[Перевод] Камень, ножницы, бумага, собеседования, Спок

Когда целыми днями слушаешь, как проходят технические собеседования, начинаешь замечать закономерности. Вернее, в нашем случае, их отсутствие. Мне удалось обнаружить всего две вещи, которые остаются неизменными. Я даже придумал алкогольную игру на их основе: каждый раз, когда кто-нибудь решает, что ответ на вопрос — хеш-таблица, выпиваем стопку, если правильный ответ действительно хеш-таблица, выпиваем две. Но играть в нее не советую, я так чуть не помер.
Почему я целыми днями слушаю собеседования? Потому что несколько лет назад стал одним из создателей сервиса interviewing.io, платформы для проведения собеседований, где люди из IT-сферы могут отрабатывать навыки общения с работодателем и между делом находить работу.
В итоге я имею доступ к большому массиву данных о том, как один и тот же пользователь показывает себя на разных собеседованиях. И они оказываются настолько непредсказуемыми, что поневоле задумаешься о том, насколько вообще показательны результаты единственной встречи.
Как мы получаем данные
Когда пользователь, проводящий собеседования, и пользователь, ищущий работу, находят друг друга, они встречаются в совместном редакторе кода. Там подключена возможность общаться голосом и через текстовые сообщения, в наличии аналог маркерной доски для записи решений — можно сразу приступать к техническим вопросам.
Вопросы на наших собеседованиях обычно из разряда тех, которые задают в ходе телефонного интервью претендентам на должность бэкенд-разработчика ПО. Пользователи, проводящие собеседования, как правило, являются сотрудниками крупных компаний (Google, Facebook, Yelp) или представителями стартапов с сильным техническим уклоном (Asana, Mattermark, KeepSafe и другие). По итогам каждой встречи работодатели оценивают кандидатов по нескольким критериям, один из которых — навыки программирования. Оценки проставляются по шкале от одного («так себе») до четырех («здорово!»). На нашей платформе оценки от тройки и выше в большинстве случаев означают, что кандидат достаточно сильный, чтобы перейти на следующий этап.
Тут вы можете сказать: «Это все замечательно, но что здесь особенного? Многие компании собирают подобную статистику в процессе отбора кандидатов». Наши данные отличаются от этой статистики в одном отношении: один и тот же пользователь может принять участие в нескольких собеседованиях, причем каждое из них будет с новым сотрудником из новой компании. Это открывает возможности для весьма интересного сравнительного анализа в более-менее стабильной среде.
Вывод №1: Результаты сильно варьируются от собеседования к собеседованию
Начнем с парочки картинок. На графике ниже каждая иконка в виде человечка показывает среднюю индивидуальную оценку одного из пользователей, который принял участие в двух или больше собеседованиях. Один из параметров, который не отображен на этом графике — временной промежуток. Можете посмотреть, как меняются успехи людей с течением времени, здесь. Там что-то в духе первобытного хаоса.
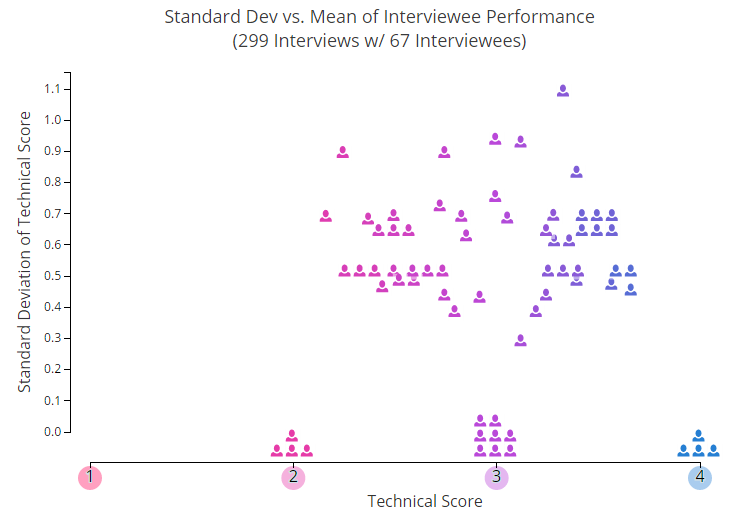
По оси Y показано типичное отклонение от средних значений — соответственно, чем выше поднимаемся, тем более непредсказуемыми оказываются результаты собеседований. Как видите, примерно 25% участников стабильно держатся на одном уровне, у остальных же все скачет вверх-вниз.
Внимательно изучив этот график, вы, несмотря на нагромождение данных, вероятно, смогли бы примерно прикинуть, кого из пользователей бы хотели пригласить на собеседование. Но здесь важно помнить: мы брали средние значения. А теперь представьте, что вам нужно принять решение на основе одной-единственной оценки, которая использовалось для его расчета. Вот тут-то и начинаются проблемы.
Для большей наглядности можете открыть офигительную интерактивную версию графика. Там каждая иконка раскрывается при наведении курсора и можно посмотреть, какую оценку пользователь получил на каждом из пройденных собеседований. Результаты могут вас сильно удивить! Ну вот например:
- Львиная доля тех, у кого есть как минимум одна четверка, хотя бы раз оказывались и в «двоечниках»
- Даже если отобрать только самых сильных кандидатов (средняя оценка — от 3.3 и выше), результаты все равно ощутимо колеблются
- У «середнячков» (средняя оценка — от 2.6 до 3.3) результаты особенно противоречивые
Нам стало интересно, есть ли какая-то зависимость между уровнем кандидата и амплитудой колебаний. Другими словами, может быть для тех, кто послабее, характерные резкие скачки, тогда как сильные программисты стабильны? Как выясняется, нет. Когда мы провели регрессионный анализ типичного отклонения по отношению к средней оценке, какой-либо значимой связи установить не удалось (R в квадрате составило около 0.03). А это значит, что люди получают разные оценки, независимо от своего общего уровня.
Я бы сказал так: когда смотришь на все эти данные, а потом представляешь, что тебе нужно выбрать человека по результатам одного собеседования, ощущение такое, будто разглядываешь прекрасную, роскошно обставленную комнату через замочную скважину. В одном случае повезет увидеть картину на стене, в другом — коллекцию вин, а в третьем — уткнешься в заднюю стенку дивана.
В реальных ситуациях, когда мы пытаемся решить, стоит ли звать претендента на собеседование в офис, мы обычно стремимся избежать ошибок первого рода (то есть случайно не отобрать тех, кто недотягивает до планки) и ошибок второго рода (то есть не отказать тем, кого стоило бы пригласить). Лидеры рынка при этом обычно выстраивают стратегию исходя из того, что ошибки второго рода приносят меньше вреда. Вроде логично, да? Если ресурсов хватает и число претендентов велико, даже при большом количестве ошибок второго рода кто-нибудь подходящий все равно найдется.
Но у этой стратегии допущения ошибок второго рода есть и теневая сторона, и сейчас она дает о себе знать, вылившись в текущий кризис найма в IT-сфере. Дают ли единичные собеседования в своем нынешнем виде достаточно информации? Не отклоняем ли мы, несмотря на повышенный спрос на талантливых разработчиков, компетентных работников просто потому, что пытаемся рассмотреть обширный график с сильными перепадами через крошечный глазок?
Итак, если отвлечься от метафор и чтения моралей: раз результаты собеседований так непредсказуемы, какова вероятность, что сильный кандидат провалится на телефонном интервью?
Вывод №2: Вероятность провала на собеседовании исходя из результатов прошлых попыток
Ниже представлено процентное распределение всей базы наших пользователей по средним оценкам.
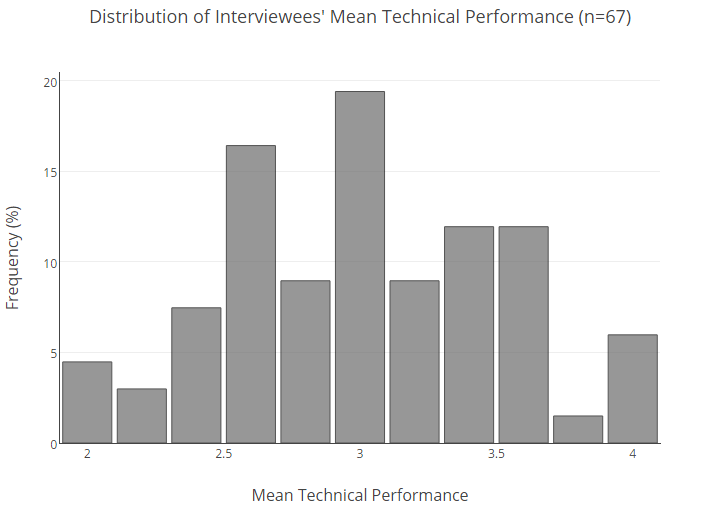
Чтобы понять, какова вероятность того, что кандидат с определенным средним результатом плохо покажет себя на интервью, нам пришлось заняться статистикой.
Сначала мы разбили собеседующихся на группы на основании средних оценок (при этом значения округлялись в пределах 0.25). Затем рассчитали для каждой группы вероятность провала, то есть получения оценки 2 и ниже. Далее, чтобы компенсировать скромный объем данных, мы сделали повторную выборку.
При составлении повторной выборки мы рассматривали результат будущего собеседования как мультиноминальное распределение. Другими словами, мы представили, что его итоги определяются броском игрального кубика с четырьмя гранями, причем для каждой группы центр тяжести у кубика смещен определенным образом.
Затем мы стали бросать эти кубики, пока не создали новый набор симулированных данных для каждой группы. Новые вероятности провала для пользователей с разными оценкам рассчитывались с учетом этих данных. Ниже вы можете увидеть график, который мы получили после 10 000 таких бросков.
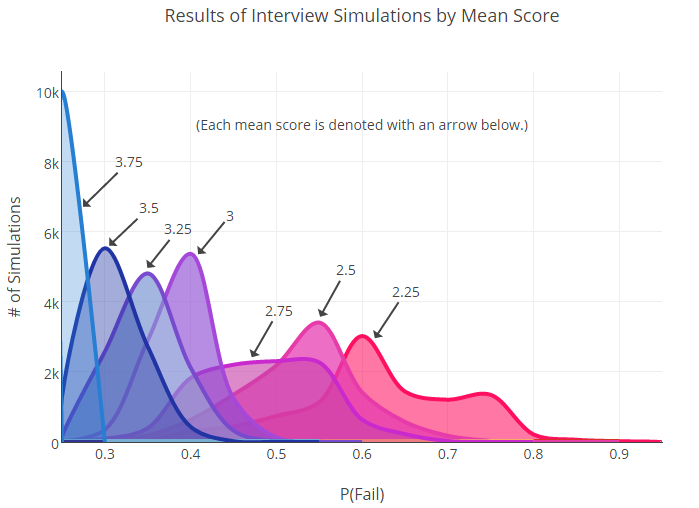
Как видите, здесь много пересечений. Это важно: факт наложения говорит нам о том, что между некоторыми из групп (например, 2.75 и 3) может не быть статистически значимых различий.
Разумеется, когда у нас будет больше данных (намного больше), границы между группами наметятся четче. С другой стороны, уже само то, что нужна огромная выборка, чтобы найти разницу между показателями частоты провала, может свидетельствовать об изначально высокой вариативности в результатах у среднего пользователя.
В конечном итоге, с уверенностью мы можем сказать следующее: разница между крайними точками шкалы (2.25 и 3.75) значительна, но все, что между ними, уже намного менее однозначно.
Тем не менее, исходя из этого распределения, мы предприняли попытку рассчитать процентную вероятность того, что кандидат с той или иной средней оценкой покажет плохой результат на отдельно взятом собеседовании:
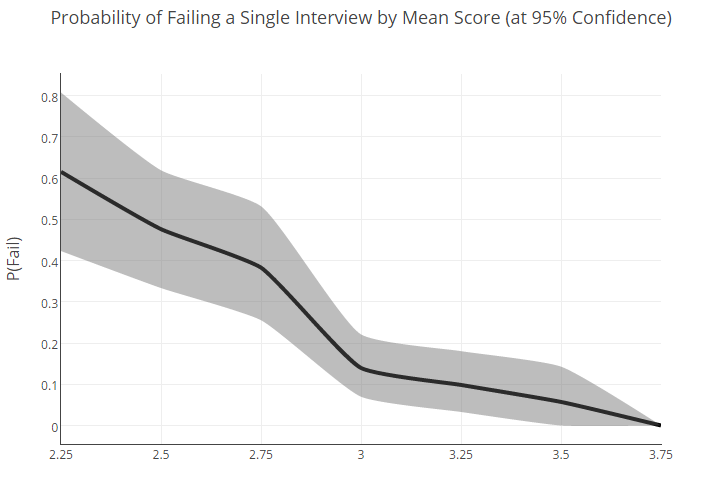
То, что люди с неплохим общим уровнем (т.е. средней оценкой около 3) могут провалиться с вероятностью в 22%, показывает: схемы отбора, которые мы используем сейчас, можно и нужно улучшать. Туманные результаты для «середнячков» только подтверждают это заключение.
Так что, собеседования обречены?
В общем и целом, слово «собеседования» вызывают у нас в сознании образ чего-то информативного и дающего воспроизводимый результат. Однако собранные нами данные говорят совсем о другом. И это другое перекликается и с моим личным опытом найма сотрудников, и с мнениями, которые часто приходится слышать в сообществе.
Статья Зака Холмэна Startup Interviewing is F***** освещает это несоответствие между основаниями для отбора кандидатов и той работой, которую им предстоит выполнять. Досточтимые господа из TripleByte пришли к подобным же выводам, обработав собственные данные. Платформа rejected.us недавно представила яркие свидетельства непоследовательности в процессе прохождения собеседований.
Можно поспорить, что многие, кого отсеяли после телефонного интервью с компанией А, показали лучший результат на другом собеседовании, оказались в какой-нибудь компании из тех, что считаются приличными — и теперь, полгода спустя, получают предложения пообщаться от рекрутеров из компании А. И несмотря на все старания обеих сторон этот процесс невнятного, непредсказуемого и, в конечном счете, случайного отбора кандидатов продолжается, словно в магическом круге.
Так что да, безусловно, один из выводов, который можно сделать, заключается в том, что технические собеседования зашли в тупик, они не дают достаточного объема надежной информации, чтобы предсказать исход отдельно взятого интервью. Собеседования с алгоритмическими задачами — очень острая тема в сообществе, и именно ее нам хотелось бы подробно разобрать в будущем.
Особенно интересно будет проследить зависимость между успешностью кандидатов и типом собеседования — у нас на платформе появляется все больше и больше подходов и разновидностей. На самом деле, это одна из наших долгосрочных целей: как следует закопаться в собранные данные, осмотреть диапазон текущих стратегий отбора кандидатов и сделать кое-какие серьезные, подкрепленные данными заключения о том, какие форматы собеседований дают больше всего полезных сведений.
Ну, а пока я склоняюсь к идее о том, что лучше смотреть на обобщенный уровень, чем руководствоваться в важном решении произвольными результатами одной-единственной встречи. Обобщенные данные позволяет сделать поправку не только на тех, кто в единичном случае отвечал нехарактерно слабо, но и на тех, кто оставил хорошее впечатление чисто из везения или со временем склонил голову перед этим чудищем и заучил наизусть Cracking the Coding Interview.
Понимаю, для компании не всегда практично или даже вообще возможно собирать где-то в дикой природе другие свидетельства мастерства кандидата. Но если, скажем, случай пограничный или человек показывает себя совсем не так, как вы ожидали — наверное, имеет смысл поговорить с ними еще раз и переключиться на другой материал, прежде чем принять окончательное решение.
