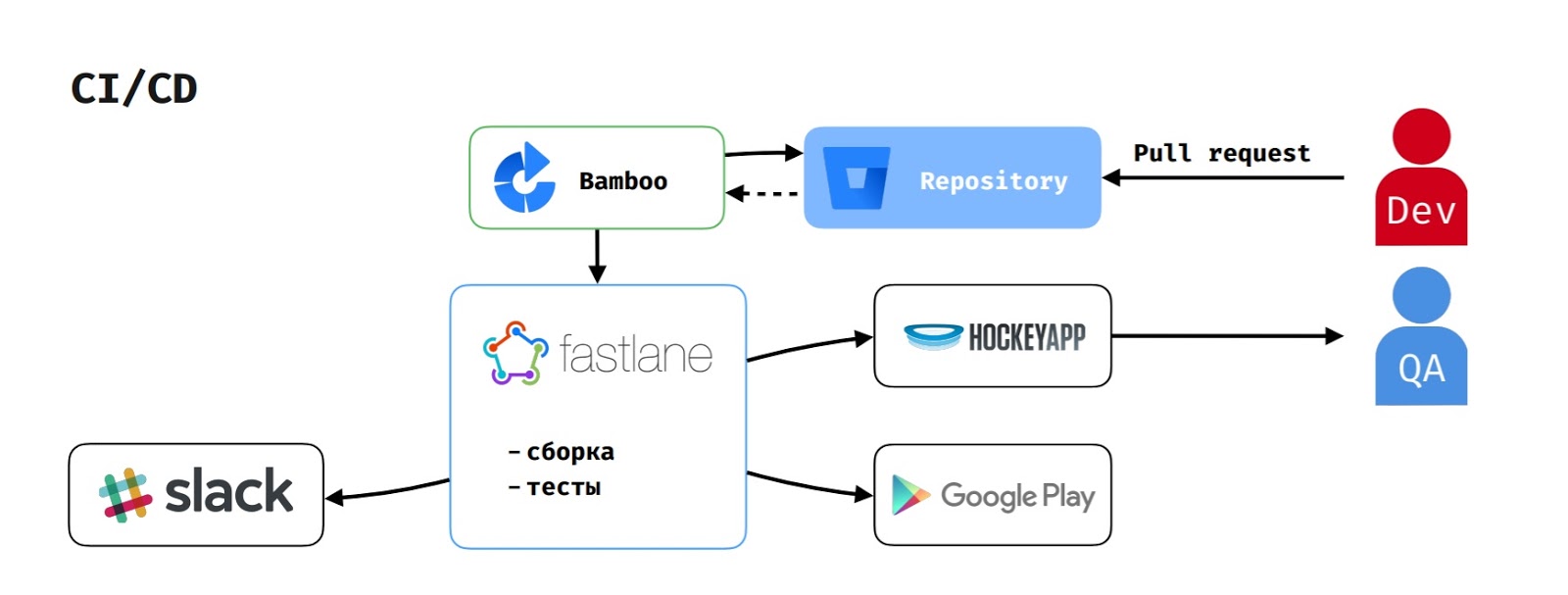
Что касается CI/CD, то так как мы используем Atlassian стек, в качестве build-сервера выступает Bamboo.
Когда разработчик создает pull-request, на Bamboo запускается задача на сборку. Она вытягивает код из репозитория, запускает скрипт на fastlane, который собирает приложение, прогоняет тесты и сообщает об этом в Slack.
Если сборку запустил тестировщик для того, чтобы протестировать фичу, то в HockeyApp ещё и загружается apk.
Для публикации релиза в Google Play Beta delivery-менеджер запускает соответствующую задачу на Bamboo, которая прогоняет тот же самый флоу, но ещё и выкладывает версию в Google Play Beta.
Применяемые практики
Pre-release сборка
Вначале у нас было два вида сборки, как и у многих:
Debug сборка, в которой были отключены ProGuard и SSL Pinning.
Release сборка, в которой ProGuard и SSL Pinning были включены.
Процесс выглядел так: разработчик заканчивает работу над фичой и отдает ее в тестирование. Тестировщик собирает Debug сборку, тестирует на ней тест-кейсы и проверяет корректность аналитики, отправляемой приложением. Если все хорошо, то он отправляет задачу в Ready for release, и она ждет момента, когда мы начнем собирать релиз.
Когда наступает время релиза приложения, разработчик сливает все задачи в master, выделяет rc-ветку и отдаёт ее QA на smoke-тестирование. QA собирает release сборку, начинает прогонять тесты. Но бывают случаи, когда что-то идет не так. Как правило, проблемы случаются из-за ProGuard. Конечно, их быстро фиксят, но это может задержать релиз или оттянуть его на какое-то время.
По этой причине мы создали pre-release сборку, в которой ProGuard включен, а SSL Pinning выключен. Это позволяет тестировщикам проверять корректность отправляемой аналитики (это являлось причиной, по которой тестировщики изначально не собирали release сборку).
Теперь же QA собирают pre-release сборку. Это дает им возможность тестировать аналитику и как можно раньше сталкиваться с проблемами вызванными ProGuard.
Specification first
Это подход, при котором спецификация первична. Когда мы разрабатываем новую фичу и для нее требуется backend, сначала создается спецификация, а потом, исходя из нее, начинается разработка фичи как со стороны backend, так и со стороны клиентов. Все изменения проходят через спецификацию, а уже потом вносятся изменения на backend и клиентах. Также по этой спецификации генерируется Swagger-документация по методам API.
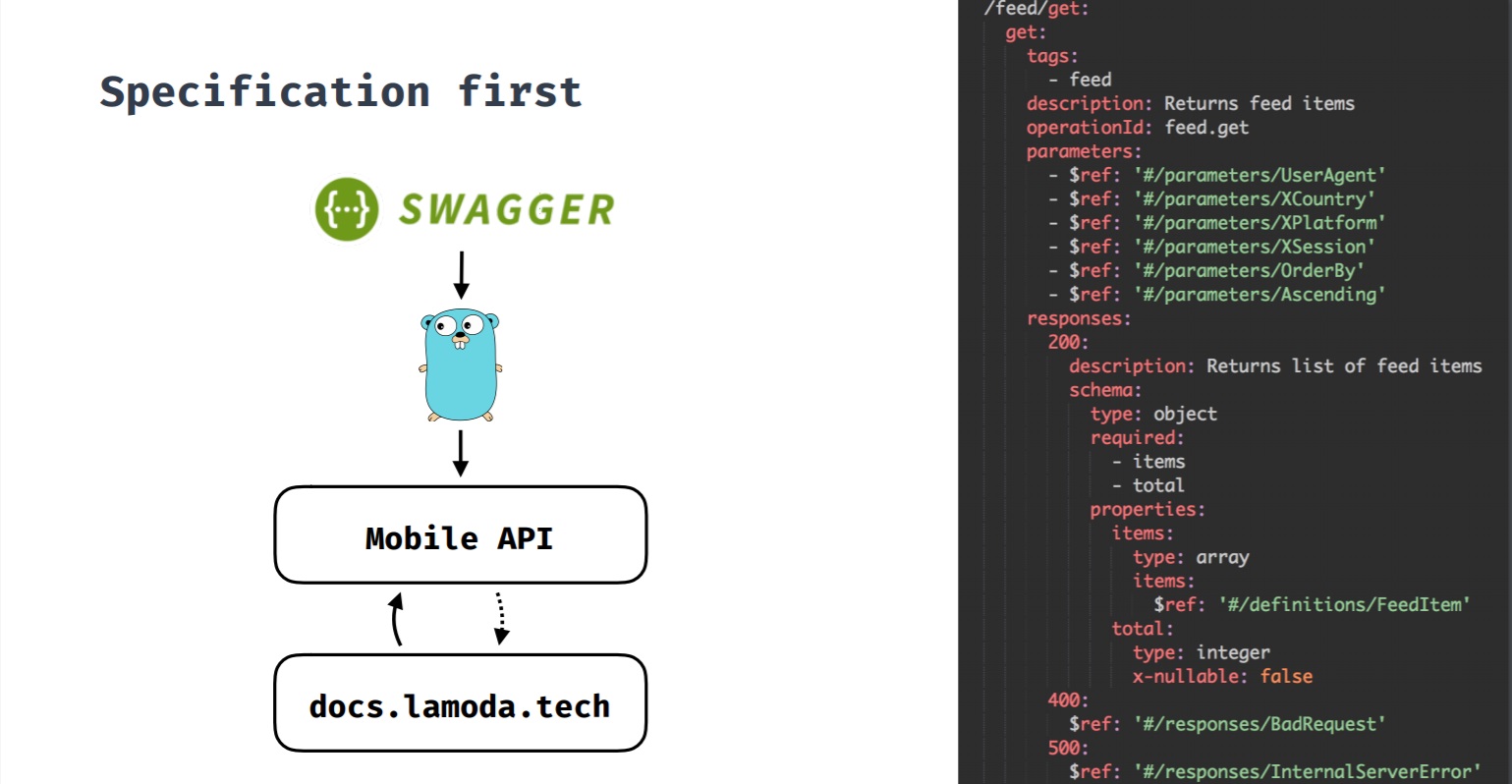
Изначально у нас был API, клиентами которого являлись не только мобильные приложения. Методы API были не консистентны между собой, что зачастую усложняло внесение изменений.
Также часто попадались забавные кейсы. Например, когда метод отдающий список брендов, в случае когда их было несколько, возвращал массив, а если бренд был один — возвращал объект.

Или, когда в отсутствии брендов возвращалось либо значение null, либо вообще 4 символа null
(не JSON). В таком случае приложению было тяжко.

Поэтому со временем мы пришли к тому, что мобильным приложениям требуется собственное API, которое бы учитывало их специфику и связывало мобильное приложение с кучей внутренних систем Lamoda, с которыми приходится взаимодействовать.

Одновременно с этим мы решили попробовать подход Specification first (Swagger-спецификация). Когда разработчик начинает работать над какой-то фичой, для которой нужен backend, он делает pull-request с контрактом фичи. Затем в этот pull-request добавляются все заинтересованные стороны из iOS, Android и backend команд. Когда всех устраивает контракт нового метода API, то pull-реквест вливается в backend-ветку и backend-разработчики начинают разработку фичи. Клиенты также начинают разработку фичи, потому что контракт теперь зафиксирован и него можно положиться и при необходимости сделать моки.
Feature-toggles
В компании есть собственная разработка A/B Tool, которая позволяет реализовывать и эксперименты, и Feature-toggles. Feature-toggles мы закрываем не критичный для пользователя функционал, который в случае необходимость можно отключить. Например, если в нем что-то пошло не так или же если нам требуется снизить нагрузку на backend (как вариант, в «черную пятницу»).
Также Feature-toggles позволяют нам тестировать библиотеки, чтобы иметь возможность посмотреть, будет ли другая библиотека решать нашу задачу лучше и вести себя стабильнее. Если же нет, то мы можем всегда откатиться на нашу предыдущую библиотеку.
Real User Monitoring
Real User Monitoring позволяет измерять производительность приложения с точки зрения пользователя. Например, покупатель нажал на товар в каталоге. Сколько времени ему понадобится ждать, прежде, чем он увидит результат своего действия, то есть увидит карточку товара с фотографиями? 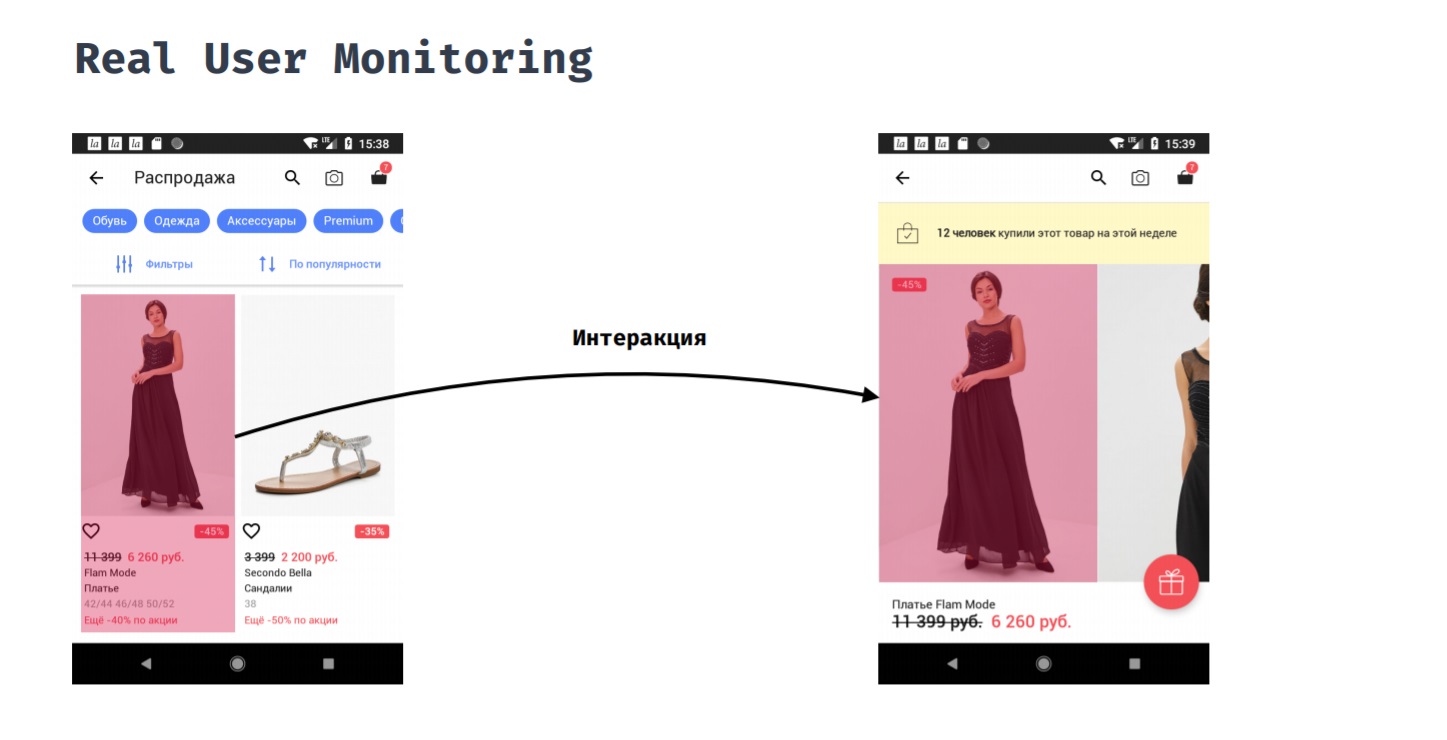
Это нельзя сделать автоматически, потому что точку начала и точку конца этого замера нужно проставлять вручную. Только разработчик понимает, когда можно считать, что пользователь уже готов взаимодействовать с новым экраном. В процессе этого взаимодействия нас могут интересовать такие вещи, как:
1. потребление памяти;
2. потребление CPU;
3. что происходило на основном потоке;
4. что грузилось из сети;
5. что происходило в других потоках.
Это дает нам возможность исправлять проблемы, если они возникают, потому что становится видно, что на самом деле заняло большую часть времени и что можно оптимизировать, чтобы приложение было более отзывчивым по отношению к пользователю.
Возврат технического долга
Перед тем как выкатить новую версию мы исправляем падения, которые произошли в предыдущей версии. Речь идёт не о критических падениях, так как это однозначно потребовало бы hotfix«ов, а о падениях, которые возникают не слишком часто, не затрагивают бизнес-показатели, но неприятны для пользователей.
После релиза версии, мы раскатываем её по процентам, мониторим критичные показатели и реагируем на инциденты, если они происходят. Для поэтапного раскатывания мы используем Google Play Console. Раскатку производится следующим образом: раскатили на 5%, мониторим показатель; если все в порядке, то катим дальше. Если что-то случилось, делаем hotfix и уже раскатываем его. Далее мы делаем раскатку на 10%, 20% и 50%.
Какие критические места мы мониторим?
- Сетевые запросы, в том числе и от сторонних библиотек: ошибки, время ответа, нагрузку.
- Падения.
- Handled exceptions, так называемые «обработанные исключения». Это исключения, которые могли бы произойти, если бы мы их не обернули в try-catch. Это позволяет не упасть приложению, если исключение произошло в некритичном для пользователя функционале. Например, из аналитики плохо падать. Однако она важна для продактов, чтобы понять, что фича улучшает или ухудшает конверсию. Использование Handled exceptions позволяет нам всё таки реагировать и исправлять эти проблемы.
Инструменты
- A/B Tool
- NewRelic RPM
- NewRelic Insights.
A/B Tool — это механизм проведения экспериментов и механизм раскатки переменных, те самые Feature-toggles. Это внутренняя разработка, поэтому она хорошо интегрирована во многие системы: в мобильные приложения, на сайт, на бэк-энд. Она позволяет доносить конфигурацию Feature-toggles не отдельным запросом за ней, а в заголовках ответов на запросы, которые приложение и так делает.
Это даёт нам возможность:
- Раскатывать эксперименты на офис, когда мы хотим какую-то фичу потестировать внутри нашего офиса.
- Раскатывать эксперимент, а также Feature-toggles на конкретного пользователя.
Система независима от внешних факторов. Если бы мы использовали сторонний инструмент, то в какой-то момент он мог бы оказаться заблокированным (привет, Роскомнадзор) или в нём что-то могло пойти не так. Для нас это было бы критично, так как в случае чего мы не смогли бы быстро переключить Feature-toggle. А так как это наша собственная разработка, такой проблемы у нас нет.
NewRelic — это такой инструмент, который позволяет в реальном режиме мониторить очень много разных показателей. Из всего многообразия возможностей New Relic мы используем, например, автоматическую инструментацию кода. Именно она позволяет нам мониторить сетевые запросы не только к нашему backend«у, но и все остальные (в том числе из сторонних библиотек). NewRelic поддерживает определённый набор стандартных клиентов для работы с сетью. Также он позволяет собирать информацию:
1. о потреблении памяти;
2. о потреблении CPU;
3. об операциях, связанных с JSON;
4. об операциях, связанных с SQlite.
Кроме того, мы используем NewRelic для сбора отчетов о падениях, для сбора обработанных исключений и для пользовательских интеракций — это как раз тот самый Real User Monitoring. У нас он реализован через механизм пользовательских интеракций NewRelic.
Что же все-таки со стабильностью?
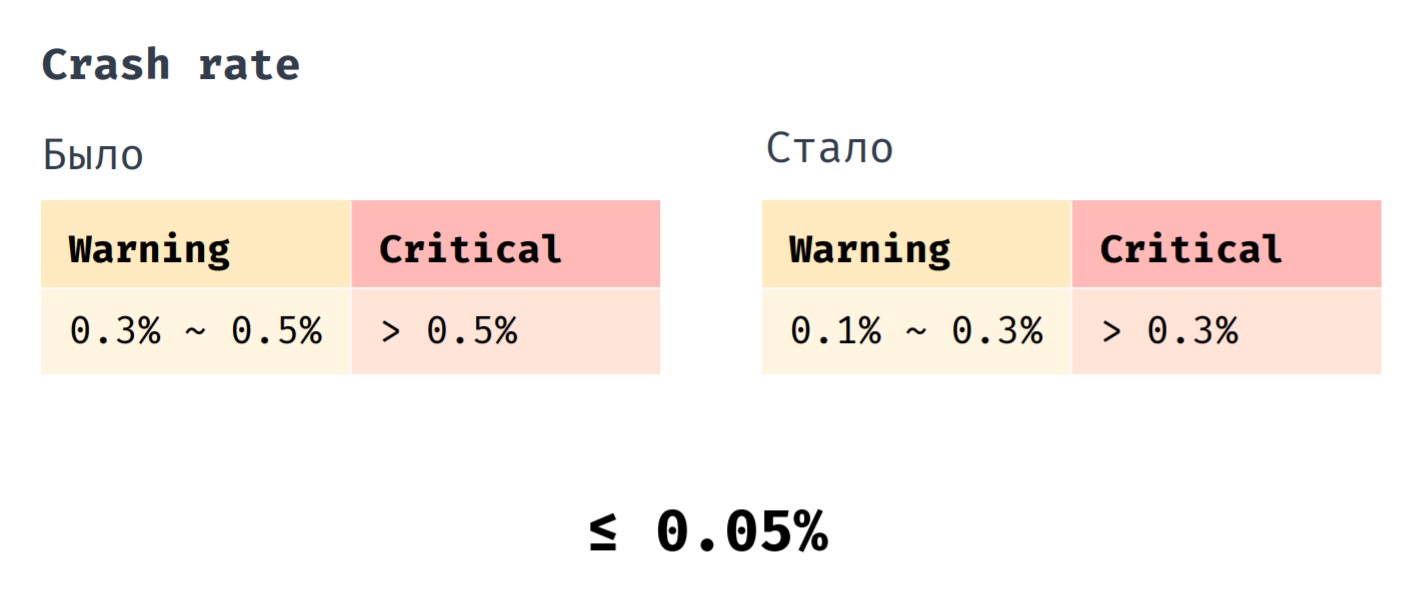
У нас есть такой показатель, как Crash rate. Раньше мы выкатывали hotfix, когда его показатель находился в промежутке от 0,3% до 0,5%. Совсем критично, если его значение становилось больше 0,5%.Теперь мы выкатываем hotfix, когда Crash rate находится в промежутке 0,1% до 0,3%. Критичным является значение, превышающее 0,3%.И, если раньше средний показатель Crash rate нашего приложения составлял 0,1%, то сейчас это 0,05%.
В заключение хотелось бы перечислить наиболее важные практики, которые помогают нам поддерживать стабильность приложения. Мы тестируем приложение максимально приближенное к production версии, закрываем некритичную функциональность feauture-toggles, а также мониторим и реагируем на важные для нас показатели.
